




 本文介绍了数学建模中的随机森林算法,包括其定义、特点、与决策树的关系、构造步骤、优缺点以及在特征筛选和分类任务中的实际应用。通过实例展示了如何使用随机森林进行特征重要性评估和参数调优。
本文介绍了数学建模中的随机森林算法,包括其定义、特点、与决策树的关系、构造步骤、优缺点以及在特征筛选和分类任务中的实际应用。通过实例展示了如何使用随机森林进行特征重要性评估和参数调优。
数学建模系列_随机森林
文章目录
【前言】
数学建模备赛内容
【回顾】
【简介】
什么是随机森林
随机森林是一种集成学习方法,通过组合多个决策树来解决分类和回归问题。每棵树都是根据随机选择的训练数据和特征构建的,最终的预测结果是基于多个树的投票(分类问题)或平均(回归问题)得出的。随机森林具有良好的泛化能力、鲁棒性和高效性,适用于各种机器学习任务。
【正文】
(一)理论部分
1. 随机森林的定义与特征
定义:
本质属于集成学习方法、由多棵决策树组成,每棵决策树都是一个分类器,将多个分类器的结果进行投票。

特征:
(1)具有极高的准确率
(2)能够使用在大数据上
(3)不需要降维
(4)能够评估重要性

2. 集成学习
(1)定义
集成学习(Ensemble Learning)是一种机器学习技术,它旨在通过结合多个弱学习器(或基本模型)的预测结果来提高整体预测的准确性和鲁棒性。集成学习的核心思想是将多个模型的意见汇总起来,以产生更强大的集成模型,从而降低过拟合的风险,提高泛化能力,并在各种机器学习任务中表现出色。

(2)特点与原理
- 弱学习器:集成学习通常使用弱学习器作为基本模型,这些模型可能相对简单,其性能略高于随机猜测。弱学习器可以是决策树、逻辑回归、神经网络的一层等。
- 多样性:集成学习通过确保每个弱学习器具有一定程度的多样性,即它们的预测错误不完全重叠。这可以通过不同的训练数据、不同的特征子集、不同的模型或不同的训练算法来实现。
- 集成方法:集成学习采用不同的集成方法来结合弱学习器的预测结果。常见的集成方法包括投票法(Voting)、Bagging、Boosting、随机森林等。每种方法都有不同的组合策略,例如平均、投票、加权平均等。
- 降低方差:通过将多个模型的预测结果结合起来,集成学习可以降低模型的方差,从而提高模型的鲁棒性。这有助于减少模型对训练数据中的噪声和变化的敏感性。
- 提高性能:通过集成多个弱学习器的意见,集成学习可以显著提高整体性能,特别是在复杂任务和大规模数据集上。
- 适用性广泛:集成学习可用于各种机器学习任务,包括分类、回归、特征选择、异常检测等。
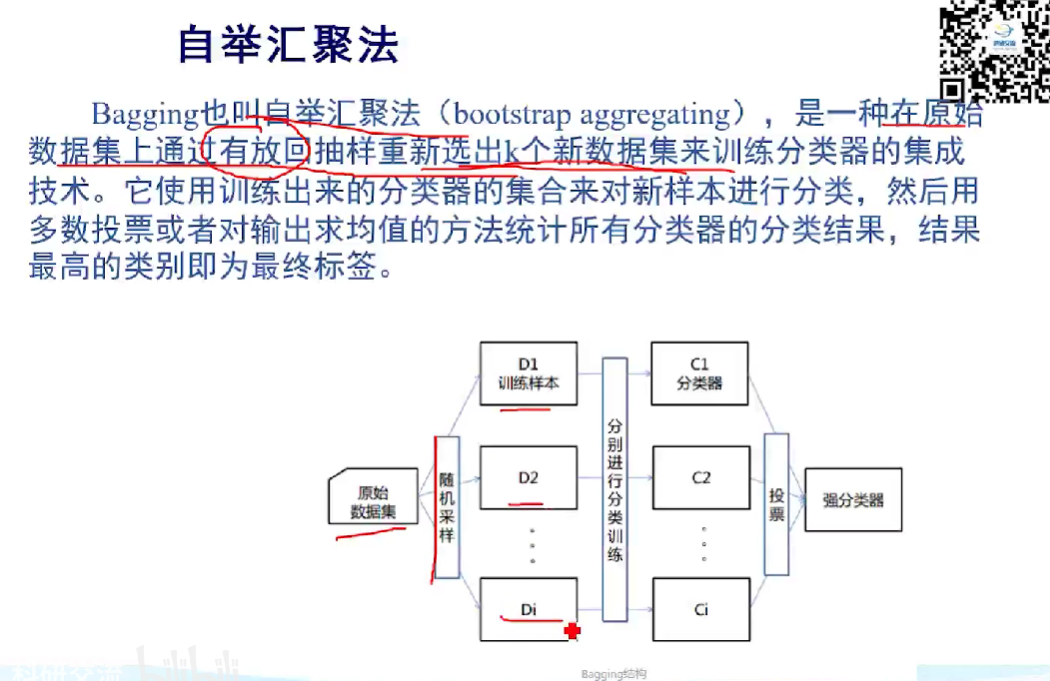
补充:自举汇聚法(Bagging)
Bagging的步骤如下:
Bootstrap 抽样:从原始训练数据集中随机有放回地抽取多个子数据集,每个子数据集的大小通常与原始数据集相同,但它们的样本是随机选择的。这意味着一些样本可能在多个子数据集中出现,而一些样本可能根本不出现。
独立模型训练:使用每个子数据集独立地训练一个弱学习器或基本模型(通常是决策树、逻辑回归等)。由于每个子数据集都是随机抽样的,因此每个模型都是基于不同的样本集训练的,具有一定的差异性。
预测组合:对于分类问题,Bagging 通过对多个子模型的分类结果进行多数投票来确定最终的分类结果。对于回归问题,Bagging 通过对多个子模型的回归结果进行平均来得出最终的回归值。
Bagging 的优势包括:
- 减少模型的方差:通过组合多个模型的预测结果,Bagging 可以减少单个模型的方差,提高模型的鲁棒性和泛化能力。
- 防止过拟合:由于每个子模型都是在不同的数据子集上训练的,Bagging 有助于减少模型对训练数据中的噪声和局部特征的过拟合。
- 并行化:每个子模型的训练是独立的,因此 Bagging 很容易并行化,提高了训练效率。
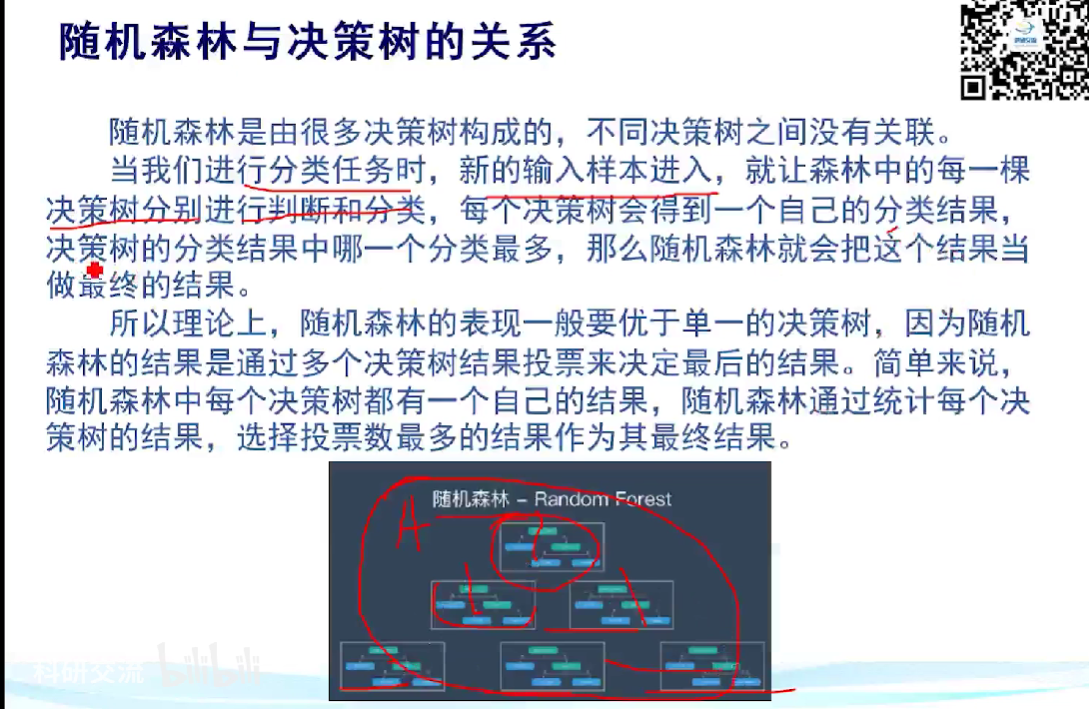
3. 随机森林与决策树的关系
随机森林由多个决策树组成,不同决策树之间没有关系,通过统计多个决策树并投票得到最终结果。
回顾:数学建模系列_决策树
4. 构造随机森林的步骤
(1)主要步骤
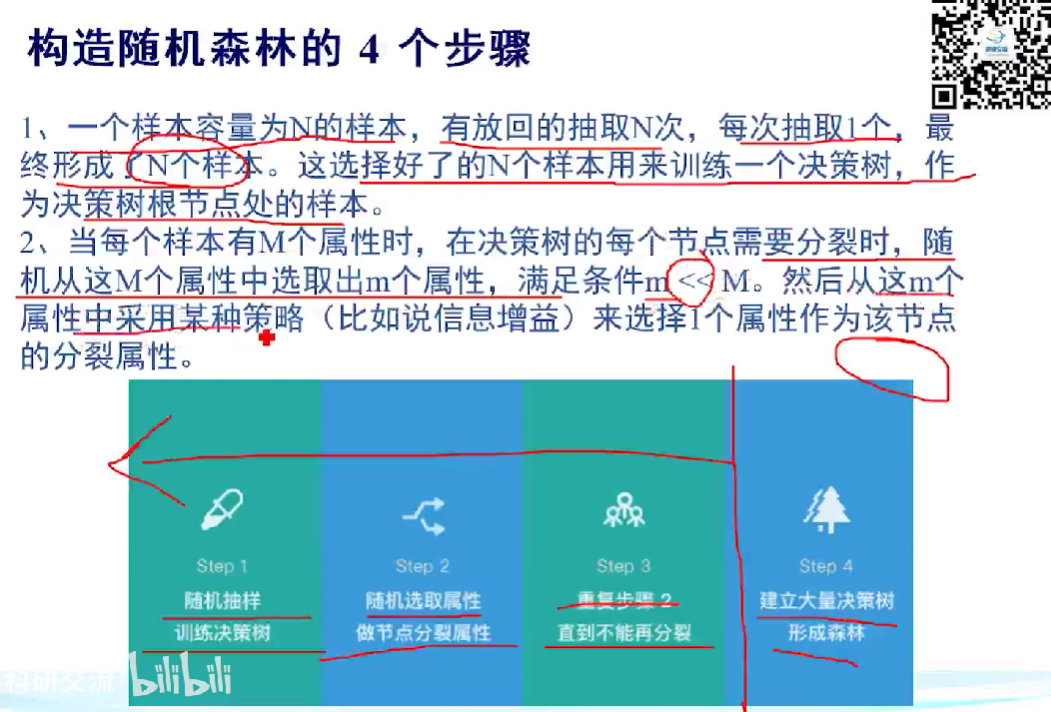

(2)详细步骤
- 收集训练数据集:首先,收集包含特征和相应标签的训练数据集。这些数据将用于随机森林的训练。
- Bootstrap 抽样:从训练数据集中使用自助法(Bootstrap Sampling)随机有放回地抽取多个子数据集。这些子数据集的大小通常与原始数据集相同,但它们的样本是随机选择的,有些样本可能在多个子数据集中出现,而有些可能不出现。
- 构建决策树:针对每个子数据集,独立地构建一棵决策树。通常使用特定的决策树算法(如CART)来训练每棵树,但在这里的关键是,每个决策树只使用子数据集的一部分样本和一部分特征进行训练。这种随机性确保了每棵树都是不同的。
- 集成多棵树:在构建足够多的决策树后,将它们组合起来形成随机森林。对于分类问题,通常采用多数投票法(Majority Voting),即通过统计每棵树的分类结果来确定最终的分类结果。对于回归问题,通常采用平均法,即取多棵树的回归结果的平均值。
- 评估性能:使用验证数据集或交叉验证等方法来评估随机森林的性能。可以使用一些指标如准确度、均方根误差(RMSE)等来评估模型的性能。
- 调整参数:根据性能评估的结果,可以调整随机森林的参数,如树的数量、每棵树的最大深度、特征采样比例等,以优化模型的性能。
- 使用随机森林:一旦构建好随机森林模型并满意性能,就可以将其应用于新的未见数据进行分类或回归预测。
- 可选的特征重要性评估:随机森林可以提供特征的重要性评估,帮助识别哪些特征对于模型的预测最重要。这可以用于特征选择或问题理解。
5. 随机森林的优缺点:
(1)优点:
- 无需降维、无需特征筛选
- 可以判断特征重要程度
- 容易并行处理
(2)缺点:
- 对于不平衡的数据,容易过拟合
- 取值划分较多的属性会对随机森林产生较大的影响
例如:身份证号/手机号码,取值划分较大且没有依据,随机森林对此类数据产出的属性权值是不可信的。
(二)实践操作
1. 应用于特征筛选
随机森林可以对特征的重要性进行评估

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3247
3247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









