






 本文介绍了一种基于条件生成对抗网络(cGAN)的文本转图像(Text2Image)方法。该方法通过结合文本特征与随机噪声生成逼真图像,解决了传统方法存在的问题,并实现了端到端训练。
本文介绍了一种基于条件生成对抗网络(cGAN)的文本转图像(Text2Image)方法。该方法通过结合文本特征与随机噪声生成逼真图像,解决了传统方法存在的问题,并实现了端到端训练。
论文简介
总体结构 (pipeline)
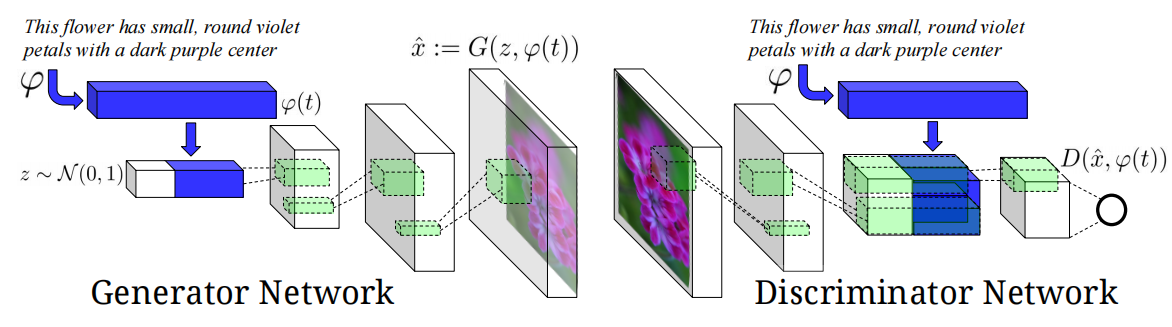
整体的模型结构如上图所示,是一个典型的GAN结构,在将噪声输入到生成网络之前,首先把100x1x1的噪声和文本向量φ(t)(φ为文本编码器,在编码后连接前先用一个全连接层把原本1024维的向量降为128维)通过一个torch.cat操作连接起来,变成一个新的向量新向量的大小为228x1x1。最终生成一个3x64x64的图片。然后把图片输入到判别器中,但判别器的feature map的大小变为4x4时,再使用cat操作把判别器的输出跟文本向量连接起来。然后再对连接后的Tensor使用一个11卷积和LeakyReLU,再用44卷积来计算最终的分数。其中,除生成器的最后一层和判别器的第一层没有用BatchNorm以外,其余卷积操作都使用了。是一个典型的DCGAN结构。
这篇论文是第一个提出使用条件式的GAN网络来解决Text2Image任务的工作,cGAN相比之前的传统方法,优势就是生成的图像更加清晰真实,可以端到端的进行训练,并且推理时间也短,在2016年这篇文章发出以后,Text2Image这个任务就真是进入了cGAN的时代了,这篇论文的很多训练方式也为后来所沿用。但是,这篇论文它能生成的图像的分辨率限制在64x64,并且在生成具有多个物体的复杂图像时也遇到了很大困难,另外,其实生成的图像虽然能粗略的符合给定文本的语义,但也有一些图像跟原始文本的语义相去甚远。除此之外,在接受一些具有相近表达方式的句子作为输入时,即是输入的噪声是不同的,模型也趋向于生成非常相似的结果。这些问题都还留待解决。
Loss

本文所使用的损失函数即是经典的GAN对抗损失,判别器D的损失是为了将真实图像和生成器G合成的图像区分开来,并使得合成的图像与文本语义相近。生成器G的损失是为了使得生成的图片在判别器那里取得gao’fen
项目简介
本项目为第四届飞桨论文复现塞《Generative Adversarial Text-to-Image Synthesis》第一名,项目基于PaddlePaddle2.1.0开发。原论文的模型在Oxford flowers 102数据集上可以合成出大小为64 x 64的真实图像,并且图像内容符合给定的对应文本,本项目复现的模型也能合成出生动的跟给定语句语义一致的文本。关于测评指标的问题,原论文中没有给出具体的质量评测指标,只进行了定性测试。因此,在这个复现项目里我们也只进行了定性测试,将复现模型生成的图片跟原始论文提供的预训练模型的生成结果进行了对比。
项目结果
本项目验收标准为Oxford-102数据集上人眼评估生成的图像,因此无具体定量指标,只展示合成的样例
| Dataset | Paddle_T2I | Text_to_Image_Synthesis |
|---|---|---|
| [Oxford-102] |  |  |
项目实现思路
我们在阅读完成论文之后,首先得弄清楚模型的结构具体是怎么样的,然后根据论文中对结构的描述完整地将模型搭建出来
import paddle
import paddle.nn as nn
# define the discriminator
class Discriminator(nn.Layer):
def __init__(self, projected_embed_dim, ndf):
super(Discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.embed_dim = 1024
self.projected_embed_dim = projected_embed_dim
self.ndf = ndf
self.conv_w_attr = paddle.framework.ParamAttr(initializer=nn.initializer.Normal(mean=0.0, std=0.02))
self.batch_w_attr = paddle.framework.ParamAttr(initializer=nn.initializer.Normal(mean=1.0, std=0.02))
self.batch_b_attr = paddle.framework.ParamAttr(initializer=nn.initializer.Normal(mean=1.0, std=0.02))
self.netD = nn.Sequential(
# 3 x 64 x 64
nn.Conv2D(self.num_channels, self.ndf, 4, 2, 1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.LeakyReLU(0.2),
# 64 x 32 x 32
nn.Conv2D(self.ndf, self.ndf * 2, 4, 2, 1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.BatchNorm2D(self.ndf * 2, weight_attr=self.batch_w_attr),
nn.LeakyReLU(0.2),
# 128 x 16 x 16
nn.Conv2D(self.ndf * 2, self.ndf * 4, 4, 2, 1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.BatchNorm2D(self.ndf * 4, weight_attr=self.batch_w_attr),
nn.LeakyReLU(0.2),
# 256 x 8 x 8
nn.Conv2D(self.ndf * 4, self.ndf * 8, 4, 2, 1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.BatchNorm2D(self.ndf * 8, weight_attr=self.batch_w_attr),
nn.LeakyReLU(0.2)
# 512 x 4 x 4
)
# reduce the dimension of sentence embeddings
self.pro_module = nn.Sequential(
nn.Linear(self.embed_dim, self.projected_embed_dim),
nn.BatchNorm1D(self.projected_embed_dim, weight_attr=self.batch_w_attr),
nn.LeakyReLU(0.2)
)
# get the final judge
self.Get_Logits = nn.Sequential(
# 512 x 4 x 4
nn.Conv2D(self.ndf * 8 + self.projected_embed_dim, 1, 4, 1, 0
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.Sigmoid()
)
def forward(self, img, text_emb):
# return the final judge and image features
pro_emb = self.pro_module(text_emb)
cat_emb = paddle.expand(pro_emb, shape=(4, 4, pro_emb.shape[0], pro_emb.shape[1]))
cat_emb = paddle.transpose(cat_emb, perm=[2, 3, 0, 1])
hidden = self.netD(img)
hidden_cat = paddle.concat([hidden, cat_emb], 1)
out = self.Get_Logits(hidden_cat)
out = paddle.reshape(out, shape=[-1, 1])
return out.squeeze(1), hidden
import paddle
import paddle.nn as nn
# define the generator
class Generator(nn.Layer):
def __init__(self, noise_dim, projected_embed_dim, ngf):
super(Generator, self).__init__()
self.num_channels = 3
self.image_size = 64
self.noise_dim = noise_dim
self.embed_dim = 1024
self.projected_embed_dim = projected_embed_dim
self.latent_dim = self.noise_dim + self.projected_embed_dim
self.ngf = ngf
self.conv_w_attr = paddle.framework.ParamAttr(initializer=nn.initializer.Normal(mean=0.0, std=0.02))
self.batch_w_attr = paddle.framework.ParamAttr(initializer=nn.initializer.Normal(mean=1.0, std=0.02))
# reduce the dimension of sentence embeddings
self.pro_module = nn.Sequential(
nn.Linear(self.embed_dim, self.projected_embed_dim),
nn.BatchNorm1D(num_features=self.projected_embed_dim, weight_attr=self.batch_w_attr),
nn.LeakyReLU(negative_slope=0.2)
)
# the generator networks
self.netG = nn.Sequential(
nn.Conv2DTranspose(in_channels=self.latent_dim, out_channels=self.ngf * 8, kernel_size=4, stride=1,
padding=0
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.BatchNorm2D(self.ngf * 8, weight_attr=self.batch_w_attr),
nn.ReLU(),
# 512 x 4 x 4
nn.Conv2DTranspose(in_channels=self.ngf * 8, out_channels=self.ngf * 4, kernel_size=4, stride=2, padding=1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.BatchNorm2D(self.ngf * 4, weight_attr=self.batch_w_attr),
nn.ReLU(),
# 256 x 8 x 8
nn.Conv2DTranspose(in_channels=self.ngf * 4, out_channels=self.ngf * 2, kernel_size=4, stride=2, padding=1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.BatchNorm2D(self.ngf * 2, weight_attr=self.batch_w_attr),
nn.ReLU(),
# 128 x 16 x 16
nn.Conv2DTranspose(in_channels=self.ngf * 2, out_channels=self.ngf, kernel_size=4, stride=2, padding=1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.BatchNorm2D(self.ngf, weight_attr=self.batch_w_attr),
nn.ReLU(),
# 64 x 32 x 32
nn.Conv2DTranspose(in_channels=self.ngf, out_channels=self.num_channels, kernel_size=4, stride=2, padding=1
, weight_attr=self.conv_w_attr, bias_attr=False),
nn.Tanh()
# 3 x 64 x 64
)
def forward(self, text_emb, z):
# inputs: sentence embeddings and latent vector
# output: fake samples synthesized by the generator
pro_emb = self.pro_module(text_emb).unsqueeze(2).unsqueeze(3)
latent_code = paddle.concat([pro_emb, z], 1)
out = self.netG(latent_code)
return out
在构建完成整体得模型以后,我们就应该完成训练函数和预测函数,确定模型能够顺利地完成任务
import paddle
import paddle.nn as nn
from paddle.io import DataLoader
from work.T2IDataset import Text2ImageDataset
import numpy as np
import os
from PIL import Image
from visualdl import LogWriter
# define the trainer
class Trainer(object):
def __init__(self, batch_size, num_workers, epochs, split, noise_dim, projected_embed_dim, ngf, ndf):
# initialize
self.G = Generator(noise_dim, projected_embed_dim, ngf)
self.D = Discriminator(projected_embed_dim, ndf)
self.noise_dim = noise_dim
self.split = split
self.batch_size = batch_size
self.num_workers = num_workers
self.num_epochs = epochs
self.dataset = Text2ImageDataset('/home/aistudio/data/data110209/flowers.hdf5', split=self.split)
self.dataloader = DataLoader(dataset=self.dataset, batch_size=self.batch_size,
shuffle=True, num_workers=self.num_workers)
self.scheduler_G = paddle.optimizer.lr.LambdaDecay(learning_rate=0.0001, lr_lambda=lambda x: 0.95**x)
self.scheduler_D = paddle.optimizer.lr.LambdaDecay(learning_rate=0.0004, lr_lambda=lambda x: 0.95**x)
self.optD = paddle.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999,
parameters=self.D.parameters())
self.optG = paddle.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999,
parameters=self.G.parameters())
def train(self):
criterion = nn.BCELoss()
self.D.train()
self.G.train()
# write the training process into the log file
with LogWriter(logdir='Log') as writer:
for epoch in range(self.num_epochs):
iter = 0
for sample in self.dataloader():
iter += 1
# get the training data
right_images = sample['right_images'].cuda()
right_embed = sample['right_embed'].cuda()
wrong_images = sample['wrong_images'].cuda()
inter_embed = sample['inter_embed'].cuda()
real_labels = paddle.ones([right_images.shape[0]]).cuda()
fake_labels = paddle.zeros([right_images.shape[0]]).cuda()
smooth_real_labels = real_labels - 0.1
smooth_real_labels = smooth_real_labels.cuda()
# train net_D
self.optD.clear_grad()
# get the judgement for real image and right embed
outputs, activation_real = self.D(right_images, right_embed)
real_loss = criterion(outputs, smooth_real_labels)
real_score = outputs
# get the judgement for real image and wrong embed, this is the CLS trick in the original paper
outputs, _ = self.D(wrong_images, right_embed)
wrong_loss = criterion(outputs, fake_labels)
wrong_score = outputs
# generate the fake samples
noise = paddle.randn(shape=[right_images.shape[0], self.noise_dim]).cuda()
noise = paddle.reshape(noise, shape=[noise.shape[0], 100, 1, 1])
fake_images = self.G(right_embed, noise)
# get the judgement for fake image and right embed
outputs, _ = self.D(fake_images.detach(), right_embed)
fake_loss = criterion(outputs, fake_labels)
fake_score = outputs
# get the loss of discriminator
d_loss = fake_loss + real_loss + wrong_loss
d_loss.backward()
self.optD.step()
# train netG
self.optG.clear_grad()
# get the judgement for fake image and right embed
outputs, activation_fake = self.D(fake_images, right_embed)
_, activation_real = self.D(right_images, right_embed)
g_loss = criterion(outputs, real_labels)
# generate the interpolated images, this is the INT trick in the original paper
noise = paddle.randn(shape=[right_images.shape[0], self.noise_dim]).cuda()
noise = paddle.reshape(noise, shape=[noise.shape[0], 100, 1, 1])
inter_images = self.G(inter_embed, noise)
outputs, _ = self.D(inter_images, inter_embed)
# get the loss of generator
g_loss_inter = criterion(outputs, real_labels)
g_loss = g_loss + g_loss_inter
g_loss.backward()
self.optG.step()
# print the training logs
print('[%d/%d][%d/%d] Loss_D: %.3f Loss_G: %.3f D(X): %.3f D(G(x)): %.3f'
% (epoch, self.num_epochs, iter, len(self.dataloader), d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))
writer.add_scalar(tag='loss_D_train', value=d_loss.item(), step=epoch)
writer.add_scalar(tag='loss_G_train', value=g_loss.item(), step=epoch)
writer.add_scalar(tag='D(x)_train', value=real_score.mean().item(), step=epoch)
writer.add_scalar(tag='D(G(x)_train', value=fake_score.mean().item(), step=epoch)
# save the fake images generated by generators
fake_images = (fake_images + 1) / 2.0
out_img = fake_images.detach().numpy()[0].transpose((1, 2, 0)) * 255
out_img = Image.fromarray(out_img.astype(np.uint8))
out_img.save(rf"image/{epoch}.png")
# save the parameters of models
if (epoch+1) % 10 == 0:
paddle.save(self.G.state_dict(), '/home/aistudio/model/netG_%03d.pdparams' % (epoch+1))
paddle.save(self.D.state_dict(), '/home/aistudio/model/netD_%03d.pdparams' % (epoch+1))
def sample(self, model_path):
# load the parameters into the models
self.G.load_dict(paddle.load(model_path))
self.G.train()
save_dir = '/home/aistudio/sample/'
for s in self.dataloader():
# get the data in test set
right_images = s['right_images']
right_embed = s['right_embed']
txt = s['txt']
# generate fake samples
noise = paddle.randn(shape=[right_images.shape[0], self.noise_dim]).cuda()
noise = paddle.reshape(noise, shape=[noise.shape[0], 100, 1, 1])
fake_images = self.G(right_embed, noise)
fake_images = (fake_images + 1) / 2.0
# save the fake images
for image, t in zip(fake_images, txt):
im = image.detach().numpy().transpose((1, 2, 0)) * 255
im = Image.fromarray(im.astype(np.uint8))
im.save(save_dir + '{0}.png'.format(t.replace("/", "")[:100]))
print(t)
然后就是要固定模型的参数量以及各项超参数,这对于模型来说十分重要。因为论文提供的数据集是一个小而简单的数据集,因此模型的规模不能太大,以免发生欠拟合的现象。另外,由于模型的参数量比较小,就可以适当的将batchsize设置得大一点,以加快训练
from work.trainer import Trainer
import argparse
# options
parser = argparse.ArgumentParser()
parser.add_argument("--batch_size", default=64, type=int)
parser.add_argument("--num_workers", default=4, type=int)
parser.add_argument("--epochs", default=200, type=int)
parser.add_argument("--split", default=0, type=int)
parser.add_argument("--validation", default=False, action='store_true')
parser.add_argument("--pretrain_model", default=None)
parser.add_argument("--noise_dim", default=100, type=int)
parser.add_argument("--projected_embed_dim", default=128, type=int)
parser.add_argument("--ngf", default=64, type=int)
False, action='store_true')
parser.add_argument("--pretrain_model", default=None)
parser.add_argument("--noise_dim", default=100, type=int)
parser.add_argument("--projected_embed_dim", default=128, type=int)
parser.add_argument("--ngf", default=64, type=int)
parser.add_argument("--ndf", default=64, type=int)
_StoreAction(option_strings=['--ndf'], dest='ndf', nargs=None, const=None, default=64, type=<class 'int'>, choices=None, help=None, metavar=None)
项目使用
训练
python main.py --split=0
测试
将模型的参数保存在model\中,然后改变pretrain_model的值,再运行以下命令,输出图片保存在image\目录中
python main.py --validation --split=2 --pretrain_model=model/netG.pdparams
使用预训练模型预测
将需要测试的文件放在参数pretrain_model确定的目录下,运行下面指令,输出图片保存在image\目录中
python main.py --validation --split=2 --pretrain_model=model/netG.pdparams

















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









