







★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
第十八届全国大学生智能汽车竞赛-百度完全模型组-线上资格赛基线
1、比赛背景介绍
全国大学生智能汽车竞赛是以智能汽车为研究对象的创意性科技竞赛,是面向全国大学生的一种具有探索性工程的实践活动,是教育部倡导的大学生A类科技竞赛之一。竞赛以立足培养,重在参与,鼓励探索,追求卓越为指导思想,培养大学生的创意性科技竞赛能力。
本次比赛数据由赛曙科技(SASU)提供,模型和基线相关技术支持由深度学习技术平台部提供,一站式AI开发平台AI Studio由百度AI技术生态部提供。要求在统一的计算资源下,能够对农业相关物体的具体位置和类别进行快速精准的识别。期待参赛者们能够以此为契机,共同推进智慧农业的发展。
2、基线程序说明
-
采用官方PaddlePaddle-GPU v2.3的环境,使用PaddleDetection-develop的框架进行训练、推理、结果生成
-
基线程序旨在全流程完成检测、后处理部分,为参赛选手提供流程上的帮助,按照此流程进行训练和处理,F1-score理论上可以达到0.95以上
-
提供将voc格式的数据集转成coco格式的示例,两者只是dataloader的方式不同,训练所得模型精度并无差异
3、比赛环境配置
3.1 安装PaddleDetection
(此步骤已经完成,在此基线环境内,不需要再次进行)
# %cd /home/aistudio/work/
# # 从github上下载PaddleDetection
# # !git clone https://github.com/PaddlePaddle/PaddleDetection.git -b develop
# # 使用提前准备好的PaddleDetection代码包
# !wget https://bj.bcebos.com/v1/paddledet/code/PaddleDetection-release-2.5.zip
# !unzip -q PaddleDetection-release-2.5.zip
# !mv PaddleDetection-release-2.5 PaddleDetection
3.2 安装依赖
(每次启动环境都要运行!)
%cd ~
%cd work/PaddleDetection
# 安装相关依赖
!pip install -r requirements.txt
# 编译安装paddledet
!python setup.py install
4、比赛数据准备
4.1 解压数据
(注意数据集中路径名、文件名尽量不要使用中文,避免中文编码问题导致出错)
# 将官方数据集解压缩至/home/aistudio/data
!unzip -oq /home/aistudio/data/data191561/DatasetVocSASU_ForIcarM2023.zip -d /home/aistudio/data/
4.2 分析数据
官方数据集一共包含4770张带有标签的图片,均为目标检测voc格式。目录如下:
├── Annotations
│ ├── 4770个xml文件
├── Images
│ ├── 4770张jpg图片
├── label_list.txt
├── random_split.py
├── train.txt
├── trainval.txt
└── val.txt
数据集为智能车视角拍摄的照片,照片格式为jpg,大小均为320 x 240,每张照片对应有一个同名标注文件,标注文件格式为 xml
| 序号 | 数据名称 | 采样说明 |
|---|---|---|
| 1 | 拖拉机-tractor | >远景、近景、蓝色底布背景; |
| 2 | 谷仓-granary | > 远景、近景、蓝色底布背景; |
| 3 | 玉米-corn | > 远景、近景、蓝色底布背景; |
| 4 | 猪-pig | > 远景、近景、蓝色底布背景; |
| 5 | 拱桥-bridge | > 远景、近景、蓝色底布背景; |
| 6 | 锥桶-cone | > 远景、近景、蓝色底布背景; |
| 7 | 减速带-bump | > 远景、近景、蓝色底布背景; |
| 8 | 斑马线-CrossWalk | > 远景、近景、蓝色底布背景; |
统计官方数据集里每个类别的数量,如果有些类别的实例数量比较少,我们可以考虑使用离线数据增强等方法缓解数据不均衡的问题。

import os
from unicodedata import name
import xml.etree.ElementTree as ET
import glob
def count_num(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(f'{str(annotations)}*.xml')
dict = {} # 新建字典,用于存放各类标签名及其对应的数目
for file in annotations: # 遍历xml文件
# 开始解析xml文件
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
# 遍历文件的所有标签
for obj in root.iter('object'):
name = obj.find('name').text
if name in dict: dict[name] += 1 # 如果标签不是第一次出现,则+1
else: dict[name] = 1 # 如果标签是第一次出现,则将该标签名对应的value初始化为1
# 打印结果
print("各类标签的数量分别为:")
for key in dict:
print(f'{key}: {str(dict[key])}')
indir='/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/Annotations/' # xml文件所在的目录
count_num(indir) # 调用函数统计各类标签数目
4.3 转换数据
原始数据集为LabelImage标注的xml格式,这里我们对其进行预处理,得到PP-YOLOE+常用的coco格式。其中,PaddleDetection提供了x2coco.py用于将voc, widerface, labelme 或者 cityscape转换为COCO格式。在转换之前我们需要提供训练集和验证集标签的id文件
# 生成训练集和验证集标签的id文件
# 随机划分数据集(可在代码中修改train_ratio的值从而改变训练集的划分比例)
!python /home/aistudio/work/voc2coco/random_split_ids.py
# voc转coco格式,得到train.json
!python /home/aistudio/work/PaddleDetection/tools/x2coco.py \
--dataset_type=voc \
--voc_anno_dir='/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/Annotations' \
--voc_anno_list='/home/aistudio/work/voc2coco/train_ann_ids.txt' \
--voc_label_list='/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/label_list.txt' \
--output_dir='/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/' \
--voc_out_name=train.json
# voc转coco格式,得到val.json
!python /home/aistudio/work/PaddleDetection/tools/x2coco.py \
--dataset_type=voc \
--voc_anno_dir='/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/Annotations' \
--voc_anno_list='/home/aistudio/work/voc2coco/val_ann_ids.txt' \
--voc_label_list='/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/label_list.txt' \
--output_dir='/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/' \
--voc_out_name=val.json
5、模型训练
5.1 模型选择
这里我们选择使用PaddleDetection(GitHub传送门)套件中的PP-YOLOE+进行训练,PP-YOLOE是一款高精度推理速度快的检测模型,包含骨干网络CSPRepResNet,特征融合CSPPAN,轻量级ETHead,改进的动态匹配算法TAL等模块, 并且根据不同的应用场景设计了一系列模型,即s/m/l/x。PP-YOLOE+是PP-YOLOE的升级版本,升级主要包括:
-
💎强大的obj365预训练模型,升级版backbone等改动大幅提升PP-YOLOE系列模型的精度。
-
👫优化预处理,提升模型端到端推理速度,更贴近用户使用的真实场景。
-
💡完善多种环境下的推理部署能力。

5.2 训练配置
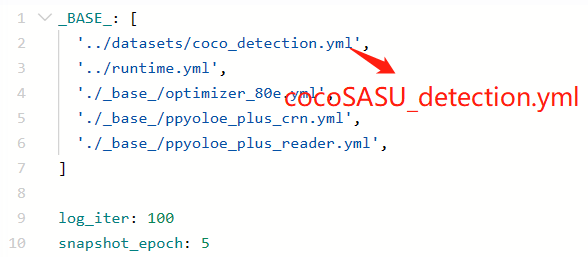
在PaddleDetection/configs/datasets/路径下新建一个cocoSASU_detection.yml文件,并配置数据集格式、类别、加载路径等信息:
metric: COCO
num_classes: 8
TrainDataset:
!COCODataSet
image_dir: Images
anno_path: train.json
dataset_dir: /home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
!COCODataSet
image_dir: Images
anno_path: val.json
dataset_dir: /home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023
TestDataset:
!ImageFolder
anno_path: val.json # also support txt (like VOC's label_list.txt)
dataset_dir: /home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023
将PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml里的数据集配置改成我们比赛的数据集配置,具体的调参过程请大家自行探索:
5.3 模型训练
当一切准备工作都做好以后,我们就可以正式开始训练啦
%cd /home/aistudio/work/PaddleDetection
# 模型训练
# 如果要恢复训练,则加上 -r output/ppyoloe_plus_crn_m_80e_coco/best_model
# 如果要边训练边评估,则加上--eval
# 训练时的日志输出将保存在--vdl_log_dir所指的路径下
!python tools/train.py \
-c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml --eval \
--use_vdl=true \
--vdl_log_dir=VisualDL
6、模型评估
用验证集评估模型的效果。如果在训练时选择了–eval,则在训练过程中就会每隔snapshot_epoch个epoch就会自动进行一次模型评估。
%cd /home/aistudio/work/PaddleDetection
# output_eval表示Evaluation directory, default is current directory.
# classwise表示是否计算每一类的AP和画P-R曲线,PR曲线图默认存放在bbox_pr_curve文件夹下
!python tools/eval.py \
-c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
--output_eval=/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/Images \
-o weights=/home/aistudio/work/PaddleDetection/output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams
7、模型预测
预测结果可视化,检验模型效果
%cd /home/aistudio/work/PaddleDetection
# infer_img表示预测改路径的单张图片
# infer_dir表示对该路径下的所有图片进行预测
# draw_threshold表示置信度大于该值的框才画出来
# 生成的图片保存在/home/aistudio/work/PaddleDetection/infer_output
!python tools/infer.py \
-c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
--infer_img=/home/aistudio/data/DatasetVocSASU_ForIcarM2023/DatasetVocSASU_ForIcarM2023/Images/1001.jpg \
--output_dir=infer_output/ \
--draw_threshold=0.5 \
-o weights=/home/aistudio/work/PaddleDetection/output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams
预测结果示例:

8、导出模型
根据eval的效果,选择best_model模型进行静态图转换
%cd /home/aistudio/work/PaddleDetection
# 将"-o weights"里的模型路径换成你自己训好的模型
!python tools/export_model.py \
-c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=/home/aistudio/work/PaddleDetection/output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams \
TestReader.fuse_normalize=true
9、结果提交
根据比赛要求的结果格式,将所需的文件拷贝到/home/aistudio/work/submission文件夹下
# 在work目录下整理提交代码
# 创建model文件夹
import os
if not os.path.exists('/home/aistudio/work/submission/model/'):
os.makedirs('/home/aistudio/work/submission/model/') #创建路径
# 将检测模型拷贝到model文件夹中
!cp -r /home/aistudio/work/PaddleDetection/output_inference/ppyoloe_plus_crn_m_80e_coco/* /home/aistudio/work/submission/model/
# 删除缓存文件
# 删除当前目录下的所有__pycache__子目录
!find . -name '__pycache__' -type d -exec rm -rf {} \;
在打包代码上传测评系统前,需要检测自己的代码能否跑通!我们可以在AI Studio简单地模拟测评系统:用predict.py脚本进行预测
# 测试predict.py是否能跑通(data.txt包含530张图片路径)
%cd /home/aistudio/work/submission
!python predict.py data.txt result.json
PS:运行完成后检查一下result.json是否为空,如果为空说明推理失败,可能是模型有问题。
# 打包代码
%cd /home/aistudio/work/submission/
!zip -r -q -o submission.zip model/ PaddleDetection/ train.py predict.py
PS:为了让压缩包更小,这里只保留了PaddleDetection的deploy文件夹
-
下载压缩包至本地,前往比赛页面的提交结果选项卡中上传压缩包
-
等待评估系统完成自动评测,就可以在下方查看提交的结果的得分详情了
-
/home/aistudio/work/submission/submission.zip是使用PP-YOLOE+的m模型训练10e所得,提交结果如下:

10、总结及优化建议
本项目使用PaddleDetection完成了数据准备、模型训练、评估和预测以及结果提交全流程,参赛选手们可尝试更多涨点技巧进一步提升模型精度。
优化建议如下:
-
对数据集进行预处理,包括数据清洗、数据增强等
-
更改模型的选择,调整模型架构等
-
优化模型超参数,如学习率、迭代次数、批量大小等
-
优化模型训练方式,包括优化器的选择、WarmUp方式的选择等
-
可以尝试使用集成学习等方法提升模型性能
-
优化predict.py
如果项目中有任何问题,欢迎在评论区留言交流,共同进步!
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









