







1.首先,先导入两个库(一个就是常用的reques库,另一个就是BeautiSoup库)
import requests
from bs4 import BeautifulSoup2.确定你要爬取的网页
本例子中爬取的网页是
https://www.dpm.org.cn/lights/royal.html(来自夜曲编程,写这篇博客是来复习的,也希望获得启发,毕竟有人在网上说过,爬虫也只是能爬取教过的网页。感觉爬虫好难啊。)
3.设置反爬虫
通过设置headers(当然设置发爬虫还可以限制爬取频率来限制,让服务器认为你是一个人类,哈哈!(time.sleep(2)))
打开网页后,按f12,查看网络的第一个文件,无论第一个文件叫什么,都是打开第一个文件,然后查看他的user-agent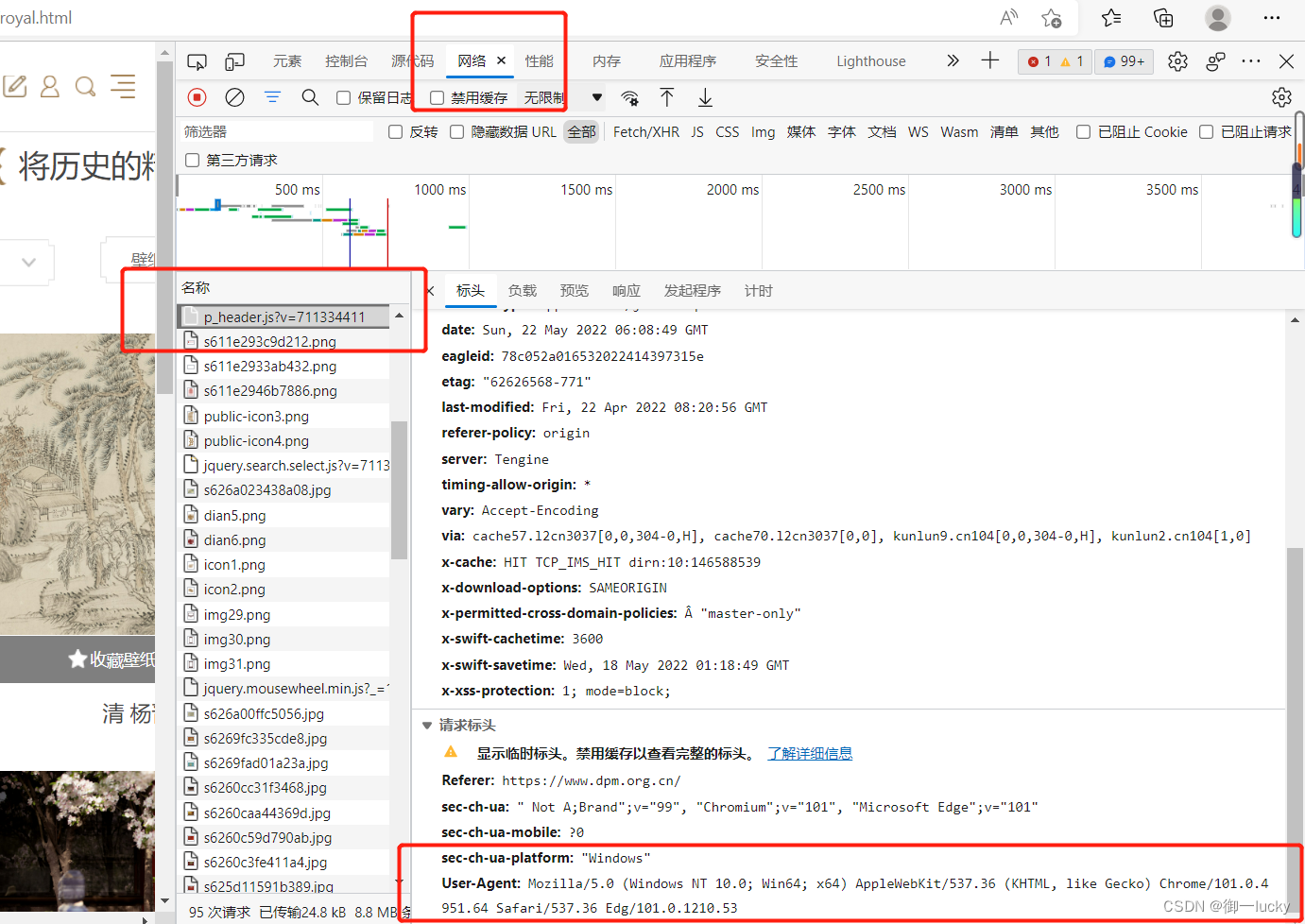
4.查看网页的页数规律
也就是查看第一页的图片是什么链接,第二页是什么,第三页,第四页,他们之间有什么规律和差别。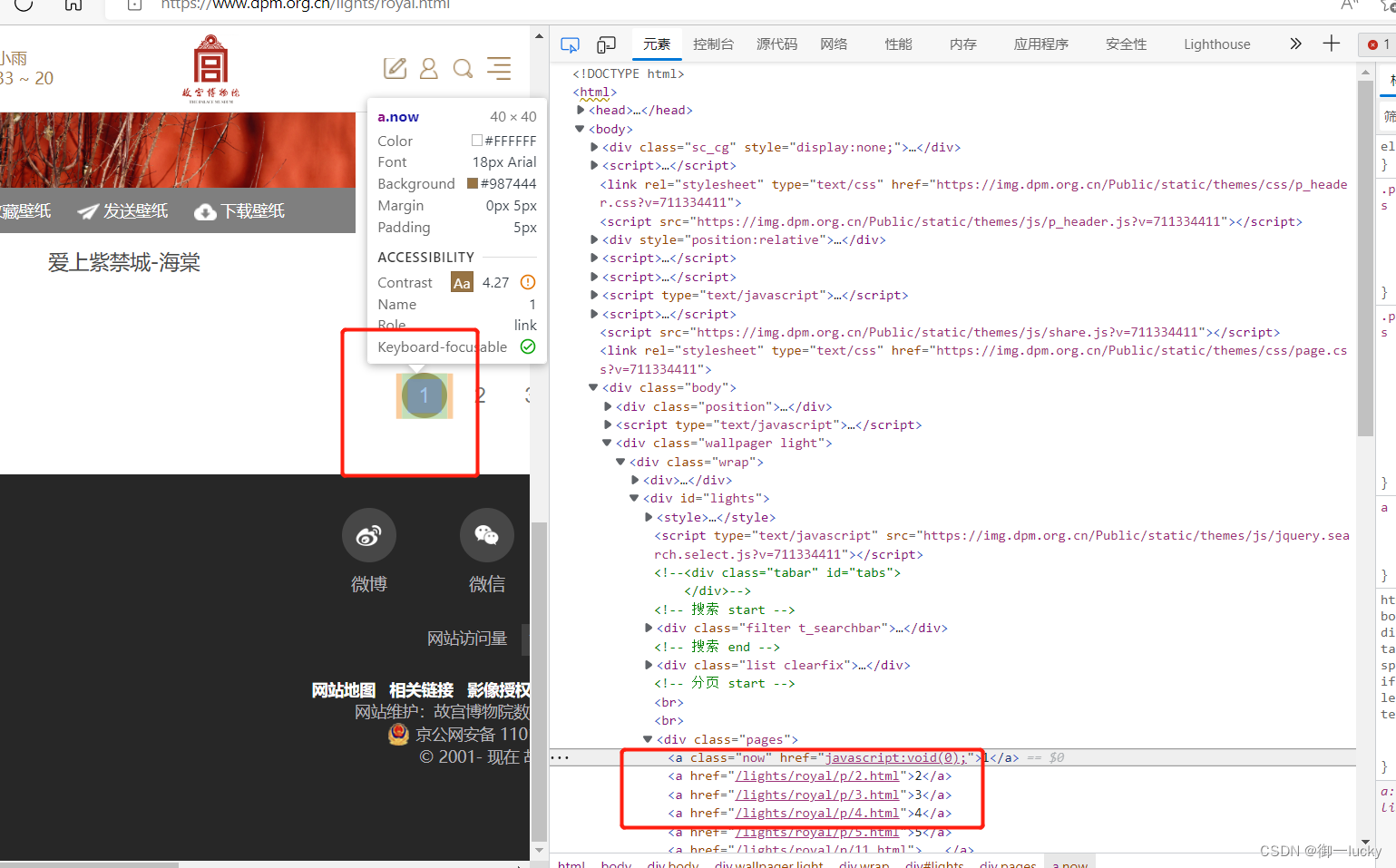
可以把鼠标放在页码序号哪里,右侧就会出现
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9027
9027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









