







只是为了学习
目录
Create dataset classifier from label text
1. Introduction and Motivating Work
2.1. Natural Language Supervision
2.2. Creating a Sufficiently Large Dataset
2.3. Selecting an Efficient Pre-Training Method
2.4. Choosing and Scaling a Model
(2) Vision Transformer (ViT) 架构
简单了解
CLIP(Contrastive Language–Image Pretraining)是OpenAI提出的一种多模态模型,旨在通过对比学习对齐图像和文本的语义表示。以下是其核心要点:
1. 核心思想
-
目标:将图像和文本映射到同一嵌入空间,使配对的图像-文本对在空间中相似度最大化,非配对对的相似度最小化。
-
方法:通过对比学习(Contrastive Learning)训练图像编码器和文本编码器,学习跨模态的语义对齐。
2. 模型结构
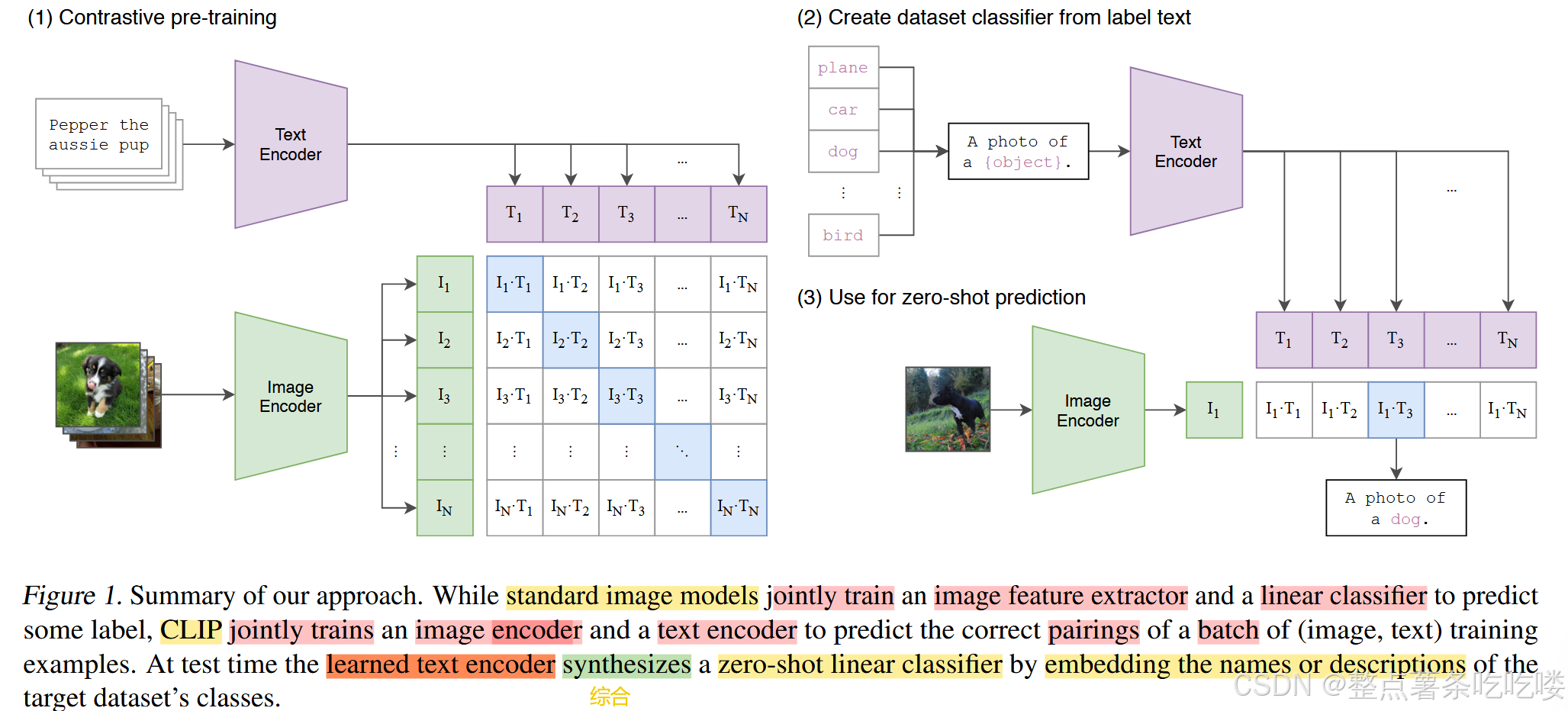
总结一下,就是将text和image分别通过Bert和Vit,分别获取文本的Embedding和图像的Embedding,将配对的(上图对角线)上的两个Embedding的内积最大化
-
图像编码器:
-
可选架构:ResNet(如ResNet-50)或Vision Transformer(ViT)。
-
功能:将图像转换为特征向量(如ViT-L/14输出768维向量)。
-
input:假设每个 training batch 都有 N 个 图像-文本 对 输入Image Encoder
-
Image Encoder输出N 个图像的特征(如图I1,I2,,,,IN)。
-
-
文本编码器:
-
架构:Transformer(类似BERT的Base或Large版本)。
-
功能:将文本描述(如“一只猫在沙发上”)转换为同维度的特征向量。
-
imput:同上
-
Text Encoder输出到N 个文本的特征(如图 T1,T2,,,TN)。
-
- CLIP 基于以上特征进行对比学习,需要正样本和负样本的定义
- 在这里配对的 图像-文本对就是正样本(即图中对角线蓝色部分)
- 矩阵中,剩下的所有非对角线元素(图中白色部分)就是负样本。
- 有了正、负样本后,模型就可以通过对比学习的方式去训练,不需要任何手工的标注。
-
相似度计算:
计算图像和文本嵌入的余弦相似度,通过对比损失优化。
- 在推理时,输入一张任意图片到Image Encoder,得到图像特征(绿色框,I1),
- 这个图片特征I1跟所有的文本特征(紫色框,T1,T2,,,TN)去做 cosine similarity(余弦相似度)计算相似度(I1−T1,I1−T2,,,I1−TN)
- 看这张图片与哪个文本最相似,就把这个文本特征所对应的句子挑出来,从而完成这个分类任务。
Create dataset classifier from label text
CLIP 经过预训练后只能得到视觉上和文本上的特征,并没有在任何分类的任务上去做继续的训练或微调,所以它没有分类头,那么 CLIP 是如何做推理的呢?、
CLIP(Contrastive Language–Image Pretraining)的推理过程基于其预训练阶段学到的多模态嵌入对齐能力,通过将分类任务转化为图像-文本相似度匹配问题,无需传统意义上的分类头(Classifier Head)。以下是具体原理和步骤:
1. 核心思想:零样本分类(Zero-Shot Classification)
CLIP的推理不依赖分类头,而是通过自然语言提示(Text Prompt)将类别标签转化为文本嵌入,并与图像嵌入计算相似度,直接完成分类。其本质是利用文本编码器动态生成分类权重。
2. 实现步骤
(1) 生成文本提示(Prompt Engineering)
输入:数据集的类别标签(如ImageNet的1000个类别名)。
模板化:将类别名嵌入自然语言描述的模板中,例如:"这是一张{类别}的图片"
更复杂的模板可能提升性能(如
"一张{类别}的高清卫星图像,拍摄于白天"用于遥感分类)。示例(ImageNet分类):["一张狗的照片", "一张猫的照片", ..., "一张飞机的照片"]
4. 关键设计细节
(1) 提示工程(Prompt Engineering)
作用:通过模板添加上下文,使文本描述更贴近预训练数据的分布(如“照片”一词与CLIP的Web数据匹配)。
改进策略:
多模板集成:对每个类别生成多个提示,取文本嵌入的平均。
领域适配:根据任务调整模板(如医学图像使用“一张X光片显示{类别}”)。
(2) 温度参数 τ
作用:缩放相似度值的范围,控制预测概率分布的尖锐程度。
CLIP的实现:τ在预训练时作为可学习参数优化,推理时固定。
5. 为什么不需要微调?
嵌入空间对齐:CLIP的预训练目标本身就是让配对的图像-文本对在嵌入空间中靠近,非配对对远离。
泛化能力:大规模预训练(4亿对数据)使模型学习了通用的视觉-语言对齐能力,可直接迁移到下游任务。
6. 与微调模型的对比
特性 CLIP(零样本) 传统监督模型(微调) 分类头 无(动态生成自文本嵌入) 需要固定分类头 数据需求 无需任务特定数据 需要标注数据 领域迁移能力 强(依赖提示工程) 弱(需重新训练) 计算成本 低(仅推理) 高(需微调)


即使这个类别标签是没有经过训练的,只要图片中有某个物体也是有很大概率判断出来的,这就是 zero-shot。
但如果像之前的那些方法,严格按照1000个类去训练分类头,那么模型就只能判断出这1000个类,这1000个类之外的所有内容都将判断不出来。
CLIP 彻底摆脱了 categorical label 的限制,无论在训练时,还是在推理时,都不需要有这么一个提前定好的标签列表,任意给出一张图片,都可以通过给模型不同的文本句子,从而知道这张图片里有没有我想要的物体。
5. 关键优势
-
跨任务泛化:支持图像分类、检索、生成(如DALL·E)、视觉问答等任务。
-
零样本能力:无需特定数据集训练,直接通过文本提示适配新任务。
-
高效迁移:在多数任务中接近或超越监督模型(如ResNet)的性能。
-
CLIP是一个预训练模型,训练好的模型能实现,输入一段文本(或者一张图像),输出文本(图像)的向量表示。CLIP和BERT、GPT、ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面内容,而BERT、GPT是单文本模态的,ViT是单图像模态的。
6. 应用场景
-
图像分类:零样本分类、细粒度识别(如鸟类品种)。
-
跨模态检索:以文搜图、以图搜文。
-
内容生成:结合生成模型(如DALL·E 2)生成文本描述的图像。
-
内容审核:检测违规图像或文本描述。
7. 局限性
-
提示工程敏感:文本提示的微小变化(如加标点)可能显著影响结果。
-
细粒度任务不足:在需要精确细节的任务(如医学图像分析)上表现有限。
-
计算成本高:大规模预训练和推理需要高性能硬件支持。
8. 实验表现
-
ImageNet零样本:CLIP ViT-L/14达到76.2%准确率,接近原始ResNet-50(76.1%)的监督训练结果。
-
鲁棒性测试:在分布偏移(如素描、对抗样本)下表现优于传统模型。
9. 对比其他模型
-
ALIGN:类似方法,但使用更大规模噪声数据(1.8亿对)。
-
Florence:微软提出的扩展版本,支持视频和更复杂的多模态任务。
-
BLIP:结合生成与理解能力,优化多模态交互。
10. 未来方向
-
效率优化:轻量化模型部署(如MobileCLIP)。
-
多模态扩展:支持音频、视频等多模态输入。
-
减少偏差:解决数据偏见导致的模型偏差问题。
CLIP通过统一图像与文本的语义空间,开创了零样本多模态学习的新范式,成为计算机视觉与自然语言处理交叉领域的里程碑工作。其代码和预训练模型已在GitHub开源,推动了广泛的研究与应用。
Abstract
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept.
Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision.
我们证明,预测哪张图片配哪个标题这一简单的预训练任务,是在从互联网上收集的 4 亿个(图片、文本)数据集上从头开始学习 SOTA 图像表征的有效且可扩展的方法。
我们通过在超过30个不同的现有计算机视觉数据集上进行基准测试来评估该方法的性能,这些数据集涵盖OCR、视频动作识别、地理定位以及多种细粒度物体分类等任务。
该方法在大多数任务中展现出显著的迁移能力,且无需针对任何特定数据集进行训练即可与全监督基线模型竞争。
例如,在零样本(zero-shot)设置下,我们无需使用任何128万张训练样本,就达到了原始ResNet-50在ImageNet上的准确率。
9. Conclusion
We have investigated whether it is possible to transfer the success of task-agnostic web-scale pre-training in NLP to another domain.我们研究了是否有可能将 NLP 中任务无关的、基于网络规模数据的预训练的成功经验移植到另一个领域。
Task-agnostic(任务无关的):指模型在预训练阶段不针对特定任务进行优化,而是学习通用的特征表示,能够适应多种下游任务(如分类、检测、生成等)。
Pre-training(预训练):指在大规模数据上训练模型,使其学习到通用的特征或知识,之后可以通过微调(Fine-tuning)或零样本学习(Zero-shot Learning)适配到具体任务。
This task learning can then be leveraged via natural language prompting to enable zero-shot transfer to many existing datasets.这种任务学习可以通过自然语言提示加以利用,从而实现对许多现有数据集的零点转移。
At sufficient scale, the performance of this approach can be competitive with task-specific supervised models although there is still room for much improvement.
1. Introduction and Motivating Work
CLIP 与 Learning Visual N-Grams from Web Data (2017年)的工作比较相似,都做了 zero-shot 的迁移学习,但当时 Transformer 还未提出,也没有大规模的且质量较好的数据集,因此17年的这篇论文的效果并不是很好。
有了 Transformer、对比学习、”完形填空“ 等强大的自监督训练方式后,也有一些工作尝试把图片和文本结合起来,去学得更好的特征,如 VirTex,ICMLM,ConVIRT,这些工作与 CLIP 很相似,但也有所区别,VirTex使用自回归的预测方式做模型的预训练;ICMLM使用 ”完形填空“ 的方法做预训练;ConVIRT 与 CLIP 很相似,但只在医学影像上做了实验。这三种方法都没有在模型或数据集上使用很大的规模。
2. Approach
2.1. Natural Language Supervision
早期主题模型和 n-gram 表示时与自然语言的复杂性进行了斗争,但深度上下文表示学习使之有效利用(McCann 等人,2017 年)。
为什么要用自然语言的监督信号来训练视觉模型?潜在优势?
- 不需要再去标注这些数据了,那么数据的规模很容易就变大。
- 被动地学习监督信息,监督信号是一个文本,而不是 N 选 1 的标签,模型的输入输出自由度就大了很多。
- 将表征与语言联系起来,实现灵活的零样本迁移。 训练时把图片和文本绑定到一起,那么训练的特征就不再仅是一个视觉特征了,而是一个多模态的特征,也就很容易去做 zero-shot 的迁移学习。如果只是做单模态的自监督学习,无论是单模态的对比学习(如MOCO),还是单模态的掩码学习(如MAE),都只能学到视觉特征,而无法与自然语言联系到一起,这样还是很难做 zero-shot 迁移。
2.2. Creating a Sufficiently Large Dataset
2.3. Selecting an Efficient Pre-Training Method
我们最初的方法与 VirTex 类似,从头开始联合训练图像 CNN 和文本转换器,以预测图像的标题。 然而,我们在有效扩展这种方法时遇到了困难。 在图 2 中,我们看到一个 6,300 万参数的transformer language model(其计算量已是 ResNet-50 图像编码器的两倍)在学习识别 ImageNet 类别时,比预测相同文本的词袋编码的简单基线慢三倍。
这两种方法都有一个关键的相似之处。 它们都试图预测每张图片所配文字的准确字词。 由于与图像同时出现的描述、评论和相关文本种类繁多,因此这是一项艰巨的任务。
最近在图像对比性表征学习方面的研究发现,对比性目标能比同等的预测性目标学习到更好的表征(Tian 等人,2019 年)。 其他研究发现,虽然图像生成模型可以学习高质量的图像表征,但与具有相同性能的对比模型相比,它们所需的计算量要高出一个数量级(Chen 等人,2020a)。
于是,我们只预测哪段文字作为一个整体与哪张图片配对,而不是预测该文字的确切单词。 从相同的字袋编码基线开始,我们将预测目标换成了图 2 中的对比目标,并观察到零样本迁移到 ImageNet 的效率提高了 4 倍。

- 给定一批 N 个(图片、文本)配对
- CLIP 经过训练可预测 N × N 个可能的(图片、文本)配对中哪一个实际出现
- CLIP 学习多模态嵌入空间
- 联合训练图像编码器和文本编码器
- 最大化批次中 N 个真实配对的图像和文本嵌入的余弦相似度,
- 最小化 N 2 - N 个错误配对的嵌入的余弦相似度。
- 在相似性得分上优化symmetric cross entropy loss
下面包含了 CLIP 核心实现的伪代码。
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts # W_i[d_i, d_e] - learned proj of image to embed # W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2大规模预训练数据,过拟合不是主要问题,因此CLIP能够简化训练流程,减少对复杂技巧的依赖。具体简化措施包括:
从头训练图像和文本编码器;
理解:CLIP的图像编码器(如ResNet或ViT)和文本编码器(如Transformer)均未使用预训练权重(如ImageNet预训练的ResNet或BERT),而是从头训练。
意义:避免了预训练权重可能引入的偏差,使模型更适应多模态任务。
使用线性投影代替非线性投影;
理解:
非线性投影:在对比学习中,通常使用多层感知机(MLP)将编码器的输出映射到对比嵌入空间(如SimCLR中的设计)。
CLIP的简化:仅使用线性投影(单层矩阵变换)将图像和文本编码器的输出映射到多模态嵌入空间。
原因:作者发现非线性投影并未显著提升训练效率,推测其可能仅在与当前图像自监督学习方法结合时才有用。
简化文本和图像变换函数;
理解:
Zhang等人(2020)的方法中,文本变换函数 tu 会从文本中均匀采样一个句子。
CLIP的预训练数据集中,许多图像-文本对仅包含一个句子,因此直接使用整个文本,无需采样。
意义:简化了文本处理流程,减少了不必要的计算。
理解:
图像变换:通常包括裁剪、翻转、颜色抖动等多种数据增强技术。
CLIP的简化:仅使用随机方形裁剪(从调整大小后的图像中随机裁剪一个方形区域)作为数据增强。
意义:简化了图像处理流程,同时保持了足够的多样性。
动态优化温度参数。
理解:
温度参数 τ:用于调整Softmax中logits的分布范围,影响对比学习的难度。
CLIP的改进:将 τ 作为可训练参数(对数参数化的乘法标量),而非固定的超参数。
意义:动态调整温度参数,避免了手动调参的麻烦,同时提升了模型性能。
2.4. Choosing and Scaling a Model
1. 图像编码器的两种架构
(1) ResNet-50 架构
改进措施:
-
ResNetD改进,优化了网络结构。
-
抗锯齿池化:抗锯齿矩形-2模糊池化(antialiased rect-2 blur pooling),减少下采样时的混叠效应。
-
注意力池化:将全局平均池化层替换为注意力池化机制。
实现方式:使用单层“Transformer风格”的多头QKV注意力机制,其中查询(Query)基于图像的全局平均池化表示。
(2) Vision Transformer (ViT) 架构
改进措施:在Transformer的输入前,对图像块嵌入(Patch Embedding)和位置嵌入(Position Embedding)的组合结果增加一层归一化。
2. 文本编码器的架构
-
基础架构:Transformer的改进版本
具体配置:
基础模型:63M参数,12层,512维,8个注意力头。
输入表示:使用小写字节对编码(BPE),词汇表大小为49,152(Sennrich et al., 2015)。
序列长度:最大长度限制为76。
特殊标记:文本序列以[SOS](开始)和[EOS](结束)标记包围。
特征提取:取[EOS]标记对应的最高层激活作为文本特征表示,经过层归一化后线性投影到多模态嵌入空间。
掩码自注意力:使用掩码自注意力机制,以便支持预训练语言模型的初始化或添加语言建模作为辅助目标(未在本文中探索)。
3. 模型扩展策略
-
图像编码器(ResNet)的扩展:
-
传统方法:单独增加宽度(Mahajan et al., 2018)或深度(He et al., 2016a)。
-
CLIP的策略:采用Tan & Le(2019)的方法,同时增加宽度、深度和分辨率,以更高效地分配计算资源。
-
具体实现:将额外计算资源均匀分配到宽度、深度和分辨率的增加上。
-
-
-
文本编码器的扩展:
-
仅增加宽度:文本编码器的宽度与ResNet的宽度增加成比例扩展。
-
不增加深度:实验发现CLIP的性能对文本编码器的容量不敏感。
-
2.5. Training
3. Experiments
3.1. Zero-Shot Transfer
3.1.1. MOTIVATION
3.1.2. USING CLIP FOR ZERO-SHOT TRANSFER
3.1.3. INITIAL COMPARISON TO VISUAL N-GRAMS
3.1.4. PROMPT ENGINEERING AND ENSEMBLING
3.1.5. ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE
3.2. Representation Learning
3.3. Robustness to Natural Distribution Shift
4. Comparison to Human Performance
5. Data Overlap Analysis
6. Limitations
7. Broader Impacts

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









