






本文除了介绍安装大模型 phi-4 和 千问 2.5以外,还会详细介绍大模型本地部署的一些概念,适合感兴趣的朋友阅读,,完整阅读预计 10分钟。

我现在的生活已经离不开 AI 了,他帮我度过了许多工作中的卡壳时刻。
不过我经常遇到:
在飞机上赶方案,正好卡住,想找 AI 帮忙,但是许多航班并没有网络服务。
需要处理公司内部事务,需要 AI 帮忙分析,但是…不敢把内容传到其他平台。
急需一个本地能跑的大模型,如果能联网搜索,就更好了。
看完本文,你就能收获一个能联网搜索的本地 AI 对话软件。
本地大模型的优势:

🆓 完全免费:不用每月支付 ChatGPT Plus 的订阅费
🚀 速度飞快:本地运行,不用等待网络延迟(快慢取决于你的电脑配置)
🔒 隐私安全:所有对话都在你自己电脑上完成,数据安全有保障
💪 完全控制:可以自由选择和调整模型
⚡ 永不掉线:不需要联网也能用,在飞机上、火车上没有网络也能随时可用
简单来说,100% 本地运行,100% 安全,100% 免费。
而整个过程只需要 35 分钟,并且不需要任何编程基础。
⏱️ 安装 Ollama:10分钟
⏱️ 下载模型:15分钟(取决于网速)
⏱️ 安装浏览器插件:5分钟
⏱️ 设置和测试:5分钟
Ps. 如果部署出错,可以在后台留言,我尽可能帮你解决。
开始之前
需要检查电脑配置
/ 01
懒得看的可以直接跳到二节。
01
什么样的配置能跑本地模型?
简单理解,大部分能运行吃鸡的游戏都能安装大模型。
大模型的运行主要看显存,硬件配置上,最基础的配置需要至少8GB显存或统一内存,不过这种配置只能跑4bit量化(先不用管量化的概念)的7B小模型,效果和性能都比较一般。
如果想要日常使用,建议配置16GB显存,这样可以跑INT8量化的13B模型,或者完整加载7B模型,使用体验会好很多。
比较理想的配置是24GB显存,可以完整加载13B模型,量化后甚至可以跑更大的模型。
如果是专业开发,最好是 32GB及以上的显存,这样就能玩转更多大模型,也有更好的扩展性。
说到实际使用体验,消费级显卡大概需要2-4秒才能给出回复,专业显卡可以做到1-2秒,如果用CPU推理可能要等5-10秒。
另外,本地大模型运行时,最好预留30%的显存给系统开销,特别是长对话可能会逐渐累积显存占用。
02
检查我的配置
Windows用户:
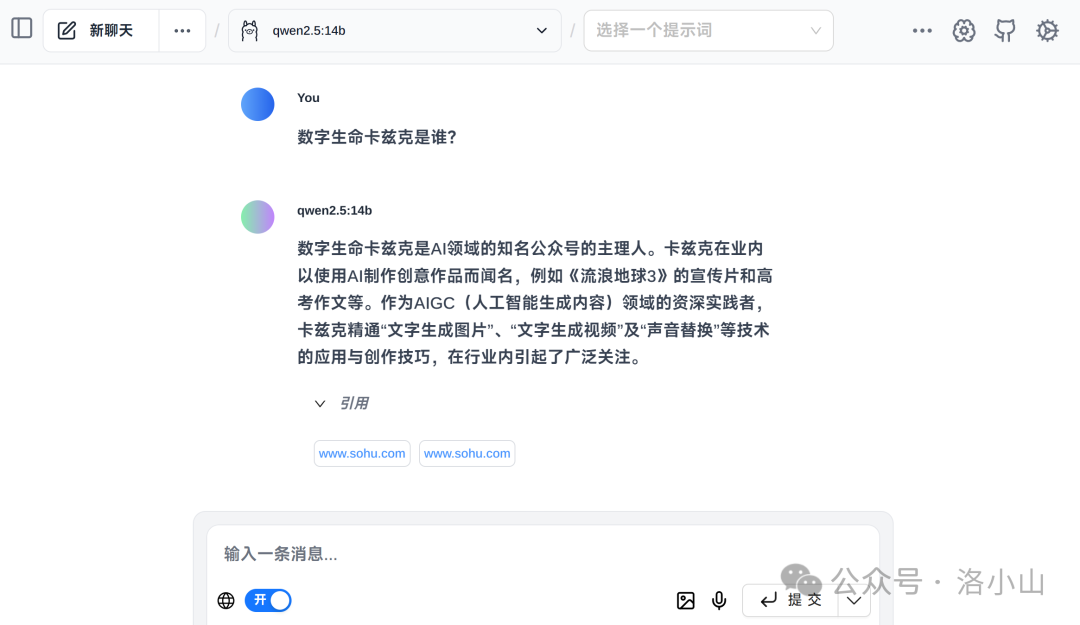
按下 Win + X,选择"系统",在系统页面可以查看内存大小。
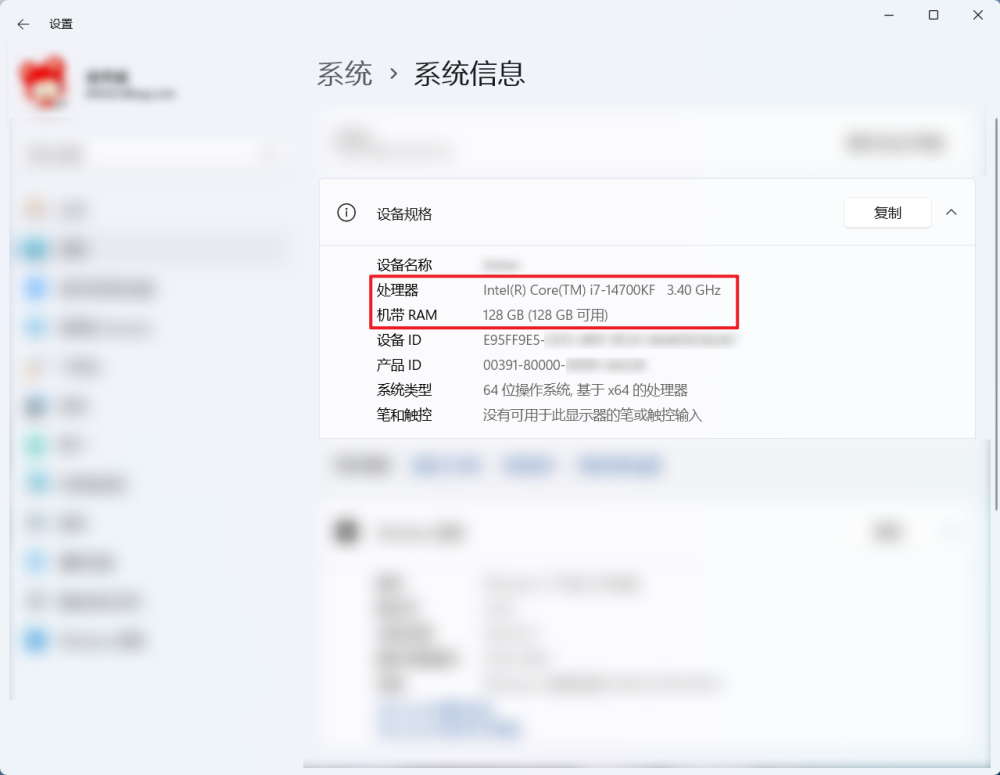
按下 Win + X,选择"设备管理器",在设备管理器中可以查看显卡型号。
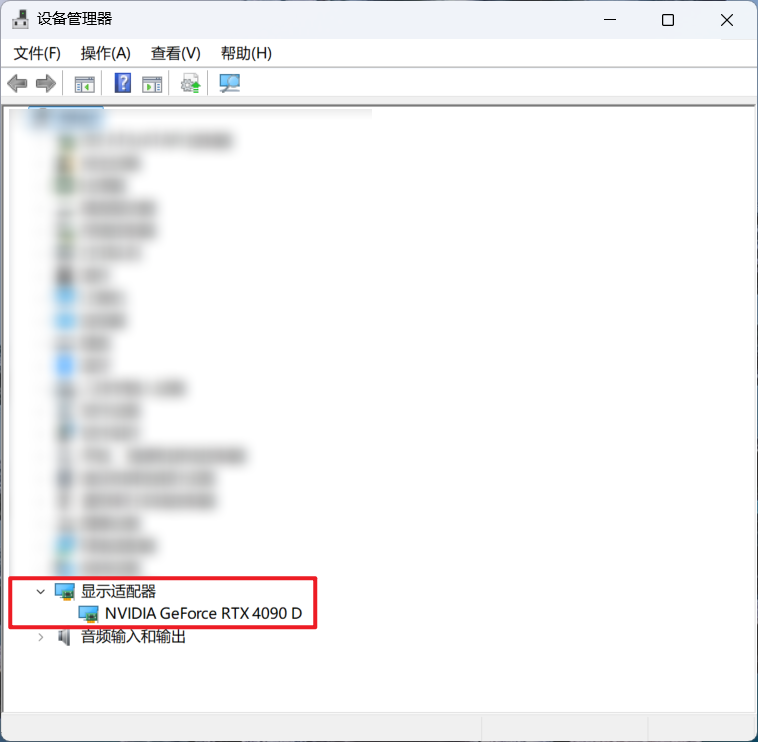
如果“显示适配器”显示 Inten® HD Graphics xxxx ,意味着你的设备是集显,虽然说不完全不能装,但可能性能会比较糟糕。
Mac用户:
点击左上角苹果图标,选择"关于本机",可以看到内存大小和芯片型号。

03
基础配置要求
Windows电脑配置要求:
💻 内存:最少 8GB,建议 16GB
🎮 显卡:需要 NVIDIA 显卡,显存至少 4GB(比如 GTX 1060 或更好的)
🔧 CPU:2014 年后的CPU一般都可以
💾 硬盘:至少要有 20GB 的空闲空间
推荐配置:
入门级可以选 RTX 3060 12GB,
主流配置是 RTX 4080 16GB,
高端就是 RTX 4090 24GB(也可以等 5090…)。
Mac电脑配置要求:
Intel Mac:
💻 内存:最少 8GB,建议 16GB
M系列 Mac(M4/M3/M2/M1):
💻 统一内存:最少 8GB,建议 16GB 或以上
⚡ 性能提示:统一内存越大,运行越流畅
推荐配置:
M1 Pro 及以上的机型(16GB以上统一内存)都可以尝试。
推荐 M4 Pro 以上机型,性价比最高。
开始安装 Ollama
/ 02
Ollama 是本地跑开源大模型最好的软件之一,不管是 windows 还是Mac,都能通过它跑各类模型。
浏览器打开 ollama.com ,点击下载按钮,选择对应的操作系统可以了。
安装Ollama的流程及其简单,直接无脑下一步即可。
接下来运行控制台。Windows 按下 Win + R ,输入cmd。
苹果用户找到 “终端” ,启动。
输入
ollama -v
看到下面的信息就表示安装成功了。
ollama version is 0.5.4
如果没有安装成功,请重新安装试试,或者后台留言。
挑选合适的模型
/ 03
已经安装好了 Ollama 之后,接下来就是选择合适的模型。
01
推荐模型
如果你平时使用英文环境,推荐:
phi-4``llama 3.2``mixtral``gemma2
如果你平时使用中文环境,推荐:
qwen2.5``glm4
如果你想要使用大模型写代码,推荐:
qwen2.5-coder
接下来,就是挑选合适的模型尺寸。
模型尺寸可以在 ollama.com/search 上查看
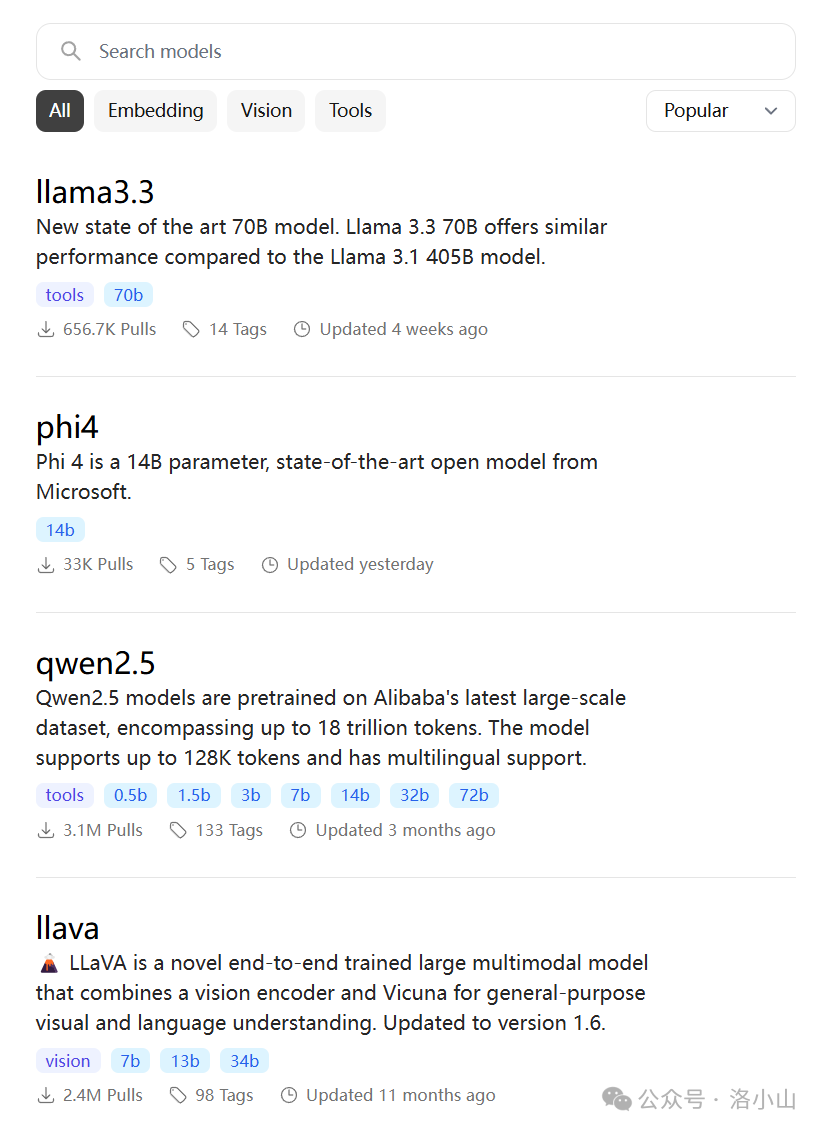
下面蓝色的标签含义是:模型支持的尺寸,比如 千问(qwen2.5)模型就有 0.5b - 72b 等多种尺寸可选。
进入模型介绍页面后,还可以点 Tags 查看模型的所有尺寸。
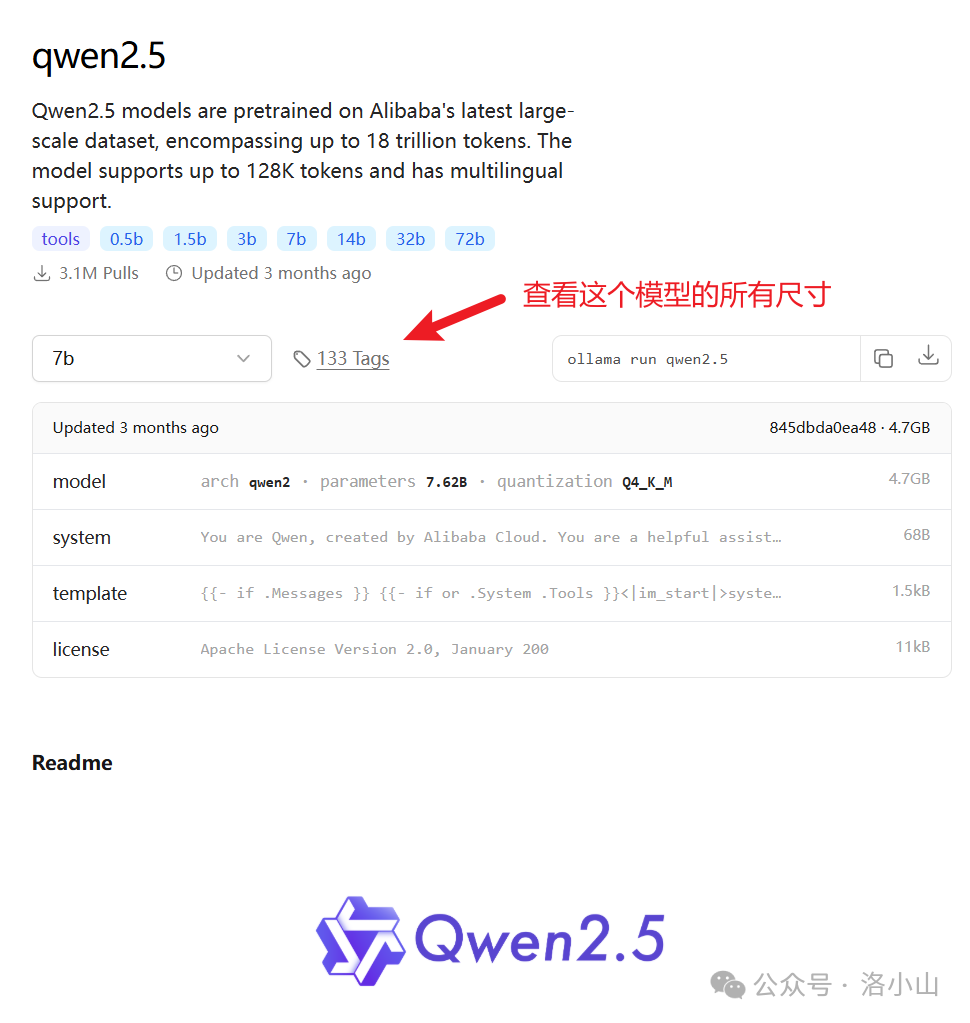

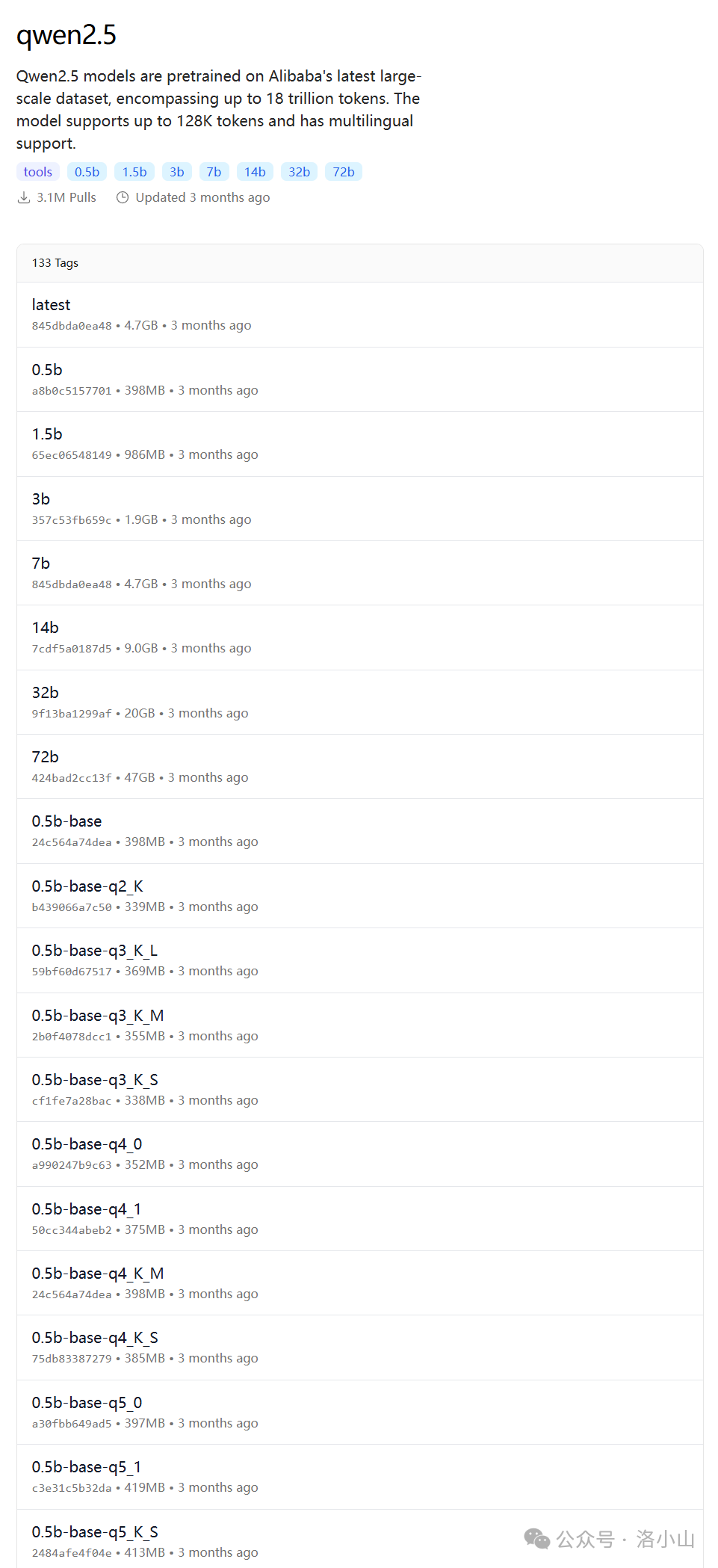
Ollama 的模型命名相对规则,遵循下面规则。

02
大模型的尺寸有哪些?
从小到大来说,目前主流的大模型尺寸大概:
· 1B左右的小模型能做一些基础的对话和补全:比如 llama3.2 就只有 1B。
· 7B是目前最受欢迎的尺寸,速度快而且可以应付大部分对话与思考场景。像 Llama3.1-8B、Mistral-7B都是这个大小,在家用显卡上就能跑,而且效果已经相当不错。
· 13B算是性能和资源消耗的平衡点,比如 Qwen2.5-14B。这个尺寸的模型能力明显比7B强,但对硬件要求也更高。
· 30B-35B是专业级需求性价比最高的尺寸,这个档位的开源大模型不太多,一些不错的比如Yi-34B 或 Qwen2.5-32B。
· 70B现在是开源大模型的天花板级别,像Llama2-70B、Qwen2.5-72B 就是这个量级。不过一般人在本地很难跑起来,得多个显卡才行,主要是研究机构和大厂在用。
· 更大的模型比如GPT-4,参数量可能上千亿,具体多大外界也不太清楚(据说 4o-mini 只有 8b,但没有官方证实),但这种级别的模型需要大量算力和优化技术支持,一般都是通过API调用。
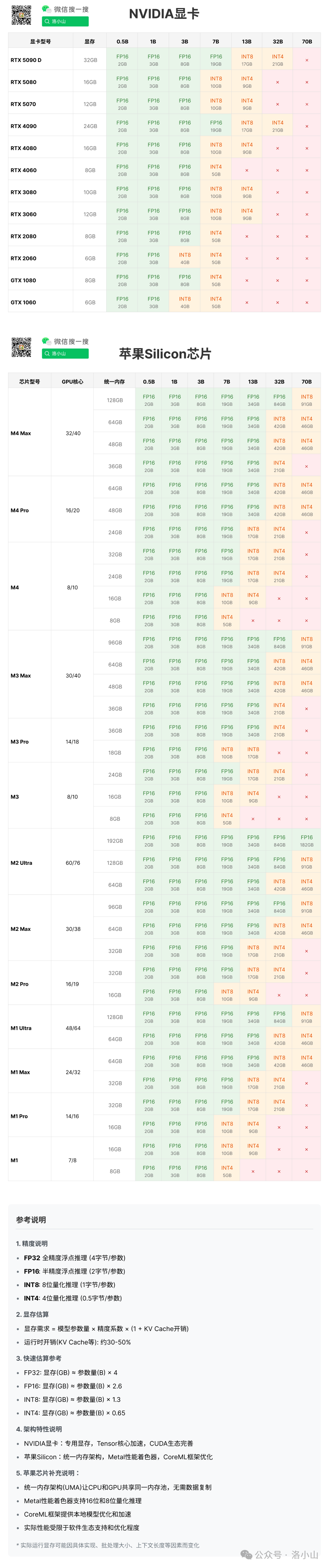
为了便于分辨显存和大模型之间的关系,我简单列了一个关系表。
如果觉得模糊,后台回复“显卡”下载原版高清版本。
显卡可运行大模型关系表:
03
什么是大模型量化?
什么是量化?
量化就是把AI模型中的数字变得更"简单"。原本模型里的数字精确到小数点后很多位,量化后用更简单的数字代替,这样可以让模型变得更小,运行更快。
核心概念:
用更省空间的方式表示数字。比如:
-
原始数字:3.14159265359 → 量化后:3.14
-
原始数字:9.99999999999 → 量化后:10
通俗的例子,就像微信发照片:
-
原图:超清晰,但文件很大
-
压缩图:稍微模糊一点,但文件小很多
-
实际聊天时,压缩图也够用
为什么要量化?
没有量化的问题:
-
模型太大,家用电脑带不动
-
运行太慢,响应不及时
-
需要很贵的显卡
量化后的好处:
-
体积变小,普通电脑也能用
-
运行变快,响应更及时
-
便宜的显卡也能跑
04
或者安装下面的模型?
了解基本概念过后,我们就可以更好地挑选合适自己的大模型了。
我们可以点击开始按钮,输入 cmd 之后回车,打开命令控制台。
Ollama 的安装指令是:
ollama run 模型名称
推荐你使用:
ollama run qwen2.5:3b
ollama run qwen2.5:7b
ollama run qwen2.5:14b
ollama run phi4
ollama run glm4
输入指令之后,如果你已经下载好了模型,就会直接进进入对话,如果没有,就会进入下载流程。
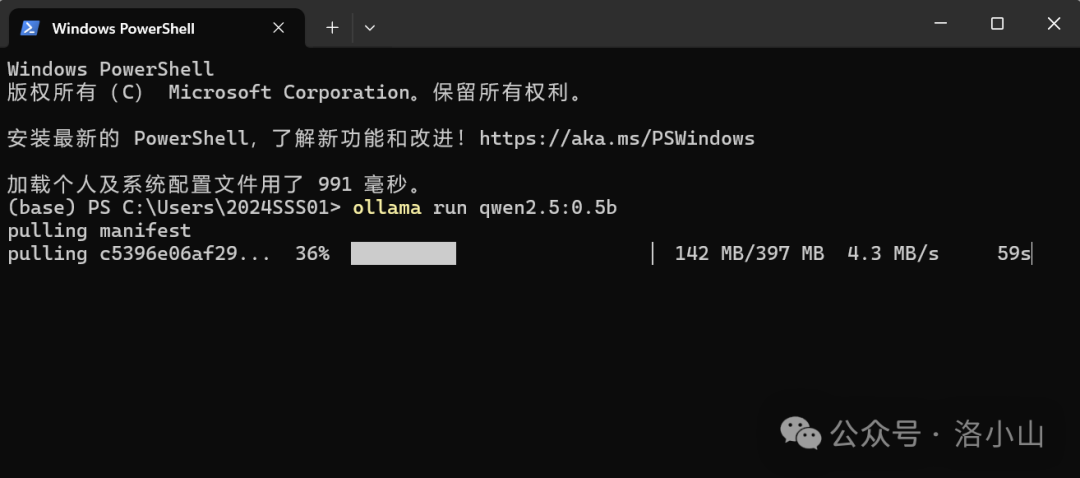
当你看到这个界面的时候,恭喜你,你已经完成了大模型的本地部署。
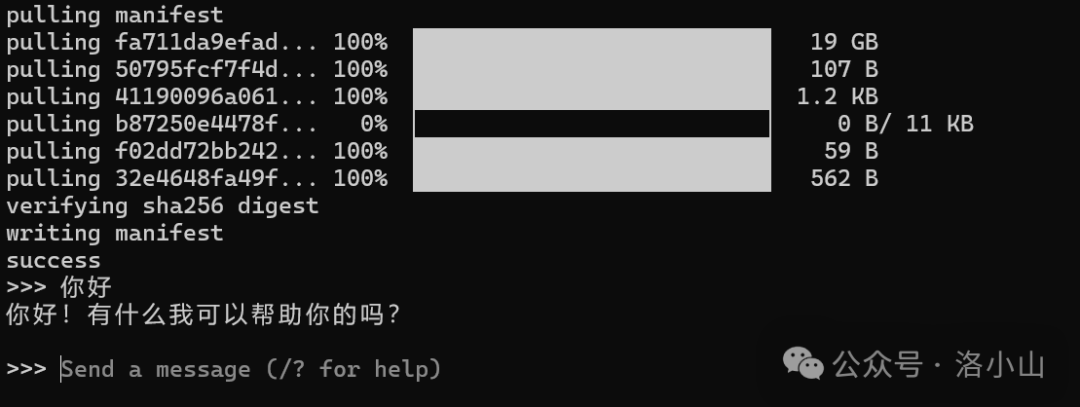
但丑丑的控制台体验不好,我们要想办法搞一个好看的界面。
下载一个好用的浏览器插件
/ 04
这里推荐一个开源的聊天界面:page-assist
这是一个体验极佳的开源插件,整体交互体验类似ChatGPT。

首先,先访问 github ,安装或者下载浏览器插件。
https://github.com/n4ze3m/page-assist
如果你能访问谷歌,就点击右侧的链接直接安装;
如果你不能访问谷歌,就点击右下角的 Release ,下载官方安装包。
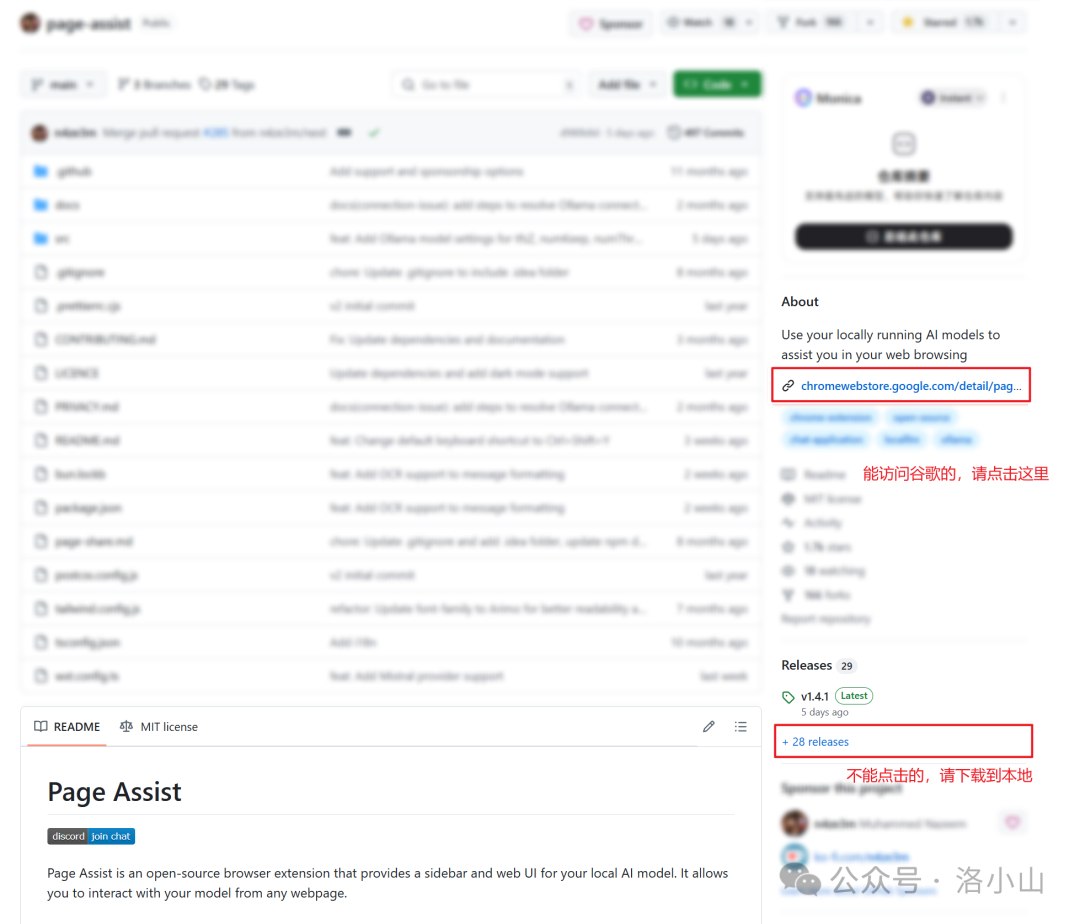
下载完成之后,找到一个合适的地方,解压缩。
推荐保存到 D盘的 Program Files 文件夹下面。
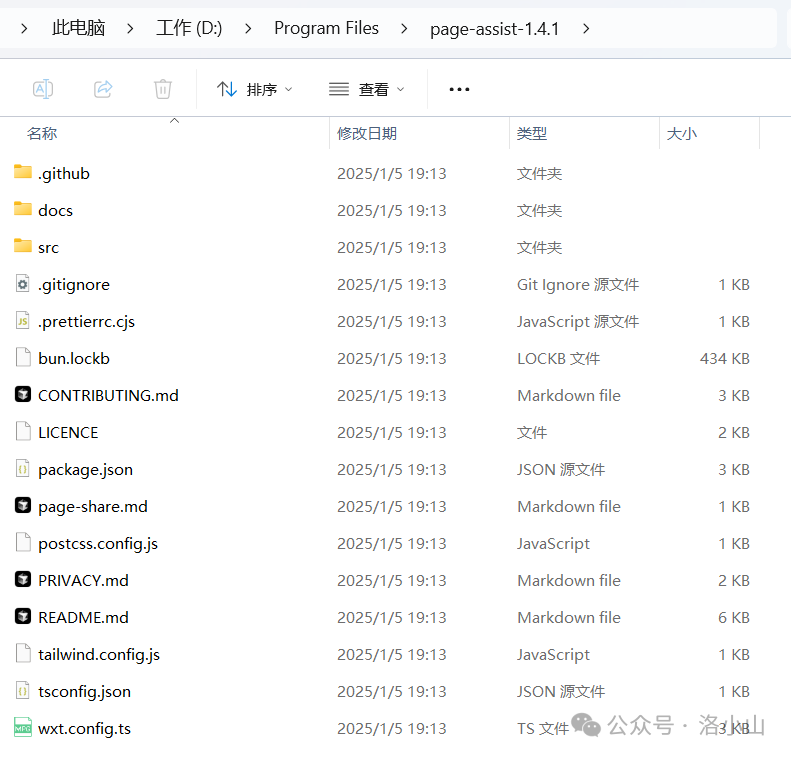
下载完成后,进入谷歌浏览器,然后点击右上角,找到管理扩展程序。
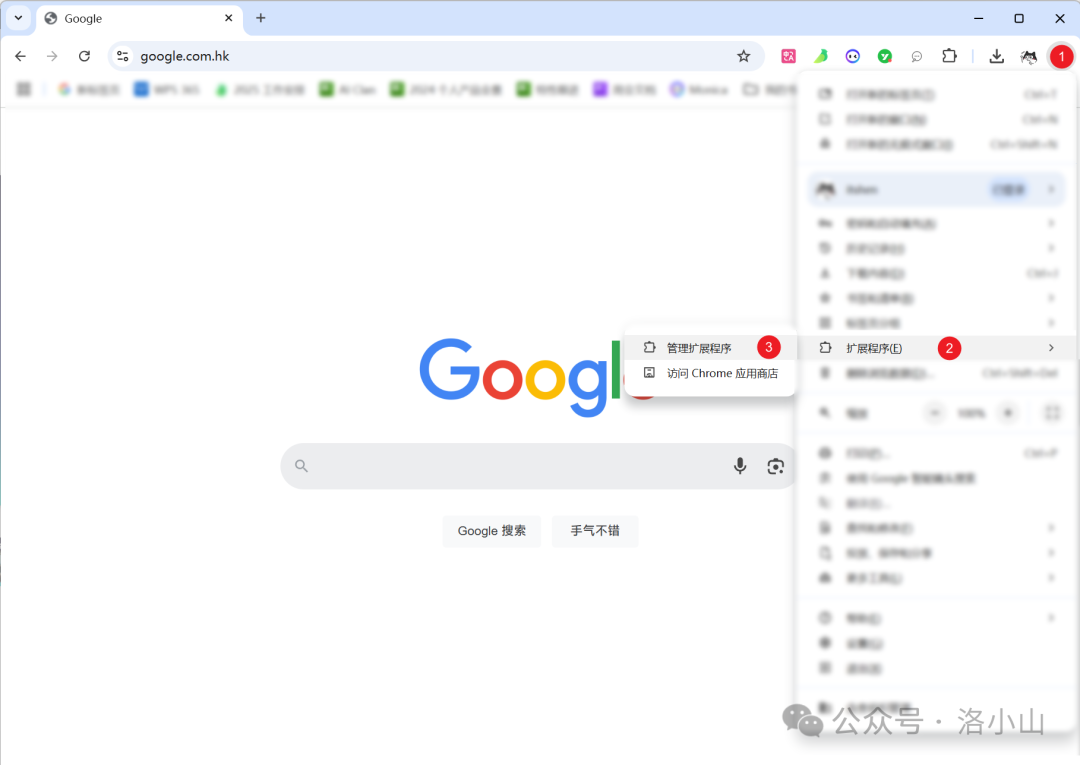
打开开发者模式之后,点击加载已解压的扩展程序。
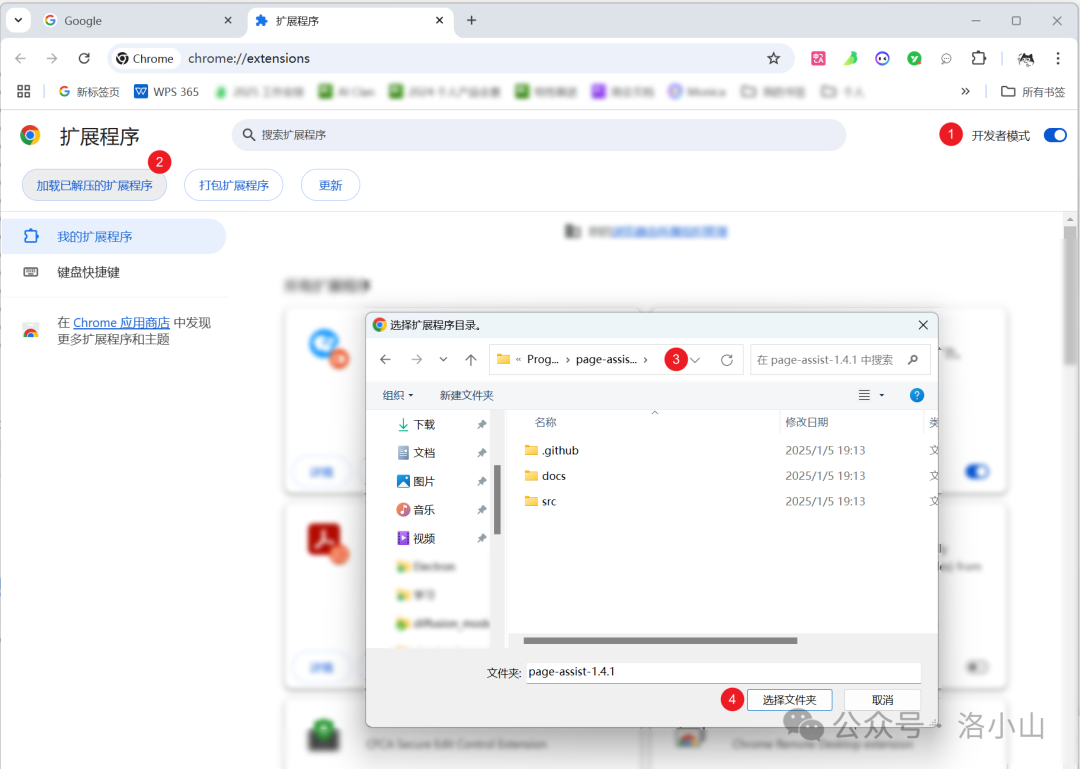
找到刚才保存的位置,点击选择文件夹就可以了。
这个时候,地址栏右侧,有一个 气泡的按钮,点击就可以启动了。
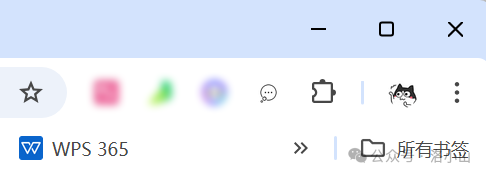
现在你就可以使用本地的 AI 了!
进阶:联网搜索
/ 05
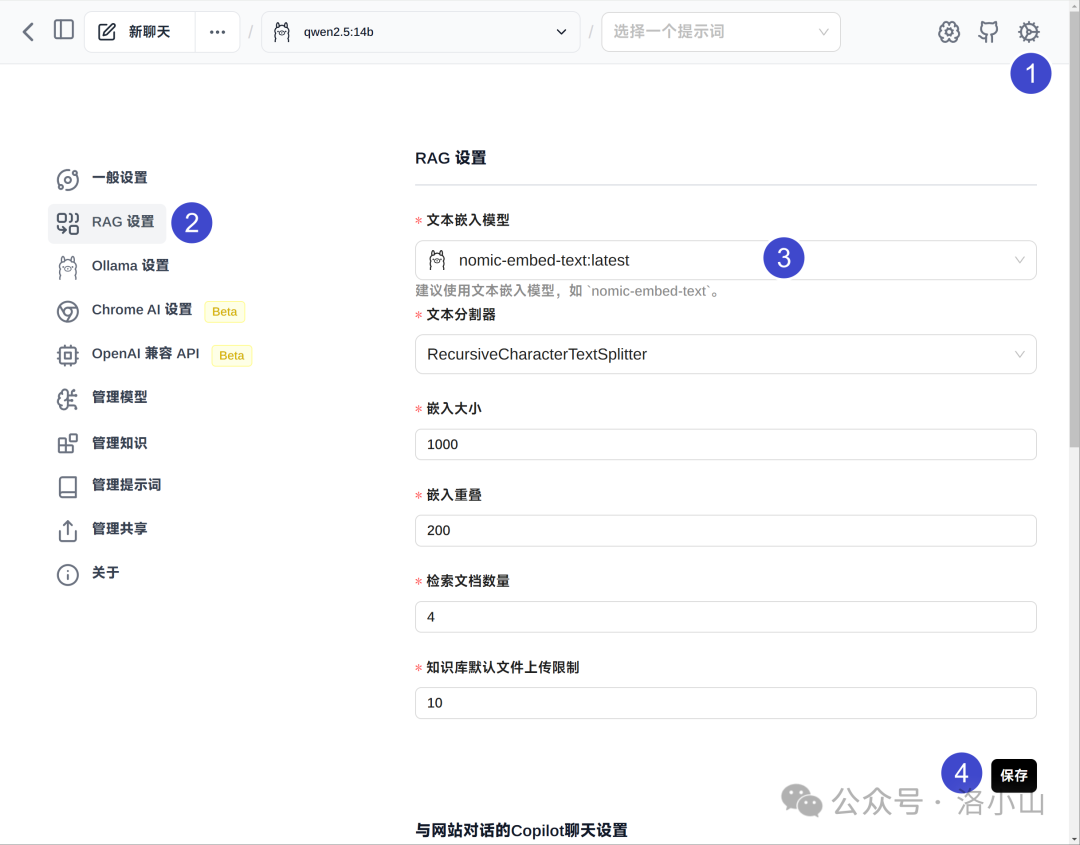
我们需要先安装一个内容解析的模型,推荐使用:
ollama run nomic-embed-text
然后点击 RAG 设置,选择刚才下载好的模型,点击保存。
再创建新聊天,你就拥有了你自己的 秘塔搜索 或者 kimi啦!
让我们试一试搜索最新的信息,确认 AI 是从网上找的答案。
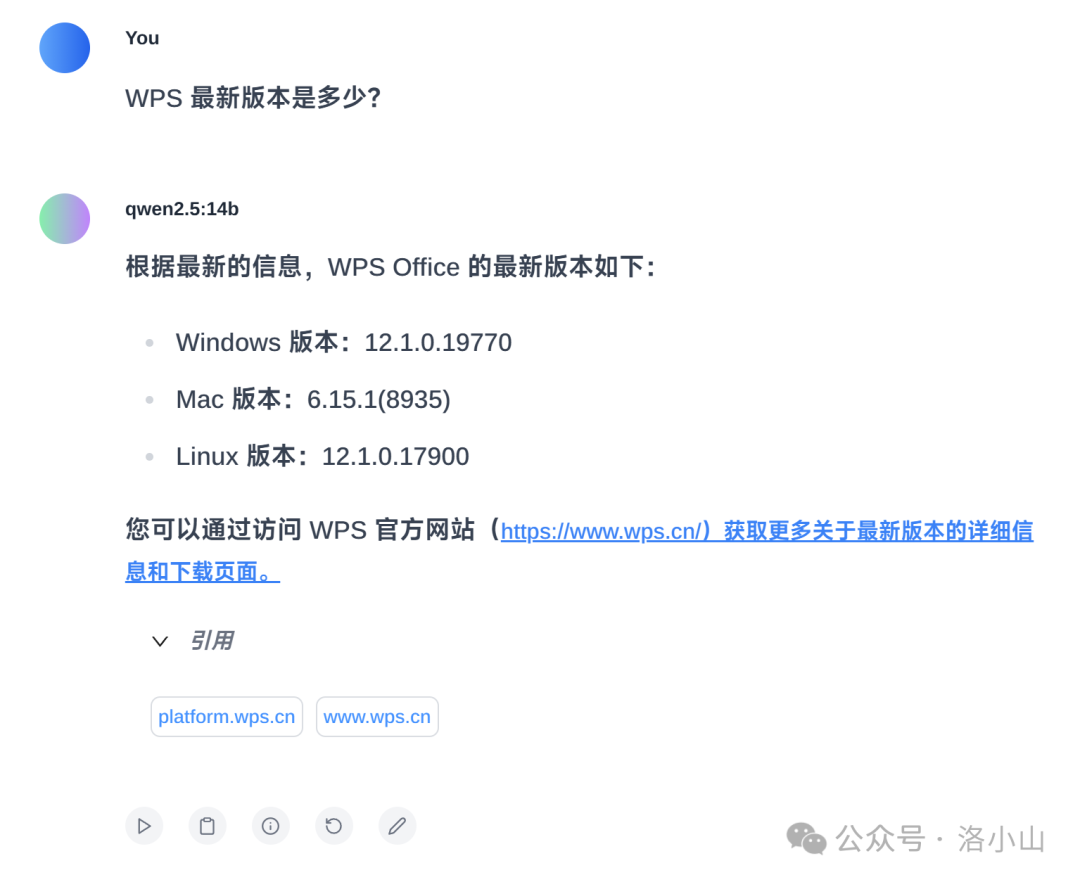
完美!
快去试试吧,如果过程中有疑问,欢迎后台留言。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 8375
8375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









