






★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
0 项目背景
信息抽取任务旨在从非结构化的自然语言文本中提取结构化信息。在本系列项目中,将讨论如何又好又快地实现一个简历信息提取任务。
作为该系列文章的第二篇,我们将通过paddlenlp.Taskflow提供的文本及文档通用信息抽取能力,实现开箱即用的简历信息抽取。
0.1 参考资料
作为填坑之作,在这里附上简历信息抽取这个项目的探索进展,感兴趣的读者可以点击查阅:
- 简历信息提取(一):PDFPlumber和PP-Structure
- 简历信息提取(二):HR救星!用UIE Taskflow快速完成简历信息批量抽取
- 简历信息提取(三):文本抽取的UIE格式转换与微调训练
- 简历信息提取(四):文本抽取微调模型的部署应用
- 简历信息提取(五):用VI-LayoutXLM提升关键信息抽取效果
- 简历信息提取(六):基于VI-LayoutXLM识别结果的微调训练和部署
# 解压缩数据集
!unzip data/data40148/train_20200121.zip
1 一键实体抽取
实体抽取,又称命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体。在简历信息抽取任务中,用户可以自己定义实体类别,如姓名、出生日期、电话等。
我们可以使用PaddleNLP Taskflow API提供的开箱即用、适配多场景的开放域通用信息抽取工具Taskflow("information_extraction"),一键完成简历中常用实体信息的抽取。
1.1 安装依赖库
# 安装依赖库
!pip install python-docx
!pip install pypinyin
!pip install LAC
!pip install --upgrade paddlenlp
!pip install pymupdf
!pip install --upgrade paddleocr
# 首次更新完以后,重启后方能生效
1.2 Taskflow API文本抽取
需要注意的是,在运行下面的cell前,需要先重启下内核,否则会出现如下报错:
AssertionError: The task name:information_extraction is not in Taskflow list, please check your task name.
from pprint import pprint
from paddlenlp import Taskflow
# 定义实体关系抽取的schema
schema = ['姓名', '出生日期', '电话']
ie = Taskflow('information_extraction', schema=schema)
[2023-01-26 22:33:16,762] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'.
我们可以随意输入一段类似人物简历内容的信息,查看下实体抽取效果。
pprint(ie("姓名:小李,性别:男,出生日期:2000年04月,民族:汉族,联系电话:13602173036"))
[{'出生日期': [{'end': 24,
'probability': 0.9984900421979503,
'start': 16,
'text': '2000年04月'}],
'姓名': [{'end': 5,
'probability': 0.980940721466304,
'start': 3,
'text': '小李'}],
'电话': [{'end': 47,
'probability': 0.9876029286607029,
'start': 36,
'text': '13602173036'}]}]
从返回的结果看,PaddleNLP使用的预训练模型,在简历信息抽取任务上表现是非常优异的,抽取的实体信息相当准确。
PaddleNLP使用的开放域信息抽取是信息抽取的一种全新范式,主要思想是减少人工参与,利用单一模型支持多种类型的开放抽取任务,用户可以使用自然语言自定义抽取目标,在实体、关系类别等未定义的情况下抽取输入文本中的信息片段。
而且从前面安装的依赖看,Taskflow API集成了分词的能力。我们在前置项目中,也可以看到现实中企业收到的简历格式多样,解析时不一定能完全保留标点、关键词,这时候就需要挑战下,如果没有标点的情况下,Taskflow API的预测效果了:
pprint(ie("姓名小李性别男出生日期2000年04月民族汉族联系电话13602173036"))
[{'出生日期': [{'end': 19,
'probability': 0.9984312446942312,
'start': 11,
'text': '2000年04月'}],
'姓名': [{'end': 4,
'probability': 0.9893165552343817,
'start': 2,
'text': '小李'}],
'电话': [{'end': 38,
'probability': 0.9649253466571253,
'start': 27,
'text': '13602173036'}]}]
我们可以看出,去掉标点对Taskflow API的预测结果还是有一点点影响,模型对抽取结果的置信度有略微降低,但是从最终效果看,还是没问题的。也就是说,如果数据组织得好,使用PaddleNLP提供的Taskflow API有望帮我们快速完成基本简历信息抽取任务。
接下来我们就尝试直接从word格式的简历当中提取文本信息,查看实体抽取的效果。在前置项目中,我们发现python-docx的文档信息提取方式相较于BeautifulSoup可能会稍微稳定一些,因此,本项目采用python-docx执行word文档解析任务。
from docx import Document
from docx.shared import Inches
def get_paragraphs_text(path):
"""
获取所有段落的文本
:param path: word路径
:return: list类型,如:
['Test', 'hello world', ...]
"""
document = Document(path)
# 有的简历是表格式样的,因此,不仅需要提取正文,还要提取表格
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
# 表格提取中,需要添加一个去重机制
fore_str = ""
cell_text = ""
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
if fore_str != cell.text:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
cell_text += cell.text + '\n'
# 提取正文文本
paragraphs_text = ""
for paragraph in document.paragraphs:
# 拼接一个list,包括段落的结构和内容
paragraphs_text += paragraph.text + "\n"
return cell_text, paragraphs_text

# 提取文档信息,这是一个表格式简历
cell_text, paragraphs_text = get_paragraphs_text('resume_train_20200121/docx/0043e770a330.docx')
由于很多简历的模板,会出现表格和正文混搭的情况,但是信息抽取任务中,受全文排版影响较小,只要上下文连接紧密,识别效果还是可以保证的。因此在使用时,我们可以直接将两种方式提取的文本信息拼接起来。
pprint(ie(cell_text, paragraphs_text))
[{'出生日期': [{'end': 25,
'probability': 0.9901952708172601,
'start': 18,
'text': '2000.04'}],
'姓名': [{'end': 6,
'probability': 0.9982152736966015,
'start': 3,
'text': '郝淑宁'}],
'电话': [{'end': 49,
'probability': 0.9545179006184981,
'start': 38,
'text': '13602173036'}]}]
1.3 Taskflow API文档抽取
2023.1.12发布的PaddleNLP v2.5在产业信息抽取应用上的一个重大更新,就是发布文档信息抽取UIE-X,也就是说,Taskflow API支持的输入格式,不再只是文本内容,也可以是图片了。这对我们做简历信息抽取可是个好消息——如果我们收到的简历是扫描件、图片或者模板花里胡哨的文档,这下可以直接转为图片送给Taskflow API看看效果了,PaddleNLP已经贴心的帮我们把PaddleOCR集成好了!
import datetime
import os
import fitz # fitz就是pip install PyMuPDF
import cv2
import shutil
import numpy as np
import pandas as pd
from tqdm import tqdm
此处需要注意的是,前置项目使用的PyMuPDF版本是pymupdf==1.18.14,而在本项目中,用的依赖包已经升级到了最新版本,里面不少API的写法已经发生了变化,在本项目中,统一用了最新API。
def pyMuPDF_fitz(pdfPath, imagePath):
startTime_pdf2img = datetime.datetime.now() # 开始时间
print("imagePath=" + imagePath)
pdfDoc = fitz.open(pdfPath)
for pg in range(pdfDoc.page_count):
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为4,这将为我们生成分辨率提高4的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 4 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 4
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
pix = page.get_pixmap(matrix=mat, alpha=False)
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
pix.save(imagePath + '/' + 'images_%s.jpeg' % pg) # 将图片写入指定的文件夹内
endTime_pdf2img = datetime.datetime.now() # 结束时间
print('pdf转图片时间=', (endTime_pdf2img - startTime_pdf2img).seconds)
# pdf转图片
pyMuPDF_fitz('./resume_train_20200121/pdf/02b5bd8a71b6.pdf', 'imgs')
imagePath=imgs
pdf转图片时间= 0

pprint(ie({"doc": "imgs/images_0.jpeg"}))
[{'出生日期': [{'bbox': [[705, 1028, 1132, 1067]],
'end': 66,
'probability': 0.5297493359020145,
'start': 56,
'text': '1943.012 年'}],
'姓名': [{'bbox': [[269, 368, 524, 488]],
'end': 16,
'probability': 0.757315754230099,
'start': 14,
'text': '昌伊'}]}]
注:如果这里出现了paddleocr依赖包没有安装上的提示,请点击右侧【包管理】,找到paddlecor安装后再运行上面的cell。
可以看出,简历模板的多样化确实对实体信息的抽取造成了一定的困扰,但是PaddleNLP的Taskflow API在识图抽取信息方面效果还是挺给力的。
2 批量处理
实际业务中,公司的HR往往要面对堆积如山的简历,业务上显然没办法接受一个个文件进行实体抽取的,想要让AI成为HR筛选简历的得力小帮手,我们还需要对输出结果进行组织。在项目中,结合数据集的实际情况,我们设计的简历批量信息抽取思路如下:
- 首先用户需要将简历文件按格式(word,pdf)分别放置在对应目录下
- word格式的简历通过Taskflow API文本信息抽取得到实体信息
- pdf或者图片格式的简历统一整理为jpeg格式,然后通过Taskflow API文档信息抽取得到实体信息
- 将文件名、实体信息逐行存入excel文件中,便于HR做后续的人工补充和筛选工作

# 选定一些HR关注的基本信息
schema = ['姓名', '出生日期', '电话', '性别', '最高学历', '籍贯', '政治面貌', '毕业院校', '学位', '毕业时间', '工作时间']
ie = Taskflow('information_extraction', schema=schema)
[2023-01-26 23:30:03,069] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'.
2.1 word格式简历批量信息抽取
准备一个统一的简历信息抽取结果处理脚本,将Taskflow API提取的信息进一步按照schema进行归类。
def get_info(cell_text, paragraphs_text):
# 将整理后的抽取结果返回为字典
schema_dict = {}
# 抽取简历信息
a = ie(cell_text, paragraphs_text)
for i in schema:
if i in a[0]:
schema_dict[i] = a[0][i][0]['text']
# 查看抽取信息
# print(a[0][i][0]['text'])
else:
schema_dict[i] = ''
return schema_dict
def get_word(path):
filenames = os.listdir(path)
result = []
for filename in tqdm(filenames):
cell_text, paragraphs_text = get_paragraphs_text(os.path.join(path,filename))
res = get_info(cell_text, paragraphs_text)
res['filename'] = filename
result.append(res)
return result
result = get_word('resume_train_20200121/docx')
100%|██████████| 2000/2000 [16:43<00:00, 1.99it/s]
仅仅耗时16分钟,我们就完成了2000份简历基本信息的提取!我们可以将提取结果用一个表格来展示:
result_pd = pd.DataFrame(result)
result_pd.tail()
| 姓名 | 出生日期 | 电话 | 性别 | 最高学历 | 籍贯 | 政治面貌 | 毕业院校 | 学位 | 毕业时间 | 工作时间 | filename | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1995 | 韩莎 | 2003.08 | 女 | 硕士学位 | 黑龙江省佳木斯市 | 清华大学 | 2003.08-2007.08 | 2006年07月 | 0bfdfb5cede0.docx | |||
| 1996 | 贺明 | 15500440494 | 男 | 大学本科 | 宁夏省银川市 | 北京师范大学 | 本科 | 2012.07-2016.07 | 2012.10-2016.10 | 9179e49b415d.docx | ||
| 1997 | 岑琴 | 男 | 大专 | 北京工商大学 | 1994.03-2011.03 | 9f0664839297.docx | ||||||
| 1998 | 柳咏 | 1960年03月 | 13506566022 | 重庆市 | 中国共产党党员 | 1960年03月 | 72e88606f22c.docx | |||||
| 1999 | 吕可 | 2000年10月 | 男 | 大专 | 北京吉利学院 | 硕士学位 | 2000年10月 | 84c488899f68.docx |
接下来,可以保存这个文件到excel中了:
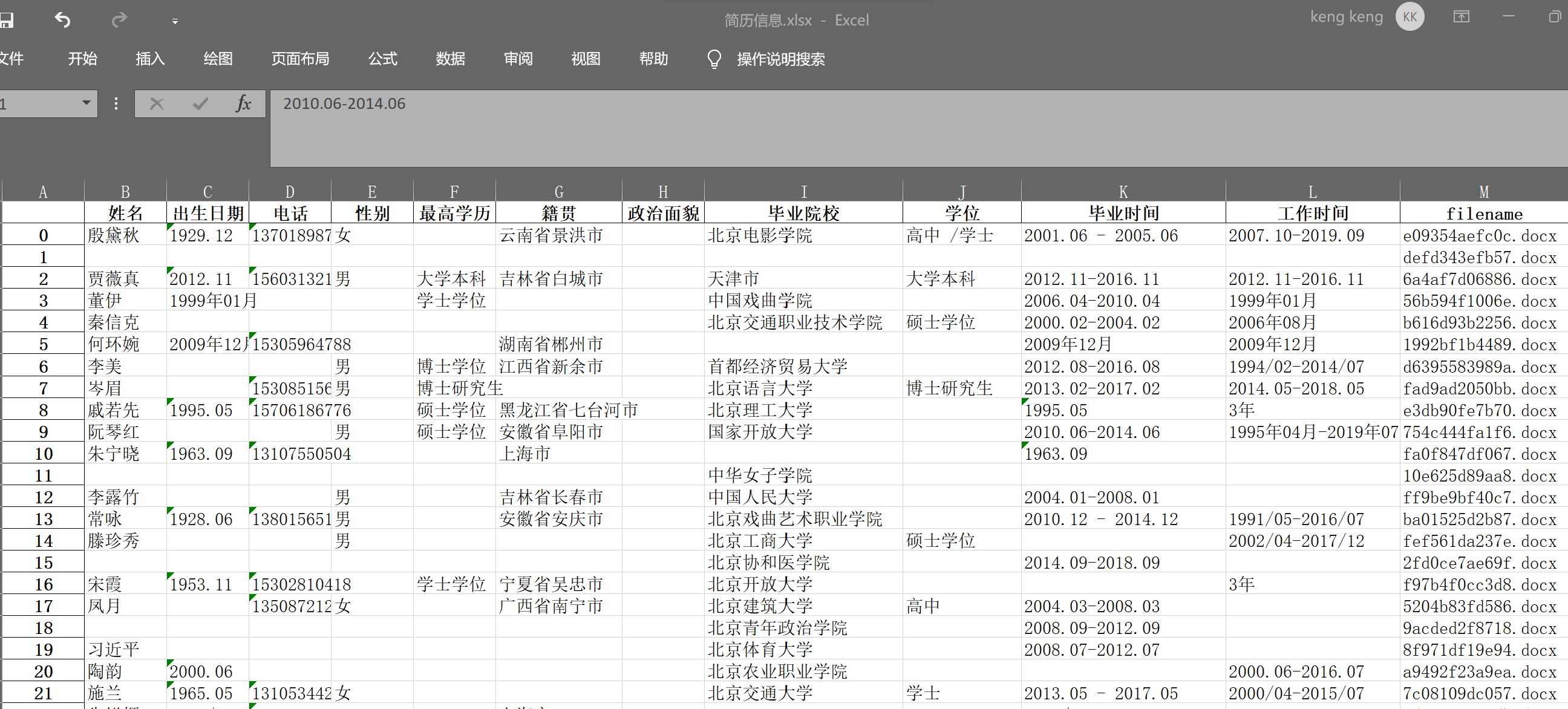
result_pd.to_excel('简历信息.xlsx')
大功告成!接下来的工作,就可以顺利移交给HR啦。
2.2 PDF/图片格式简历批量信息抽取
下面我们再看看图片格式的信息抽取,整体的思路虽然大同小异,但是这里有个地方稍微复杂一些,就是要多一步判断下,目录里的文件是pdf还是jpeg格式。
另一方面,涉及到多页的pdf,每页信息都要试着提取下。
def get_pic_info(path):
# 将整理后的抽取结果返回为字典
schema_dict = {}
if os.path.splitext(path)[-1]=='.pdf':
pdfDoc = fitz.open(path)
for pg in range(pdfDoc.page_count):
page = pdfDoc[pg]
rotate = int(0)
zoom_x = 4 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 4
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
pix = page.get_pixmap(matrix=mat, alpha=False)
# 保存过渡图片
temp_path = pix.save('temp.jpeg')
# 抽取过渡图片中的简历信息
a = ie({"doc":'temp.jpeg'})
if pg==0:
for i in schema:
if i in a[0]:
schema_dict[i] = a[0][i][0]['text']
else:
schema_dict[i] = ''
else:
for i in schema:
if i in a[0]:
schema_dict[i] = a[0][i][0]['text']
elif os.path.splitext(path)[-1]=='.jpeg':
# 抽取图片中的简历信息
a = ie({"doc":path})
for i in schema:
if i in a[0]:
schema_dict[i] = a[0][i][0]['text']
else:
schema_dict[i] = ''
else:
print('图片信息抽取只支持pdf和jpeg格式,请调整后重试。')
return schema_dict
def get_pics(path):
filenames = os.listdir(path)
result = []
for filename in tqdm(filenames):
res = get_pic_info(os.path.join(path,filename))
res['文件名'] = filename
result.append(res)
return result
result = get_pics('resume_train_20200121/pdf')
100%|██████████| 108/108 [04:32<00:00, 2.52s/it]
100%|██████████| 108/108 [04:32<00:00, 2.52s/it]
因为图片处理显然需要更长的时间,因此这里我们仅使用一百余份简历,展示批量处理的效果。
result_pd = pd.DataFrame(result)
result_pd.head()
| 姓名 | 出生日期 | 电话 | 性别 | 最高学历 | 籍贯 | 政治面貌 | 毕业院校 | 学位 | 毕业时间 | 工作时间 | 文件名 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1984.11 | 学士学位 | 重庆市 | 北京外国语大学 | 学士学位 | 2005.12 -- 2009.12 | 2006.08-2017.08 | f8347799dc77.pdf | ||||
| 1 | 江姣娴 | 1964.06 | 沟通 | 男 | 中国民主促进会会员 | 北京电影学院 | 高中计算机软件 | 1964.06 | 1992/02-2018/04 | f96bbe080756.pdf | ||
| 2 | 谢纯亚 | 2002年05月 | 15906850079 | 男 | 博士研究生 | 山西省忻州市 | 中国农工民主党党员 | 北京电影学院 | 博士研究生 | 2009.03-2013.03 | 2008/03-2011/01 | fc52a5feaf4e.pdf |
| 3 | 魏进 | 1990年02月 | 15903711789 | 男 | 江苏省连云港市 | 首都师范大学 | 2010.07-2014.07 | 1995/07-2016/12 | fc9dbea3e727.pdf | |||
| 4 | 汤珍玲 | 1942.07 | 南开大学 | 1942.072 年 | fff6da0a5e37.pdf |
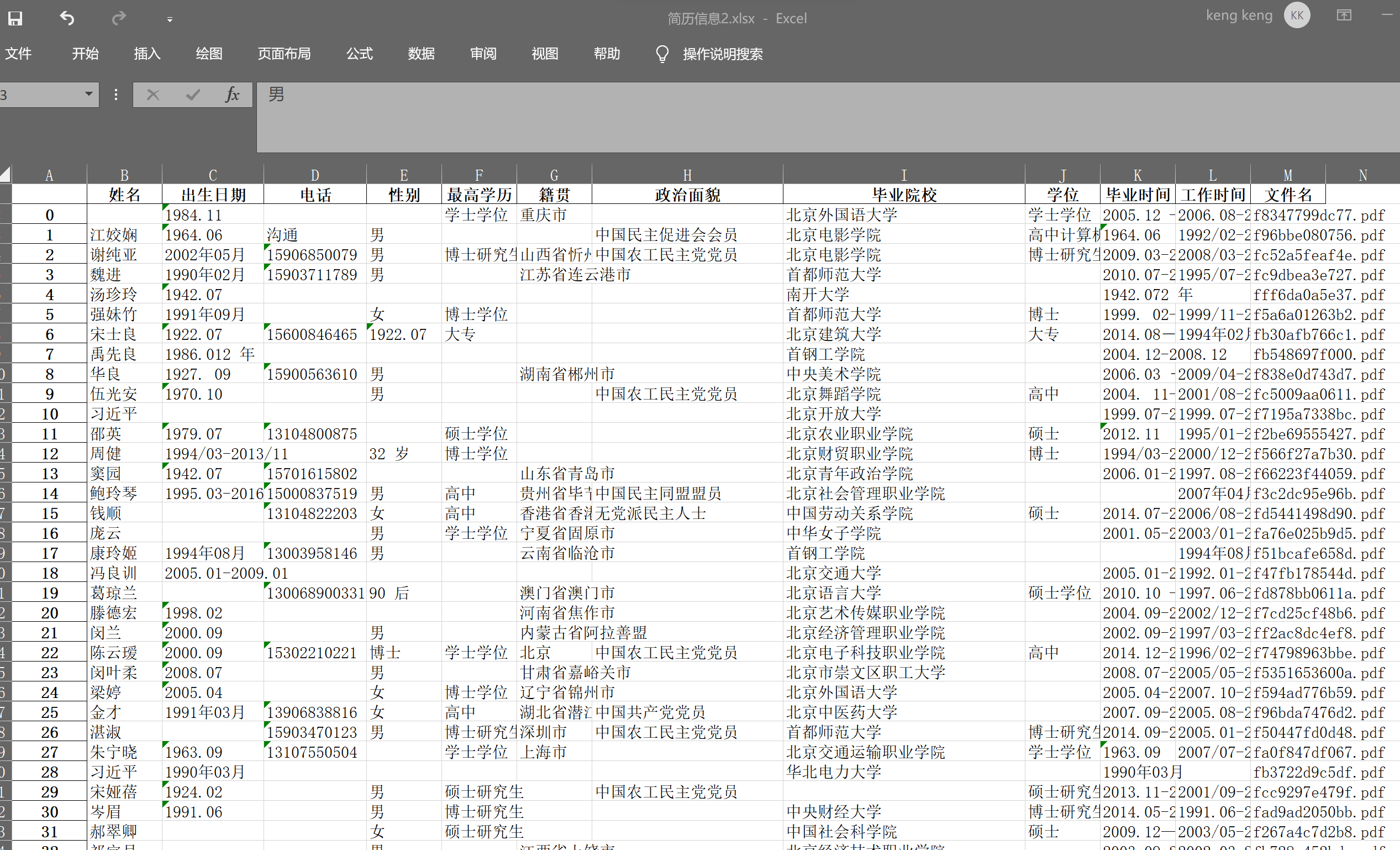
我们可以看到,即使是通过图片转换后再进行实体信息抽取,得到的简历信息还是挺完整的。看来,有PaddleNLP这个好帮手,到招聘季,HR们可以省下好多力气了!
# 保存提取的简历信息
result_pd.to_excel('简历信息2.xlsx')
3 小结
在本项目中,我们使用PaddleNLP开放域信息抽取工具UIE Taskflow,开发了一个可以对Word、PDF、图片格式的简历文件进行批量信息提取的工具,生成的结果可直接供企业HR进行直接补充、筛选和加工。
当然,我们也可以发现,直接用现有的预训练模型,抽取结果还有不少缺失。在后续的项目中,我们尝试将基于项目使用的数据集,用PaddleNLP迁移学习,训练一个精度更高的简历信息抽取模型,并将其在线部署。

















 3122
3122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









