







【前言】
第一次尝试此类比赛,踩了很多坑,也有很多地方还可以改进,最终得分也只有0.76,如果您愿意分享您宝贵的经验和知识,我将不胜感激。
【比赛简介】
“Titanic - Machine Learning from Disaster” 是 Kaggle 平台上的一个知名比赛,参与者需使用机器学习模型预测哪些乘客在泰坦尼克号沉船事故中幸存。比赛提供了包含各种特征的乘客数据,如性别、年龄、舱位等。参赛作品将根据预测幸存结果的准确性进行评估。
【正文】
(一)数据获取
通过命令行的方式
1. cmd安装kaggle包
pip install kaggle
2. 获取kaggle.json
在kaggle的个人主页,点击account,在API处点击create New API token创建一个kaggle.json文件
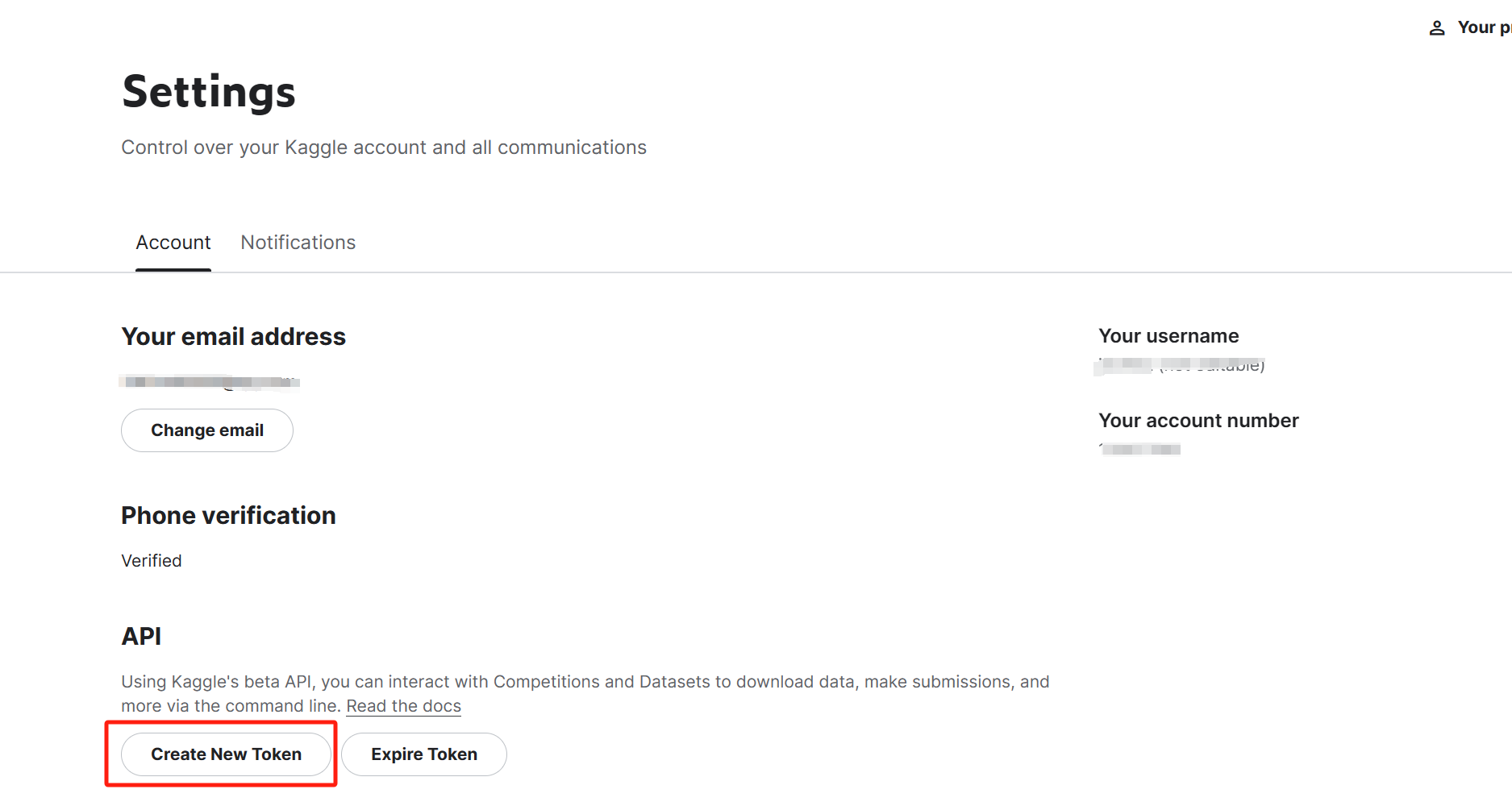
将kaggle.json文件移动到.kaggle文件夹内,一般会存放在C盘用户主目录内。
若此时没有.kaggle文件夹,则需在命令行中输入
kaggle competitions list
不需要管结果如何,此时再刷新C盘,即可发现生成的.kaggle文件夹。
即可完成个人账户与命令行下载的关联过程
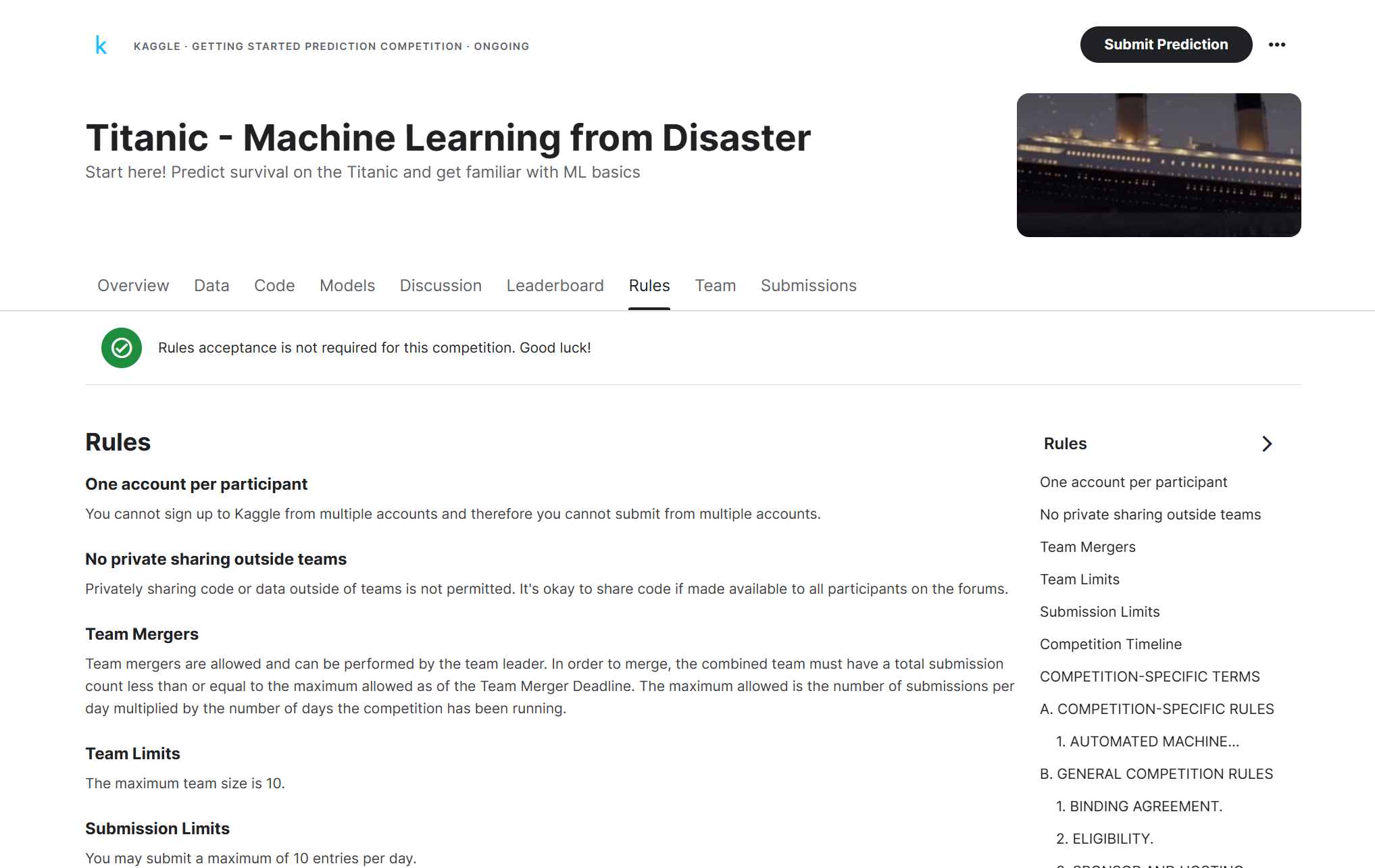
3. 同意比赛的规则
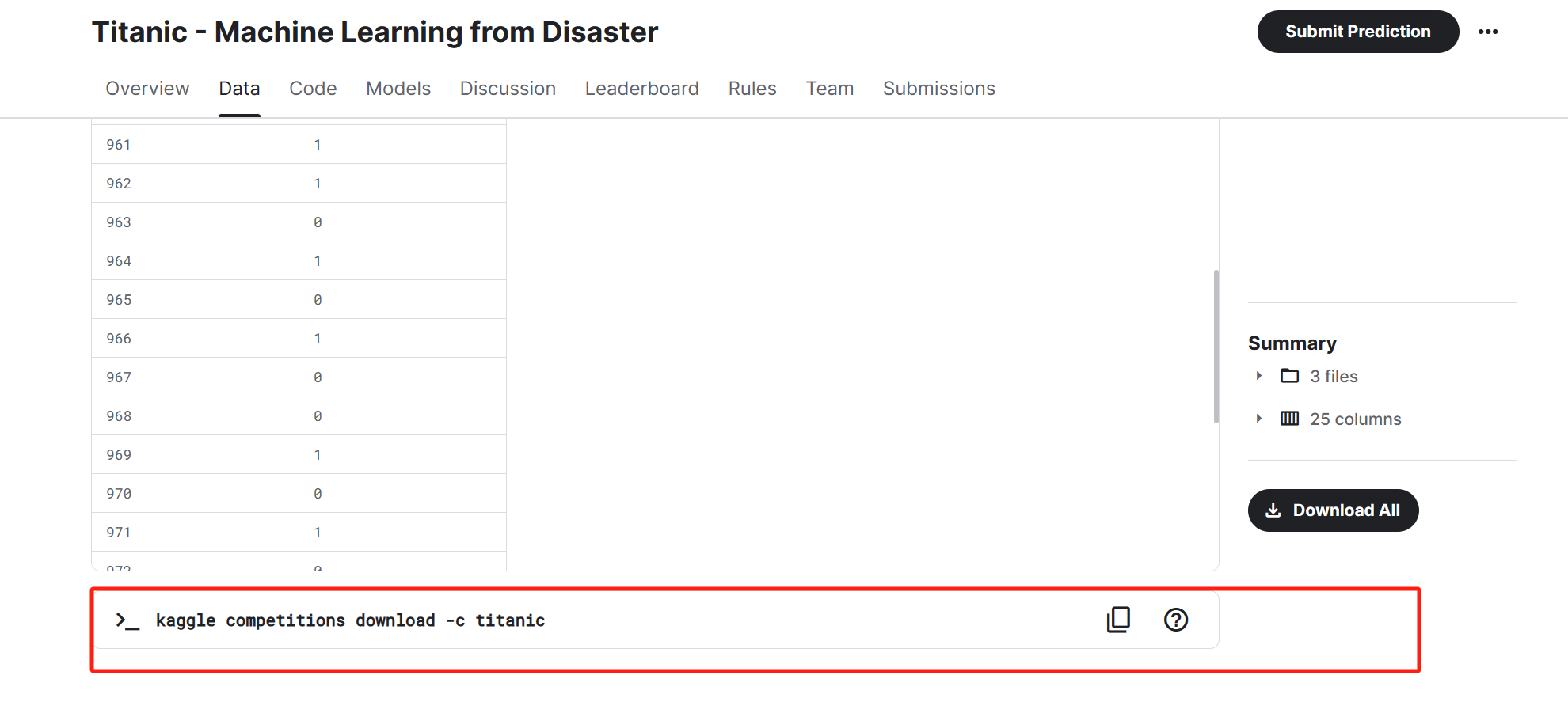
4. 通过命令行下载比赛数据
修改默认下载路径:
命令行输入
kaggle config set -n path -v <路径>
5. 直接使用kaggle平台进行处理
新建一个notebook
在右侧界面添加数据集

选择Titanic数据集并导入
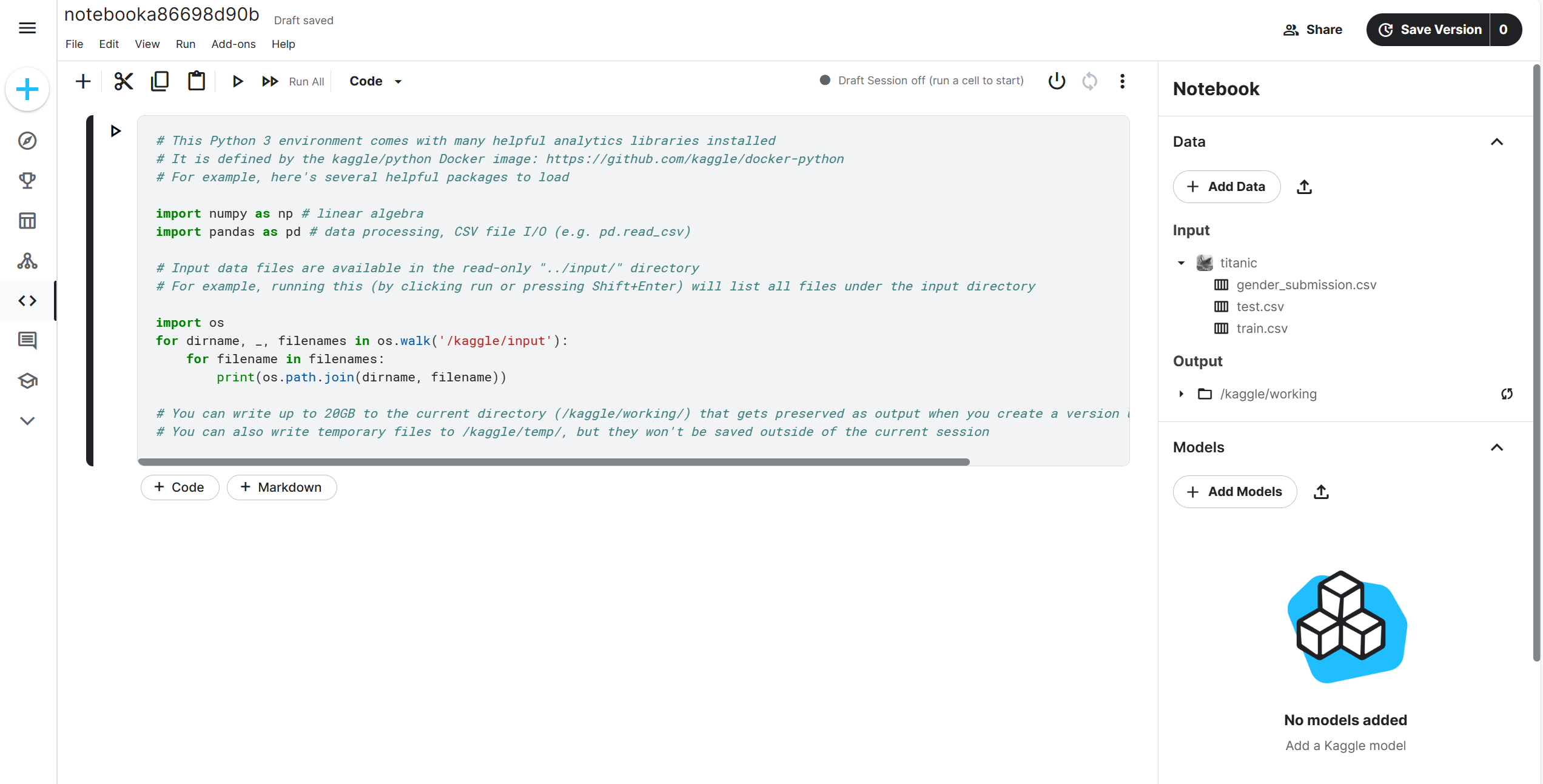
已导入的数据集会存放在input文件夹下,具体路径为
/kaggle/input/titanic/train.csv
(二)数据分析
1. 初步分析
读取文件
train = pd.read_csv("/kaggle/input/titanic/train.csv", header=0)
test = pd.read_csv("/kaggle/input/titanic/test.csv", header=0)
查看前五行
train.head(5)
test.head(5)

查看形状(数据量、属性个数)
(train.shape, test.shape)
# ((891, 12), (418, 11))
2. 数据质量分析
(1)判断唯一索引是否有重复值
train['Name'].nunique() == train.shape[0],test['Name'].nunique() == test.shape[0]
Out:
(True, True)
(2)缺失值检验
train.isnull().sum()

test.isnull().sum()

(3)异常值检验
cols = train.columns.values.tolist()
cols.remove('Name')
cols.remove('PassengerId')
cols.remove('Ticket')
cols.remove('Cabin')
print(cols)
# remove() 方法会直接在原始列表上删除指定的元素,并且它没有返回值(返回值为 None)
[‘Survived’, ‘Pclass’, ‘Sex’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’, ‘Embarked’]
循环打印各个属性的直方图
sns.set()
for col in cols:
statistic = train[col].describe()
print(statistic)
plt.figure(figsize=(6, 6))
sns.histplot(train[col], kde=True)
plt.title(f'Histogram of {col}')
plt.show()
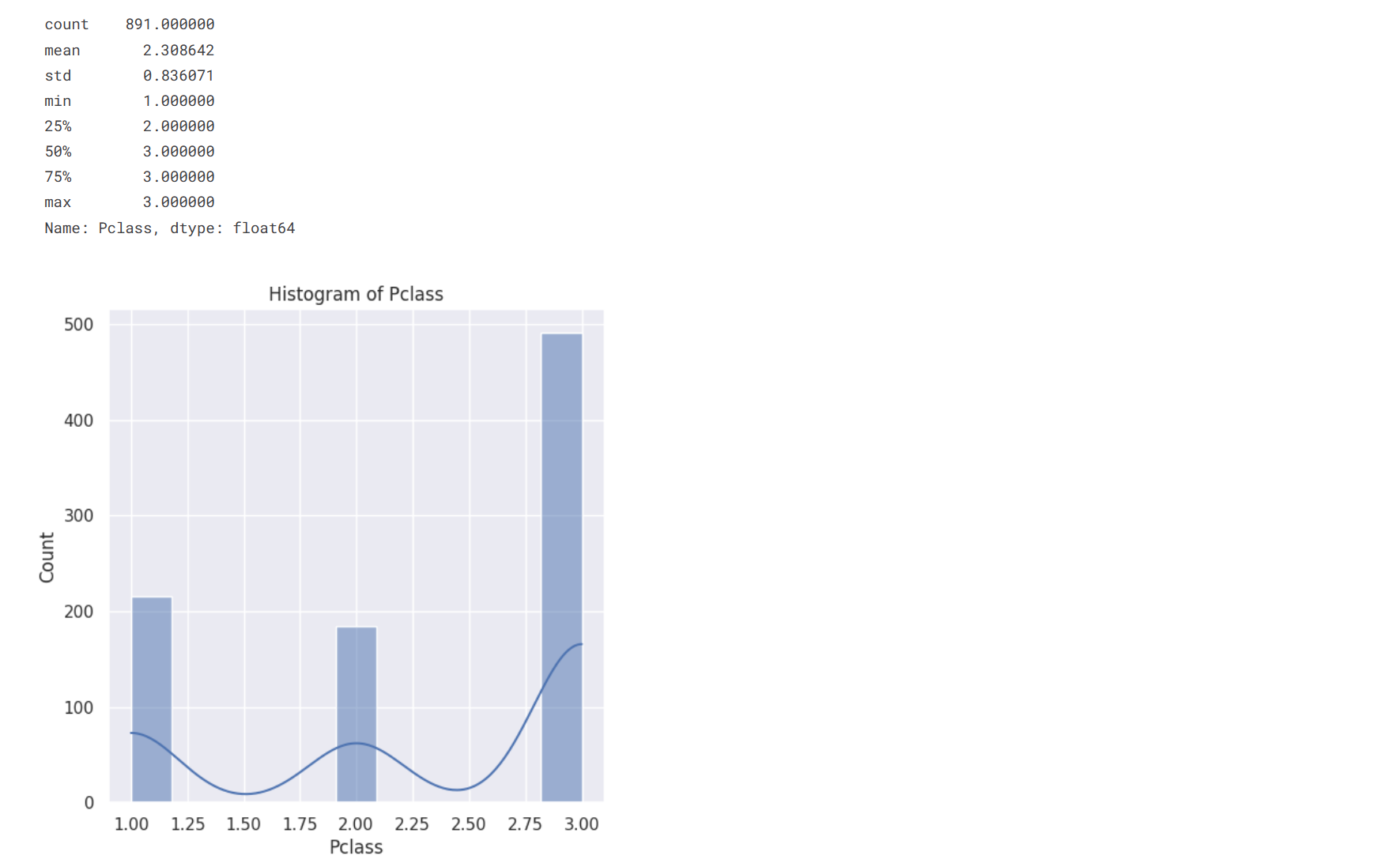
经过对直方图的观察后,初步判断没有将对实验产生影响的异常值
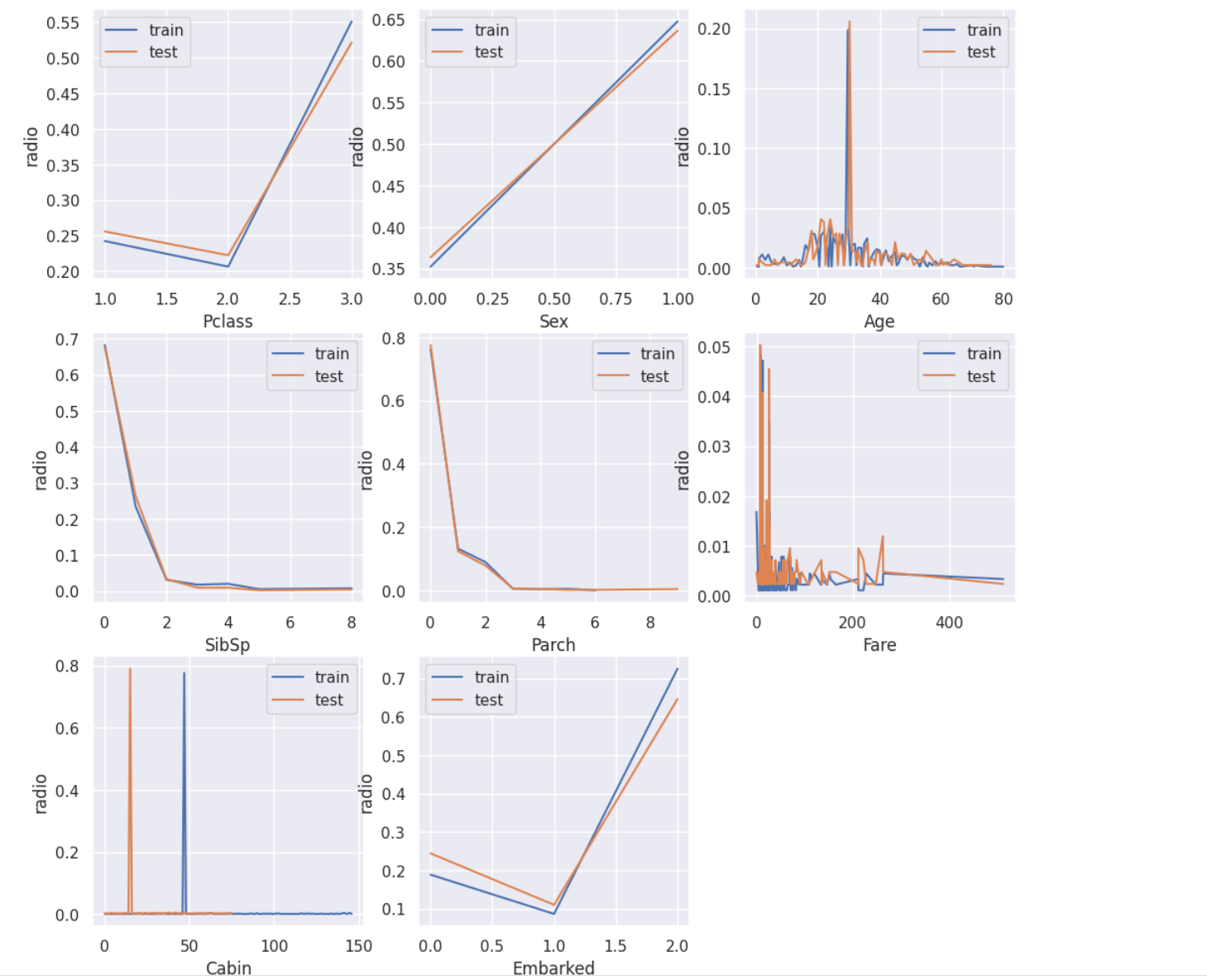
(4)规律一致性检测
判断test表与train表是否出自同一分布
train_count = train.shape[0]
test_count = test.shape[0]
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']
i = 1
plt.figure(figsize=(18, 18))
for feature in features:
plt.subplot(3, 3, i)
(train[feature].value_counts().sort_index()/train_count).plot()
(test[feature].value_counts().sort_index()/test_count).plot()
plt.legend(['train', 'test'])
plt.xlabel(feature)
plt.ylabel('radio')
plt.show
i+=1
发现除了cabin属性外,train表与test表在其余属性的分布相近,因此我在建模时没有使用cabin属性
(三)数据预处理
1. 缺失值填充
train.isnull().sum()
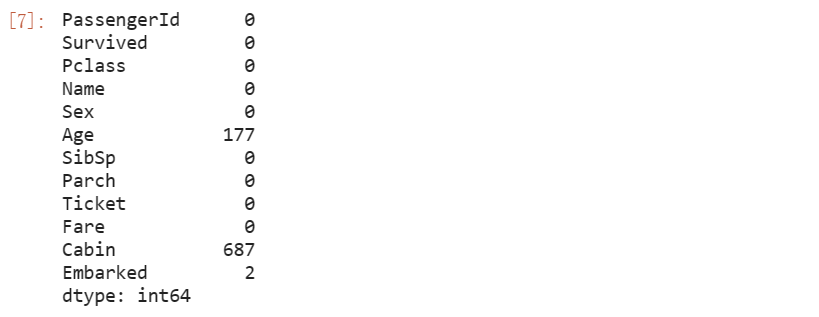
将train、test表的Age字段填充为均值,Cabin字段填充为众数,将train表的Embarked字段填充为众数、test表的Fare字段填充为均值
train['Age'] = train['Age'].fillna(train['Age'].mean())
test['Age'] = test['Age'].fillna(test['Age'].mean())
train['Cabin'] = train['Cabin'].fillna(train['Cabin'].mode()[0])
test['Cabin'] = test['Cabin'].fillna(test['Cabin'].mode()[0])
train['Embarked'] = train['Embarked'].fillna(train['Embarked'].mode()[0])
test['Fare'] = test['Fare'].fillna(test['Fare'].mean())
train.isnull().sum()

2. 将object数据类型进行字典编码
train.info()
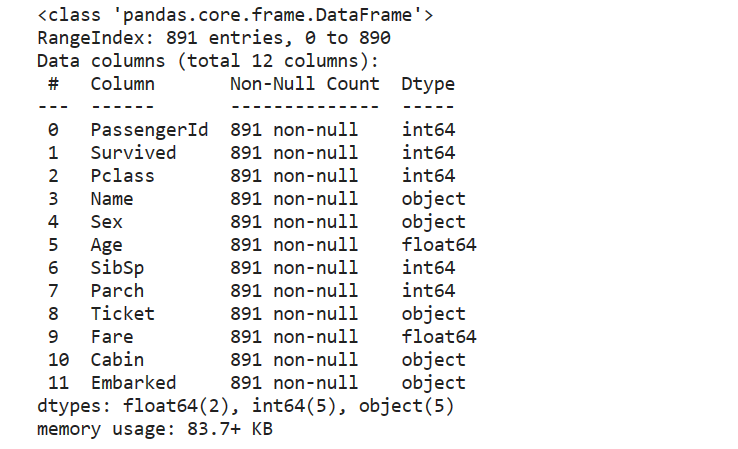
发现Name、Sex、Ticket、Cabin、Embarked字段为object类型,因为我们不使用Name作为判断的条件,因此将除了Name以外的字段进行字典编码
def change_object_cols(se):
value = se.unique().tolist()
value.sort()
return se.map(pd.Series(range(len(value)), index=value)).values
for col in ['Sex', 'Ticket', 'Cabin', 'Embarked']:
train[col] = change_object_cols(train[col])
test[col] = change_object_cols(test[col])
再次查看数据类型
train.info()
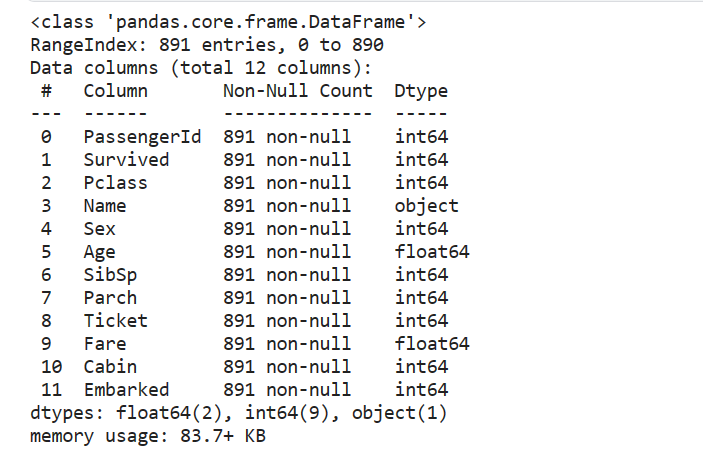
(四)保存数据
train.to_csv('/kaggle/working/train_pre.csv', index=False)
test.to_csv('/kaggle/working/test_pre.csv', index=False)
(五)建模过程
1. 导入必要的包
import gc
import pandas as pd
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
2. 读取已经处理好的数据
因为kaggle平台一次性最多只能运行12h,而且中途会检测你人是否还在,因此最好将数据预处理、数据清晰与建模分析的过程分开来,防止因中断内核导致的内存释放。
train = pd.read_csv('/kaggle/input/titanic-dataset/train_pre.csv', header=0)
test = pd.read_csv('/kaggle/input/upload2/test_pre (1).csv', header=0)
train.head(5)

可以看到经过预处理后,原先的object字段已经全部转换为字典编码,可以被模型读入。
3. 特征工程
通用组合特征,统计不同离散特征在不同取值水平下、不同连续特征取值之和创建的特征,并根据PassengerId进行分组求和。通过该方法创建的数据集,不仅能够尽可能从更多维度表示每个Passenger的情况,同时也能够顺利和训练集/测试集完成拼接,从而带入模型进行建模。
(1)选择离散、连续字段
numeric_cols = ['Age','Fare']
category_cols = []
for col in train.columns:
if col not in numeric_cols:
category_cols.append(col)
category_cols.remove('PassengerId')
category_cols.remove('Name')
category_cols.remove('Survived')
category_cols.remove('Cabin')
id_cols = ['PassengerId', 'Name']
因为不使用PassengerId、Name、Cabin进行建模,因此我最终选定的离散字段是’Pclass’, ‘Sex’, ‘SibSp’, ‘Parch’, ‘Ticket’, ‘Embarked’,连续字段是’Age’,‘Fare’。
(2)特征拼接
features = {}
people_all = pd.concat([train['PassengerId'], test['PassengerId']]).values.tolist()
for people in people_all:
features[people] = {}
columns = train.columns.tolist()
idx = columns.index('PassengerId')
category_cols_index = [columns.index(col) for col in category_cols]
numeric_cols_index = [columns.index(col) for col in numeric_cols]
s = time.time()
num = 0
for i in range(train.shape[0]):
va = train.loc[i].values
people = va[idx]
for cate_ind in category_cols_index:
for num_ind in numeric_cols_index:
col_name = '&'.join([columns[cate_ind], str(va[cate_ind]), columns[num_ind]])
features[people][col_name] = features[people].get(col_name, 0) + va[num_ind]
num+=1
if num % 100 ==0:
print(time.time()-s, 's')
(3)格式转换
df = pd.DataFrame(features).T.reset_index()
cols = df.columns.tolist()
df.columns = ['PassengerId'] + cols[1:]
df.isnull().sum()

df
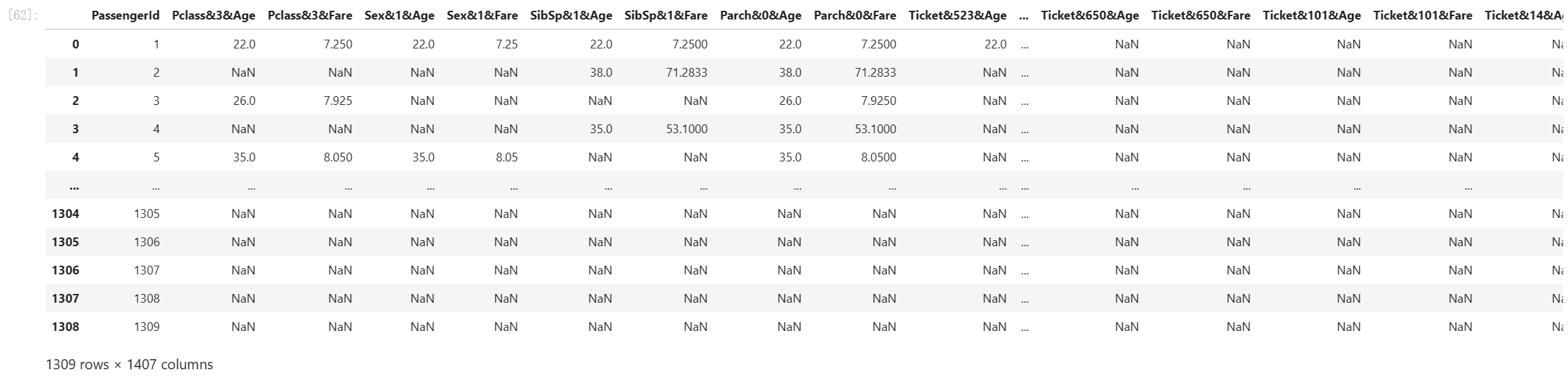
我们发现有很多属性是有很多缺失值的,需要在后续进行处理
(4)与train/test表合并
train_dict = pd.merge(train, df, how='left', on='PassengerId')
test_dict = pd.merge(test, df, how='left', on='PassengerId')
4. 特征筛选
我使用的是一种基础而通用的特征筛选的方法:基于皮尔逊相关系数的Filter方法进行特征筛选。
features = train_dict.columns.tolist()
features.remove('PassengerId')
features.remove('Name')
features.remove('Survived')
features.remove('Cabin')
featureSelect = features[:]
corr = []
for fea in featureSelect:
corr.append(abs(train_dict[[fea, 'Survived']].fillna(0).corr().values[0][1]))
se = pd.Series(corr, index=featureSelect).sort_values(ascending=False)
se
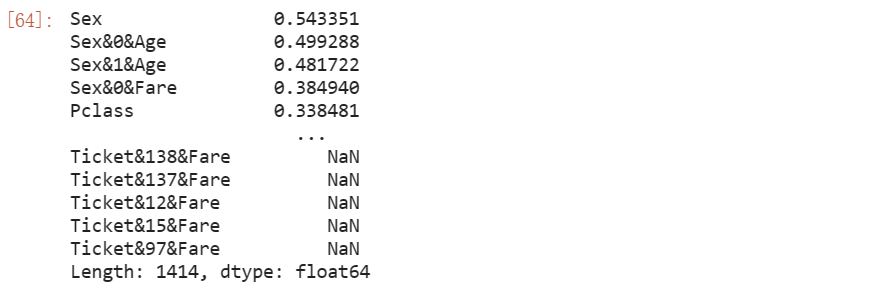
选择相关系数最大的前70个特征进行建模
feature_select = ['PassengerId'] + se[:70].index.tolist()
将survived属性与选择出来的70个属性作为最终我们建模使用的属性。
同时将缺失值赋予0(可能还有更好的方法,目前没想到┭┮﹏┭┮)
train = train_dict[feature_select + ['Survived']]
test = test_dict[feature_select]
train = train.fillna(0)
test = test.fillna(0)
5. 建模过程
使用随机森林分类器进行建模
(1)RandomizedSearchCV 全局调优
RandomizedSearchCV 的参数空间
n_estimators: 树的数量。这是随机森林中决策树的数量。增加树的数量通常会提高模型的性能和稳健性,但也会增加计算成本和时间。min_samples_leaf: 叶节点最少样本数。这是每个叶子节点(树的最底部节点)所需的最小样本数。增加这个参数的值会使模型变得更加保守,可以减少过拟合的风险。min_samples_split: 分裂内部节点所需的最小样本数。这是树在继续分裂一个内部节点之前所需的最小样本数。增加这个值可以防止模型学习过于复杂的树结构,也有助于防止过拟合。max_depth: 树的最大深度。这是树可以增长的最大深度。限制树的深度有助于减少模型的复杂性,避免过拟合。max_features: 寻找最佳分割时要考虑的特征数量。它决定了在分割一个节点时,随机森林会考虑多少个特征。可以是整数(直接指定数量),浮点数(作为总特征数的比例),“auto”(等于sqrt(n_features)),“sqrt”(同“auto”),“log2”(等于log2(n_features))。class_weight: 类别的权重。这个参数用于处理类别不平衡的问题。如果设置为“balanced”,算法将自动根据输入数据中的类频率为每个类别分配权重。“balanced_subsample” 类似于 “balanced”,但是权重是基于每棵树的数据样本计算的,而不是整个数据集。
有关RandomizedSearchCV的参数设置可能还有更大的改进空间,n_iter是否可以再大些?
# 在建模时,去除PassengerId与Survived字段
features = train.columns.tolist()
features.remove('PassengerId')
features.remove('Survived')
# 定义随机搜索的参数范围
random_grid = {
'n_estimators': np.arange(1, 20, 1),
'max_features': ['auto', 'sqrt'],
'max_depth': np.arange(1, 10, 1),
'min_samples_split': np.arange(30, 100, 5),
'min_samples_leaf': np.arange(30, 100, ),
'class_weight': ['balanced', 'balanced_subsample']
}
# 初始化随机森林分类器
rf = RandomForestClassifier()
# 随机搜索对象
rf_random = RandomizedSearchCV(rf, random_grid, n_iter=400, cv=2, verbose=2, n_jobs=-1, scoring='accuracy')
# 拟合随机搜索模型
rf_random.fit(train[features].values, train['Survived'].values)
(2)查看最佳参数组合
# 查看最佳参数组合
print(rf_random.best_score_)
print(rf_random.best_params_)

(3)GridSearchCV局部调优
# 假设 RandomizedSearchCV 的输出为 rf_random.best_params_ = {'n_estimators': 18, 'min_samples_split': 70, ...}
param_grid = {
'n_estimators': [17, 18, 19],
'max_features': [rf_random.best_params_['max_features']],
'max_depth': [rf_random.best_params_['max_depth'] - 1, rf_random.best_params_['max_depth'], rf_random.best_params_['max_depth'] + 1],
'min_samples_split': [rf_random.best_params_['min_samples_split'] - 1, rf_random.best_params_['min_samples_split'], rf_random.best_params_['min_samples_split'] + 1],
'min_samples_leaf': [rf_random.best_params_['min_samples_leaf'] - 1, rf_random.best_params_['min_samples_leaf'], rf_random.best_params_['min_samples_leaf'] + 1],
'class_weight': [rf_random.best_params_['class_weight']]
}
# 网格搜索对象
rf_grid = GridSearchCV(rf, param_grid, cv=2, n_jobs=-1, verbose=2, scoring='accuracy')
# 拟合网格搜索模型
rf_grid.fit(train[features].values, train['Survived'].values)
(4)查看最佳参数组合
# 查看最佳参数组合
print(rf_grid.best_score_)
print(rf_grid.best_params_)

提升了那么一丢丢。
6. 提交答案
(1)查看该参数组合在test表上的输出
rf_grid.best_estimator_.predict(test[features])

(2)按照提交格式保存输出文件
提交文件由PassengerId与Survived字段组成
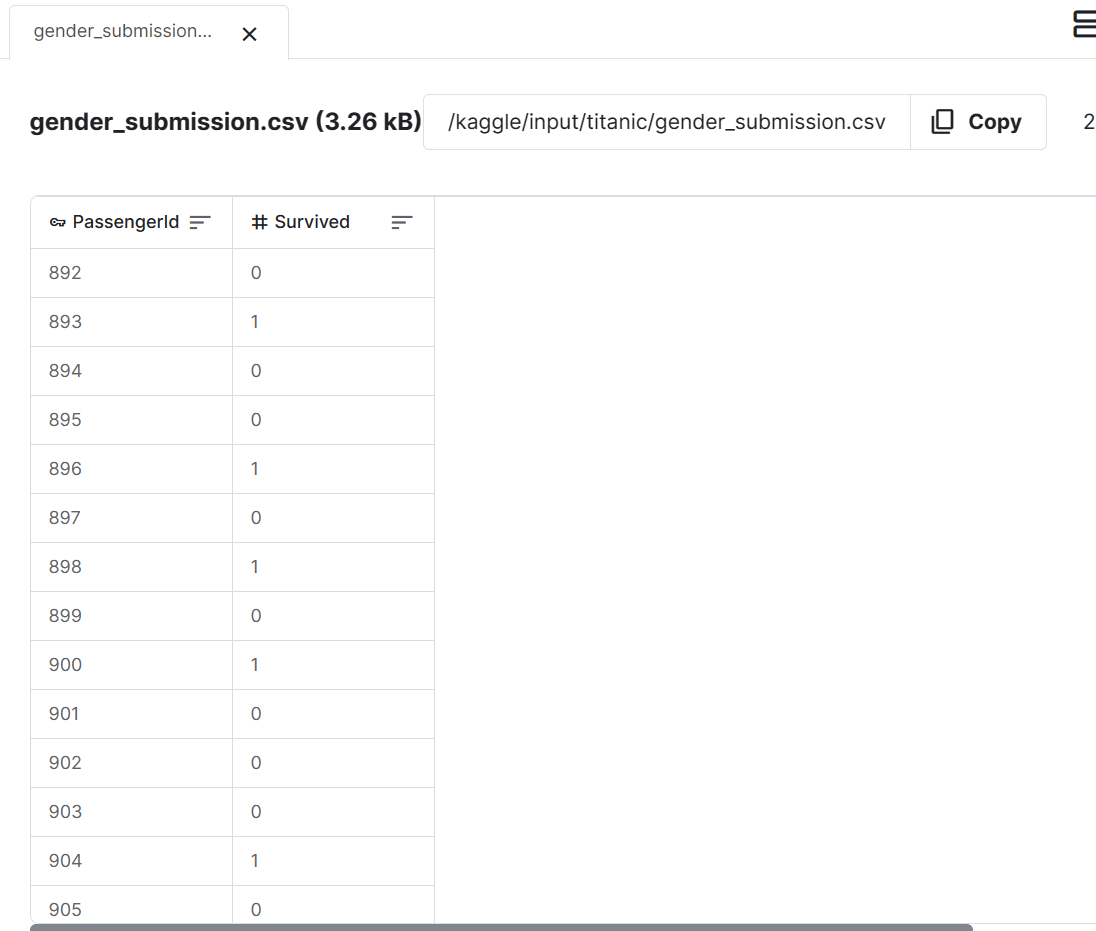
按照提交格式要求保存输出文件
test['Survived'] = rf_grid.best_estimator_.predict(test[features])
test[['PassengerId', 'Survived']].to_csv('/kaggle/working/submission_randomforest.csv', index=False)
在比赛页面上提交输出文件
查看自己的分数以及排名
排名一万多哈哈哈哈哈。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









