







1.常规定位(⼋⼤元素定位实战)
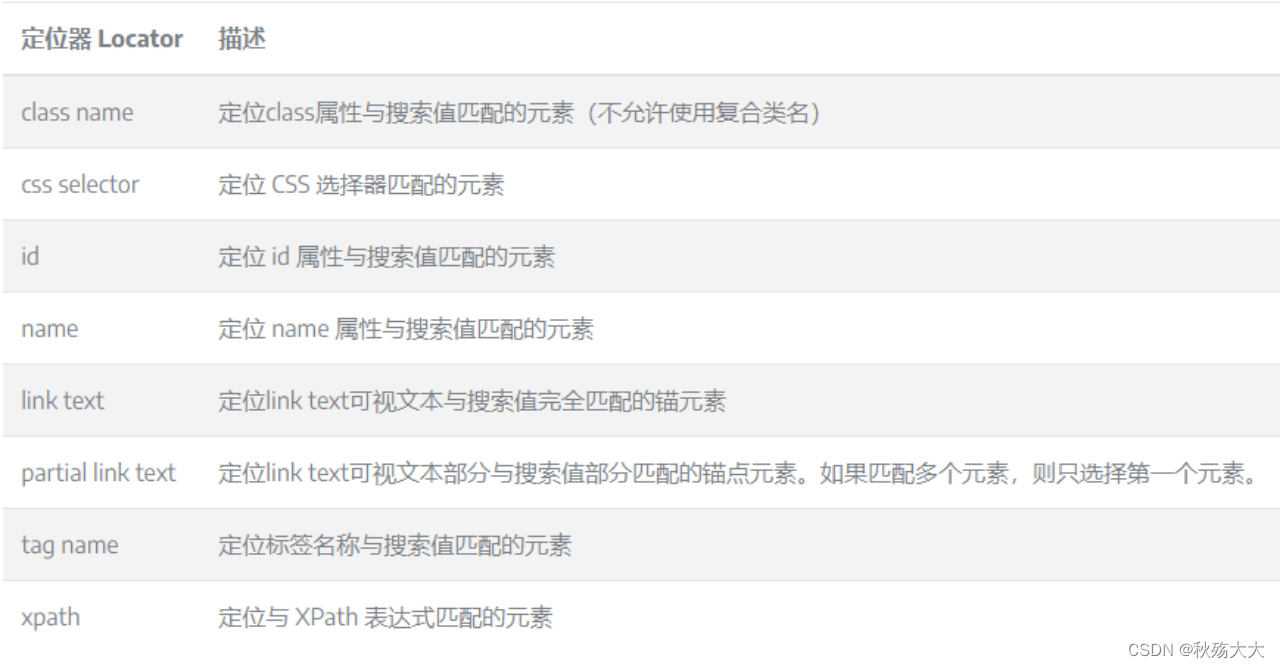 需要注意的的点:
需要注意的的点:
⻚⾯元素是在视觉上有欺骗效果, css提供元素样式,但元素定位时,我们关键是看标签的 名字 , 属性 和 text的区别,尖括号外⾯的是text,尖括号⾥⾯的是属性元素定位,就等于定位⻚⾯标签
元素定位的方式
元素定位的原理:通过定位UI界面的元素属性,来找到这些元素,然后进行其他的操作
1.id元素定位
基于元素属性中的id的值来进⾏定位, id是⼀个标签的唯⼀属性值,可以通过id属性来唯⼀定位⼀个元素,是⾸选的元素定位⽅式,动态ID不做考虑
driver.find_element(By.ID, 'id')
2.name元素定位
基于元素属性中的name的值来进⾏定位,但name并不是唯⼀的,很可能会出现重名。
driver.find_element(By.NAME,'name')3.class_name元素定位
基于元素class样式来定位,⾮常容易遇到重复的,这个⽅法的参数只能是⼀个class值,列如: class属性有空格隔开两个class的值时,只能选取其中⼀个进⾏定位。
driver.find_element(By.CLASS_NAME,'class_name') 4.tag_name元素定位 :
driver.find_element(By.TAG_NAME, 'tag_name')5.css_selector元素定位 :
css可以通过元素的id、 class、属性、⼦元素、后代元素、 index、兄弟元素等多种⽅式进⾏元素定位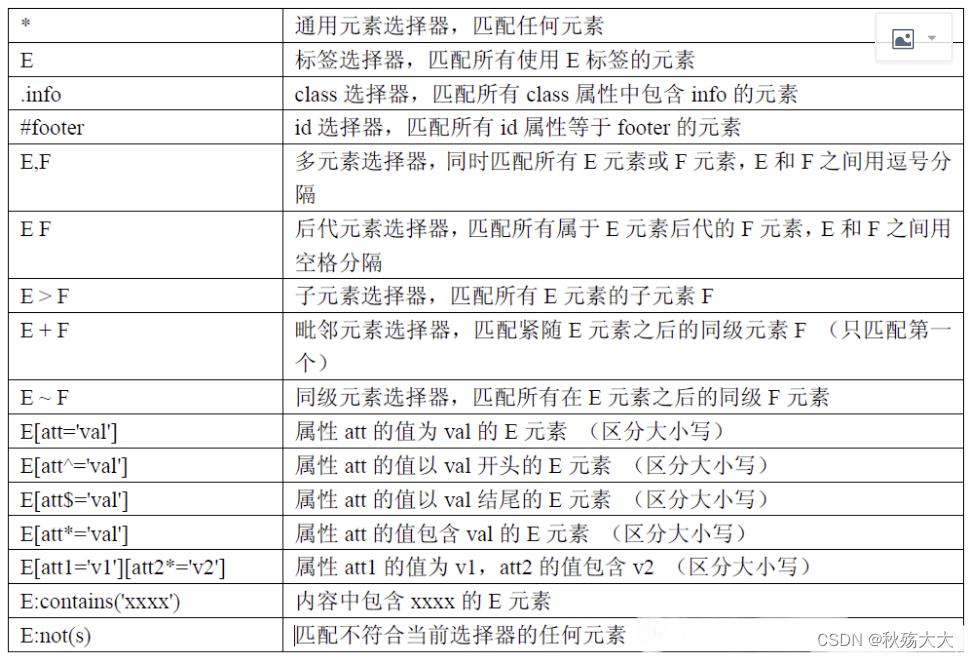
6.link_text元素定位 :
主要⽤于超链接进⾏定位,全部匹配⽂本值,使⽤在链接位置处,例如: a标签
driver.find_element(By.LINK_TEXT, 'link_text')7.partial_link_text元素定位 :
基于链接的部分⽂字来定位, link text模糊匹配,模糊查询匹配到多个符合调节的元素,选取第⼀个,同样也只使⽤在链接位置处,例如: a标签
driver.find_element(By.PARTIAL_LINK_TEXT, 'partial_link_text')8. xpath元素定位 (建议通过手写加强代码能力):
xpath是⼀⻔在xml⽂档中查找信息的语⾔。 xpath可⽤来在xml⽂档中对元素和属性进⾏遍历。由于html的层次结构与xml的层次结构天然⼀致,所以使⽤xpath也能够进⾏html元素的定位。
xpath的功能⾮常强⼤,通过xpath的各种⽅式组合,能够解决selenium⾃动化测试中界⾯元素定位的绝⼤部分问题。
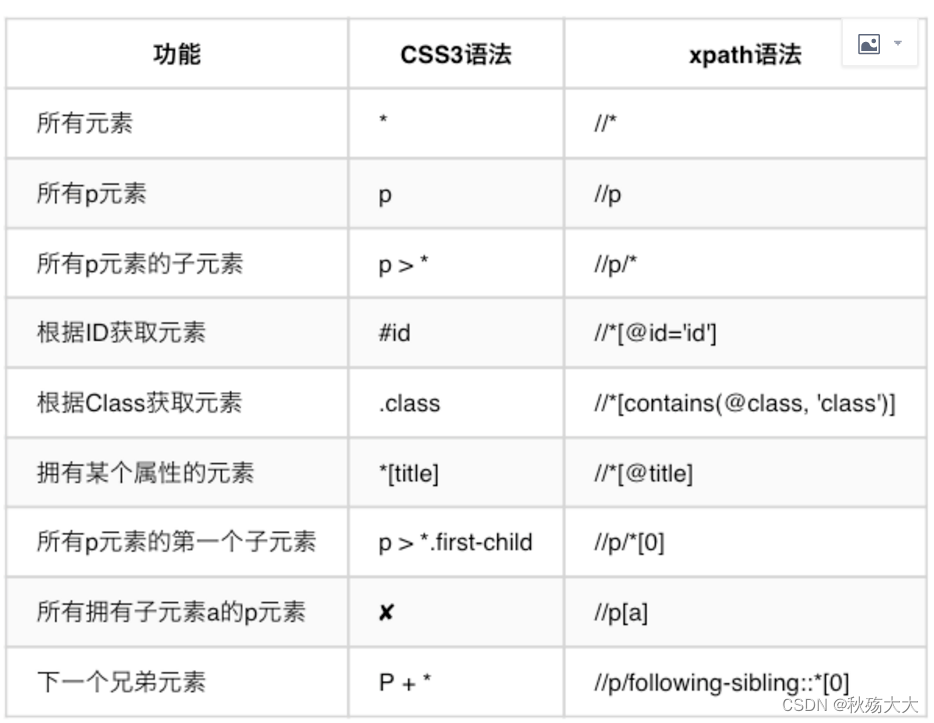
简单来说:通过元素的属性结合⻚⾯元素的结构( 层级路径关系 )来进⾏定位xpath常⻅语法⼀览表:

8.1 xpath通过绝对路径定位元素
将 Xpath 表达式从 html 的最外层节点,逐层填写,最后定位到操作元素,这种⽅法,⼀旦路径有变化会导致定位失败,所以不推荐使⽤该⽅式
8.2 xpath通过 相对路径定位元素
绝对路径与相对路径的差别与⽂件系统中的绝对和相对路径类似,相对路径是只给出元素路径的部分信息,在html的任意层次中寻找符合条件的元素, 语句以//开始 。
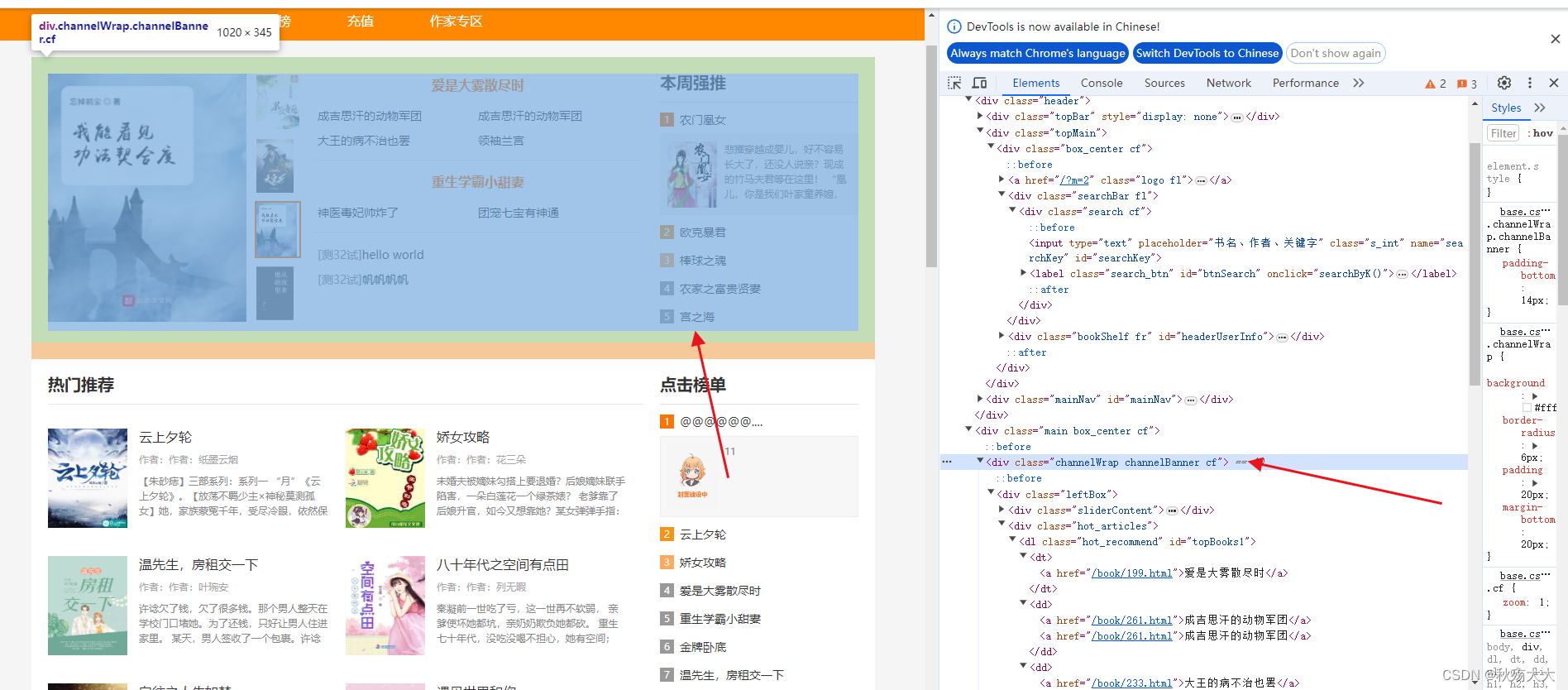
如图所示,我们有一个图书屋系统,在里面定位一个书名

通过查看相对路径可以发现代码在(//dl[@id='topBooks1']/dd[2]/a[2])这个路径下,
el = driver.find_element(By.XPATH, "//dl[@id='topBooks1']/dd[2]/a[2]")8.3 xpath通过元素属性定位元素
我们的相对路径也就是可以说成通过一个或者多个元素进行定位
单属性定位 : //input[@name='pwd']表示name属性为pwd的input
el = driver.find_element(By.XPATH, "//dl[@id='topBooks1']/dd[2]/a[2]")
多属性定位 : //a[@title="tutorial" and @rel="follow"],假如一个路径下有两个属性的id是相同的,这时我们就不能靠一个元素进行定位,就需要多个元素,如上图所示
 ,我们还可以加一个class的元素
,我们还可以加一个class的元素
el = driver.find_element(By.XPATH, '//dl[@class="hot_recommend" and @id="topBooks1"]/dd[2]/a[2]')8.4 xpath通过属性值 模糊匹配定位元素:
模糊查询的写法有两种:
starts-with : //label[starts-with(@class,'btn')], class属性值 以btn开头 的label元素
contains : //label[contains(@class,'btn')],通过属性值 包含btn 的label元素我们假如给这个属性进行模糊匹配
则代码如下
el = driver.find_element(By.XPATH, '//div[starts-with(@class,"cha")]')
el = driver.find_element(By.XPATH, '//div[contains(@class,"Banner")]')8.5 xpath 通过⽂本定位元素
⽂本内容的定位是利⽤html的text字段进⾏定位的⽅法, //span[text()='下⼀步'],由于 “下⼀步” 这⼏个字是浏览器界⾯就可以看到的, “所⻅即所得”,这种特征改的可能性⾮常⼩,优先推荐使⽤。与属性值类似,⽂本内容也⽀持starts-with和contains模糊匹配
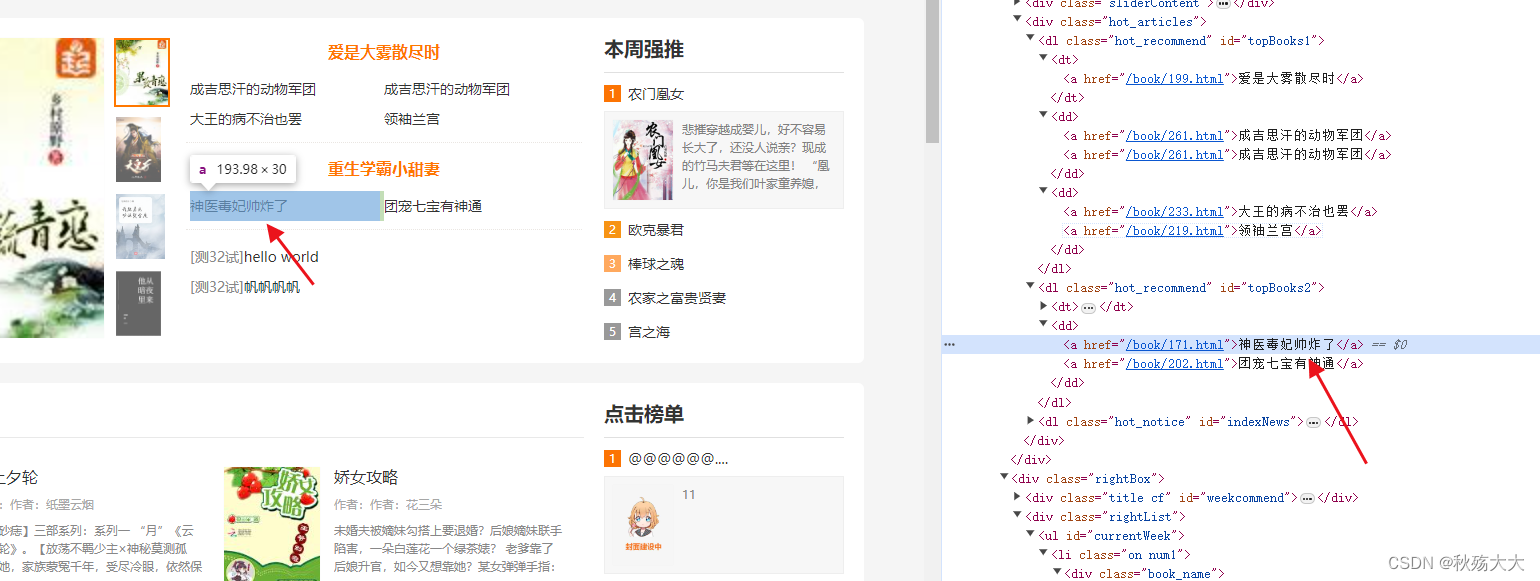
如上图所示,我们定位这个标签,我们就可以直接定义文本中的内容
el = driver.find_element(By.XPATH, "//a[text()='神医毒妃帅炸了']")因此,我们这种文本定位的方法也是可以通过模糊匹配来进行定位
el = driver.find_element(By.XPATH, '//a[starts-with(text(),"神医毒妃")]')
el = driver.find_element(By.XPATH, '//a[contains(text(),"神医毒妃")]')8.6通过通配符进行匹配
当页面上的标签是独一无二的时候,可以考虑用这种方式
el = driver.find_element(By.XPATH, '//*[@id="topBooks1"]/dt/a')
9.用css进行定位
假如我们要找到如下这个标签

# 01 id定位:
# el = driver.find_element(By.CSS_SELECTOR, "input#searchKey")
# 02 class定位:
# el = driver.find_element(By.CSS_SELECTOR, "input.s_int")
# 03 属性定位:
# el = driver.find_element(By.CSS_SELECTOR, "input[type='text']")
# 04 通过子元素定位:
# el = driver.find_element(By.CSS_SELECTOR, "div.search>input")
# 05 通过后代元素定位:
# el = driver.find_element(By.CSS_SELECTOR, "div.searchBar input")
# 06 通过元素的index值定位元素(:nth-child是div的固定写法):
# el = driver.find_element(By.CSS_SELECTOR, "div.box_center>div:nth-child(3)")
# 07 通过元素的兄弟元素定位元素:
el = driver.find_element(By.CSS_SELECTOR, "div.header>div+div")2.元素定位值Selenium4.0特有⽹格定位
selenium4版本引⼊的新⽅法,简单理解: 通过定位到第⼀个元素,然后再根据这个元素的上下左右⽅位进⼀步定位到⽬标元素
包含的⽅法: above(在上⽅) ,below(在下⽅) ,Left of(左边), Right of(右边) Near(附近) 了解一下即可















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









