






LSTM缓解梯度消失
1.习题6-4 推导LSTM网络中参数的梯度, 并分析其避免梯度消失的效果
LSTM的出现主要是为了缓解在RNN的长程依赖问题中存在的梯度消失的问题,为什么会出现梯度消失问题?上一篇文章有详细的推导。
首先来看一下LSTM的网络结构:

要分析为什么LSTM能缓解梯度消失,网上很多文章都直接用 ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct来证明的,但是 为什么要用 ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct来证明 ,而不是用其他的求偏导来证明? ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct到底在反向传播中以什么样的形式存在? 对反向传播起到了什么作用? 为什么证明了 ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct能缓解梯度消失,就能说明LSTM可以缓解梯度消失?
接下来将LSTM的反向传播的公式推导,以下图为例进行推导:

可以看到在LSTM网络中,参数有很多:
W
x
f
、
W
h
f
、
W
x
i
、
W
h
i
、
W
x
g
、
W
h
g
、
W
x
o
、
W
h
o
、
b
W_{xf}\text{、}W_{hf}\text{、}W_{xi}\text{、}W_{hi}\text{、}W_{xg}\text{、}W_{hg}\text{、}W_{xo}\text{、}W_{ho}\text{、}b
Wxf、Whf、Wxi、Whi、Wxg、Whg、Wxo、Who、b 下面在
t
=
3
t=3
t=3时刻,以
W
x
f
W_{xf}
Wxf为例来推导LSTM的反向传播。
图中顺着箭头的方向是前向传播,反向传播就是逆着箭头的方向找路径(对某参数矩阵求偏导,同一条路径上是相乘的关系,不同路径是相加的关系)。
过程有点长,感觉麻烦的可以直接看最后结论。




可以看到,
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct 存在于LSTM反向传播的某些路径之中,而且存在连乘项,我们如果能证明至少有一条路径上缓解了梯度消失,那么就可以说明LSTM确实缓解了梯度消失(正常梯度 + 消失梯度 = 正常梯度)。
下面来求一下
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct:
∂
C
t
∂
C
t
−
1
=
∂
C
t
∂
f
t
∂
f
t
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
i
t
∂
i
t
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
g
t
∂
g
t
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
C
t
−
1
\frac{\partial C_t}{\partial C_{t-1}}=\frac{\partial C_t}{\partial f_t}\frac{\partial f_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial i_t}\frac{\partial i_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial {g_t}}\frac{\partial {g_t}}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial C_{t-1}}\ \ \ \
∂Ct−1∂Ct=∂ft∂Ct∂ht−1∂ft∂Ct−1∂ht−1+∂it∂Ct∂ht−1∂it∂Ct−1∂ht−1+∂gt∂Ct∂ht−1∂gt∂Ct−1∂ht−1+∂Ct−1∂Ct
=
C
t
−
1
σ
’
(
⋅
)
W
h
f
O
t
−
1
tan
h
’
(
C
t
−
1
)
=C_{t-1}\sigma ^’\left( \cdot \right) W_{hf}O_{t-1}\tan\text{h}^’\left( C_{t-1} \right) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
=Ct−1σ’(⋅)WhfOt−1tanh’(Ct−1)
+
g
t
σ
’
(
⋅
)
W
h
i
O
t
−
1
tan
h
’
(
C
t
−
1
)
+\ {g_t}\sigma ^’\left( \cdot \right) W_{hi}O_{t-1}\tan\text{h}^’\left( C_{t-1} \right) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
+ gtσ’(⋅)WhiOt−1tanh’(Ct−1)
+
i
t
tan
h
’
(
⋅
)
W
h
g
O
t
−
1
tan
h
’
(
C
t
−
1
)
+i_t\tan\text{h}^’\left( \cdot \right) W_{hg}O_{t-1}\tan\text{h}^’\left( C_{t-1} \right) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
+ittanh’(⋅)WhgOt−1tanh’(Ct−1)
+
f
t
+f_{t} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
+ft
可以看到
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct的大小是由参数
W
h
f
、
W
h
i
、
W
h
g
…
…
W_{hf}、W_{hi}、W_{hg}……
Whf、Whi、Whg……来调控的(注意这些参数都是不一样的),神经网络在参数学习过程中可以通过自己控制这些参数相互配合来让
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct趋近于1,当有多个
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct进行连乘时,那么这条路径上的梯度可能不会消失(但是其他的路径依然可能会发生梯度消失)。
看到这可能会发出疑问了:RNN难道不可以自己控制参数从而避免梯度消失吗?
下图是RNN产生梯度消失的原因,多个连乘项,而且连乘项的参数就只有
U
U
U,只要
U
U
U小于1,那么经过长时间的积累,梯度就会越来越小。而LSTM是有多个不同的参数共同来控制梯度的,网络在反向传播的过程中可以通过这些参数的相互配合,使
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct趋于1,当有多个
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct连乘时,在一定程度上可以缓解梯度消失。

鱼书中是这么说的:

注意几个问题:
- RNN 中总的梯度是不会消失的。即便梯度越传越弱,那也只是远距离的梯度消失,由于近距离的梯度不会消失,所有梯度之和便不会消失。RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
- LSTM 中梯度的传播有很多条路径, C t − 1 → C t = f t ⊙ C t − 1 + i t ⊙ C t ~ C_{t-1}\rightarrow C_t=f_t\odot C_{t-1}+i_t\odot \widetilde{C_t} Ct−1→Ct=ft⊙Ct−1+it⊙Ct 这条路径上只有逐元素相乘和相加的操作,梯度流最稳定;但是其他路径上梯度流与普通 RNN 类似,照样会发生相同的权重矩阵反复连乘。
- 由于总的远距离梯度 = 各条路径的远距离梯度之和,即便其他远距离路径梯度消失了,只要保证有一条远距离路径(就是上面说的那条路)梯度不消失,总的远距离梯度就不会消失(正常梯度 + 消失梯度 = 正常梯度)。因此 LSTM 通过改善一条路径上的梯度问题拯救了总体的远距离梯度。
- 同样,因为总的远距离梯度 = 各条路径的远距离梯度之和,有一条上梯度流比较稳定,但其他路径上梯度有可能爆炸(正常梯度 + 爆炸梯度 = 爆炸梯度),因此 LSTM 仍然有可能发生梯度爆炸。不过,由于 LSTM 的其他路径非常崎岖,和普通 RNN 相比多经过了很多次激活函数(导数都小于 1),因此 LSTM 发生梯度爆炸的频率要低得多。实践中梯度爆炸一般通过梯度截断来解决。
总结几个存在疑问的点:
虽然文章中写了一些推导过程,但是感觉不是很能说服我,还是存在一些疑问:
1.很多其他文章中写道,减少梯度消失现象的很重要的一个点就是对于遗忘门的把控。
但是,遗忘门不也是个sigmoid函数吗?取值不也在(0,1)之间吗?再加上一些其他的含有激活函数的项之后,难道就能确保
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct不在(0,1)之间了吗?只要
∂
C
t
∂
C
t
−
1
<
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}<1
∂Ct−1∂Ct<1,经过多次连乘之后,不就发生梯度消失了?只要
∂
C
t
∂
C
t
−
1
>
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}>1
∂Ct−1∂Ct>1,经过多次连乘之后,不就发生梯度爆炸了?
2.也有文章提到LSTM是有多个不同的参数共同来控制梯度的,网络在反向传播的过程中可以通过这些参数的相互配合,使
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct趋于1,当有多个
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct连乘时,在一定程度上可以缓解梯度消失。
这个原因我是有一点点相信的,但是还是存在一些疑问,神经网络能通过调整这些参数使得
∂
C
t
∂
C
t
−
1
\frac{\boldsymbol{\partial C}_{\boldsymbol{t}}}{\boldsymbol{\partial C}_{\boldsymbol{t}-1}}
∂Ct−1∂Ct趋于1,从而在反向传播中缓解梯度消失吗?
(这可能也是说神经网络是黑盒的原因所在,我只能说是通过实验确实证明了LSTM的记忆时间比RNN更长,能不能继续改进网络结构,使短期记忆变成长期记忆,使记忆时间更长呢?我认为在未来还是可以的。)
总之,我的理解是LSTM相对于RNN多了一些权重矩阵,模型稍微复杂了一点,使得反向传播时不是同一个参数矩阵一直做连乘,而是有不同的参数矩阵、还有相加的操作,从而缓解了梯度消失。
只能说是LSTM网络的记忆时间相对于RNN长了一些,但是时间长了仍然可能有梯度消失、梯度爆炸。
2.习题6-3P 编程实现下图LSTM运行过程


使用Numpy实现LSTM算子
代码:
import numpy as np
#定义激活函数
def sigmoid(x):
return 1/(1+np.exp(-x))
#权重
input_weight=np.array([1,0,0,0])
inputgate_weight=np.array([0,100,0,-10])
forgetgate_weight=np.array([0,100,0,10])
outputgate_weight=np.array([0,0,100,-10])
#输入
input=np.array([[1,0,0,1],[3,1,0,1],[2,0,0,1],[4,1,0,1],[2,0,0,1],[1,0,1,1],[3,-1,0,1],[6,1,0,1],[1,0,1,1]])
y=[] #输出
c_t=0 #内部状态
for x in input:
g_t=np.matmul(input_weight,x) #候选状态
i_t=np.round(sigmoid(np.matmul(inputgate_weight,x))) #输入门
after_inputgate=g_t*i_t #候选状态经过输入门
f_t=np.round(sigmoid(np.matmul(forgetgate_weight,x))) #遗忘门
after_forgetgate=f_t*c_t #内部状态经过遗忘门
c_t=np.add(after_inputgate,after_forgetgate) #新的内部状态
o_t=np.round(sigmoid(np.matmul(outputgate_weight,x))) #输出门
after_outputgate=o_t*c_t #新的内部状态经过输出门
y.append(after_outputgate) #输出
print('输出:',y)
运行结果:
![]()
使用nn.LSTMCell实现
先来看一下怎么使用nn.LSTMCell
首先是对nn.LSTMCell进行实例化,传入的参数是输入层神经元个数,隐层神经元个数。
![]()
接着调用,传入的参数是输入、h_0、c_0,注意,这里把h_0和c_0是组成了一个元组,作为一个参数,一块儿输进去的。h_0、c_0默认是0,注意各参数应该是什么形状的。

接下来看输出,输出的是h_1,c_1,注意,这里也是把把h_1和c_1是组成了一个元组,一块儿输出来的。

网络中的参数,注意参数的维度:
weight_ih:输入x与输入门、遗忘门、候选、输出门的连接权重。
weight_hh:隐层h与输入门、遗忘门、候选、输出门的连接权重。

代码:
import torch
import torch.nn as nn
#实例化
input_size=4
hidden_size=1
cell=nn.LSTMCell(input_size=input_size,hidden_size=hidden_size)
#修改模型参数 weight_ih.shape=(4*hidden_size, input_size),weight_hh.shape=(4*hidden_size, hidden_size),
#weight_ih、weight_hh分别为输入x、隐层h分别与输入门、遗忘门、候选、输出门的权重
cell.weight_ih.data=torch.tensor([[0,100,0,-10],[0,100,0,10],[1,0,0,0],[0,0,100,-10]],dtype=torch.float32)
cell.weight_hh.data=torch.zeros(4,1)
print('cell.weight_ih.shape:',cell.weight_ih.shape)
print('cell.weight_hh.shape',cell.weight_hh.shape)
#初始化h_0,c_0
h_t=torch.zeros(1,1)
c_t=torch.zeros(1,1)
#模型输入input_0.shape=(batch,seq_len,input_size)
input_0=torch.tensor([[[1,0,0,1],[3,1,0,1],[2,0,0,1],[4,1,0,1],[2,0,0,1],[1,0,1,1],[3,-1,0,1],[6,1,0,1],[1,0,1,1]]],dtype=torch.float32)
#交换前两维顺序,方便遍历input.shape=(seq_len,batch,input_size)
input=torch.transpose(input_0,1,0)
print('input.shape:',input.shape)
output=[]
#调用
for x in input:
h_t,c_t=cell(x,(h_t,c_t))
output.append(np.around(h_t.item(), decimals=3))#保留3位小数
print('output:',output)
![]()
使用nn.LSTM实现
先来看一下怎么使用nn.LSTMCell
首先是对nn.LSTM进行实例化,传入的参数是输入层神经元个数,隐层神经元个数,隐层的个数,batch_first。
注意如果输入的形状为(batch,seq_len,input_size),那么batch_first要=True。

输入

输出:

#LSTM
#实例化
input_size=4
hidden_size=1
lstm=nn.LSTM(input_size=input_size,hidden_size=hidden_size,batch_first=True)
#修改模型参数
lstm.weight_ih_l0.data=torch.tensor([[0,100,0,-10],[0,100,0,10],[1,0,0,0],[0,0,100,-10]],dtype=torch.float32)
lstm.weight_hh_l0.data=torch.zeros(4,1)
#模型输入input.shape=(batch,seq_len,input_size)
input=torch.tensor([[[1,0,0,1],[3,1,0,1],[2,0,0,1],[4,1,0,1],[2,0,0,1],[1,0,1,1],[3,-1,0,1],[6,1,0,1],[1,0,1,1]]],dtype=torch.float32)
#初始化h_0,c_0
h_t=torch.zeros(1,1,1)
c_t=torch.zeros(1,1,1)
#调用
output,(h_t,c_t)=lstm(input,(h_t,c_t))
rounded_output = torch.round(output * 1000) / 1000 # 保留3位小数
print(rounded_output)
运行结果
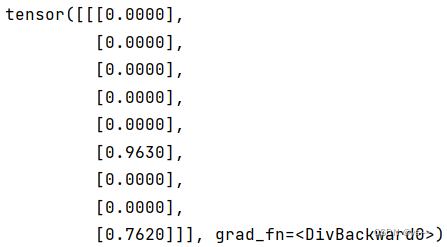
这个运行结果与numpy的结果不一样,是因为我numpy里的计算完候选状态和新的内部状态之后没有用tanh激活一下。
下面代码是用了tanh的numpy版代码:
import numpy as np
#定义激活函数
def sigmoid(x):
return 1/(1+np.exp(-x))
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
#权重
input_weight=np.array([1,0,0,0])
inputgate_weight=np.array([0,100,0,-10])
forgetgate_weight=np.array([0,100,0,10])
outputgate_weight=np.array([0,0,100,-10])
#输入
input=np.array([[1,0,0,1],[3,1,0,1],[2,0,0,1],[4,1,0,1],[2,0,0,1],[1,0,1,1],[3,-1,0,1],[6,1,0,1],[1,0,1,1]])
y=[] #输出
c_t=0 #内部状态
for x in input:
g_t=tanh(np.matmul(input_weight,x)) #候选状态
i_t=np.round(sigmoid(np.matmul(inputgate_weight,x))) #输入门
after_inputgate=g_t*i_t #候选状态经过输入门
f_t=np.round(sigmoid(np.matmul(forgetgate_weight,x))) #遗忘门
after_forgetgate=f_t*c_t #内部状态经过遗忘门
c_t=np.add(after_inputgate,after_forgetgate) #新的内部状态
o_t=np.round(sigmoid(np.matmul(outputgate_weight,x))) #输出门
after_outputgate=o_t*tanh(c_t) #激活后新的内部状态经过输出门
y.append(round(after_outputgate,2)) #输出
print('输出:',y)
运行结果:
![]()
这里一定一定要注意tanh加的位置,一个是计算候选状态时要加一个tanh,还有就是新的内部状态经过输出门之前要加一个tanh,注意,这里新的内部状态作为下一时刻的内部状态时是不需要加tanh的,这一点一定要注意,刚开始我加错tanh的位置了,结果一直不对,后来让聪明的舍友小张看了看,帮我纠正了这个问题。
参考:
【重温经典】大白话讲解LSTM长短期记忆网络 如何缓解梯度消失,手把手公式推-b站
《神经网络的梯度推导与代码验证》之LSTM的前向传播和反向梯度推导 -博客园
LSTM如何来避免梯度弥散和梯度爆炸?-知乎总结
LSTM模型与前向反向传播算法-刘建平
手搓GPT系列之 - 理解LSTM解决梯度消失的原理 -LSTM创始论文全部推导公式,配超多图帮助理解(上中下篇)-csdn
人人都能看懂的LSTM介绍及反向传播算法推导-知乎
pytorch nn.LSTM及nn.LSTMCell的用法和理解
nn.LSTMCell和nn.LSTM-b站
nn.LSTM详解















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









