






1.前言
本文源自本人的数据采集课设,主要重心放在的数据采集上,对于模型的搭建并不熟练,望谅解。
2.数据集
本次实验数据集为个人在必应,百度等搜索引擎爬取,数据集质量差。各位如果想要复现resnet,推荐使用fair face数据集(对于年龄,男女,种族都做了标签处理,数据量大,推荐使用,下方是下载链接,如果github下载速度慢可以使用百度网盘)joojs/fairface: FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age (github.com)
以下是百度网盘链接分享(2.5G左右)
链接:https://pan.baidu.com/s/15svQUi-BdKZ3KH6ydK8fxg
提取码:HHHH
--来自百度网盘超级会员V1的分享
3.resnet技术介绍
ResNet(Residual Network)是一种深度学习神经网络架构,它在解决深度神经网络训练过程中的梯度消失和梯度爆炸问题上取得了显著的成功。由Kaiming He等人在2015年提出,是ImageNet图像分类比赛中获胜的关键架构之一。
以下是ResNet技术的一些关键点和特征:
-
残差学习(Residual Learning):
- ResNet引入了残差块(Residual Block),通过引入跳跃连接(skip connection)来实现残差学习。
- 普通的神经网络会尝试学习输入和输出之间的映射关系,而残差学习则试图学习残差(残余)映射。这通过将输入直接添加到网络的输出来实现。
-
跳跃连接(Skip Connection):
- 在每个残差块中,输入被直接添加到网络的输出,形成了一个跳跃连接。这使得梯度能够更轻松地通过整个网络传播,避免了梯度消失问题。
- 跳跃连接有助于减轻训练过程中的梯度消失,并且允许更容易地训练非常深的网络。
-
网络深度:
- ResNet通常以深度的方式设计,包含数十、甚至上百个卷积层。
- 通过使用残差学习,ResNet能够在更深的网络中学习更复杂的特征表示。
-
全局平均池化(Global Average Pooling):
- ResNet在最后一层卷积层之后使用了全局平均池化,将每个特征图的所有值取平均值。这将整个特征图转换为一个向量,作为最终的分类层的输入。
-
不同版本:
- ResNet有不同的版本,如ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,它们的数字表示网络中残差块的层数。
-
应用领域:
- ResNet主要用于图像分类任务,但由于其强大的特征学习能力,也被广泛应用于目标检测、语义分割和其他计算机视觉任务中。
总体而言,ResNet通过引入残差学习和跳跃连接的机制,成功解决了深度神经网络中常见的梯度消失问题,使得更深、更复杂的网络能够更容易地训练和优化。
4.代码实现
1.python实现,库函数调用
import torch
from torch.nn import Dropout
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import numpy as np
import matplotlib.pyplot as plt
import os
from tqdm import tqdm2.模型训练函数
def train_and_valid(model, loss_function, optimizer, scheduler, epochs):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
history = []
best_acc = 0.0
best_epoch = 0
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(tqdm(train_data)):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(tqdm(valid_data)):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_function(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/train_data_size
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/valid_data_size
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if best_acc < avg_valid_acc:
best_acc = avg_valid_acc
best_epoch = epoch + 1
torch.save(model, './models/' + '_mybestmodel_.pt')
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch+1, avg_train_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start
))
# 每个 epoch 完成后根据验证 loss 更新学习速率
scheduler.step(avg_valid_loss)
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
return model, history这里有一个很优秀的调参的东西,叫做根据模型的性能动态地调整学习率。这个学习率调度器的主要目标是根据模型的性能动态地调整学习率,以便在训练过程中更有效地收敛。
3.数据集处理
image_transforms = {
'train': transforms.Compose([
transforms.Resize(size=(224, 224)),
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(size=224),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}
# 加载数据
dataset ='D:/MYDATA/125-race_small'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'valid')
batch_size = 16
num_classes = 3
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid'])
}
train_data_size = len(data['train'])
valid_data_size = len(data['valid'])
train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=4)#shuffle是随机打乱,时序的不允许打乱
valid_data = DataLoader(data['valid'], batch_size=batch_size, shuffle=True, num_workers=4)
print(train_data_size, valid_data_size)4.模型训练
resnet50 = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 3),
nn.LogSoftmax(dim=1)
)
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
for param in resnet50.parameters():
param.requires_grad = True
resnet50 = resnet50.to('cuda:0')
# 定义损失函数和优化器
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(resnet50.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-9)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='max',factor=0.8, patience=2)
num_epochs = 50
trained_model, history = train_and_valid(resnet50, loss_func, optimizer, scheduler, num_epochs)
# 保存模型和历史记录
# torch.save(history, 'models/'+'_history.txt')
torch.save(trained_model, 'models/'+'_trained_model.pt')
# 可视化训练结果
history = np.array(history)
plt.plot(history[:, 0:2])
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1)
plt.savefig(dataset + '_loss_curve.png')
plt.show()
plt.plot(history[:, 2:4])
plt.legend(['Tr Accuracy', 'Val Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig(dataset + '_accuracy_curve.png')
plt.show()scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='max',factor=0.8, patience=2)
这个就是上面说的loss动态调节学习率的函数
这代码片段涉及到PyTorch中的学习率调度器(learning rate scheduler),具体而言是optim.lr_scheduler.ReduceLROnPlateau。
pythonCopy code
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.8, patience=2)
让我们逐一解释各个参数:
-
optimizer:
- 这是你正在使用的优化器(optimizer),比如随机梯度下降(SGD)或Adam。学习率调度器将根据模型的性能动态地调整这个优化器的学习率。
-
mode:
- 这是衡量性能的指标,决定了学习率调度器是监测指标的增加还是减少。在这里,
'max'表示希望监测的指标(可能是验证集上的准确性或其他性能指标)越大越好。
- 这是衡量性能的指标,决定了学习率调度器是监测指标的增加还是减少。在这里,
-
factor:
- 学习率调度因子,用于调整学习率。当观察到指标不再改善时,学习率将乘以这个因子。在这里,
factor=0.8表示每次学习率调整时,将学习率乘以0.8。
- 学习率调度因子,用于调整学习率。当观察到指标不再改善时,学习率将乘以这个因子。在这里,
-
patience:
- 当连续指定的轮次中监测的指标没有改善时,调度器会触发学习率的调整。
patience=2表示如果在连续两个epoch中都没有看到性能改善,那么就触发学习率的调整。
- 当连续指定的轮次中监测的指标没有改善时,调度器会触发学习率的调整。
这个学习率调度器的主要目标是根据模型的性能动态地调整学习率,以便在训练过程中更有效地收敛。如果模型在连续指定的轮次中没有看到性能的改善,学习率将通过乘以factor进行调整,以促使模型更快地收敛或跳出局部最优点。这是一种自适应学习率调整的方法,经常用于训练深度神经网络。
5.结果可视化
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
# 迁移学习
# resnet50 = models.resnet50(weigths=models.ResNet50_Weights.DEFAULT)
# for param in resnet50.parameters():
# param.requires_grad = False
fc_inputs = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 3),
nn.Softmax(dim=1)
)
model=torch.load('./models/_mybestmodel_.pt')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
valid_acc = 0.0
class_correct = [0. for i in range(num_classes)]
class_total = [0. for i in range(num_classes)]
confusion_matrix = torch.zeros(num_classes, num_classes)
with torch.no_grad():
for inputs, labels in valid_data:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(len(labels)):
confusion_matrix[labels[i], predicted[i]] += 1
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
print('*'*20+'混淆矩阵'+'*'*20)
print(confusion_matrix)
import numpy as np
import matplotlib.pyplot as plt
# 定义类别名称
classesy = ['Pre-Black', 'Pre-White', 'Pre-Yellow']
classesx = ['Ture-Black', 'Ture-White', 'Ture-Yellow']
# 绘制热力图
fig, ax = plt.subplots()
im = ax.imshow(confusion_matrix, cmap='Blues')
# 设置标题和标签
ax.set_title('Confusion Matrix')
ax.set_xticks(np.arange(len(classesx)))
ax.set_yticks(np.arange(len(classesy)))
ax.set_xticklabels(classesx)
ax.set_yticklabels(classesy)
# 添加数值标签
for i in range(len(classesx)):
for j in range(len(classesy)):
text = ax.text(j, i, confusion_matrix[i, j],
ha="center", va="center", color="w")
# 添加颜色条
cbar = ax.figure.colorbar(im, ax=ax)
# 显示图形
plt.show()
classes=['黑种人的人脸识别准确率','白种人的人脸识别准确率','黄种人的人脸识别准确率']
for i in range(num_classes):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
valacc=(class_correct[0]+class_correct[1]+class_correct[2])/(class_total[0]+class_total[1]+class_total[2])
from matplotlib import pyplot as plt
for i in range(3):
plt.title(classes[i], fontproperties='KaiTi', fontsize=20, color="red")
labels = ['ture', 'false']
sizes = [class_correct[i] / class_total[i], 1 -class_correct[i] / class_total[i]]
explode = (0, 0)
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=False)
plt.axis('equal')
plt.show()
plt.title("整体识别准确率", fontproperties='KaiTi', fontsize=30, color="red")
labels = ['ture', 'false']
sizes = [valacc, 1-valacc]
explode = (0, 0)
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=False)
plt.axis('equal')
plt.show()可视化结果


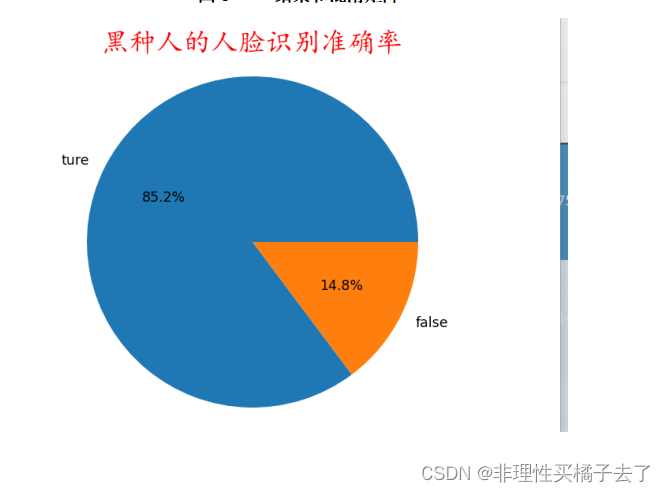


6.总结
1.由于实验的数据集是个人爬取,规模性小,导致结果十分差劲!大家采用专门数据集的准确率应该会更好!
2.resnet提供了预训练模型,github上可以直接调用预训练模型加快训练速度,有兴趣的大佬也可以从头搭建。
7.源码
import torch
from torch.nn import Dropout
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import numpy as np
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
def train_and_valid(model, loss_function, optimizer, scheduler, epochs):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
history = []
best_acc = 0.0
best_epoch = 0
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(tqdm(train_data)):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(tqdm(valid_data)):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_function(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/train_data_size
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/valid_data_size
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if best_acc < avg_valid_acc:
best_acc = avg_valid_acc
best_epoch = epoch + 1
torch.save(model, './models/' + '_mybestmodel_.pt')
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch+1, avg_train_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start
))
# 每个 epoch 完成后根据验证 loss 更新学习速率
scheduler.step(avg_valid_loss)
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
return model, history
if __name__ == '__main__':
# 数据增强
image_transforms = {
'train': transforms.Compose([
transforms.Resize(size=(224, 224)),
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(size=224),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}
# 加载数据
dataset ='D:/MYDATA/125-race_small'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'valid')
batch_size = 16
num_classes = 3
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid'])
}
train_data_size = len(data['train'])
valid_data_size = len(data['valid'])
train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=4)#shuffle是随机打乱,时序的不允许打乱
valid_data = DataLoader(data['valid'], batch_size=batch_size, shuffle=True, num_workers=4)
print(train_data_size, valid_data_size)
# def get_mean_std(loader):
# # Var[x] = E[X**2]-E[X]**2
# channels_sum, channels_squared_sum, num_batches = 0, 0, 0
# for data, _ in loader:
# channels_sum += torch.mean(data, dim=[0, 2, 3])
# channels_squared_sum += torch.mean(data ** 2, dim=[0, 2, 3])
# num_batches += 1
#
# # print(num_batches)
# # print(channels_sum)
# mean = channels_sum / num_batches
# std = (channels_squared_sum / num_batches - mean ** 2) ** 0.5
#
# return mean, std
#
#
# mean, std = get_mean_std(train_data)
#
# print(mean)
# print(std)
i=2
#1代表模型训练,2代表模型测试以及的可视化,分开运行!!!
if i==1:
resnet50 = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 3),
nn.LogSoftmax(dim=1)
)
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
for param in resnet50.parameters():
param.requires_grad = True
resnet50 = resnet50.to('cuda:0')
# 定义损失函数和优化器
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(resnet50.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-9)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='max',factor=0.8, patience=2)
num_epochs = 50
trained_model, history = train_and_valid(resnet50, loss_func, optimizer, scheduler, num_epochs)
# 保存模型和历史记录
# torch.save(history, 'models/'+'_history.txt')
torch.save(trained_model, 'models/'+'_trained_model.pt')
# 可视化训练结果
history = np.array(history)
plt.plot(history[:, 0:2])
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1)
plt.savefig(dataset + '_loss_curve.png')
plt.show()
plt.plot(history[:, 2:4])
plt.legend(['Tr Accuracy', 'Val Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig(dataset + '_accuracy_curve.png')
plt.show()
if i==2:
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
# 迁移学习
# resnet50 = models.resnet50(weigths=models.ResNet50_Weights.DEFAULT)
# for param in resnet50.parameters():
# param.requires_grad = False
fc_inputs = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 3),
nn.Softmax(dim=1)
)
model=torch.load('./models/_mybestmodel_.pt')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
valid_acc = 0.0
class_correct = [0. for i in range(num_classes)]
class_total = [0. for i in range(num_classes)]
confusion_matrix = torch.zeros(num_classes, num_classes)
with torch.no_grad():
for inputs, labels in valid_data:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(len(labels)):
confusion_matrix[labels[i], predicted[i]] += 1
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
print('*'*20+'混淆矩阵'+'*'*20)
print(confusion_matrix)
import numpy as np
import matplotlib.pyplot as plt
# 定义类别名称
classesy = ['Pre-Black', 'Pre-White', 'Pre-Yellow']
classesx = ['Ture-Black', 'Ture-White', 'Ture-Yellow']
# 绘制热力图
fig, ax = plt.subplots()
im = ax.imshow(confusion_matrix, cmap='Blues')
# 设置标题和标签
ax.set_title('Confusion Matrix')
ax.set_xticks(np.arange(len(classesx)))
ax.set_yticks(np.arange(len(classesy)))
ax.set_xticklabels(classesx)
ax.set_yticklabels(classesy)
# 添加数值标签
for i in range(len(classesx)):
for j in range(len(classesy)):
text = ax.text(j, i, confusion_matrix[i, j],
ha="center", va="center", color="w")
# 添加颜色条
cbar = ax.figure.colorbar(im, ax=ax)
# 显示图形
plt.show()
classes=['黑种人的人脸识别准确率','白种人的人脸识别准确率','黄种人的人脸识别准确率']
for i in range(num_classes):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
valacc=(class_correct[0]+class_correct[1]+class_correct[2])/(class_total[0]+class_total[1]+class_total[2])
from matplotlib import pyplot as plt
for i in range(3):
plt.title(classes[i], fontproperties='KaiTi', fontsize=20, color="red")
labels = ['ture', 'false']
sizes = [class_correct[i] / class_total[i], 1 -class_correct[i] / class_total[i]]
explode = (0, 0)
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=False)
plt.axis('equal')
plt.show()
plt.title("整体识别准确率", fontproperties='KaiTi', fontsize=30, color="red")
labels = ['ture', 'false']
sizes = [valacc, 1-valacc]
explode = (0, 0)
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=False)
plt.axis('equal')
plt.show()














 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









