










 本文详细介绍了CatBoost,一种强大的梯度提升机器学习算法,其核心概念包括梯度提升树、目标函数、损失函数以及特征重要性的评估。文章比较了CatBoost与LightGBM和XGBoost的关联,强调了CatBoost在处理分类特征、防止过拟合和内置缺失值处理方面的优势。同时,文章涵盖了CatBoost的实际操作,包括数据格式、参数设置和模型训练过程中的可视化。
本文详细介绍了CatBoost,一种强大的梯度提升机器学习算法,其核心概念包括梯度提升树、目标函数、损失函数以及特征重要性的评估。文章比较了CatBoost与LightGBM和XGBoost的关联,强调了CatBoost在处理分类特征、防止过拟合和内置缺失值处理方面的优势。同时,文章涵盖了CatBoost的实际操作,包括数据格式、参数设置和模型训练过程中的可视化。
文章目录
【文章系列】
第一章 集成学习_LightGBM————集成学习之Boosting方法系列_LightGBM
第二章 集成学习_XGBoost————集成学习之Boosting方法系列_XGboost
第三章 集成学习_CatBoost————集成学习之Boosting方法系列_CatBoost
【前言】
集成学习是一种机器学习方法,通过将多个弱学习器(weak learners)组合成一个更强大的集成模型来提高预测性能和泛化能力。
Boosting 是一种迭代的集成方法,它通过逐步调整训练数据的权重和/或模型的权重来训练多个弱学习器,以便每个弱学习器更关注先前被错误分类的样本。AdaBoost、Gradient Boosting 和 XGBoost 都是 Boosting 的变种。
本文将介绍Boosting方法的其中一种:CatBoost
【算法简介】
CatBoost是一种高效的梯度提升机器学习算法,适用于分类和回归问题,具有自动处理分类特征、防止过拟合、并行处理、内置缺失值处理等优势,通常在性能上胜过其他梯度提升方法,是一个强大而易于使用的模型训练工具。
【正文】
(一)CatBoost核心概念
1. 梯度提升树
CatBoost使用梯度提升树作为基本学习器,这是一种集成学习方法,通过逐步构建多个决策树来改进预测性能。每棵树都试图纠正前一棵树的错误。
2. 目标函数
CatBoost的目标函数是优化的核心,它是一个损失函数的组合,用于衡量模型的预测误差。在训练过程中,CatBoost通过最小化目标函数来不断优化模型的参数,使模型的预测更接近实际值。
3. 损失函数
损失函数是目标函数的一部分,它是用来度量模型对训练数据的拟合程度的函数。在分类问题中,常见的损失函数包括对数损失(Logarithmic Loss),均方误差(Mean Squared Error)用于回归问题。CatBoost允许用户自定义损失函数以满足特定任务需求。
4. 特征重要性
CatBoost可以估计每个特征的重要性,这有助于了解哪些特征对模型的预测起到关键作用。它可以通过不同的方式来计算特征重要性,如基于树的方法、基于Permutation Importance的方法等,帮助用户进行特征选择和解释模型。
(二)CatBoost与LightGBM、XGBoost的关联
1. 共同之处
(1)基于梯度提升树:CatBoost、LightGBM和XGBoost都使用梯度提升树作为基本学习器,通过构建多个决策树来改进预测性能。
(2)支持分类和回归:这三种算法都可以用于解决分类问题和回归问题,具有广泛的应用领域。
(3)可处理缺失值:它们都具有处理缺失值的能力,无需额外的数据预处理。
(4)提供特征重要性:CatBoost、LightGBM和XGBoost都能够估计特征的重要性,帮助用户进行特征选择和模型解释。
2. 优势
(1)CatBoost的优势:
- 自动处理分类特征:CatBoost可以自动处理分类特征,无需进行独热编码或标签编码,因此更加方便。
- 防止过拟合:CatBoost使用对称树的正则化方法来防止过拟合。
- 内置的数据处理:CatBoost内置了数据处理功能,可以处理缺失值。
- 鲁棒性:CatBoost在处理噪声数据时表现出色,具有良好的鲁棒性。
(2)LightGBM的优势:
- 高效的训练速度:LightGBM以其基于直方图的分割方法,通常能够比其他算法更快地训练模型。
- 内存效率:LightGBM具有较低的内存占用,适合处理大规模数据集。
(3)XGBoost的优势:
- 丰富的生态系统:XGBoost有一个强大的生态系统,有丰富的支持库和工具。
- 可解释性:XGBoost提供了较好的模型可解释性,能够帮助用户理解模型的预测过程。
(三)CatBoost的工作原理
1. 基本数学模型
梯度提升是一种集成学习技术,它通过迭代地添加预测模型 (通常是决策树) 来最小化损失函数。每一步都尝试添加一个新的模型,以纠正前一步骤中的残差 (即真实值与当前模型预测值之间的差异) 。
在 CatBoost 中,模型的预测值 y ^ \hat{y} y^ 是通过累加所有决策树的贡献来计算的:
y
^
i
=
∑
k
=
1
K
f
k
(
x
i
)
\hat{y}_i=\sum_{k=1}^Kf_k(x_i)
y^i=k=1∑Kfk(xi)
其中,
f
k
(
x
i
)
f_k(x_i)
fk(xi) 是第
k
k
k 个决策树对第
i
i
i 个样本的预测贡献,
K
K
K 是决策树的总数,
x
i
x_i
xi 是第
i
i
i 个样本的特征向量。
在每一步
k
k
k, CatBoost 会找到一个新的决策树
f
k
f_k
fk, 以最大化损失函数的负梯度,这可
以视为解决以下优化问题:
f
k
=
arg
min
f
∑
i
=
1
N
L
(
y
i
,
y
^
i
(
k
−
1
)
+
f
(
x
i
)
)
f_k=\arg\min_f\sum_{i=1}^NL(y_i,\hat{y}_i^{(k-1)}+f(x_i))
fk=argfmini=1∑NL(yi,y^i(k−1)+f(xi))
其中,
L
L
L 是损失函数,
N
N
N 是训练样本的数量,
y
^
i
(
k
−
1
)
\hat{y}_i^{(k-1)}
y^i(k−1) 是在加入
f
k
f_k
fk 之前,使用前
k
−
1
k-1
k−1 个决策树对第
i
i
i 个样本的预测值。
2. 优化提高
CatBoost 采用了几个独特的技术来提高模型的性能和减少过拟合,包括:
(1)目标统计:这是处理分类特征的一种技术,旨在减少目标泄露和过拟合。
(2)有序提升:这是一种避免训练数据的时间顺序影响模型的技术,通过随机排列数据来提高泛化能力。
(3)边界感知梯度提升:这是一种特殊的梯度提升实现,用于优化特定于 CatBoost 的损失函数,以改进对稀疏数据和分类特征的处理。
(四)CatBoost实际操作
1. 前期准备
(1)数据格式
与LightGBM的lgb.Dataset和XGBoost的xgb.DMatrix不同,CatBoost可以直接读入Numpy数组进行处理
CatBoost 支持的几种主要数据格式:
- NumPy 数组:CatBoost 可以直接处理 NumPy 数组作为输入数据。这是最基本的数据格式,适用于已经预处理好的数值型数据。
- Pandas DataFrame:CatBoost 也可以直接处理 Pandas DataFrame。这对于包含数值型和类别型特征的数据集特别有用,因为 CatBoost 在内部对类别型特征进行优化处理,无需手动进行独热编码或其他预处理步骤。
- CatBoost Pool 类:对于更复杂的数据处理需求,CatBoost 提供了一个
Pool类。Pool类可以用来处理包含特征名称、权重和分组信息的数据集。如果您需要对数据进行高级处理(如指定特征的类型或处理缺失值),可以使用Pool类来实现。 - 文本特征:CatBoost 支持直接处理文本特征。您可以将文本列直接作为 DataFrame 的一部分传入模型,CatBoost 会自动进行文本特征的处理。
- 类别型特征:CatBoost 特别优化了对类别型特征的处理。您只需要在训练模型时通过
cat_features参数指定 DataFrame 中哪些列是类别型特征,CatBoost 会自动处理这些特征,无需进行传统的预处理步骤(如独热编码)。
(2)参数设置
loss_function损失函数,支持的有RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE,Poisson。默认RMSE。custom_metric训练过程中输出的度量值。这些功能未经优化,仅出于信息目的显示。默认None。eval_metric用于过拟合检验(设置True)和最佳模型选择(设置True)的loss function,用于优化。iterations最大树数。默认1000。learning_rate学习率。默认0.03。random_seed训练时候的随机种子l2_leaf_regL2正则参数。默认3bootstrap_type定义权重计算逻辑,可选参数:Poisson (supported for GPU only)/Bayesian/Bernoulli/No,默认为Bayesianbagging_temperature贝叶斯套袋控制强度,区间[0, 1]。默认1。subsample设置样本率,当bootstrap_type为Poisson或Bernoulli时使用,默认66sampling_frequency设置创建树时的采样频率,可选值PerTree/PerTreeLevel,默认为PerTreeLevelrandom_strength分数标准差乘数。默认1。use_best_model设置此参数时,需要提供测试数据,树的个数通过训练参数和优化loss function获得。默认False。best_model_min_trees最佳模型应该具有的树的最小数目。depth树深,最大16,建议在1到10之间。默认6。ignored_features忽略数据集中的某些特征。默认None。one_hot_max_size如果feature包含的不同值的数目超过了指定值,将feature转化为float。默认Falsehas_time在将categorical features转化为numericalfeatures和选择树结构时,顺序选择输入数据。默认False(随机)rsm随机子空间(Random subspace method)。默认1。nan_mode处理输入数据中缺失值的方法,包括Forbidden(禁止存在缺失),Min(用最小值补),Max(用最大值补)。默认Min。fold_permutation_block_size数据集中的对象在随机排列之前按块分组。此参数定义块的大小。值越小,训练越慢。较大的值可能导致质量下降。leaf_estimation_method计算叶子值的方法,Newton/ Gradient。默认Gradient。leaf_estimation_iterations计算叶子值时梯度步数。leaf_estimation_backtracking在梯度下降期间要使用的回溯类型。fold_len_multiplier folds长度系数。设置大于1的参数,在参数较小时获得最佳结果。默认2。approx_on_full_history计算近似值,False:使用1/fold_len_multiplier计算;True:使用fold中前面所有行计算。默认False。class_weights类别的权重。默认None。scale_pos_weight二进制分类中class 1的权重。该值用作class 1中对象权重的乘数。boosting_type增压方案allow_const_label使用它为所有对象训练具有相同标签值的数据集的模型。默认为False
2. 实际演示
(1)获取数据
以UCI Raisin数据集为例
导入相关包
import numpy as np
import pandas as pd
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier, Pool # 导入CatBoost分类器
import matplotlib.pyplot as plt
获取UCI Raisin数据集
# fetch dataset
raisin = fetch_ucirepo(id=850)
# data (as pandas dataframes)
train = raisin.data.features
label = raisin.data.targets
# metadata
print(raisin.metadata)
# variable information
print(raisin.variables)
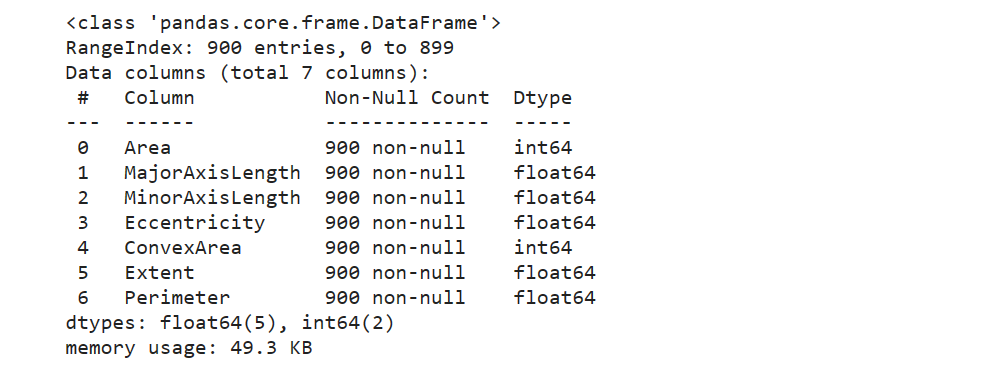
查看输入属性与输出属性
train.info()
label.info()
对object数据类型,进行字典编码
def change_object_cols(se):
value = se.unique().tolist()
value.sort()
return se.map(pd.Series(range(len(value)), index=value)).values
label['Class'] = change_object_cols(label['Class'])
label.info()
全部转换为0、1编码
label['Class'].values
(2)划分训练、测试数据集
x_train, x_test, y_train, y_test = train_test_split(train, label, test_size=0.3, random_state=0)
# 将标签向量转换为一维数组
y_train = y_train.values.ravel()
y_test = y_test.values.ravel()
(3)设定参数
与XGBoost的区别:
# 定义XGBoost的参数
params = {
'objective': 'binary:logistic', # 适用于二分类问题
'max_depth': 8, # 决策树深度
'learning_rate': 0.03, # 学习率
'eval_metric': 'logloss', # 评估指标
'num_leaves': 6, # 树的叶子节点数
'subsample': 0.8, # 每次迭代时用于训练的子样本比例
'colsample_bytree': 0.8, # 每次迭代时用于训练的特征比例
'early_stopping_rounds': 20 # 提前停止的轮数,如果验证误差不再下降
}
# 定义CatBoost的参数
params = {
'loss_function': 'Logloss', # 用于二分类问题的损失函数
'depth': 8, # 决策树深度,与 XGBoost 的 'max_depth' 相似
'learning_rate': 0.03, # 学习率,与 XGBoost 相同
# CatBoost 没有 'num_leaves' 参数,因为它自动管理叶子节点的数量
'subsample': 0.8, # 每次迭代时用于训练的子样本比例,CatBoost 中称为 'bagging_temperature'
'colsample_bylevel': 0.8, # 每个级别的特征采样比例,与 XGBoost 的 'colsample_bytree' 近似
# CatBoost 使用的是 'iterations' 和 'early_stopping_rounds' 参数,需要设置迭代次数
'iterations': 1000, # 最大迭代次数
'early_stopping_rounds': 20 # 提前停止的轮数,如果验证误差不再下降
}
CatBoost 的 subsample 参数与 XGBoost 中的不完全相同。CatBoost 中,bagging_temperature 控制了子采样的强度,但它的工作原理与 XGBoost 的 subsample 略有不同。在 CatBoost 中,较大的 bagging_temperature 值会导致更强的子采样。如果需要子样本采样,需要对 bagging_temperature 参数进行调整以获得最佳效果。
此外,CatBoost 的 colsample_bylevel 与 XGBoost 的 colsample_bytree 在概念上是相似的,但 CatBoost 还提供了 colsample_bytree 和 colsample_bynode 选项,以提供不同级别的特征采样控制。
需要注意的是,CatBoost 中没有直接等价于 XGBoost 的 num_leaves 参数,因为 CatBoost 自动管理决策树的复杂度。
(4)开始训练
可以将数据集封装成CatBoost的Pool格式,有助于控制训练过程
train_pool = Pool(x_train, y_train)
test_pool = Pool(x_test, y_test)
# 初始化 CatBoost 分类器
catboost_model = CatBoostClassifier(**params)
# 训练模型
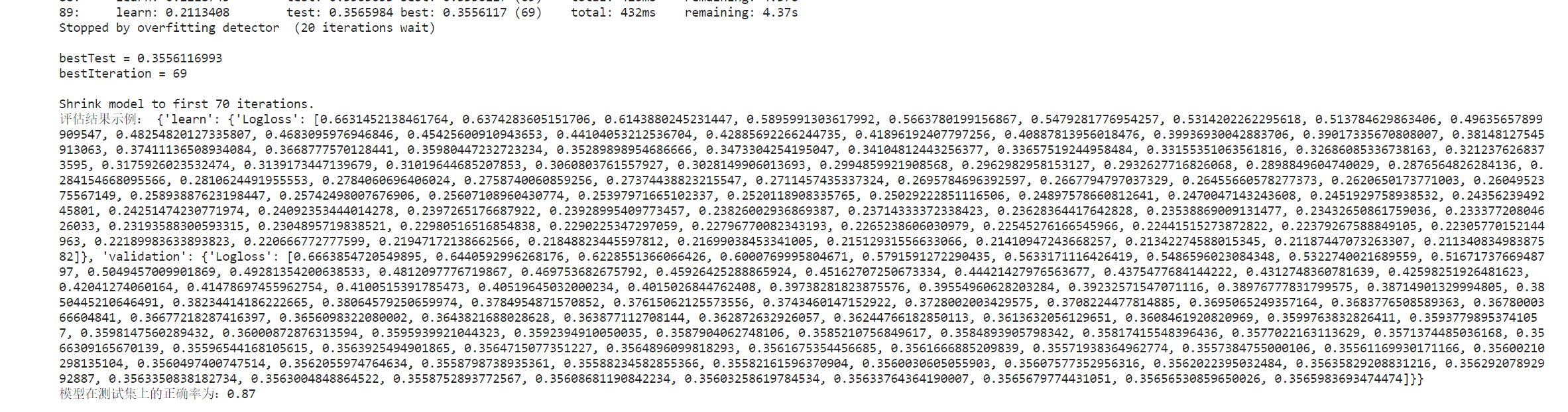
catboost_model.fit(train_pool, eval_set=test_pool, plot=True)
# 获取评估结果
eval_result = catboost_model.get_evals_result()
accuracy = catboost_model.score(x_test, y_test)
print("评估结果示例:", eval_result)
print(f"模型在测试集上的正确率为:{accuracy:.2f}")
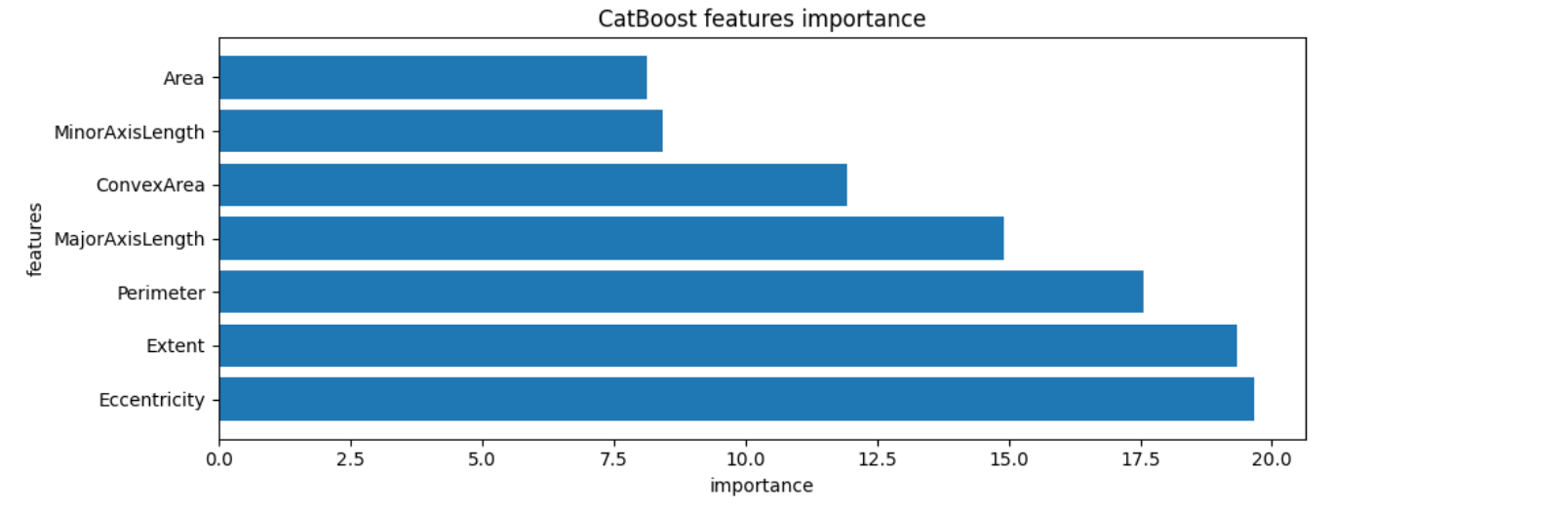
(5)可视化训练过程
- 特征重要程度
# 获取特征重要性
feature_importances = catboost_model.get_feature_importance()
# 创建特征名称列表
importance_pairs = sorted(zip(feature_names, feature_importances), key=lambda x: x[1], reverse=True)
# 解压配对列表以分别获取排序后的特征名称和重要性值
sorted_features, sorted_importances = zip(*importance_pairs)
# 创建一个条形图
plt.figure(figsize=(10, 4))
plt.barh(range(len(sorted_importances)), sorted_importances, align='center')
plt.yticks(range(len(sorted_importances)), sorted_features)
plt.xlabel('importance')
plt.ylabel('features')
plt.title('CatBoost features importance')
plt.tight_layout()
plt.show()
- SHAP值解释
SHAP具体解释可以参考知乎的这篇文章:数据科学家必备|可解释模型SHAP可视化全解析 - 知乎 (zhihu.com)
简单来讲:SHAP 值是一个实数值,可以是正数或负数。正值表示特征的该值增加了模型输出的概率(例如,在二分类问题中增加了类别为 1 的概率),而负值表示它降低了模型输出的概率。
import catboost
import shap
# 计算 SHAP 值
explainer = shap.TreeExplainer(catboost_model)
shap_values = explainer.shap_values(x_train)
# 绘制摘要图,展示最重要的特征对模型预测的影响
shap.summary_plot(shap_values, x_train)
















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









