






 本文介绍了YOLOv8,一个专为实时推理设计的强大工具,支持图像、视频处理,具有高性能、易用性和高度定制性。文章详细讲解了使用CLI和Python接口的方法,以及如何利用YOLOv8处理数据集、训练模型和自定义任务的过程。
本文介绍了YOLOv8,一个专为实时推理设计的强大工具,支持图像、视频处理,具有高性能、易用性和高度定制性。文章详细讲解了使用CLI和Python接口的方法,以及如何利用YOLOv8处理数据集、训练模型和自定义任务的过程。
1.YOLOv8简介
YOLOv8是一个十分强大且好用的工具,它专为各种数据来源的高性能实时推理而设计。使用YOLOv8进行推理的原因[1]:
多功能性:能够对图像、视频乃至实时流进行推理。
性能:工程为实时、高速处理而设计、不牺牲准确性。
易用性:直观的python和CLI接口,便于快速部署和测试。
高度可定制性:多种设置和参数可调,依据您的具体需求调整模型的推理行为。
YOLOv8可以用于分类、检测、分割、姿态等任务,其在github上的网址为:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite关于YOLOv8的使用在其给出的官方文档中已经有很详细的说明(中文文档为:主页 - Ultralytics YOLOv8 文档),此处仅简单介绍。
1.1使用CLI接口使用YOLOv8的模板:
yolo 任务 模式 参数
其中 任务(可选)是[detect, segment, classify]中的一个
模式(必需)是[train, val, predict, export, track]中的一个
参数(可选)是任意数量的自定义“arg=value”对,如“imgsz=320”,可覆盖默认值。1.2使用python调用YOLOv8
from ultralytics import YOLO
# 从头开始创建一个新的YOLO模型
model = YOLO('yolov8n.yaml')
# 加载预训练的YOLO模型(推荐用于训练)
model = YOLO('yolov8n.pt')
# 使用“coco128.yaml”数据集训练模型3个周期
results = model.train(data='coco128.yaml', epochs=3)
# 评估模型在验证集上的性能
results = model.val()
# 使用模型对图片进行目标检测
results = model('https://ultralytics.com/images/bus.jpg')
# 将模型导出为ONNX格式
success = model.export(format='onnx')2.YOLOv8中提供的数据集
YOLOv8中针对不同任务提供了不同的数据集,这些数据集在第一次调用时会自动下载。针对检测任务有coco,coco8,voc等数据集,针对分割任务有coco,coco-seg数据集,针对分类任务有CIFAR-10,ImageNet,MNIST等数据集。关于数据集的简单介绍在上述的中文文档中也有说明,接下来我说一下如何使用自己的数据集进行训练。
3.使用自己数据集
在制作自己的数据集时可以按照以下步骤进行(以下步骤来源于官方文档):
(1)收集图像:收集属于数据集的图像,可以是公共数据集或自己收集的数据集。
(2)注释图像:根据任务对这些图像进行边界框、分段或关键点的标记。关于图像标注工具可以使用Labelme,而labelme的使用网上有详细的教程。
(3)导出注释:将这些注释转换为Ultralytics支持的YOLO*.txt文件格式。注意,使用labelme进行标注时生成的标注文件为json格式,因此要将json格式文件转换为txt格式(如何转换网上有许多的代码)。以下是我对一个苹果数据集标注后生成的txt文件:

上述中两行表示图片中有两个苹果,第一行第一个数字0表示类别,第2和第3个数据表示苹果的中心坐标(x,y),第4和第5个数据表示标注框的宽和高。
(4)组织数据集:按正确的文件夹结构安排自己的数据集。应该有train/和val/顶级目录,在每个目录内有images/和labels/子目录。
dataset/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/上面是官方给出的文件创作方式,也可以使用coco128数据集的文件格式,如下图所示:
在根目录下创建datasets文件夹,用于存放数据(小规模数据集可以这样使用),对于大规模数据集也可以将该文件夹放于其他任何地方,进入datasets文件夹后(如下),其中fruits是我自己标注的数据集。

进入fruits文件夹后(如下),其中images用于存放train、val、test的图片,而labels文件夹用于存放train、val、test图片中相应的txt标注信息。

进入images文件后(如下),此处我只划分了train,val。train和val文件夹存放图片数据,labels文件夹里面也创建相同名称的子文件夹,用于存放相应图片的txt信息。

(5)创建一个data.yaml文件:在数据集的根目录中,创建一个描述数据集的data.yaml文件(如上述myfruits.yaml),这个yaml文件包括类别信息等必要内容,比如我的就是根据coco128.yaml文件进行简单修改。
在官方文档中还有以下三步,但我觉得做一些小项目可能用不到。
(6)优化图像(可选):如果您想为了更高效的处理而减小数据集的大小,可以使用以下代码来优化图像。这不是必需的,但推荐用于减小数据集大小和加快下载速度。
(7)压缩数据集:将整个数据集文件夹压缩成一个 zip 文件。
(8)文档和 PR:创建描述您的数据集和它如何融入现有框架的文档页面。之后,提交一个 Pull Request (PR)。
优化和压缩数据集的实例代码(来源于官方文档)
from pathlib import Path
from ultralytics.data.utils import compress_one_image
from ultralytics.utils.downloads import zip_directory
# 定义数据集目录
path = Path('path/to/dataset')
# 优化数据集中的图像(可选)
for f in path.rglob('*.jpg'):
compress_one_image(f)
# 将数据集压缩成 'path/to/dataset.zip'
zip_directory(path)4.训练自己的模型
完成数据集的制作后,还要创建两个yaml文件,一个就是关于数据集的yaml文件,一个是关于模型的yaml文件。
上述的myfruits.yaml文件如下,可以根据coco128.yaml进行更改而来。
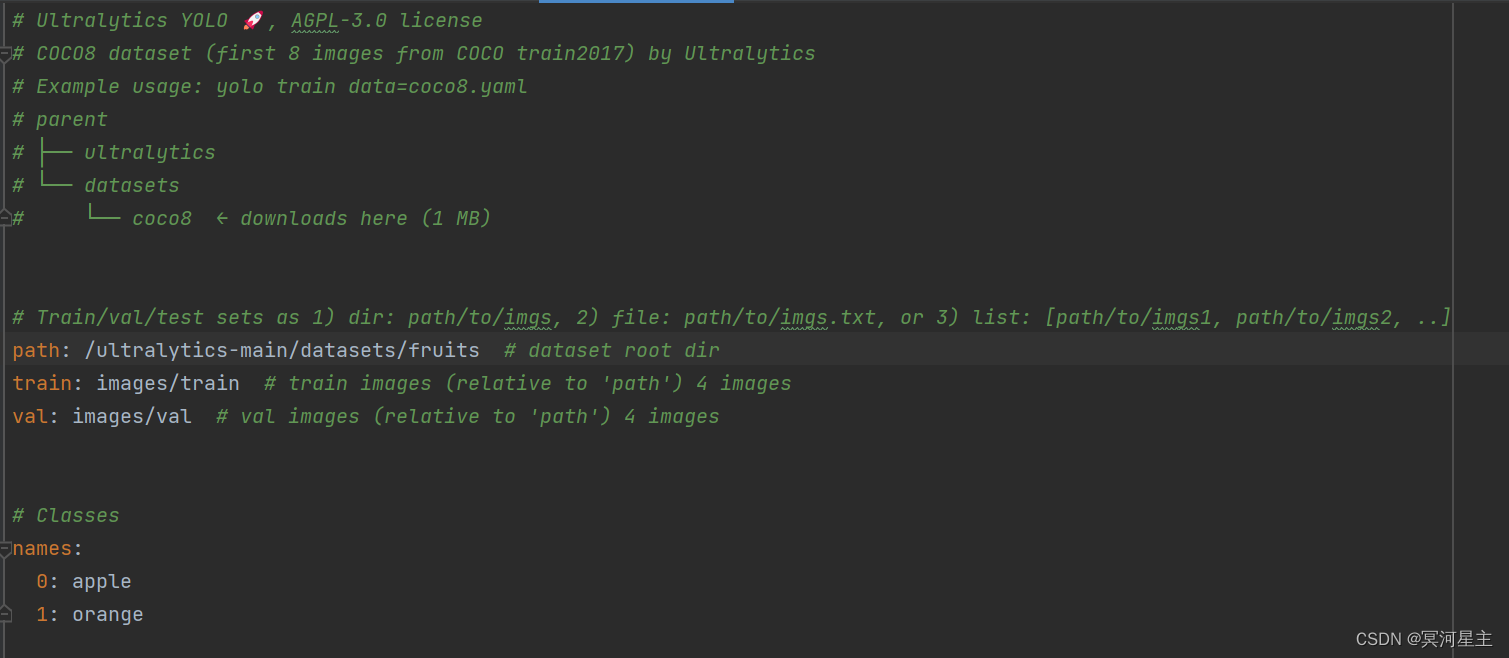
关于模型的yaml文件如下,可以根据相应任务的yaml文件进行更改,如我的是一个简单分类任务,根据yolov8.yaml文件修改而来(把里面的分类类别数改成了我实际任务的类别数,其他的不变)。
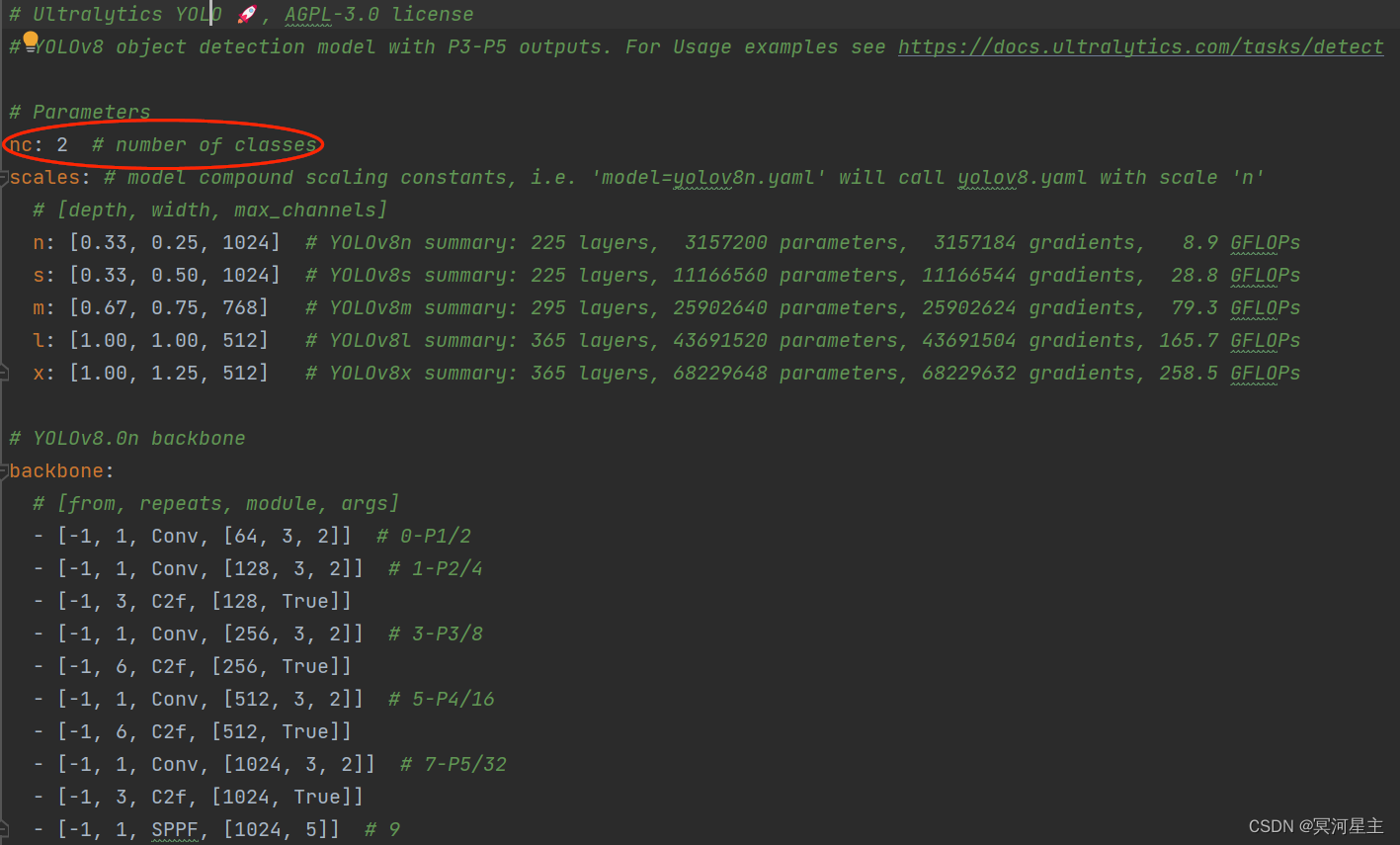
制作完这两个yaml文件后,需要下载相应的预训练权重(如预测任务的yolov8n.pt,分类任务的yolov8n-cls.pt等等),然后我们就可以训练自己的任务了,具体训练代码可以参考官方文档实例,也可根据最前面1.2python使用方法进行简单修改,下面是我的训练时代码,注意两个yaml文件和权重文件在训练前要指定其相应的位置。
from ultralytics import YOLO
model = YOLO("ultralytics/cfg/models/v8/fruits_model.yaml")
model = YOLO("yolov8n.pt")
results = model.train(data="datasets/fruits/myfruits.yaml", epochs=50, workers=0, device=0)
results = model.val()














 9261
9261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









