






YOLOv3
本文的学习视频是:yolov3理论讲解_哔哩哔哩_bilibili
YOLOv3没有很多的创新点
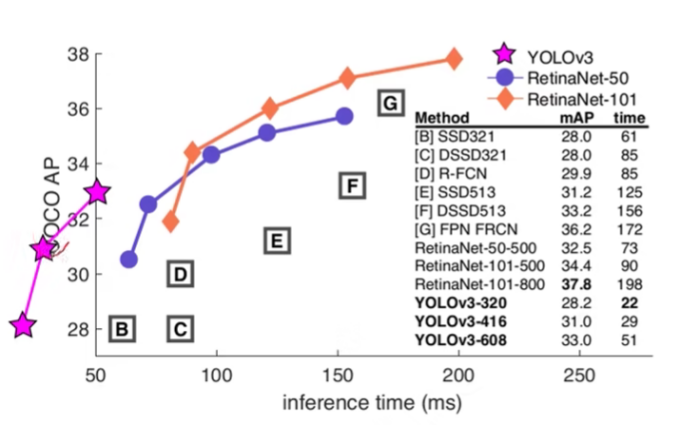
YOLOv3与当前的一系列目标检测网络在COCO数据集的准确率对比,可以看出,相比于其他网络,YOLOv3的速度是非常快的,横坐标是推理时间,YOLOv3的推理速度是最快的,但是从mAP指标来看,它的准确率其实没有那么地高
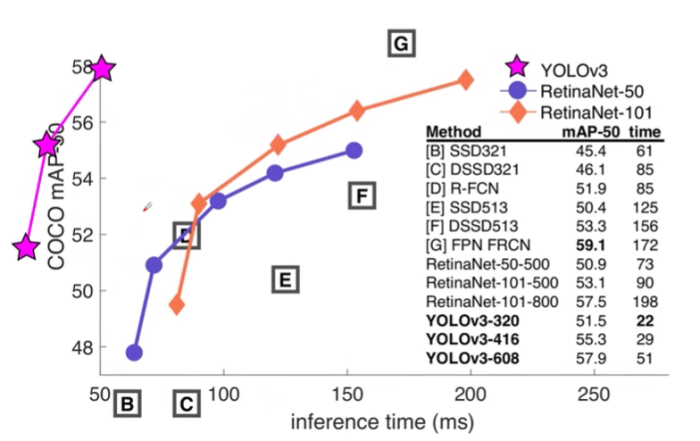
纵坐标是IoU等于0.5时候的mAP,此时它对应的就是Pasco VOC的一个mAP了,通过这个指标来看,我们发现YOLOv3的检测效果对比其他而言有很大的优势,除了非常快以外,它的准确度也非常地高
接下来进入YOLOv3的网络讲解部分
Darknet-53
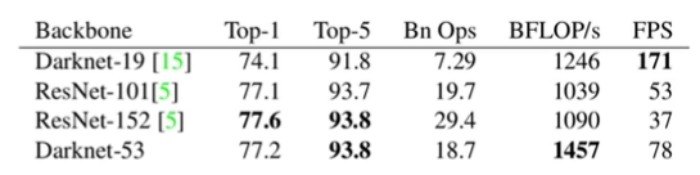
首先YOLOv3的第一个改进之处就是修改了backbone,YOLOv2采用的是Darknet-19的网络,从下面的图可以看出,Darknet-19在ImageNet数据集上的Top-1是74.1%,检测速度是每秒钟可以推理171张图片,对比参考的两个网络是ResNet-101和ResNet-152,YOLOv3中重新训练的backbone,也就是Darknet-53,它的Top-1达到了77.2%,相比于Darknet-19有很大提升,与ResNet-152基本持平了,Top-5是一样的,它的检测速度达到了78FPS,也就是说Darknet-53与ResNet-152是基本持平的,但是检测速度是ResNet-152的两倍,所以YOLOv3的backbone也是非常强劲的
为什么叫Darknet-53,和Darknet-19一样,因为有53个卷积层,2+(1x2)+1+(2x2)+1+(8x2)+1+(8x2)+1+(4x2)+1=53,黑框里面是残差网络,后面讲
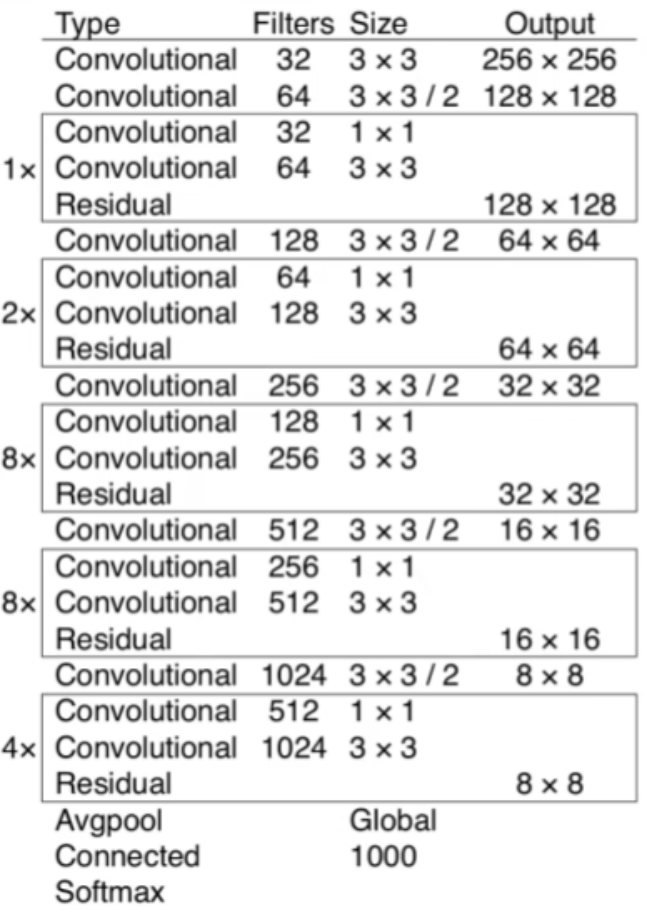
为什么Darknet-53比ResNet-152这种更深层的网络更好呢?Darknet-53是没有最大池化层的,所有的下采样基本上都是通过卷积层来实现的,比如第二个卷积,它的步长是等于2的,通过这个卷积后,它的高和宽就缩小为原来的一半了,同理,下面的几个卷积层也是这样,通过卷积层对特征图的尺度压缩的,所以这些卷积层替代原来的最大池化下采样层,才带来了检测效果上面的提升,它的速度为什么这么快呢?因为对比ResNet网络,可以看出它的卷积层比Darknet-53的卷积层多很多
这里的卷积层不单是普通的卷积层,而是卷积加上BN,再加上激活函数的组合,使用BN之后,卷积层的参数是没有偏置这个参数的
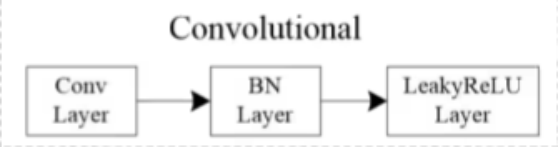
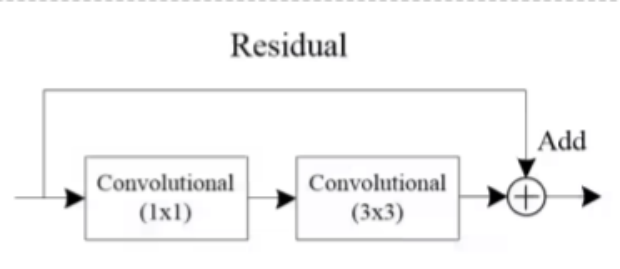
Darknet-53中每个方框标出的部分其实对应的是一个残差结构,它的主分支上就是一个1x1的卷积层,然后再通过一个3x3的卷积层,从输入引过来,和主干支的输出进行相加,得到最终的一个输出
多尺度预测和特征金字塔网络结构
YOLOv3模型结构的部分
YOLOv3会生成三个预测特征图,每个预测特征图上会使用三种尺度,这些尺度同样是使用K-means聚类算法得到的,最终共有9种尺度,如下图

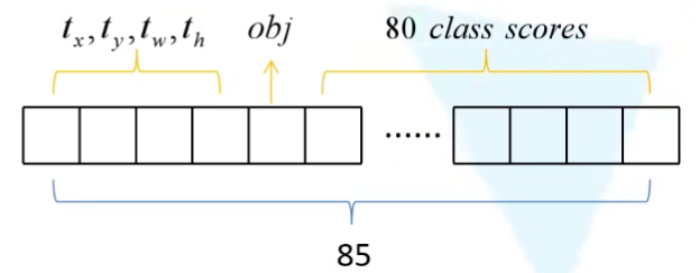
最终会预测出NxNx[3x(4+1+80)]个参数,N代表预测特征层的大小,预测特征层上,每个会预测出三个尺度,每个尺度上面会预测(4+1+80)个参数,在COCO数据上面预测的,有80个类别,对于每一个锚框而言,有四个偏移参数,还有一个置信度参数
YOLOv3的模型图如下图所示,
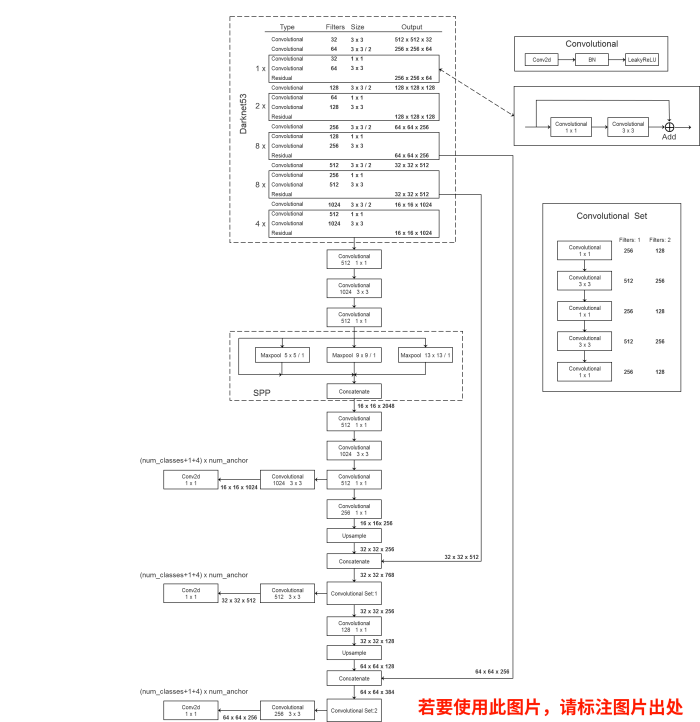
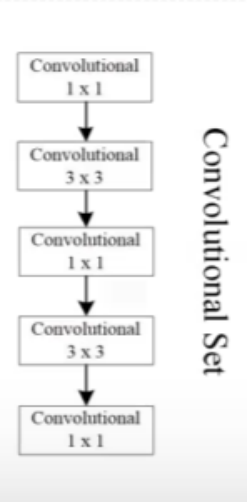
首先从Darknet-53(去掉平均池化层和全连接层)输出之后得到的13x13的特征图,然后通过一个Convolutional Set,它是将五个卷积层堆叠在一起的结构,然后再经过一个3x3卷积层,就得到第一个预测特征图,它的大小就是13x13的,最后我们会使用卷积核大小为1x1的预测器,在我们的特征图上进行预测,它所预测参数的个数就是13x13x[3x(4+1+80)]
然后我们再回到这个Convolutional Set,另外一个分支,首先通过一个1x1的卷积层,然后再经过一个上采样层,通过上采样层之后,它的高和宽会扩大到原来的两倍,所以就从13x13变成了26x26,和Darknet-53输出的26x26拼接,与FPN的特征金字塔结构不同,FPN将两个预测特征图结合的方式是在对应的维度上进行相加,但这里是进行拼接,将进行拼接之后得到的特征矩阵再经过Convolutional Set进行处理,同样一个分支是通往预测特征图2,另外一个分支接着往下走,通过一个1x1的卷积层,然后再通过上采样,就从26x26变成了52x52,再和backbone网络中8个残差结构输出的52x52大小的特征图进行拼接,拼接之后再通过Convolutional Set,再通过一个3x3的卷积层,就得到了第三个预测特征图,也就是52x52大小的,同样用大小为1x1的卷积核进行预测,这里的卷积是Conv,不是Convolutional,这里的卷积核只是一个普通的卷积层
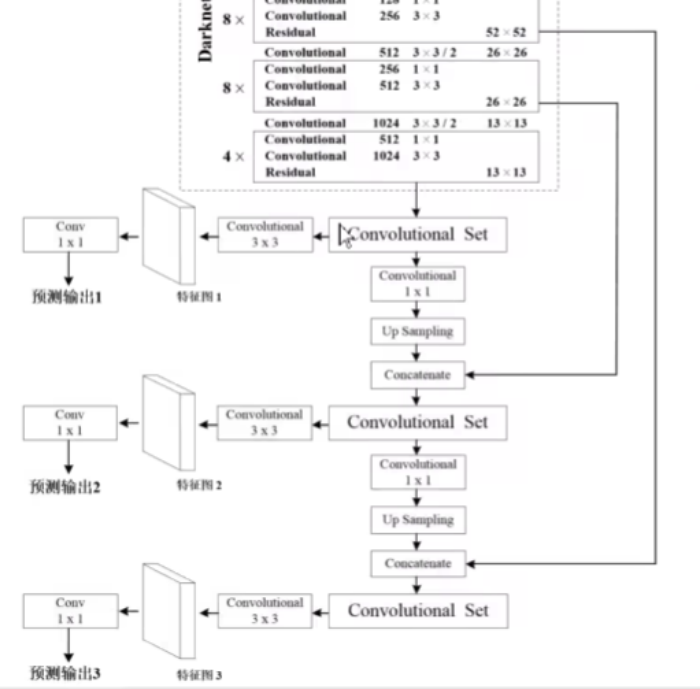
因为预测特征图1的大小是13x13的,所以我们会在预测特征图上预测相对较大的目标,预测特征图2的大小是26x26,所以我们会在这个特征图上预测中等大小的目标,预测特征图3的大小是52x52,它的细粒度是最高的,会在预测特征图上预测小目标,这就是我们YOLOv3的整个模型结构
目标边界框的预测
YOLOv3采用的是和YOLOv2一样的机制
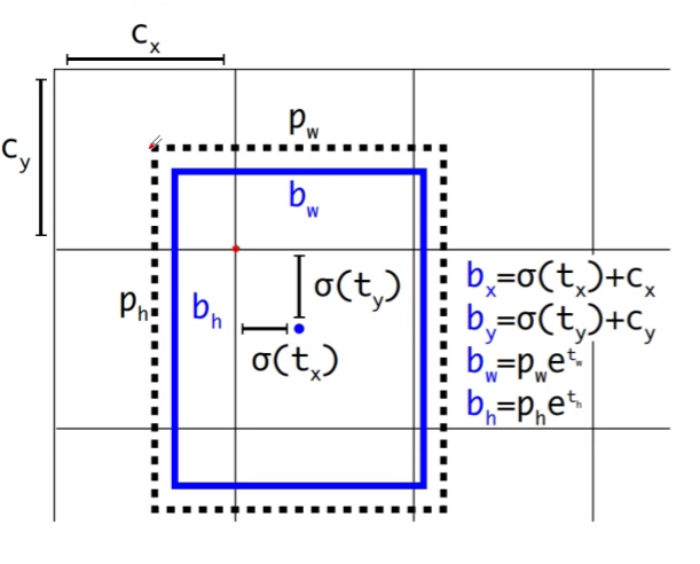
Faster R-CNN和SSD中网络预测的关于中心点的回归参数,都是相对于锚框而言的,但是在YOLOv3和YOLOv2中,网络预测的有关目标中心点的回归参数并不是相对于锚框的,而是相对于当前网格的左上角点的
最后是通过一个1x1的卷积层,在最后的预测特征图上去预测所有的相关信息的,在YOLOv3中,一共有三个预测特征层,每个预测特征图又采用了三个不同的模板,假设下图就是针对某一个预测特征图而言,假设1x1的卷积层滑动到中间窗口的时候,它会针对每个锚框模板,预测四个回归参数,一个obj参数和80个类别概率
正负样本的匹配
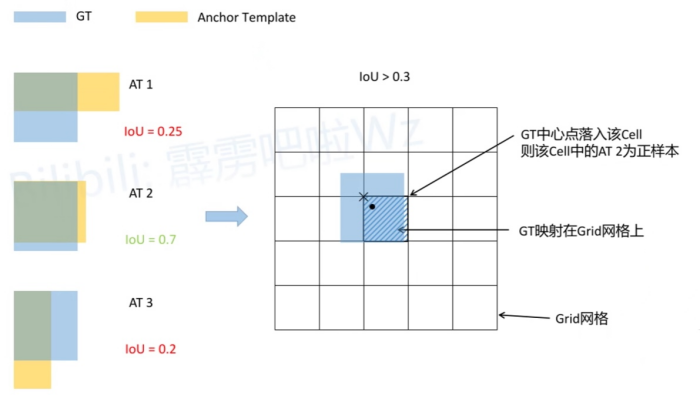
GT是真实框,AT是锚框模板,对于每个预测特征图而言,我们会采用三个不同的锚框模板,对每个GT和三个AT进行IoU的计算,是将GT和AT的左上角重合然后计算IoU,分别为0.25、0.7、0.2,我们设置IoU的阈值为0.3,只要IoU大于0.3,我们都会将它置成正样本,只有第二个AT是满足条件的,接下来我们再将GT映射到网格中,黑色的原点对应的是GT的中心点,这个中心点落在了一个网格中,那么这个网格中的AT 2为正样本
那如果三个AT与GT的IoU都大于阈值呢?那就在当前的网格中对应的三个AT都会被视为正样本
损失函数
使用二元交叉熵损失处理损失函数


















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









