







只是为了学习
【9年后重读深度学习奠基作之一:AlexNet【论文精读·2】】 https://www.bilibili.com/video/BV1ih411J7Kz/?share_source=copy_web&vd_source=24a9db747e66eedd721d4dffea60f749
目录
4.1. Rectified Linear Unit nonlinearity
4.3. Local response normalization
(1) 饱和型非线性(Saturating Nonlinearities)
(2) 非饱和型非线性(Non-saturating Nonlinearities)
侧抑制(Lateral Inhibition)机制的实现,以及响应归一化(Response Normalization)的作用。
先简单了解一下Alexnet
AlexNet 是一种深度卷积神经网络(CNN),在深度学习和计算机视觉领域具有里程碑意义。它由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年提出,并在当年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中取得了第一名的成绩,显著优于其他方法。AlexNet 的成功标志着深度学习在计算机视觉领域的崛起,并开启了深度学习在多个领域的广泛应用。
AlexNet 的主要特点
深度结构:AlexNet 是一个深度卷积神经网络,包含 8 层(5 个卷积层和 3 个全连接层)。这种深度结构能够学习到图像的多层次特征。
ReLU 激活函数:AlexNet 首次在卷积神经网络中大规模使用了 ReLU(Rectified Linear Unit)激活函数,相比传统的 Sigmoid 或 Tanh 激活函数,ReLU 计算效率更高,且能有效缓解梯度消失问题。
Dropout 技术:在全连接层中使用了 Dropout 技术,随机丢弃一部分神经元的输出,从而防止模型过拟合。
GPU 加速:AlexNet 的训练过程利用了 GPU 的并行计算能力,显著提高了训练速度,使得大规模深度网络的训练成为可能。
大数据集训练:AlexNet 使用了 ImageNet 数据集进行训练,该数据集包含超过 1000 个类别和数百万张标记图像,为模型提供了丰富的训练样本。
Abstract
a large, deep convolutional neural network
consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully connected layers with a final 1000-way softmax.
To make training faster, we used 非饱和神经元 + GPU
To reduce overfitting过拟合 in the fully connected layers we employed a recently developed regularization正则化 method called “dropout”
8. DISCUSSION
a large, deep CNN is capable of achieving record-breaking results (SOTA) on a highly challenging dataset(指的是ImageNet)using purely supervised learning.
did not use any unsupervised pre-training
这里强调purely supervised learning是因为之前 有监督学习 打不赢 机器学习,eg 树 SVM,但是这个论文现在证明模型够大、有标签数据够多、我 No. 1 !
但是 未来表明无监督也挺好使的,如Bert,GAN
the depth really is important :remove a single convolutional layer降 2%,,,但是不能证明深度是最重要的,也可能参数没调好
Unsupervised Pre-training(无监督预训练) 是一种机器学习方法,其核心思想是在没有标注数据的情况下,通过大规模未标注数据训练模型,使其学习到数据的内在结构和特征表示。这种方法通常作为模型训练的预训练阶段,后续可以通过少量标注数据进行微调(Fine-tuning),以适应特定任务。
7.1. Qualitative evaluations
even off-center objects,can be recognized by the net 但是也有不好的,在某些情况下(金属网罩、樱桃),照片的预期焦点确实模糊不清。
If two images produce feature activation vectors with a small Euclidean separation, we can say that the higher levels of the neural network consider them to be similar.
Notice that at the pixel level, the retrieved training images are generally not close in L2 to the query images in the first column.但是 输入图片在 CNN 的倒数第二层的数,作为每个图片的语义向量,和输入图片向量相似,即图片最后向量(学到了一种嵌入表示,DL 的一大强项)的语义表示 特别好,非常适合后面的 ML,一个简单的 softmax 就能分类的很好!
1. PROLOGUE(序言)
for deep neural networks to shine, they needed far more labeled data and hugely more computation.
2. INTRODUCTION
描述了怎么做神经网络,这里只介绍了CNN
写论文的时候,千万不要只说自己这个领域这个小方向大概怎么样,还要提到别的方向怎么样
We wrote a highly optimized GPU implementation of 2D convolution and all the other operations inherent in training CNNs, which we make available publicly.
Our network contains a number of new and unusual features which improve its performance and reduce its training time, which are detailed in Section 4.
3. THE DATASET

当时做计算机视觉都是将特征抽出来,抽SIFT也好,抽别的特征也好(imagenet数据集也提供了一个SIFT版本的特征),这篇文章说不要抽特征,直接是在原始的Pixels上做了。
在之后的工作里面基本上主要是end to end(端到端):及那个原始的图片或者文本直接进去,不做任何的特征提取,神经网络能够帮助你完成这部分工作。
4. THE ARCHITECTURE
模型过大,训练不动,切割模型,model paralle

4.1. Rectified Linear Unit nonlinearity

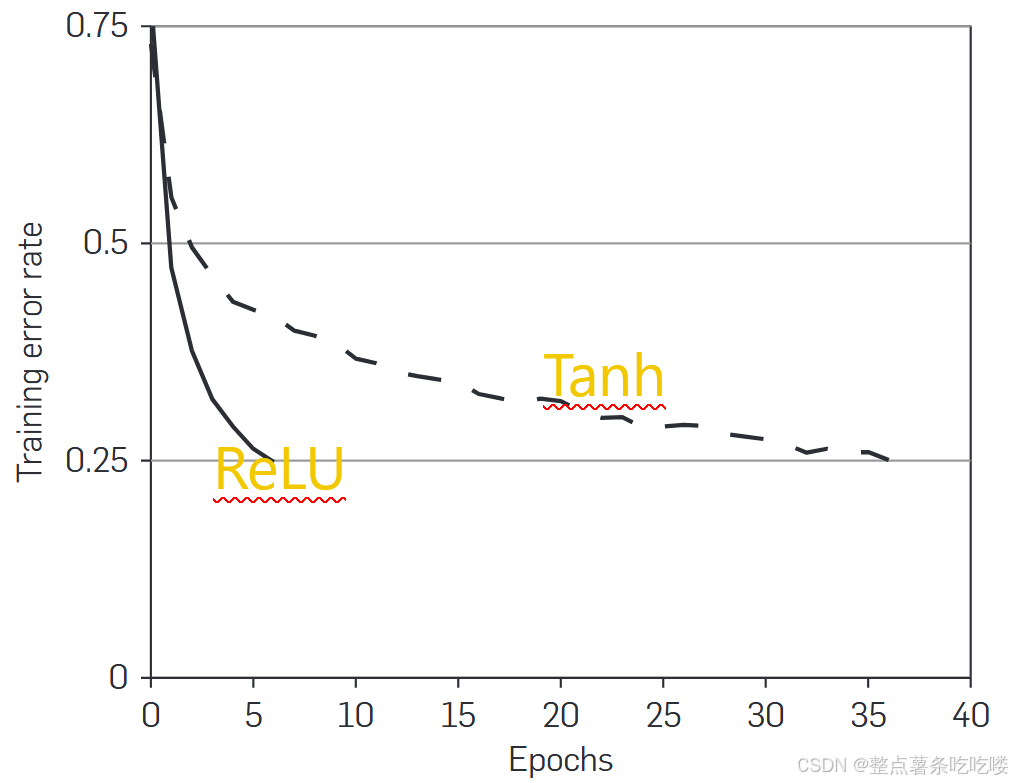
手画可还行
4.3. Local response normalization

用 ai x, y 表示在位置 (x, y) 应用核 i 并应用 ReLU 非线性计算出的神经元活动,响应归一化活动 bi x, y 的表达式为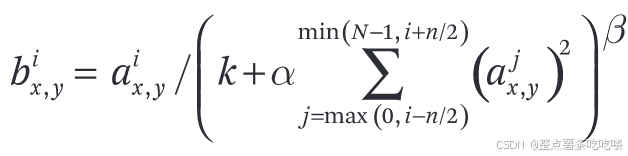
其中,总和为同一空间位置上 n 个 "相邻 "内核映射的总和,N 为该层的内核总数。
常数 k、n、α 和 β 是超参数,其值通过验证集确定。

关于N的理解:多通道卷积
通道数设置:
- CNN的卷积核通道数 = 卷积输入层的通道数
- CNN的卷积输出层通道数(深度)= 卷积核的个数
在卷积层的计算中,假设输入是H x W x C, C是输入的深度(即通道数),那么卷积核(滤波器)的通道数需要和输入的通道数相同,所以也为C,假设卷积核的大小为K x K,一个卷积核就为K x K x C,计算时卷积核的对应通道应用于输入的对应通道,这样一个卷积核应用于输入就得到输出的一个通道。假设有P个K x K x C的卷积核,这样每个卷积核应用于输入都会得到一个通道,所以输出有P个通道,因为CNN卷积输出层通道数就等于卷积核个数。
总结:
多通道卷积的计算过程:将矩阵与滤波器对应的每一个通道进行卷积运算,最后相加,形成一个单通道输出,加上偏置项后,我们得到了一个最终的单通道输出。如果存在多个filter,这时我们可以把这些最终的单通道输出组合成一个总输出。
参考【深度学习基础】CNN的卷积核通道数、卷积输出的通道数、步长与填充之间的关系(附多通道卷积)_卷积层 通道数-CSDN博客
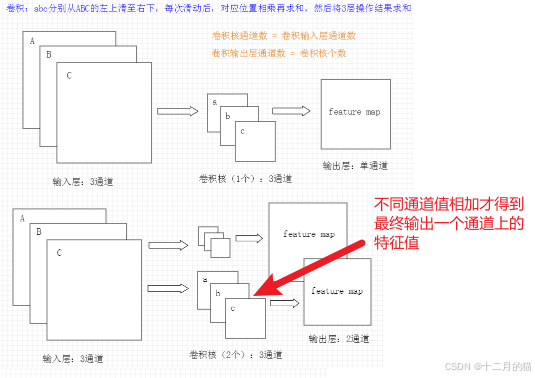
关于n的理解:
在神经网络中,尤其是在处理具有多个通道(channel)的特征图时,“局部邻域窗口大小(跨通道)”这个参数用于定义在跨通道维度上进行操作的区域大小。
通道(Channel):在处理图像时,通道通常指的是图像的色彩通道,如RGB图像有3个通道(红、绿、蓝)。在卷积神经网络(CNN)中,经过多层卷积操作后,特征图会有更多通道,每个通道都包含不同类型的特征信息。
局部邻域窗口:这是指在计算过程中,所操作的区域范围。例如,卷积核定义了一个局部邻域窗口,用于在特征图上滑动并进行计算。
示例
假设我们有一个特征图,其维度为 H×W×C(高度 × 宽度 × 通道)。传统的局部邻域窗口可能只考虑在 H×W 空间维度上的区域(例如,3×3像素的邻域)。而“跨通道”的局部邻域窗口不仅在空间维度上考虑,还在通道维度上定义一个大小为 n 的窗口。这意味着在计算时,会同时考虑多个通道中的局部区域,从而捕获通道之间的局部相关性。
响应归一化实现了一种横向抑制,其灵感来源于真实神经元中的类型,从而在使用不同内核计算的神经元输出之间形成了对大活动的竞争。
4.4. Overlapping pooling
更准确地说,池化层可以看作是由间隔 s 个像素的池化单元网格组成,每个池化单元概括了以汇集单元位置为中心的 z × z 大小的邻域。池化层通过池化单元对特征图进行局部汇总,以提取特征的代表性值。
传统上,池化单元之间的区域是不重叠的(s = z)。
如果池化单元之间的间距小于汇总区域的大小(s < z),则会导致区域重叠,这种重叠池化方式在某些情况下可以更好地捕捉特征的连续性。
重叠池化的优点
1.增加特征的连续性,使得模型对局部特征的变化更加敏感。
2.减少信息丢失,因为相邻区域之间有部分重叠,特征信息不会被完全丢弃。
5. REDUCING OVERFITTING
5.1数据增强(data augmentation)
- 把一些图片人工地变大
- 在图片中随机地抠出一部分区域,做一张新的图片
- 把整个RGB的颜色通道channel上做一些改变,这里使用的是一个PCA(主成分分析)的方法,颜色会有不同,因此每次图片跟原始图片是有一定的不同的
5.2 dropout
- 随机的把一些隐藏层的输出变成用50%的概率设为0,每次得到一个新的模型,但是权重是共享的
- dropout在现行模型上等价于一个L2正则项
- 这里将dropout用在了前面的两个全连接层上面
- 文没有dropout的话,overfitting会非常严重,有dropout的话,训练会比别人慢两倍
- dropout在全连接上还是很有用的,在RNN和Attension中使用的非常多
分步解析
1. Dropout 的操作过程
训练阶段:
对每个隐藏层的神经元,以概率 p=0.5将其输出置零(即暂时从网络中移除)。
未被置零的神经元的输出按 1/(1−p)缩放(此处 p=0.5,故放大为2倍),以保持激活值的总体期望不变。
每次训练迭代(或每个批次)随机生成一个新的“子网络”。
测试阶段:
不使用 Dropout,所有神经元均激活,但输出需乘以保留概率 (1−p)(即此处乘以0.5),以匹配训练时的期望。
2. 为什么是“每次得到一个新的模型”?
Dropout 的随机性导致每次迭代中网络的结构不同(部分神经元被丢弃),相当于训练了多个不同的子模型(Sub-model)。
这些子模型共享参数(同一组权重),但每次仅更新部分参数,最终通过参数共享和集成(Ensemble)提升泛化性能。
3. 50%概率的作用
平衡能力与鲁棒性:
过高的丢弃概率(如 p>0.8p>0.8)会导致网络容量不足,难以学习有效特征。
过低的丢弃概率(如 p<0.2p<0.2)则无法充分抑制过拟合。
经验表明,对隐藏层使用 p=0.5p=0.5 是一个常用且有效的平衡点。
缩放补偿:
丢弃后保留的神经元输出需放大2倍(11−0.5=21−0.51=2),确保训练和测试时的信号强度一致。
6. DETAILS OF LEARNING
- 使用SGD(随机梯度下降)来进行训练
SGD调参相对困难,后来发现SGD里面的噪音对模型的泛化性有好处的,所以现在深度学习中普遍使用SGD对模型进行训练。在这个文章之后SGD基本上在机器学习界成为了最主流的一个优化算法。
- weight decay(权重衰减)
也就是L2正则项,但是不是加在模型上,而是加在优化算法上,虽然两者是等价关系,但是因为深度学习,大家现在基本上把这个东西叫做weight decay了。
- momentum
当优化的表面非常不平滑的时候,冲量使得不要被当下的梯度过多的误导,可以保持一个冲量,沿着一个比较平缓的方向往前走,不容易陷入到局部最优解。
- 权重用的是一个均值为0,方差为0.01的高斯随机变量来初始化
对于一些相对简单的神经网络,0.01是一个不错的选项,现在就算是比较大的那些BERT,也只是用了0.02作为随机的初始值的方差。
- 在第二层、第四层和第五层的卷积层把初始的偏移量初始化成1,剩下的全部初始化成0
- 每个层使用同样的学习率,从0.01开始,如果验证误差不往下降了,就手动的乘以0.1,就是降低十倍
现在使用更加平滑的曲线来降低学习率,比如果用一个cos的函数比较平缓地往下降。一开始的选择也很重要,如果选的太大可能会发生爆炸,如果太小又有可能训练不动,所以现在主流的做法是学习率从0开始再慢慢上升,慢慢下降。
额外知识点
正则好像不是很重要,更关键的是神经网络的设计?
参考 https://dl.acm.org/doi/abs/10.1145/3446776
Abstract
尽管深度人工神经网络的规模很大,但成功的深度人工神经网络在训练和测试性能之间可以表现出非常小的差距。
传统观点将较小的泛化误差归因于模型系列的属性或训练期间使用的正则化技术。
BUT: 传统方法无法解释为什么大型神经网络在实践中可以很好地泛化。
因为: 用随机梯度方法训练的最先进的用于图像分类的卷积网络很容易拟合训练数据的随机标记。这种现象在质量上不受显式正则化的影响,即使我们用完全非结构化的随机噪声替换真实图像,这种现象也会发生。
一旦参数数量超过数据点的数量(过参数化),简单深度两个神经网络就已经具有完美的有限样本表达能力
参数数量 > 数据点数量:
神经网络的可调参数(权重和偏置)数量超过训练样本数量。例如,若训练集有1000个样本,模型参数可能有2000个。有限样本表达能力:
模型能够完美拟合有限数量的训练样本(训练误差趋近于零,即“插值”所有数据点)。简单深度网络:
即使是结构简单的深度神经网络(如两层全连接网络),在过参数化时也能实现这一目标。
无监督预训练的典型方法:
(1) 语言模型(NLP领域)
-
自回归模型(Autoregressive Models):如GPT系列,通过预测下一个词(Next Token Prediction)学习语言表示。
-
自编码模型(Autoencoding Models):如BERT,通过掩码语言建模(Masked Language Modeling, MLM)学习上下文表示。
-
对比学习(Contrastive Learning):如SimCSE,通过对比正负样本学习句子表示。
(2) 计算机视觉(CV领域)
-
自编码器(Autoencoders):通过重建输入图像学习特征表示。
-
对比学习:如SimCLR、MoCo,通过最大化正样本对之间的相似性和最小化负样本对之间的相似性学习特征。
-
生成对抗网络(GANs):通过生成器和判别器的对抗训练学习数据分布。
(3) 多模态领域
-
跨模态对比学习:如CLIP,通过匹配图像和文本对学习跨模态表示。
-
掩码建模:如BEiT、MAE,通过预测被掩码的图像块或文本片段学习特征。
梯度特性对参数更新的影响不同。
在梯度下降训练过程中,饱和型非线性激活函数(saturating nonlinearities)(如 Sigmoid、Tanh)与非饱和型非线性激活函数(non-saturating nonlinearities)(如 ReLU)在训练速度上的差异。核心原因在于两者的梯度特性对参数更新的影响不同。
1. 关键概念
(1) 饱和型非线性(Saturating Nonlinearities)
-
定义:当输入值的绝对值较大时,激活函数的梯度趋近于零。
-
典型例子:
-
Sigmoid:f(x)=11+e−xf(x)=1+e−x1,梯度 f′(x)=f(x)(1−f(x))f′(x)=f(x)(1−f(x)),当 x→±∞x→±∞ 时,f′(x)→0f′(x)→0。
-
Tanh:f(x)=ex−e−xex+e−xf(x)=ex+e−xex−e−x,梯度 f′(x)=1−f(x)2f′(x)=1−f(x)2,当 x→±∞x→±∞ 时,f′(x)→0f′(x)→0。
-
(2) 非饱和型非线性(Non-saturating Nonlinearities)
-
定义:在输入值的正区间内,梯度保持恒定(非零)。
-
典型例子:
-
ReLU:f(x)=max(0,x)f(x)=max(0,x),梯度在 x>0x>0 时为 1,在 x≤0x≤0 时为 0。
-
2. 为什么饱和型非线性训练更慢?
(1) 梯度消失问题(Vanishing Gradients)
-
现象:当输入值过大或过小时,饱和型激活函数的梯度趋近于零,导致反向传播中参数更新量极小。
-
后果:
-
深层网络中梯度逐层衰减,浅层参数几乎不更新。
-
训练停滞,收敛速度大幅降低。
-
(2) ReLU 的梯度特性
-
优势:在 x>0x>0 时,ReLU 的梯度恒为 1,避免了梯度消失。
-
效果:
-
反向传播时梯度能有效传递到浅层网络。
-
参数更新幅度稳定,训练速度显著提升。
-
3. 补充说明
(1) ReLU 的局限性
-
死亡 ReLU(Dead ReLU):当输入 x≤0时,梯度为零,神经元可能永久失活。
-
改进方案:
-
Leaky ReLU:f(x)=max(αx,x)(α 为小常数,如 0.01)。
-
Parametric ReLU (PReLU):将 α 作为可学习参数。
-
ELU:f(x)=x(x>0),f(x)=α(ex−1)(x≤0)。
-
(2) 饱和型激活函数的适用场景
-
某些特定任务(如二分类输出层)仍可能使用 Sigmoid。
-
循环神经网络(RNN)中,Tanh 常用于隐藏层,但需配合梯度裁剪(Gradient Clipping)缓解梯度问题。
总结
-
饱和型非线性(如 Sigmoid、Tanh)在梯度下降中训练速度慢,原因是输入值较大时梯度消失,导致参数更新停滞。
-
非饱和型非线性(如 ReLU)在正区间保持恒定梯度,避免了梯度消失,显著加速训练。
-
实践中,ReLU 及其变体已成为深度网络的首选激活函数,平衡了训练速度和模型性能。
侧抑制(Lateral Inhibition)机制的实现,以及响应归一化(Response Normalization)的作用。
其核心思想是通过模仿生物神经元的竞争机制,增强特征表达的有效性和多样性。以下是分步解析:
1. 关键概念解释
(1) Kernel Maps(卷积核映射)
-
定义:每个卷积核(kernel)在输入数据上滑动计算后生成的特征图(feature map)。不同卷积核提取不同特征(如边缘、纹理、颜色等)。
-
“排序是任意的”:卷积核的初始化顺序(即特征图的排列顺序)在训练前是随机确定的,没有固定意义,但一旦训练开始,每个卷积核会学习到特定的特征模式。
(2) 侧抑制(Lateral Inhibition)
-
生物学来源:在生物神经系统中,活跃的神经元会抑制邻近神经元的活动,从而增强显著信号的对比度(例如视觉系统中突出边缘或运动物体)。
-
CNN中的模拟:通过响应归一化,让 同一位置 不同卷积核(特征通道)的激活值相互竞争,抑制非显著特征,突出重要特征。
(3) 响应归一化(Response Normalization)
-
作用:对同一空间位置上不同卷积核的激活值进行归一化,使大激活值抑制小激活值,从而增强特征间的差异性。
-
典型实现:如局部响应归一化(Local Response Normalization, LRN),曾用于AlexNet等早期CNN模型。
-
示例:输入图像:一只猫的图片。
-
卷积核响应:
-
卷积核1:检测“竖直边缘”(如猫的胡须)。
-
卷积核2:检测“水平边缘”(如背景中的地板纹理)。
-
-
归一化后:若竖直边缘的激活更强,则抑制水平边缘的响应,使网络更关注猫的胡须而非背景。
2. 与后续技术的对比
-
LRN vs. Batch Normalization(BN):
-
LRN:跨通道归一化,模拟侧抑制,增强局部特征对比。
-
BN:跨批次归一化,解决内部协变量偏移(Internal Covariate Shift),稳定训练过程。
-
现状:BN逐渐取代LRN,成为主流归一化方法,但侧抑制的思想仍影响后续设计(如分组卷积、通道注意力机制)
-

















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









