动手安装NLTK(Anaconda)








于 2024-06-22 00:49:42 首次发布
 4806
3147
5872
5万+
4806
3147
5872
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




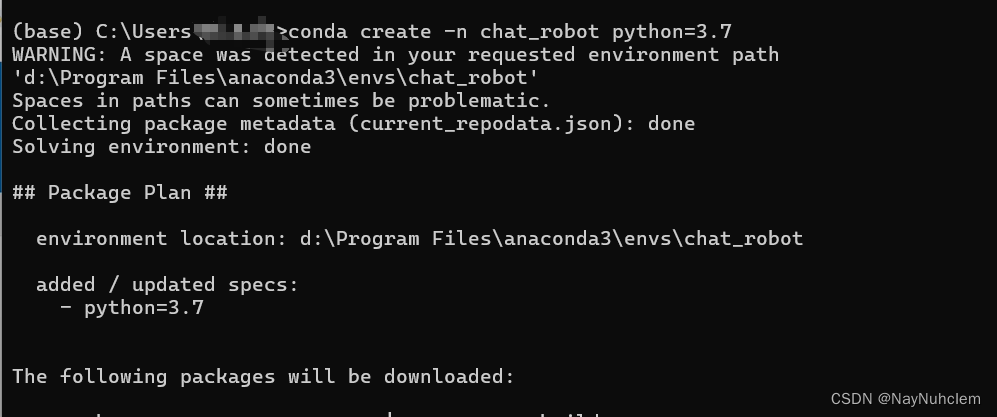
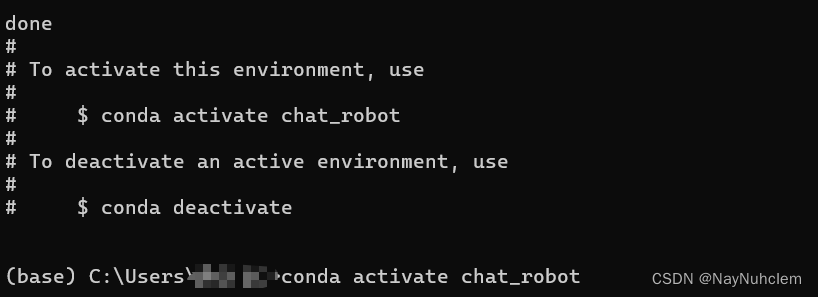

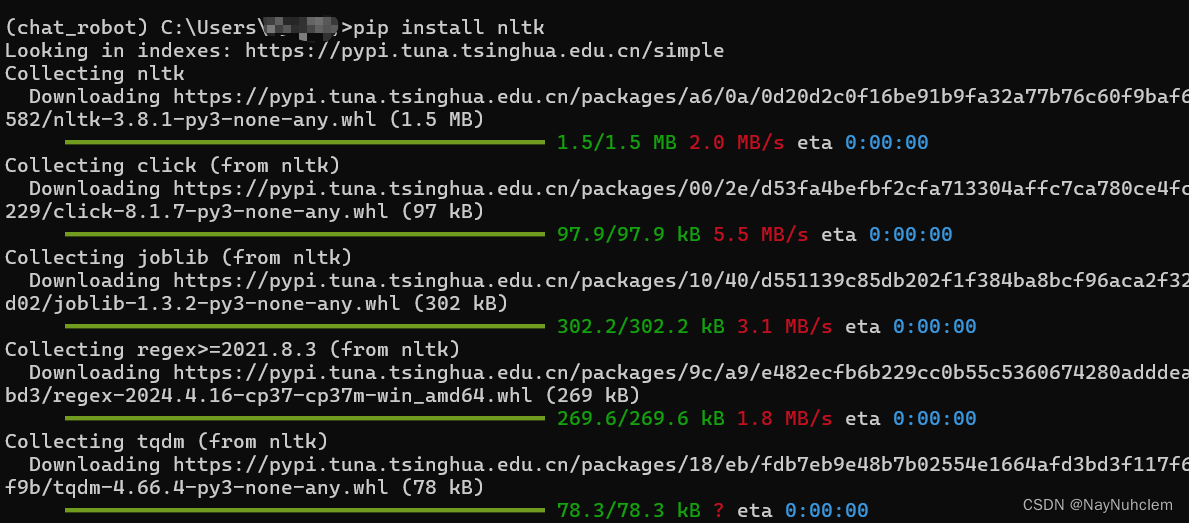

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























