









文章目录
【文章系列】
第一章 初探Kaggle竞赛————Kaggle竞赛系列_Titanic比赛
第二章 知识补充_随机森林————数学建模系列_随机森林
第三章 知识补充_LightGBM————集成学习之Boosting方法系列_LightGBM
第四章 再战Kaggle竞赛————Kaggle竞赛系列_SpaceshipTitanic比赛
第五章 重温回顾_学习金牌方法_数据分析————Kaggle竞赛系列_SpaceshipTitanic金牌方案分析_数据分析
第六章 重温回顾_学习金牌方法_数据处理————Kaggle竞赛系列_SpaceshipTitanic金牌方案分析_数据处理
第七章 重温回顾_学习金牌方法_建模分析
【前言】
Spaceship Titanic比赛,类似Titanic比赛,只是增加了更多的属性以及更大的数据量,仍是一个二分类问题。
今天要分析的是一篇大神的解决方案,看完后觉得干货满满,由衷地敬佩他们对数据分析的细致程度,对比之下只觉得之前自己的分析仅仅是表面功夫,单纯靠着模型的强大能力去完成任务。看来以后还是得不断地向各位前辈大佬学习,完善自己的解决方案!!!
【比赛简介】
Spaceship Titanic比赛是一个在Kaggle上举办的机器学习挑战,参赛者的任务是预测Spaceship Titanic在与时空异常碰撞时,哪些乘客被传送到了另一个维度。这个比赛提供了从飞船损坏的计算机系统中恢复的一组个人记录,参赛者需要使用这些数据来进行预测。
【回顾】
对数据的分析与处理已经在前两篇博客中提到:
Kaggle竞赛系列_SpaceshipTitanic金牌方案分析_数据分析
Kaggle竞赛系列_SpaceshipTitanic金牌方案分析_数据处理
本篇博客主要对处理好的数据的进行建模并求解问题
【正文】
(一)模型介绍
1. LR模型(逻辑回归)
逻辑回归是一种用于二元分类任务的统计方法,其中目标变量是二进制或分类的(通常为0或1、真或假、是或否)。与线性回归不同,线性回归用于回归任务,其中目标变量是连续的,而逻辑回归模型了解了给定输入属于两个类别之一的概率(例如,0或1)。
关于逻辑回归的一些关键点:
- 最大似然估计(MLE):逻辑回归使用最大似然估计来估计逻辑函数的参数。MLE是一种用于找到最大化观察到的给定数据的似然性的参数值的方法。
- S型/逻辑曲线:逻辑回归模型将S型或逻辑曲线拟合到数据上。这个曲线是一条S形曲线,范围在0和1之间。它将任何实数映射到0和1之间的值,可以解释为概率。
- 二进制输出:逻辑回归非常适合二元分类问题,其中输出可以取两个可能的值之一。它模型化了正类别的概率,通常在0.5处设置决策边界(阈值)。如果预测的概率大于0.5,则将实例分类为正类别;否则,将其分类为负类别。
- 对数几率:逻辑回归模型化了概率的对数几率(对数比值)。对数几率是输入特征的线性组合,通过S型函数转换为概率。
- 正则化:与线性回归类似,逻辑回归也可以进行正则化以防止过拟合。常见的正则化技术包括L1(Lasso)和L2(Ridge)正则化。
- 可解释性:逻辑回归为每个输入特征提供了系数,可以解释为了解每个特征对正类别概率的影响。
2. KNN模型(K最近邻)
KNN算法通过选择k个最近邻居中的多数类来进行分类,通常使用欧氏距离作为距离度量。这是一种简单而有效的算法,但受多种因素影响,例如k的值、对数据的预处理以及所使用的距离度量方法。
以下是关于K-最近邻(KNN)算法的一些关键点:
- K值选择:KNN的性能高度依赖于k的选择,k表示选择多少个最近邻来决定样本的分类。选择较小的k值可能会导致模型对噪声敏感,而选择较大的k值可能会平滑决策边界,忽略了局部特征。
- 距离度量:KNN通常使用欧氏距离来度量数据点之间的相似性。然而,根据具体问题,也可以选择其他距离度量方法,如曼哈顿距离、闵可夫斯基距离等。
- 数据预处理:数据的预处理对KNN的性能影响很大。对数据进行特征缩放、去除异常值、处理缺失值等预处理步骤可以改善模型的性能。
- 多类别问题:KNN通常用于二元分类问题,但也可以扩展到多类别分类。在多类别问题中,可以使用投票法来选择多数类。
- 计算成本:KNN的计算成本较高,因为对每个预测样本都需要计算与所有训练样本的距离。为了提高效率,可以使用数据结构如KD树或Ball树来加速最近邻搜索。
- 超参数调优:除了k值外,还可以通过交叉验证等方法来调整KNN的其他超参数,以达到更好的性能。
3. SVM模型(支持向量机)
SVM寻找在特征空间中分隔数据的最优超平面。预测是通过查看测试点位于超平面的哪一侧来进行的。普通的SVM假定数据是线性可分的,但这并不总是成立。当这一假设不成立时,可以使用核技巧(Kernel Trick)将数据转换到高维空间,以使其线性可分。SVM是一种流行的算法,因为它具有计算效率高且能产生非常好的结果的特点。
以下是关于支持向量机(SVM)算法的一些关键点:
- 超平面:SVM的目标是找到一个超平面,它将训练数据在特征空间中划分为两个类别。这个超平面被选择为离最近的训练样本点最远的超平面,这些样本点被称为支持向量。
- 线性可分与核技巧:普通的SVM假定数据是线性可分的,即存在一个超平面可以完美地分隔两个类别。然而,现实中的数据通常不是线性可分的。为了处理这种情况,可以使用核技巧将数据映射到更高维的特征空间,使其在那个空间中变得线性可分。常见的核函数包括线性核、多项式核和高斯径向基核(RBF核)等。
- 支持向量:支持向量是离超平面最近的那些训练样本点。它们对于定义超平面具有重要作用,因为它们的位置和数量决定了超平面的位置和方向。
- C参数:SVM中的C参数控制着正则化的程度。较小的C值会导致更大的间隔,但可能会允许一些训练样本点错误分类。较大的C值会导致更小的间隔,但会更严格地要求所有训练样本点正确分类。
- 多类别分类:SVM最初设计用于二元分类问题,但可以扩展到多类别分类问题。一种方法是使用一对一(One-vs-One)或一对其余(One-vs-Rest)策略来处理多类别问题。
- 计算效率:SVM在许多情况下非常计算高效,特别适用于高维数据。它在处理小到中等大小的数据集时表现良好。
4. RF模型(随机森林)
随机森林是一种可靠的决策树集成方法,可用于回归或分类问题。在随机森林中,个体决策树是通过装袋(bagging)构建的,也就是通过有放回抽样创建多个训练数据集,并使用较少的特征进行划分。由此产生的多样化、不相关的决策树组成的森林具有降低方差的特性,因此对数据的变化更具鲁棒性,并将其预测准确性保持到新数据上。它适用于连续和分类数据。
以下是关于随机森林(RF)的一些关键点:
- 集成方法:随机森林是一个集成方法,它由多个决策树组成,每个决策树对数据进行独立训练。最终的预测结果是由这些个体决策树的投票或平均值组合而成。
- 装袋(Bagging):随机森林使用装袋技术,通过从原始数据中有放回地抽样创建多个训练数据集。这意味着每个决策树的训练数据都是通过随机抽样生成的,增加了模型的多样性。
- 特征子集:在每个决策树的训练过程中,只使用了数据中的一部分特征子集。这有助于减小每个决策树之间的相关性,进一步提高了模型的多样性。
- 降低方差:随机森林的多样性和装袋技术使其能够减小模型的方差,从而提高了模型的泛化能力。这意味着它对数据的变化更具鲁棒性,更容易适应不同的数据集。
- 适用性:随机森林适用于各种类型的数据,包括连续数据和分类数据。它不需要对数据进行太多的预处理,并且通常不需要调整太多的超参数。
- 重要性评估:随机森林可以估计特征的重要性,帮助识别哪些特征对于预测最重要。
具体算法原理以及实现可以参考我的另一篇博客:数学建模系列_随机森林
5. XGBoost模型(极端梯度提升)
XGBoost与随机森林(RF)类似,它也由一组决策树组成。不同之处在于如何派生这些决策树;XGBoost在优化其目标函数时使用了极端梯度提升。它通常能够产生最佳结果,但相对于其他梯度提升算法而言,速度较慢。
以下是关于极端梯度提升(XGBoost)的一些关键点:
- 集成方法:XGBoost也是一个集成方法,它由多个决策树组成,每个决策树都是基于前一棵树的预测进行构建的。这使得模型能够捕捉数据中的复杂关系。
- 梯度提升:XGBoost使用梯度提升技术来优化其目标函数。它通过迭代的方式逐步改进模型的预测性能,每次迭代都调整模型以降低误差。
- 效果出色:XGBoost通常能够产生出色的结果,因为它在每一步都尝试最小化损失函数,并且可以处理复杂的数据分布和特征关系。它通常被用于各种类型的机器学习竞赛中,并且在实际应用中也表现良好。
- 相对较慢:相对于其他梯度提升算法,XGBoost的训练速度较慢。这是因为它需要进行多轮迭代来不断优化模型。但近年来,XGBoost的性能已经得到了改进,特别是通过使用并行计算和优化技巧。
- 正则化和特征重要性:XGBoost支持正则化技巧,可以减少过拟合的风险。此外,它还可以估计特征的重要性,帮助识别哪些特征对于预测最重要。
6. LightGBM模型(轻梯度提升)
LGBM基本上与XGBoost工作方式相同,但使用了一种更轻的提升技术。它通常能够产生与XGBoost类似的结果,但速度明显更快。
以下是关于轻梯度提升机(LGBM)的一些关键点:
- 集成方法:LGBM也是一种集成方法,它由多个决策树组成,并使用提升技术来逐步改进模型的预测性能。
- 轻量级:LGBM之所以称为"轻"梯度提升机,是因为它采用了一种轻量级的提升技术,相对于一些其他提升算法,如XGBoost,它的实现更加高效。这使得LGBM在训练和预测时速度更快。
- 结果相似:尽管LGBM采用了更轻量级的技术,但通常能够产生与XGBoost相似的结果。这使得LGBM成为一种在时间和性能之间取得平衡的选择。
- 并行计算:LGBM还支持并行计算,可以充分利用多核处理器的性能,加速模型的训练过程。
- 应用广泛:LGBM在各种机器学习任务中得到广泛应用,包括分类、回归、排名等。它在大规模数据集和高维数据上表现出色。
具体算法原理以及实现可以参考我的另外两篇博客:
7. CatBoost模型(分类提升)
CatBoost是一种基于梯度提升决策树的开源算法。它支持数值、分类和文本特征。CatBoost在处理异构数据和相对较小的数据集时表现良好。非正式地说,它试图从XGBoost和LGBM中融合最佳的特点。
以下是关于分类提升(CatBoost)的一些关键点:
- 梯度提升决策树:CatBoost是一种梯度提升决策树算法,它在集成多个决策树的基础上逐步改进模型的预测性能。
- 支持多种特征类型:CatBoost具有广泛的特征支持,包括数值特征、分类特征和文本特征。这使得它在处理多种类型的数据时非常灵活。
- 适用于小型数据集:CatBoost在相对较小的数据集上表现出色,这使得它适用于许多实际应用中的情况。
- 性能平衡:CatBoost试图在XGBoost和LGBM之间取得性能平衡,即在速度和模型性能之间找到一个良好的折中点。
- 自动处理分类特征:CatBoost可以自动处理分类特征的编码,无需手动进行独热编码等操作。
- 强大的正则化:CatBoost支持强大的正则化技术,有助于防止过拟合。
8. NB模型(朴素贝叶斯)
朴素贝叶斯是一种通过使用贝叶斯定理来学习如何对样本进行分类的算法。它利用先验信息根据贝叶斯法则“更新”事件的概率。该算法运行速度较快,但一个缺点是它假定输入特征是相互独立的,而这并不总是成立。
以下是关于朴素贝叶斯(NB)的一些关键点:
- 基于贝叶斯定理:朴素贝叶斯算法基于贝叶斯定理,利用先验信息和样本数据来估计类别的后验概率。通过比较后验概率,算法可以将样本分配给最有可能的类别。
- 快速:朴素贝叶斯算法通常运行速度较快,这使得它适用于大规模数据集和实时分类任务。
- 朴素假设:朴素贝叶斯算法的“朴素”部分指的是它假定输入特征之间是相互独立的,即每个特征对于类别的影响是相互独立的。这个假设有时候并不符合实际情况,因为特征之间可能存在相关性。
- 适用性:朴素贝叶斯通常用于文本分类、垃圾邮件过滤、情感分析等自然语言处理任务,以及一些小到中等规模的分类问题。它在处理高维数据和稀疏数据时表现良好。
- 多种变种:朴素贝叶斯有许多变种,如多项式朴素贝叶斯、伯努利朴素贝叶斯等,用于不同类型的数据和问题。
(二)模型训练
1. 定义模型参数
定义的各类模型以及对应的参数解释如下所示:
# 分类器
classifiers = {
"LogisticRegression": LogisticRegression(random_state=0), # 逻辑回归分类器
"KNN": KNeighborsClassifier(), # K最近邻分类器
"SVC": SVC(random_state=0, probability=True), # 支持向量机分类器
"RandomForest": RandomForestClassifier(random_state=0), # 随机森林分类器
#"XGBoost" : XGBClassifier(random_state=0, use_label_encoder=False, eval_metric='logloss'), # XGBoost分类器,耗时较长
"LGBM": LGBMClassifier(random_state=0), # 轻梯度提升机分类器
"CatBoost": CatBoostClassifier(random_state=0, verbose=False), # 分类提升(CatBoost)分类器
"NaiveBayes": GaussianNB() # 朴素贝叶斯分类器
}
# 网格搜索的参数范围
LR_grid = {'penalty': ['l1', 'l2'], # 逻辑回归的正则化类型
'C': [0.25, 0.5, 0.75, 1, 1.25, 1.5], # 正则化强度
'max_iter': [50, 100, 150]} # 最大迭代次数
KNN_grid = {'n_neighbors': [3, 5, 7, 9], # K最近邻的邻居数
'p': [1, 2]} # 距离度量参数
SVC_grid = {'C': [0.25, 0.5, 0.75, 1, 1.25, 1.5], # SVM的正则化强度
'kernel': ['linear', 'rbf'], # 核函数类型
'gamma': ['scale', 'auto']} # 核函数参数
RF_grid = {'n_estimators': [50, 100, 150, 200, 250, 300], # 随机森林的树的数量
'max_depth': [4, 6, 8, 10, 12]} # 树的最大深度
boosted_grid = {'n_estimators': [50, 100, 150, 200], # 提升树的数量
'max_depth': [4, 8, 12], # 树的最大深度
'learning_rate': [0.05, 0.1, 0.15]} # 学习率
NB_grid = {'var_smoothing': [1e-10, 1e-9, 1e-8, 1e-7]} # 朴素贝叶斯的平滑参数
# 所有网格参数的字典
grid = {
"LogisticRegression": LR_grid,
"KNN": KNN_grid,
"SVC": SVC_grid,
"RandomForest": RF_grid,
"XGBoost": boosted_grid,
"LGBM": boosted_grid,
"CatBoost": boosted_grid,
"NaiveBayes": NB_grid
}
2. 超参调优
使用网格搜索(GridSearchCV)来寻找每个分类器的最佳参数,并在验证集上评估它们的性能。
i = 0
clf_best_params = classifiers.copy()
valid_scores = pd.DataFrame({'Classifer': classifiers.keys(), 'Validation accuracy': np.zeros(len(classifiers)), 'Training time': np.zeros(len(classifiers))})
# 遍历每个分类器和对应的参数网格
for key, classifier in classifiers.items():
start = time.time()
clf = GridSearchCV(estimator=classifier, param_grid=grid[key], n_jobs=-1, cv=None)
# 训练和评分
clf.fit(X_train, y_train)
valid_scores.iloc[i, 1] = clf.score(X_valid, y_valid)
# 保存训练好的模型
clf_best_params[key] = clf.best_params_
# 打印迭代次数和训练时间
stop = time.time()
valid_scores.iloc[i, 2] = np.round((stop - start) / 60, 2)
print('模型:', key)
print('训练时间(分钟):', valid_scores.iloc[i, 2])
print('')
i += 1
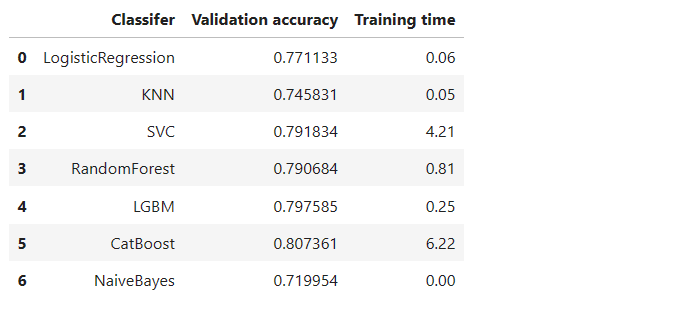
得到不同模型的valid_scores如下:
valid_scores
对应的最佳超参如下:
clf_best_params

3. 预测输出
(1)确定模型以及对应超参
根据上面的步骤,最终确定使用LGBM以及CatBoost模型来输出。
best_classifiers = {
"LGBM" : LGBMClassifier(**clf_best_params["LGBM"], random_state=0),
"CatBoost" : CatBoostClassifier(**clf_best_params["CatBoost"], verbose=False, random_state=0),
}
(2)交叉验证以及集成预测
使用软投票将结果结合在一起
# 交叉验证的折数
FOLDS = 10
preds = np.zeros(len(X_test))
# 遍历最佳分类器字典中的每个分类器
for key, classifier in best_classifiers.items():
start = time.time()
# 使用10折交叉验证
cv = StratifiedKFold(n_splits=FOLDS, shuffle=True, random_state=0)
score = 0
for fold, (train_idx, val_idx) in enumerate(cv.split(X, y)):
# 获取训练集和验证集
X_train, X_valid = X[train_idx], X[val_idx]
y_train, y_valid = y[train_idx], y[val_idx]
# 训练模型
clf = classifier
clf.fit(X_train, y_train)
# 进行预测并计算准确率
preds += clf.predict_proba(X_test)[:, 1]
score += clf.score(X_valid, y_valid)
# 平均准确率
score = score / FOLDS
# 停止计时
stop = time.time()
# 打印准确率和时间
print('模型:', key)
print('平均验证准确率:', np.round(100 * score, 2))
print('训练时间(分钟):', np.round((stop - start) / 60, 2))
print('')
# 集成预测
preds = preds / (FOLDS * len(best_classifiers))

4. 提交结果
(1)显示预测概率分布的分布图
plt.figure(figsize=(10,4))
sns.histplot(preds, binwidth=0.01, kde=True)
plt.title('Predicted probabilities')
plt.xlabel('Probability')
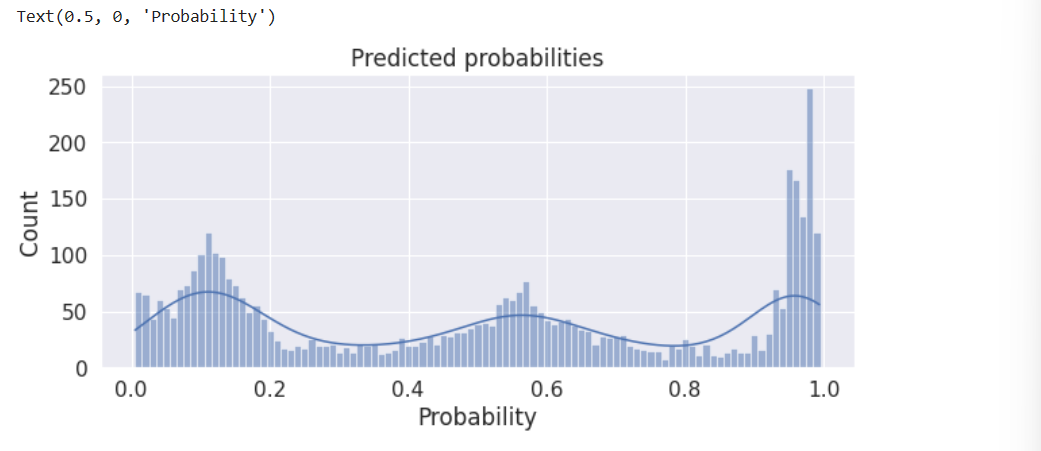
(2)转换为二分类
最后,我们需要将每个预测的概率值转化为两个类别中的一个(True、False)。最简单的方法是将每个概率四舍五入到最接近的整数(0 表示 False 或 1 表示 True)。然而,假设训练集和测试集具有类似的分布,我们可以调整分类阈值,以使我们的预测中运输和不运输的比例与训练集中的比例相似。请记住,训练集中运输乘客的比例为 50.4%。
# 计算通过四舍五入将预测概率值转化为二进制分类结果后,在测试集中所占的比例
rounded_proportion = np.round(100 * np.round(preds).sum() / len(preds), 2)
# 打印结果
print(rounded_proportion)
# out:52.84
我们的模型似乎(潜在地)高估了测试集中运输的乘客数量。让我们试着把这个比例降低一点。
(3)微调阈值
# 定义函数 preds_prop,用于计算给定阈值下的预测正类别(运输)的比例
def preds_prop(preds_arr, thresh):
pred_classes = (preds_arr >= thresh).astype(int)
return pred_classes.sum() / len(pred_classes)
# 定义函数 plot_preds_prop,用于绘制一系列阈值下的预测正类别比例曲线
def plot_preds_prop(preds_arr):
# 创建一个阈值数组
T_array = np.arange(0, 1, 0.001)
# 计算不同阈值下的正类别比例
prop = np.zeros(len(T_array))
for i, T in enumerate(T_array):
prop[i] = preds_prop(preds_arr, T)
# 绘制正类别比例曲线
plt.figure(figsize=(10, 4))
plt.plot(T_array, prop)
target_prop = 0.519 # 试验中可以调整这个目标值
plt.axhline(y=target_prop, color='r', linestyle='--')
plt.text(-0.02, 0.45, f'Target proportion: {target_prop}', fontsize=14)
plt.title('Predicted target distribution vs threshold')
plt.xlabel('Threshold')
plt.ylabel('Proportion')
# 寻找最优阈值(使得比例最接近目标比例)
T_opt = T_array[np.abs(prop - target_prop).argmin()]
print('Optimal threshold:', T_opt)
return T_opt
# 调用函数 plot_preds_prop 来绘制曲线并寻找最优阈值
T_opt = plot_preds_prop(preds)

preds_tuned=(preds>=T_opt).astype(int)
(4)提交结果
# 读取样本提交文件
sub = pd.read_csv('../input/spaceship-titanic/sample_submission.csv')
# 添加预测结果到样本提交文件中,假设 preds_tuned 是您的调整后的预测结果
sub['Transported'] = preds_tuned
# 将0替换为False,将1替换为True
sub = sub.replace({0: False, 1: True})
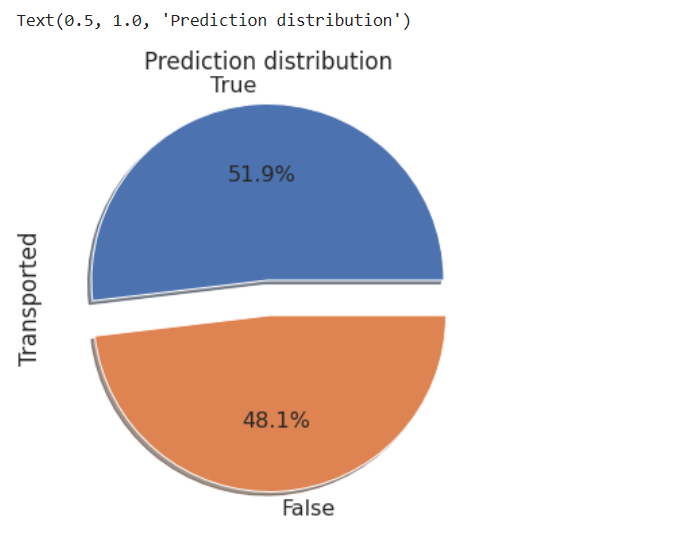
# 绘制预测结果的分布情况
plt.figure(figsize=(6, 6))
sub['Transported'].value_counts().plot.pie(explode=[0.1, 0.1], autopct='%1.1f%%', shadow=True, textprops={'fontsize': 16}).set_title("Prediction distribution")
sub.to_csv('submission.csv', index=False)
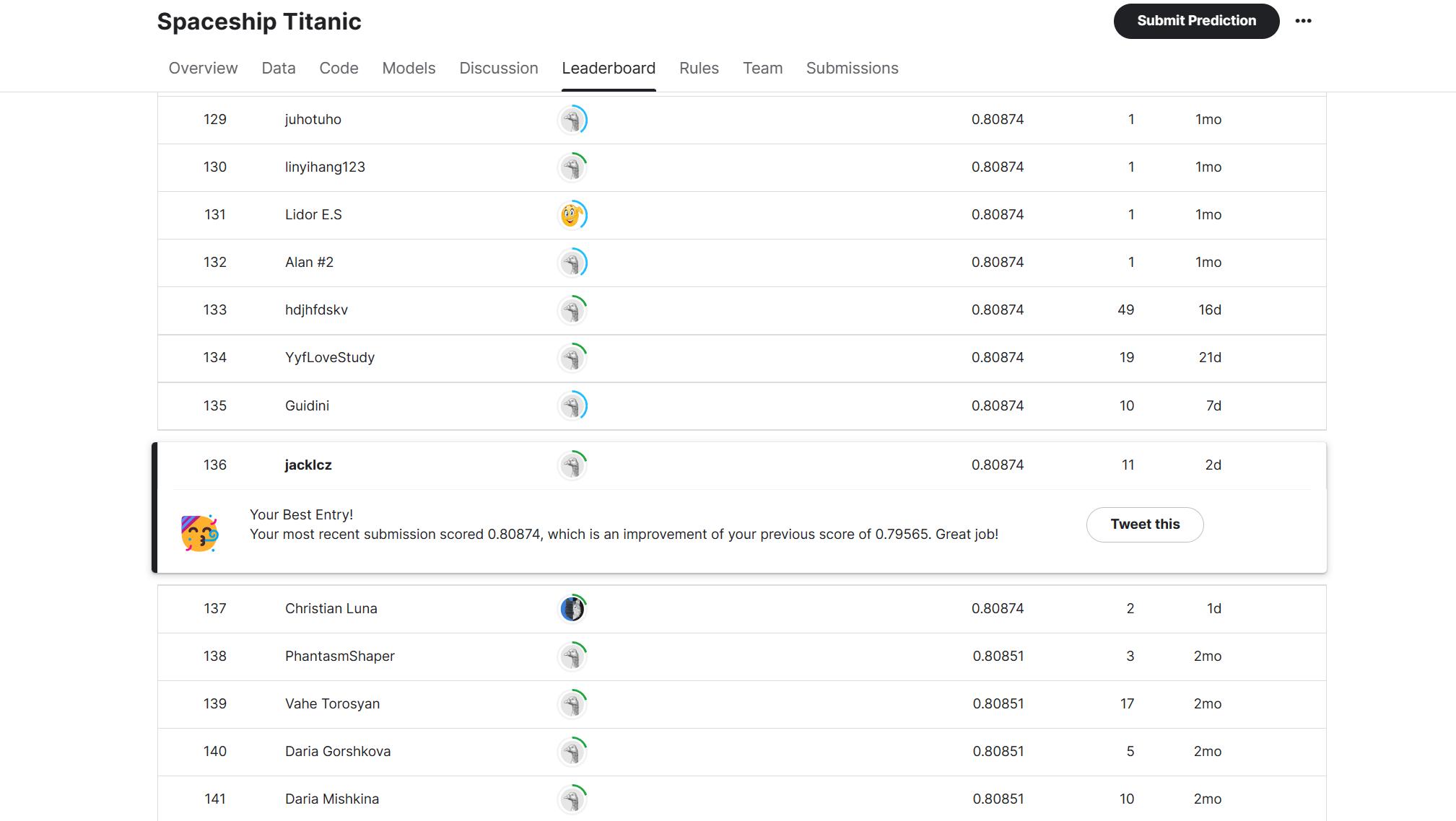
最终该方案的得分是0.80874,排名136。
(三)归纳总结
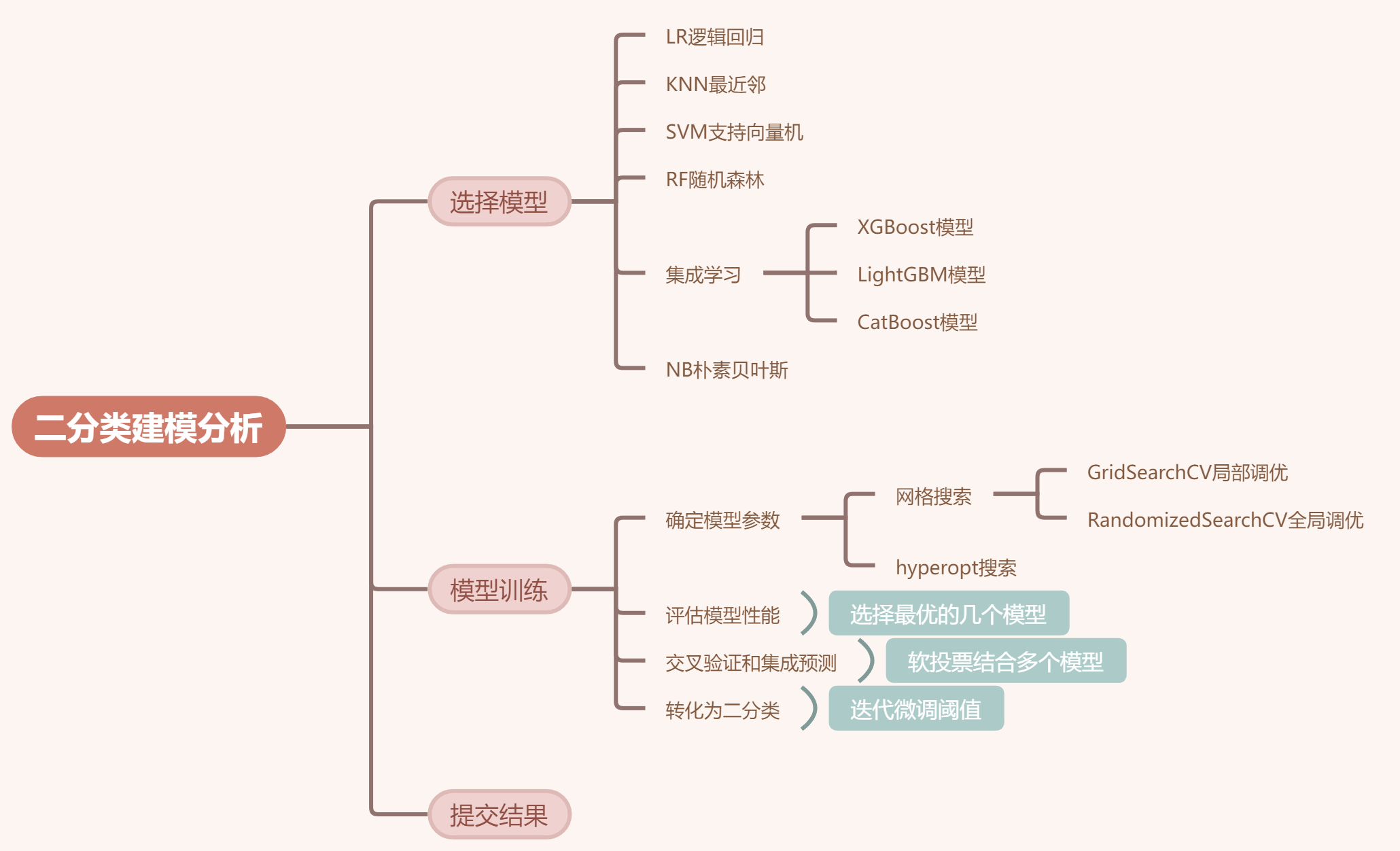
对于二分类问题,我们可以采用以下的流程进行建模处理
(四)写在最后
至此,关于该金牌方案的分析过程已全部完成,有什么问题与见解欢迎在评论区留言或私信我o( ̄▽ ̄)ブ
往期工作:















 2092
2092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









