






语义分割:识别图像中存在的内容以及位置(通过查找属于它的所有像素,精度更高)
目录
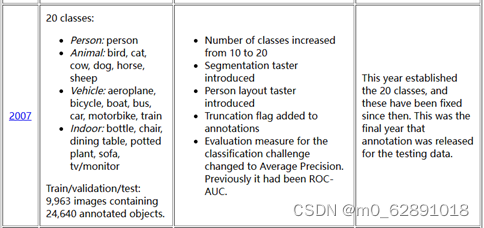
VOC数据集介绍:
- VOC数据集
官网:The PASCAL Visual Object Classes Homepage (ox.ac.uk)
常选用:VOC 2007 VOC 2012


VOC数据集下载:
官网下载
VOC 2007:http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
VOC 2012:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
通过pytorch下载也可以
VOC 2007数据集的标注:
解压后
- annotations:标注
用VS Code打开一个000032.xml,包含各种信息,特别是目标的位置坐标bndbox
![]()
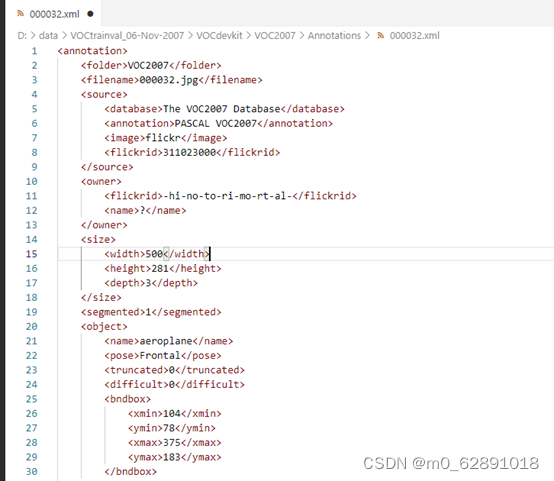
bndbox比较核心

- imagesets:图片合集,主要关注Main文件,包含了不同类别目标的训练/验证数据集图片的名称
打开Main——aeroplane_train
前面的数字对应图片,后面的1表示正样本,有aeroplane,-1则无
训练数据集
![]()
验证数据集
![]()
训练和验证数据集在一起:
![]()
- JPEGImages:.jpg原图片
以000032.jpg为例子

- SegmentationClass,SegmentationObject图片区域的标注(目标检测中这俩文件夹不用基本上)
一个标注网址:https://www.gifgit.com/image/rectangle-tool

左上角代表x最小值和y的最小值,右下角代表最大值
VOC 2012数据集的标注:
目标检测相关的其实不包含2007


COCO数据集:
COCO is a large-scale object detection, segmentation, and captioning dataset.
我们常用的是COCO2017
数据集的下载:

由于训练集比较大,只下载了验证集val文件和标注
打开annotation,我们目标检测主要用的是instance的文件,用pycharm/vscode打开
打开instance——val.json会得到一个乱糟糟的文件 可以通过ctrl+alt+p整理
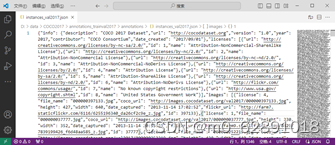
youtube上有关于.json讲的比较好的网址(推荐看一下):
https://www.youtube.com/watch?v=h6s61a_pqfM&ab_channel=lmmersiveLimit
我们重点关注的是里面的images和annotations
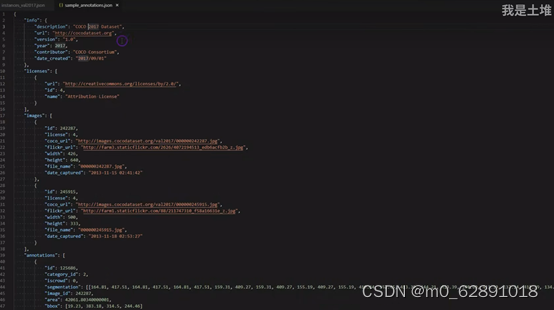
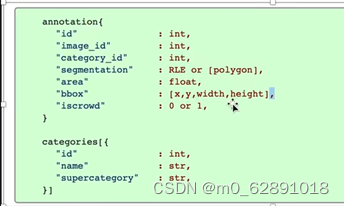
标注自己的数据集:
在线工具:
MakeScence在线工具:https://www.makesense.ai/
CVAT在线工具:Computer Vision Annotation Tool (cvat.ai)
CVAT更全面更方便用于大型。
用CVAT生成的coco数据集.json文件我们用pycharm打开通过ctrl+alt+L可以实现代码规范调整,实现从这样:

变成这样:
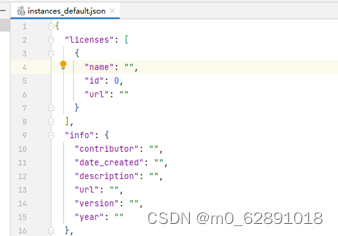
本地标注数据集:
精灵标注助手 不太推荐
但是导出的json不是coco数据集对应的那种格式
用pytorch去加载COCO数据集
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力
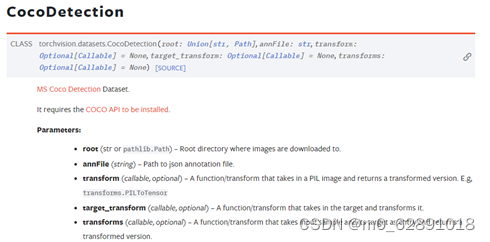
CocoDetection — Torchvision 0.18 documentation
- 首先了解一下python基础
元组:元组用“( )”表示,不可修改
字典:字典定义了键和值之间一对一的关系
数组:数组用“[ ]”表示,可修改
a = (2, 3, 4)
b = {'gongzhonghao':'tuduisuinian','username':'tudui'}
c = [1, 2, 3]
print(a)
print(b)
print(c)
print(type(a)) # <class 'tuple'>
print(type(b)) # <class 'dict'>
print(type(c)) # <class 'list'>

代码:
import torchvision
from PIL import ImageDraw
coco_dataset = torchvision.datasets.CocoDetection(root=r"D:\data\COCO2017\val2017\val2017", # 为了避免转义字符的冲突在文件地址前加上r能够避免冲突
annFile=r"D:\data\COCO2017\annotations_trainval2017\annotations\instances_val2017.json")
image, info = coco_dataset[0]
# image对应[0]:Image, info对应[1]:list,大概就是生成了20个候选框
# ctrl+p提示括号需要的参数
# 图片显示
image.show()
image_hanler = ImageDraw.ImageDraw(image)
# info显示, 我们需要ImageDraw来把候选框生成
for annotation in info:
x_min, y_min, width, height =annotation['bbox'] # 想取它的bbox,输入key即可, 会返回四个值,我们分别用四个变量去接收
image_hanler.rectangle(((x_min, y_min), (x_min + width, y_min + height)))
image.show()结果

















 3300
3300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









