







🚀本项目基于百度飞桨AI Studio平台实现:飞桨AI Studio - 人工智能学习与实训社区
🏠本人AI Studio平台主页:飞桨AI Studio - 人工智能学习与实训社区
百度飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件、丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。欢迎大家一起来平台学习交流哦~🚀😎🚀
一、项目简介
项目背景:
该项目着眼于基于视觉深度学习的自动驾驶场景,旨在对车载摄像头采集的视频数据进行道路场景解析,为自动驾驶提供一种解决思路。利用YOLO系列模型PP_YOLOE+完成车辆检测实现一种高效高精度的道路场景解析方式,从而实现真正意义上的自动驾驶,减少交通事故的发生,保障车主的人身安全。
项目意义:
在行车检测方面,现有检测模型可以实现多种类型的车辆检测,然而,一方面,检测模型在速度和精度上存在矛盾,对于精度较高的模型,如两阶段检测网络Faster R-CNN,其FPS较低,无法满足实时检测,因此其商用价值受到很大限制。另一方面,对于道路场景的目标检测,许多数据集会对场景中很多类型的目标进行标注,然而,经过我们的实践和观察,使用这种数据集训练模型并不能带来很好的效果。由于目标类别本身存在多样性,例如各式各样的货车,电瓶车,亦或是各式各样的路标和交通灯等,这会对模型的学习造成混淆,最终导致模型在现实场景中对很多目标造成误判,极大的影响模型在现实中的应用。为解决这两个问题,我们在本项目中使用飞桨开源的YOLOE+作为检测模型,在检测速度和检测精度上实现了较好的权衡。另外,我们对大规模道路场景数据集的标签进行了重构处理,仅学习数据集中的汽车类型,保证足以商用的准确率和召回率,对于其他类别,暂时当做背景类,后续可以再使用初始模型重新对背景类中的部分或全部目标进行训练,让不同模型各司其职,专注于不同目标来降低错误率,提高泛化能力。
效果演示:
基于paddledetection的行车检测_哔哩哔哩_bilibili
二、数据集介绍
数据集地址:Berkeley DeepDrive
视频数据: 超过1,100小时的100000个高清视频序列在一天中许多不同的时间,天气条件,和驾驶场景驾驶经验。视频序列还包括GPS位置、IMU数据和时间戳。
道路目标检测:2D边框框注释了100,000张图片,用于公交、交通灯、交通标志、人、自行车、卡车、摩托车、小汽车、火车和骑手。
实例分割:超过10,000张具有像素级和丰富实例级注释的不同图像。
引擎区域:从10万张图片中学习复杂的可驾驶决策。
车道标记:10万张图片上多类型的车道标注,用于引导驾驶。


三、技术路线
ppyoloe的介绍:
详情可参考:https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/configs/ppyoloe/README_cn.md
PP-YOLOE是基于PP-YOLOv2的单阶段Anchor-free模型,超越了多种流行的yolo模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免使用诸如deformable convolution或者matrix nms之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。 PP-YOLOE-l 在 COCO test-dev 上精度可达 51.4%,在 V100 上使用 TRT FP16 进行推理,速度可达 149.2FPS,相较于YOLOX-l精度提升 1.3 AP,速度提升 24.96%;相较于YOLOv5-x精度提升 0.7AP,TRT-FP16 加速 26.8%;相较于PP-YOLOv2精度提升 1.9 AP,速度提升 13.35%。

目前YOLOX以50.1达到了速度和精度的最佳平衡,V100上测试可达68FPS,是当前YOLO系列网络的集大成者,YOLOX引入了先进的动态标签分配方法,在精度方面显著优于YOLOv5,受到YOLOX的启发,作者进一步优化了之前的工作PP-YOLOv2。在PP-YOLOv2的基础上提出YOLOE,该检测器避免使用deformable convolution和matrix nms等运算操作,能在各种硬件上得到很好的支持。
模型架构:
下面我们来看看pp-yoloe的模型架构并且简单介绍下其中的内容:

PP-YOLOE由以下方法组成:
可扩展的backbone和neck Task Alignment Learning Efficient Task-aligned head with DFL和VFL SiLU激活函数
RepVGG:
RepVGG,这个网络就是在VGG的基础上面进行改进,主要的思路包括:
在VGG网络的Block块中加入了Identity和残差分支,相当于把ResNet网络中的精华应用 到VGG网络中; 模型推理阶段,通过Op融合策略将所有的网络层都转换为3×3卷积,便于网络的部署和加速。

为什么要用VGG式模型? 3×3卷积非常快。在GPU上,3×3卷积的计算密度(理论运算量除以所用时间)可达1×1和5×5卷积的4倍。 单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。 单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。 单路架构灵活性更好,容易改变各层的宽度(如剪枝)。 RepVGG主体部分只有一种算子:3×3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价可以集成海量的3×3卷积+ReLU计算单元来达到很高的效率。
CSPNet结构:
CSPNet的主要思想还是Partial Dense Block,设计Partial Dense Block的目的是:
增加梯度路径。 平衡各层的计算。 减少内存流量。

CSPNet的提出解决了以下问题:
强化 CNN 的学习能力:现有 CNN 网络一般在轻量化以后就会降低效果,CSPNet 希望能够在轻量化的同时保持良好的效果。CSPNet 在嵌入分类任务的 ResNet、ResNeXt、DenseNet 等网络后,可以在保持原有效果的同时,降低计算量 10%~20%
移除计算瓶颈:过高的计算瓶颈会导致推理时间更长,在其计算的过程中其他很多单元空闲,所以作者期望所有的计算单元的效率差不太多,从而提升每个单元的利用率,减少不必要的损耗。
减少内存占用:CSPNet 使用 cross-channel pooling 的方法来压缩特征图
SPP结构:
SPP-Net全名为Spatial Pyramid Pooling(空间金字塔池化结构),2015年由微软研究院的何恺明提出,主要解决2个问题:
有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题。 解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
SPP 显著特点 不管输入尺寸是怎样,SPP 可以产生固定大小的输出 使用多个窗口(pooling window) SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。 其它特点 由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting) 实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence) SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层) 不仅可以用于图像分类而且可以用来目标检测

通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP。
Neck结构:
yoloe的neck结构采用的依旧是FPN+PAN结构模式,FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图。和FPN层不同,yoloe在FPN层的后面还添加了一个自底向上的特征金字塔。FPN是自顶向下,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递,而本文就是针对这一点,在FPN的后面添加一个自底向上的金字塔。这样的操作是对FPN的补充,将低层的强定位特征传递上去。

Head结构:
对于PP-YOLOE的head部分,其依旧是TOOD的head,也就是T-Head,主要是包括了Cls Head和Loc Head。具体来说,T-head首先在FPN特征基础上进行分类与定位预测;然后TAL基于所提任务对齐测度计算任务对齐信息;最后T-head根据从TAL传回的信息自动调整分类概率与定位预测。

由于2个任务的预测都是基于这个交互特征来完成的,但是2个任务对于特征的需求肯定是不一样的,因为作者设计了一个layer attention来为每个任务单独的调整一下特征,可以理解为是一个channel-wise的注意力机制。这样的话就得到了对于每个任务单独的特征,然后再利用这些特征生成所需要的类别或者定位的特征图。

PP-YOLOE+改进之处:
精度
首先,我们使用Objects365大规模数据集对模型进行了预训练。Objects365数据集含有的数据量可达百万级,在大数据量下的训练可以使模型获得更强大的特征提取能力、更好的泛化能力,在下游任务上的训练可以达到更好的效果。
其次,我们在RepResBlock中的1x1卷积上增加了一个可学习的权重alpha,进一步提升了backbone的表征能力,获得了不错的效果提升。最后,我们调整了NMS的参数,在COCO上可以获得更好的评估精度。
训练速度
基于Objects365的预训练模型,将学习率调整为原始学习率的十分之一,训练的epoch从300降到了80,在大大缩短了训练时间的同时,获得了精度上的提升。
端到端推理速度
我们精简了预处理的计算方式,由于减均值除方差的方式在CPU上极其耗时,所以我们在优化时直接去除掉了这部分的预处理操作,使得PP-YOLOE+系列模型在端到端的速度上能获得40%以上的加速提升。
下游泛化性增强
我们验证了PP-YOLOE+模型强大的泛化能力,在农业、低光、工业等不同场景下游任务检测效果稳定提升。
ppyoloe+模型效果:

四、环境配置
# 克隆paddledetection仓库
# gitee 国内下载比较快
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git
# github
# !git clone https://github.com/PaddlePaddle/PaddleDetection.git# 导入package
!pip install -r ~/PaddleDetection/requirements.txt
以上是requirement文件里的库,大家可以根据需要修改添加。
# 继续安装依赖库
!python3 ~/PaddleDetection/setup.py install进行依赖库的安装时,有时候会报缺少version.py文件的错误,这时候我发现只要将后面的步骤先进行,到训练的时候如果训练出错了,再重新返回来执行依赖库安装的程序,那么就可以了。(其实这个库不安装也行,到后面程序如果需要什么库,再一个一个安装即可)
五、数据准备
!unzip -oq /home/aistudio/data/data167518/bdd100k.zip -d /home/aistudio/PaddleDetection/dataset
- 由于平台上的BDD100K数据集很多不能直接用,需要进行格式转换,所以该数据已经转换了BDD100K的目标检测部分(转换到了VOC格式,当然也提供了原始JSON文件,有特殊需要的也可以自行转换),并提供了train_list.txt、val_list.txt和label.txt,直接修改配置文件的数据集路径即可使用,不需要任何格式转换。
由于本项目挂载的数据集路径存在一定问题,大家可以使用mv命令移动下载好的数据集路径,放到PaddleDetection/dataset里面就行。

以下是详细代码:
# mv命令移动数据集到合适位置
%mv /home/aistudio/PaddleDetection/dataset/home/aistudio/PaddleDetection/dataset/bdd100k /home/aistudio/PaddleDetection/dataset# 查看数据集数量
import os
os.chdir('/home/aistudio/PaddleDetection/dataset/bdd100k')
base_dir = 'images/100k/'
imgs = os.listdir(base_dir + 'train')
print('训练集图片总量: {}'.format(len(imgs)))
imgs = os.listdir(base_dir + 'val')
print('验证集图片总量: {}'.format(len(imgs)))
imgs = os.listdir(base_dir + 'test')
print('测试集图片总量: {}'.format(len(imgs))) 在本项目中,我们使用的是bdd100k数据集,此数据集已经转为了VOC的数据格式,并且已经生成train_list.txt和val_list.txt文件,我们还需要做的操作是到PaddleDetection/configs/datasets/voc.yml目录下,修改一下anno_path,或者将train_list.txt和val_list.txt文件改为trainval.txt和test.txt。
内容如下图所示:

# 导入pycocotools库
!pip install pycocotools这一步是如果依赖库安装步骤出了问题无法解决,那么就单独下载下pycocotools这个库,因为我们训练需要用到~
六、数据预处理
sample_transforms:
- Decode: {}
- RandomDistort: {}
- RandomExpand: {fill_value: [123.675, 116.28, 103.53]}
- RandomCrop: {}
- RandomFlip: {}
batch_transforms:
- BatchRandomResize: {target_size: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeImage: {mean: [0., 0., 0.], std: [1., 1., 1.], norm_type: none}
- Permute: {}
- PadGT: {}
- RandomCrop:随机裁剪图像。
- RandomFlip:实现图像的随机翻转(翻转概率为0.5)。
- RandomDistort:以一定的概率对图像进行随机像素内容变换,可包括亮度、对比度、饱和度、色相角度、通道顺序的调整,模型训练时的数据增强操作。
- BatchRandomResize:对一个批次中的图片随机指定尺寸,范围是[320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768],插值方式为随机插值,进行多尺度训练。
- NormalizeImage:用于通过调整像素的颜色以覆盖整个可用颜色范围来增强彩色图像的对比度。
七、模型训练
端到端速度
| 模型 | AP0.5:0.95 | TRT-FP32(fps) | TRT-FP16(fps) |
|---|---|---|---|
| PP-YOLOE+_s | 43.7 | 44.44 | 47.85 |
| PP-YOLOE+_m | 49.8 | 39.06 | 43.86 |
| PP-YOLOE+_l | 52.9 | 34.01 | 42.02 |
| PP-YOLOE+_x | 54.7 | 26.88 | 36.76 |
根据官方文档,我选择了PP-YOLOE+_m模型。因为它的AP值和FPS都处于中上的水平。大家如果有兴趣的,可以尝试下PP-YOLOE+_l和PP-YOLOE+_x模型。
本项目使用的配置文件是~/PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml
修改配置文件 PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml
BASE: [
'../datasets/voc.yml', #配置文件数据集路径
'../runtime.yml',
'./base/optimizer_80e.yml',
'./base/ppyoloe_plus_crn.yml',
'./base/ppyoloe_plus_reader.yml',
]log_iter: 100 # log_iter为多少iter输出一次
snapshot_epoch: 5 # snapshot_epochiter为多少轮评估一次
weights: output/ppyoloe_plus_crn_m_80e_coco/model_final # 预训练权重的位置pretrain_weights: https://bj.bcebos.com/v1/paddledet/models/pretrained/ppyoloe_crn_m_obj365_pretrained.pdparams
depth_mult: 0.67 # 模型的深度
width_mult: 0.75 # 模型的宽度
修改配置文件 PaddleDetection/configs/datasets/voc.yml
metric: VOC
map_type: 11point
num_classes: 14 # 包含背景类TrainDataset:
!VOCDataSet
dataset_dir: dataset/bdd100k
anno_path: train_list.txt
label_list: labels.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']EvalDataset:
!VOCDataSet
dataset_dir: dataset/bdd100k
anno_path: val_list.txt
label_list: labels.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']TestDataset:
!ImageFolder
anno_path: dataset/bdd100k/labels.txt
# 开始训练
%cd ~/PaddleDetection
!python3 tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml --eval \
--use_vdl True \
--vdl_log_dir output/vdl_picodet_xs/ \
-o use_gpu=true- YOLOE+默认训练的是80轮,在这由于时间原因,我只训练了50轮,发现每轮的精度和FPS都会有所提升,最终训练50轮的mPA停留在49左右,FPS停留在15左右。如果大家时间充裕,可以将80轮训练完看看效果。
八、模型评估
# 评估 默认使用训练过程中保存的best_model
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置),需使用单卡评估
%cd ~/PaddleDetection
!python tools/eval.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=PaddleDetection/output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams \
-o use_gpu=true九、模型测试
动态图测试
# 测试 -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
# --infer_dir 参数指定预测图像所在文件夹路径
# --infer_img 参数指定预测图像路径
# --output_dir 输出结果文件夹路径
# 预测结束后会在output文件夹中生成一张画有预测结果的同名图像
%cd ~/PaddleDetection
!python tools/infer.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
--infer_dir=dataset/bdd100k/images/100k/test \
--output_dir=dataset/result \
-o use_gpu=true \
-o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams 测试结果如下:
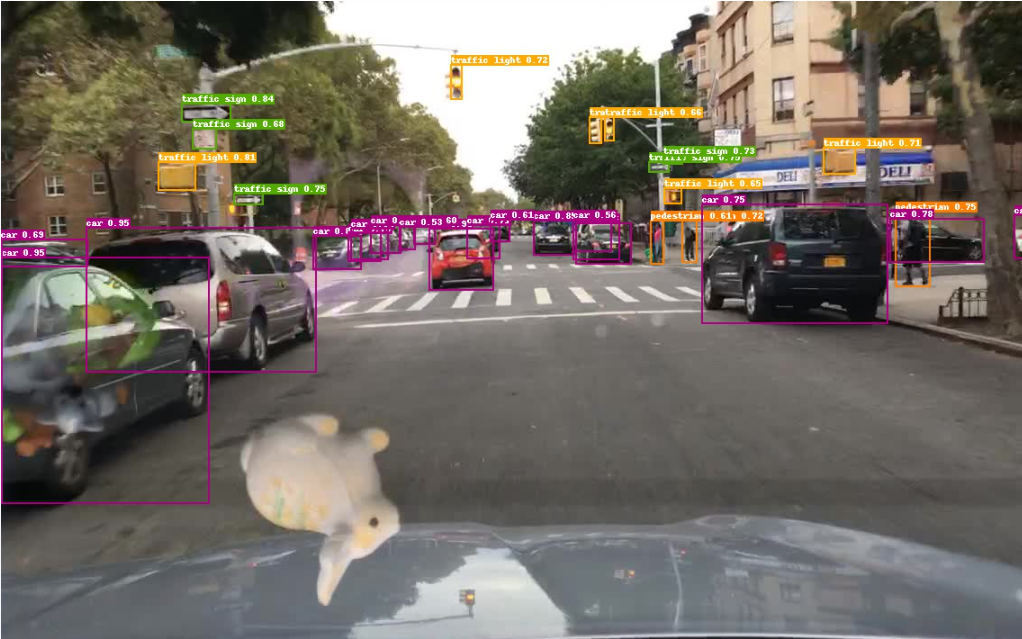

静态图测试
# 将训练好的模型导出为静态图
%cd ~/PaddleDetection
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams \
--output_dir=inference导出文件结构如下
inference/ppyoloe_plus_crn_m_80e_coco
|--infer_cfg.yml
|--model.pdiparams
|--model.pdiparams.info
|--model.pdmodel
inference/ppyoloe_plus_crn_m_80e_coco
|--infer_cfg.yml
|--model.pdiparams
|--model.pdiparams.info
|--model.pdmodel
PP-YOLOE+静态图性能测试 在这里,随机从20000张测试集中选择1000张图片进行性能测试,测试环境包括以下三种配置:
CPU+4 Thread
CPU+MKL+4 Thread
GPU
# 随机采样1000张测试集图片
import shutil
import os
import numpy as np
data_dir = "dataset/bdd100k/images/100k/test/"
pathlist= os.listdir(data_dir)
t = np.random.choice(pathlist, size=1000, replace=False)
for path in t:
src = data_dir + path
dst = "dataset/static_test/" + path
shutil.copy(src, dst)如果执行随机采样的时候,dataset目录里面没有static_test这个文件,那么可以自己创建此文件夹,用来存储采样后的数据。
# CPU测试推理模型(不开启mkldnn加速)
!python deploy/python/infer.py --model_dir=inference/ppyoloe_plus_crn_m_80e_coco \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=CPU --batch_size=1 \
--cpu_threads=4# CPU测试推理模型(开启mkldnn加速)
!python deploy/python/infer.py --model_dir=inference/ppyoloe_plus_crn_m_80e_coco \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=CPU --batch_size=1 \
--cpu_threads=4 \
--enable_mkldnn=True# GPU测试推理模型
!python deploy/python/infer.py --model_dir=inference/ppyoloe_plus_crn_m_80e_coco \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=GPU --batch_size=1测试结果如下:
| ppyoloe_plus_crn_m_80e_coco | preprocess_time(ms) | inference_time(ms) | postprocess_time(ms) | average latency time(ms) |
|---|---|---|---|---|
| CPU | 16.10 | 791.70 | 0.10 | 807.87 |
| CPU+MKL | 18.90 | 294.60 | 0.10 | 313.57 |
| GPU | 14.00 | 44.30 | 0.10 |
可以看到,ppyoloe_plus_crn_m_80e_coco在开了MKL加速后推理速度快了约64%,而GPU模式下相比于MKL加速的CPU模式推理速度快了约85%。由此,在硬件只提供CPU的情况下,开启MKL加速可以大大提高推理速度,如果提供GPU,那么将会使得推理速度进一步大幅提升。
另外,开启MKL加速对前处理和后处理影响不大,然而,开启GPU加速则对前后处理和模型推理都有较大的提升。
十、模型导出
PP-YOLOE+在GPU上部署或者速度测试需要通过tools/export_model.py导出模型。
当你使用Paddle Inference但不使用TensorRT时,运行以下的命令导出模型
# Paddle Inference
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams
当你使用Paddle Inference且使用TensorRT时,需要指定-o trt=True来导出模型。
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=PaddleDetection/output/ppyoloe_plus_crn_m_80e_coco \
-o trt=True如果你想将PP-YOLOE模型导出为ONNX格式,参考 PaddleDetection模型导出为ONNX格式教程,运行以下命令:
# 导出推理模型
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
--output_dir=output_inference \
-o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams
# 安装paddle2onnx
!pip install paddle2onnx
# 转换成onnx格式
!paddle2onnx --model_dir output_inference/ppyoloe_plus_crn_m_80e_coco \
--model_filename model.pdmodel --params_filename model.pdiparams \
--opset_version 11 --save_file ppyoloe_plus_crn_m_80e_coco.onnx注意: ONNX模型目前只支持batch_size=1
十一、速度测试
为了公平起见,在模型库中的速度测试结果均为不包含数据预处理和模型输出后处理(NMS)的数据(与YOLOv4(AlexyAB)测试方法一致),需要在导出模型时指定-o exclude_nms=True.
使用Paddle Inference但不使用TensorRT进行测速,执行以下命令:
# 安装GPUtil库
!pip install GPUtil
# 导出模型
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams \
--exclude_nms=True
# 速度测试,使用run_benchmark=True
!CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py \
--model_dir=output_inference/ppyoloe_plus_crn_m_80e_coco \
--image_file=/home/aistudio/PaddleDetection/dataset/bdd100k/images/100k/train/02d5e1be-bd9bd999.jpg\
--run_mode=paddle \
--device=gpu \
--run_benchmark=True测试结果:

使用Paddle Inference且使用TensorRT进行测速,执行以下命令:
# 安装TensorRT库
!pip install TensorRT
# 导出模型,使用trt=True
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml -o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams --exclude_nms=True --trt=True
# 速度测试,使用run_benchmark=True, run_mode=trt_fp32/trt_fp16
!CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyoloe_plus_crn_m_80e_coco --image_file=PaddleDetection/dataset/bdd100k/images/100k/train/02d5e1be-bd9bd999.jpg --run_mode=trt_fp16 --device=gpu --run_benchmark=True使用 ONNX 和 TensorRT 进行测速,执行以下命令:
# 导出模型
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml -o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams exclude_nms=True trt=True
# 转化成ONNX格式
!paddle2onnx --model_dir output_inference/ppyoloe_plus_crn_m_80e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 12 --save_file ppyoloe_plus_crn_m_80e_coco.onnx \
# 测试速度,半精度,batch_size=1
!trtexec --onnx=./ppyoloe_plus_crn_m_80e_coco.onnx --saveEngine=./ppyoloe_m_bs1.engine --workspace=1024 --avgRuns=1000 --shapes=image:1x3x640x640,scale_factor:1x2 --fp16
# 测试速度,半精度,batch_size=32
!trtexec --onnx=./ppyoloe_plus_crn_m_80e_coco.onnx --saveEngine=./ppyoloe_m_bs32.engine --workspace=1024 --avgRuns=1000 --shapes=image:32x3x640x640,scale_factor:32x2 --fp16
# 使用上边的脚本, 在T4 和 TensorRT 7.2的环境下,PPYOLOE-plus-m模型速度如下
# batch_size=1, 2.80ms, 357fps
# batch_size=32, 67.69ms, 472fps 如果报/bin/bash: trtexec: 未找到命令的错误,出现这个问题是因为,我们需要把TensorRT目录下的bin文件添加到环境变量里。
在终端执行以下命令
vim ~/.bashrc
# 按i进入编辑模式,在最后一行添加: export PATH=/usr/src/tensorrt/bin:$PATH # 添加完毕后按下ESC,:wq!退出即可
# 最后输入即可 source ~/.bashrc
十二、模型部署
PP-YOLOE可以使用以下方式进行部署:
- Paddle Inference Python & C++
- Paddle-TensorRT
- PaddleServing
- PaddleSlim模型量化
接下来,我们将介绍PP-YOLOE如何使用Paddle Inference在TensorRT FP16模式下部署
首先,参考Paddle Inference文档,下载并安装与你的CUDA, CUDNN和TensorRT相应的wheel包。

然后,运行以下命令导出模型
# 导入下载好与你的CUDA, CUDNN和TensorRT相应的wheel包。
!pip install *.whl考虑到whl文件过大,上传可能花费时间很长,所以在此也可以使用wget方法在终端输入以下命令直接下载使用即可
命令如下:
wget https://paddle-inference-lib.bj.bcebos.com/2.3.2/python/Linux/GPU/x86-64_gcc8.2_avx_mkl_cuda11.2_cudnn8.2.1_trt8.0.3.4/paddlepaddle_gpu-2.3.2.post112-cp37-cp37m-linux_x86_64.whl!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams \
-o trt=True最后,使用TensorRT FP16进行推理
# 推理单张图片
!CUDA_VISIBLE_DEVICES=0 python PaddleDetection/deploy/python/infer.py --model_dir=output_inference/ppyoloe_plus_crn_m_80e_coco --image_file=PaddleDetection/dataset/bdd100k/images/100k/train/02d5e1be-bd9bd999.jpg --device=gpu --run_mode=trt_fp16
# 推理文件夹下的所有图片
!CUDA_VISIBLE_DEVICES=0 python PaddleDetection/deploy/python/infer.py --model_dir=output_inference/ppyoloe_plus_crn_m_80e_coco --image_dir=PaddleDetection/dataset/bdd100k/images/100k/train --device=gpu --run_mode=trt_fp16注意:
- TensorRT会根据网络的定义,执行针对当前硬件平台的优化,生成推理引擎并序列化为文件。该推理引擎只适用于当前软硬件平台。如果你的软硬件平台没有发生变化,你可以设置enable_tensorrt_engine的参数use_static=True,这样生成的序列化文件将会保存在output_inference文件夹下,下次执行TensorRT时将加载保存的序列化文件。
- PaddleDetection release/2.4及其之后的版本将支持NMS调用TensorRT,需要依赖PaddlePaddle release/2.3及其之后的版本
项目总结:
- 利用PP-YOLOE+在大规模车辆数据集BDD100k上进行了50个epoch的预训练,并导出了静态模型,分别在CPU、CPU+MKL、GPU模式下进行了测试,并得出了比较结果。
- 并使用Paddle Inference在TensorRT FP16模式下部署。
由于是新手,写的有哪里不太明确的地方欢迎大家指正~
















 4079
4079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











