







只是为了学习
目录
3.1 Encoder and Decoder Stacks
2. 输出嵌入的偏移(Shifted Output Embeddings)
3.2.1 Scaled Dot-Product Attention
3.2.3 Applications of Attention in our Model
3.3 Position-wise Feed-Forward Networks
用下面的20道面试题看看自己是不是真的掌握了transformer这个模型。
初步了解
基于Transformer的语言模型是自然语言处理(NLP)领域的革命性技术,其核心是自注意力机制和并行化处理能力。以下是对其关键点及应用的系统总结:
1. Transformer架构核心
-
自注意力机制(Self-Attention):通过计算序列中每个词与其他词的相关性(查询query、键key、值value的点积),动态捕捉上下文依赖。引入缩放因子(dk)防止梯度爆炸,并支持多头注意力(多个独立注意力头学习不同模式)。
-
位置编码(Positional Encoding):使用正弦/余弦函数或可学习的嵌入向量,为模型注入序列位置信息,弥补Transformer缺乏循环/卷积结构的缺陷。
-
前馈网络(FFN)与残差连接:每个注意力层后接全连接层(如ReLU激活)进行非线性变换,配合残差连接和层归一化,缓解梯度消失问题。
2. 典型模型分类
-
编码器架构(如BERT)专注于双向上下文理解,通过掩码语言建模(MLM)预训练,适用于分类、问答等任务。
-
解码器架构(如GPT系列)采用自回归生成(预测下一个词),仅利用左侧上下文,擅长文本生成、续写等任务。
-
编码器-解码器架构(如T5、BART)处理序列到序列任务(翻译、摘要),结合双向编码和自回归生成。
3. 训练与优化
-
预训练任务
BERT:MLM + 下一句预测(NSP)
GPT:自回归语言建模
ELECTRA:替换词检测(更高效)
-
微调与迁移学习:预训练模型通过少量标注数据微调,适配下游任务,显著降低数据需求。
-
优化技术:Adam优化器、学习率预热、梯度裁剪、混合精度训练等,支撑大规模参数(如GPT-3的175B参数)训练。
4. 优势与挑战
优势:
-
长距离依赖捕捉能力远超RNN/CNN;
-
并行计算加速训练;迁移学习范式提升小任务表现
挑战:
-
计算成本高:注意力复杂度为O(n2)O(n2),长文本处理受限(需稀疏注意力、分块等优化);
-
可解释性差:黑盒模型决策过程不透明;
-
数据偏见:训练数据中的社会偏见可能被放大,需伦理审查。
5. 创新与改进
-
高效架构
-
任务统一化:T5将任务转换为“文本到文本”格式,统一处理翻译、分类等任务。
6. 未来方向
-
轻量化模型:蒸馏(如DistilBERT)、量化、剪枝
-
多模态扩展:结合视觉、语音(如CLIP、DALL·E)
Abstract
主流的序列转换(sequence transduction)模型都是编码器(encoder)和解码器(decoder)架构,并基于复杂的循环或卷积神经网络实现。目前性能最好的模型还加入了注意力机制将编码器和解码器连接起来。
我们提出了一种新的简单网络架构——Transformer,其仅使用注意力机制,完全不需要循环和卷积单元。
7 Conclusion
完全基于注意力的序列转换模型,用多头自注意力取代了编码器-解码器架构中最常用的循环层。
计划将 Transformer 扩展到文本以外的输入和输出模式的问题,并研究局部的、受限的注意力机制,以有效地处理图像、音频和视频等大型输入和输出。让生成具有更少的顺序性。
1 Introduction
循环模型通常会沿着输入和输出序列的符号位置进行计算。通过在计算时将位置与时间步(steps)对齐,其生成一系列隐藏状态 ℎ𝑡 ,作为前一个隐藏状态 ℎ𝑡−1 与位置 𝑡 二者的函数。
这些模型天生要求顺序操作,这阻碍了训练样本中的并行化,但在较长的序列上进行并行化十分重要,因为有限的内存限制了样本之间的批处理。
注意力机制(Attention)允许对依赖关系进行建模,而不用考虑它们在输入或输出序列中的距离。
在这项工作中,我们提出了 Transformer,避免使用循环的模型架构,完全依赖注意力机制来描述输入和输出之间的全局依赖关系。Transformer 显著提高了并行度,仅在 8 个 P100 GPU 上进行 12 小时的训练后,即可以在翻译质量方面达到新的 sota。
2 Background
使用卷积神经网络作为基本模块,并行地计算所有输入和输出位置的隐藏表示(hidden representations)。在这些模型中,将来自两个任意输入或输出位置的信号关联起来所需的操作数,随位置之间的距离而增加, ConvS2S 为线性增长, ByteNet 则是对数增长。这使得学习远距离的依赖关系变得更加困难 [12]。
在 Transformer 中,这被减少至常数次操作,尽管其代价是由于注意力加权位置平均化而降低了有效分辨率,我们用多头注意力(Multi-Head Attention)来抵消这种影响,见 3.2 节。
自注意力(Self-attention)将单一序列不同位置相关联的注意力机制,可以计算序列的表示形式。
端到端记忆网络(End-to-end memory networks)基于循环注意力(recurrent attention)机制,而非序列对齐循环(sequence-aligned recurrence),已证明其在简单语言问答和语言模型任务上有良好的表现 [34]。
3 Model Architecture
大多数有竞争力的神经序列转换模型都采用编码器-解码器结构 [5,2,35]。
编码器将符号表示的输入序列 (𝑥1,...,𝑥𝑛) 映射到连续的序列 𝑧=(𝑧1,...,𝑧𝑛) 。
给定 𝑧 ,解码器随之生成一个符号输出序列 (𝑦1,...,𝑦𝑚) ,一次生成一个元素。
每一步中,模型都是自回归(auto-regressive)[10] 的,生成下一个元素时,将先前生成的符号用作附加输入。
Transformer 遵循这个整体架构,对编码器和解码器使用多层堆叠的自注意力层,以及逐点(point-wise)的全连接层,分别如图 1 的左右两部分所示。
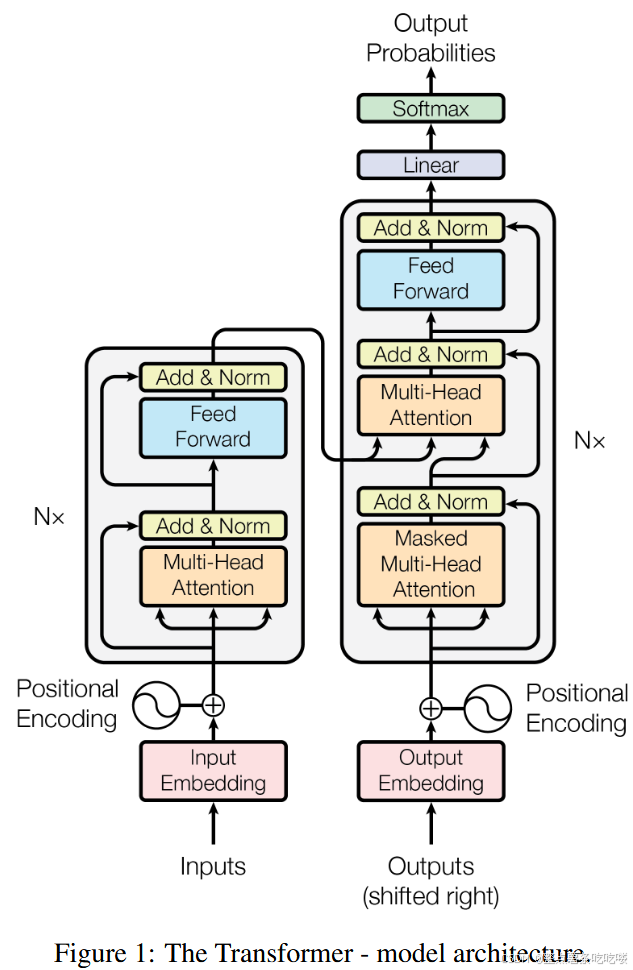
3.1 Encoder and Decoder Stacks
Encoder:
- 编码器由 𝑁=6 个相同层组成的栈构成。
- 每一层有两个子层,其一是multi-head self-attention机制,其二是简单的positionwise fully connected feed-forward network。
- 我们的两个子层都采用残差连接(residual connection)[11],随之layer normalization[1]。换言之,每个子层的输出为 LayerNorm(𝑥+Sublayer(𝑥)) ,其中 Sublayer(𝑥) 是子层本身实现的函数。
- 为方便残差连接,模型中所有子层及嵌入(embedding)层都生成 𝑑model=512 维的输出。
Decoder:
- 解码器也由 𝑁=6 个相同层组成的栈构成。
- 除了编码器层中的两个子层之外,解码器还插入了第三个子层,该子层对编码器栈的输出执行多头注意力。
- 与编码器类似,我们对每个子层采用残差连接,随之进行层归一化。
- 修改了解码器栈中的自注意力子层,以防止以当前位置信息中被添加进后续的位置信息。mask与偏移一个位置输出嵌入的相结合,保证位置 𝑖 的预测只能依赖于位置小于 𝑖 的已知输出。
在Transformer解码器的设计中,为了确保模型在生成序列时遵循自回归(Autgressive)特性(即位置 ii 的预测仅依赖于位置 <i 的信息),需通过以下两个关键机制约束自注意力子层:
1. Masked Self-Attention 的原理
目标:防止当前位置 i 在计算注意力时“看到”未来的位置(j>i)。
实现:
掩码(Mask)矩阵:在自注意力计算中,对注意力权重矩阵应用一个下三角掩码。
效果:
生成第 ii个位置的输出时,模型只能利用前 i−1个位置的已知信息,符合自回归生成的要求。
2. 输出嵌入的偏移(Shifted Output Embeddings)
目标:确保训练时的输入与预测时的行为一致。
实现:
在训练阶段,将目标序列(待生成的输出序列)向右移动一位,并在开头添加一个特殊的起始符(如
<sos>)。
输入序列(Decoder Input):
[<sos>, y_1, y_2, ..., y_{n-1}]目标序列(Decoder Output):
[y_1, y_2, ..., y_n]在预测阶段,模型逐步生成序列:
初始输入为起始符
<sos>,生成第一个词 y1;将 y1作为输入,生成 y2,依此类推。
效果:
训练时,模型在预测位置 i时,实际接收的输入是前 i−1 步生成的输出(而非当前步的真实标签),避免了信息泄漏。
迫使模型学会仅依赖历史信息生成下一个词。
3. Mask与偏移的协同作用
通过掩码自注意力和输入偏移的结合,模型实现了严格的自回归生成:
掩码机制:在计算注意力时,强制模型仅关注当前位置之前的上下文。
输入偏移:在训练时对齐输入与输出的位置,确保模型学习到正确的条件概率分布:
P(yi∣y1,y2,...,yi−1).
技术细节与示例
输入偏移的直观示例
假设目标序列为
["A", "B", "C"]:
Decoder输入:
[<sos>, "A", "B"](右移一位 + 起始符)Decoder输出:
["A", "B", "C"]
模型在预测位置3(对应输出"C")时,输入为[<sos>, "A", "B"],且掩码禁止关注位置3及之后的信息。掩码的矩阵表示
以序列长度3为例,掩码矩阵 M 为:
M=
第一行:位置1只能关注自身(起始符);
第二行:位置2可以关注位置1和2;
第三行:位置3可以关注所有位置,但实际训练中由于输入偏移,此时输入不包含位置3的真实标签。
总结
通过掩码自注意力和输入偏移的协同设计,Transformer解码器确保了:
生成位置 i时,模型无法访问未来信息(由掩码保证);
训练与预测的行为一致,避免信息泄漏(由输入偏移保证)。
这是自回归生成模型(如GPT、Transformer-based翻译模型)的核心机制。

3.2 Attention
3.2.1 Scaled Dot-Product Attention
- 输入:𝑑𝑘 维的 queries 和 keys 以及 𝑑𝑣 维的 values
- 计算 query 和所有 keys 的点积,随之除以 𝑑𝑘 ,再应用 softmax 函数来获取 values 的权重。
- 实际应用中,将一组 queries 转换成一个矩阵 𝑄 ,同时应用注意力函数。keys 和 values 也同样被转换成矩阵 𝐾 和 𝑉 。
- 按照
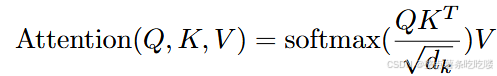 计算输出矩阵。
计算输出矩阵。
- 两种最常用的注意力函数是加性注意力(additive attention)[2] 和点积注意力(dot-product (multiplicative) attention)。
- 点积注意力与我们的算法相同,只是没有 1𝑑𝑘 的缩放因子。
- 加性注意力使用有单个隐藏层的前馈网络来计算兼容函数。
- 虽然二者在理论复杂性上相似,但在实践中点积注意力更快、更节省空间,因其可以使用高度优化的矩阵乘法代码来实现。
- 对于较小的 𝑑𝑘 值,两种机制的表现相似,但对于较大的 𝑑𝑘 值,additive优于dot-product,且无需进行缩放[3]。
- 对于较大的 𝑑𝑘 值,点积的数量级会变大,从而会将 softmax 函数推入梯度极小的区域 。为了抵消这种影响,将点积缩放 1𝑑𝑘 倍。
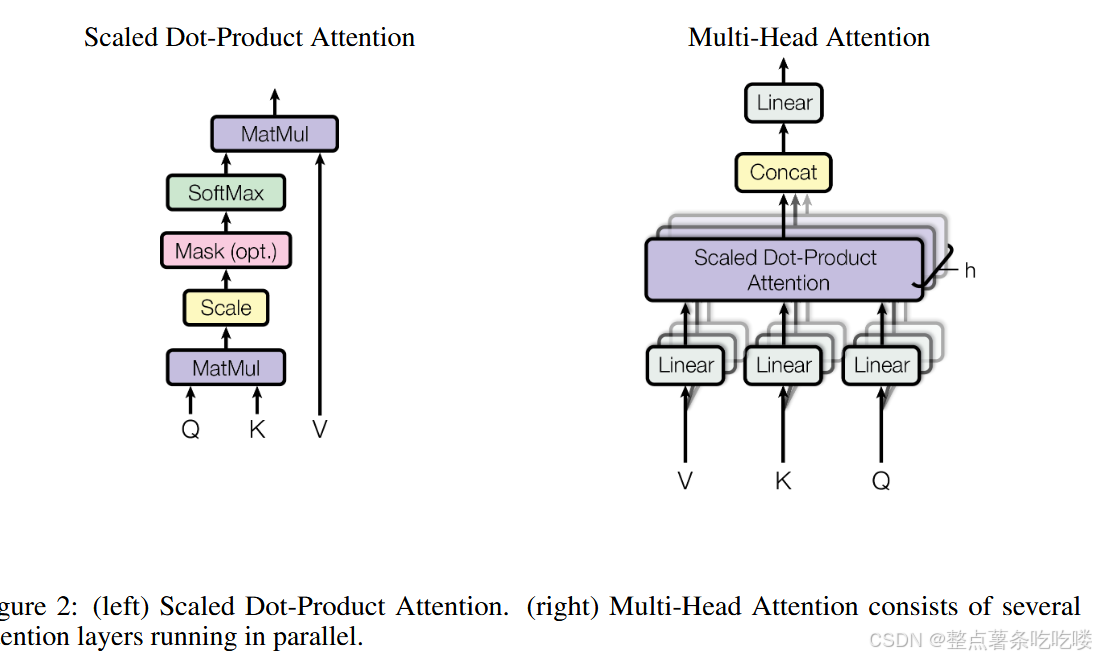
3.2.2 Multi-Head Attention
- Instead of performing a single attention function with dmodel-dimensional keys, values and queries
- we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively.
- On each of these projected versions of queries, keys and values ,we then perform the attention function in parallel,
- output 𝑑𝑣 维输出值,连接起来再次进行投影,产生最终值,如图2.
多头注意力使得模型同时关注来自不同位置的、不同表示子空间的信息。对于单一注意力头,均值运算反而会抑制之。
在这项工作中,采用 ℎ=8 个并行注意力层或头(head)。每个头都采用 𝑑𝑘=𝑑𝑣=𝑑model/ℎ=64 。由于每个头的维度减少,总计算成本与全维度的单头注意力相似。
3.2.3 Applications of Attention in our Model
The Transformer uses multi-head attention in three different ways:
- 在“encoder-decoder attention”层中,queries 来自先前的解码器层,而 keys 和 values 来自编码器的输出。这使得解码器中的每个位置都可关联到输入序列中的所有位置。这是在模仿序列到序列(sequence-to-sequence, seq2seq)模型中典型的编码器-解码器注意机制,例如 [38,2,9]。
- 编码器包含了自注意力层。在自注意力层中,所有 keys、values 和 queries 都来自同一位置(在本例中是编码器中前一层的输出)。编码器中的每个位置可以关注到编码器上一层中的所有位置。
- 解码器中包含自注意力层,这使得解码器中的每个位置都关注到解码器之前的所有位置(并包括当前位置)。为了保持解码器的自回归特性,需要防止解码器中的信息向左流动。在缩放点积注意力的内部,我们通过屏蔽(设置为−∞)softmax 输入中所有非法连接对应的值,从而实现了这一点。见图 2。
3.3 Position-wise Feed-Forward Networks
除了注意力子层之外,我们编码器与解码器中的每个层中都包含一个全连接前馈网络,该网络单独且相同地应用于每个位置。其由两个线性变换组成,中间有一个 ReLU 激活。
![]()
虽然不同位置的线性变换是相同的,但它们在层与层之间采用不同的参数。另一种描述方式是两个核大小为 1 的卷积。输入和输出的维度为 𝑑model=512 ,内层的维度为 𝑑𝑓𝑓=2048 。
3.4 Embeddings and Softmax
使用learned embeddings将输入和输出 tokens 转换为维度 𝑑model 的向量。
使用常用的learned linear transformation and softmax function,将解码器输出转换为预测下一个 token 的概率。
在我们的模型中,两个嵌入层和 pre-softmax 线性变换之间共享相同的权重矩阵,类似于 [30]。在嵌入层中,将权重乘以 𝑑model 。
3.5 Positional Encoding
为了使模型能够利用序列的顺序信息,注入一些有关序列中 tokens 的相对或绝对位置的信息。
将“positional encodings”添加到编码器和解码器栈底部的输入嵌入中。位置编码与嵌入具有相同的 𝑑model 维度,因此可以将两者相加。
位置编码有多种选择,既可以学习得到,也可以将其固定 [9]。
在本工作中,我们使用不同频率的正弦和余弦函数:
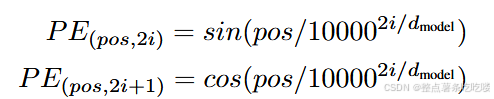
位置编码的每个维度都对应于一个正弦曲线。波长呈从 2𝜋 到 10000⋅2𝜋 的几何级数。之所以选择此函数,是因为我们假设它可以让模型很容易地关注相对位置进行学习,因为对于任何固定偏移 𝑘 , 𝑃𝐸𝑝𝑜𝑠+𝑘 可以表示为 𝑃𝐸𝑝𝑜𝑠 的线性函数。
4 Why Self-Attention
One is the total computational complexity per layer.
Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
The third is the path length between long-range dependencies in the network.
Learning long-range dependencies is a key challenge in many sequence transduction tasks. 有一个关键因素会对这种依赖性的学习能力产生影响:前向和后向信号在网络中必须经过的路径的长度。输入和输出序列中的任意位置组合之间的路径越短,学习长距离依赖关系就越容易 [12]。Hence we also compare the maximum path length between any two input and output positions in networks composed of the different layer types.
- 自注意力层将所有位置与常数个顺序执行操作相连,而循环层需要 𝑂(𝑛) 次顺序操作。
- 就计算复杂度而言,当序列长度 𝑛 小于表示维度 𝑑 时,自注意力层比循环层更快。
- 对于涉及很长序列的任务,为了提高计算性能,self-attention could be restricted,仅考虑输入序列中以相应输出位置为中心的大小为 𝑟 的邻域。这会将最大路径长度增加到 𝑂(𝑛/𝑟) 。

核宽度为 𝑘<𝑛 的单个卷积层不会连接所有输入和输出位置对。要实现这点,需要在卷积核连续(contiguous kernels)的情况下堆叠 𝑂(𝑛/𝑘) 个卷积层,或者在空洞卷积(dilated convolutions)[18] 的情况下需要 𝑂(𝑙𝑜𝑔𝑘(𝑛)) ,这增加了网络中任意两个位置之间的最长路径的长度。
卷积层通常比循环层开销贵 𝑘 倍。
然而,可分离卷积(Separable convolutions)[6] 大大降低了复杂性,可至 𝑂(𝑘⋅𝑛⋅𝑑+𝑛⋅𝑑2) 。然而,即使 𝑘=𝑛 ,可分离卷积的复杂性也等于自注意力层和逐点前馈层的组合,即我们模型采用的方法。
一个附加好处是,单个注意力头不仅可以清楚地学习并执行不同的任务,而且多个注意力头似乎表现出与句子的句法和语义结构相关的行为。
5 Training
5.3 Optimizer

5.4 Regularization正则化
We employ three types of regularization during training:

用下面的20道面试题看看自己是不是真的掌握了transformer这个模型。
详细答案在Transformer常见问题与回答总结 - Jack CC的文章 - 知乎
https://zhuanlan.zhihu.com/p/496012402
1.Transformer为何使用多头注意力机制?(为什么不使用一个头)
2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
5.在计算attention score的时候如何对padding做mask操作?
6.为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
7.大概讲一下Transformer的Encoder模块?
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
9.简单介绍一下Transformer的位置编码?有什么意义和优缺点?
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
11.简单讲一下Transformer中的残差结构以及意义。
12.为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
13.简答讲一下BatchNorm技术,以及它的优缺点。
14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点? 15.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
17.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
19.Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
20解码端的残差结构有没有把后续未被看见的mask信息添加进来,造成信息的泄露。
以下是针对每个问题的简短回答:
1. 为何使用多头注意力机制?
答:多头注意力允许模型同时关注不同子空间的上下文信息,增强模型捕捉多样化特征的能力,避免单头注意力可能导致的表达瓶颈。
2. Q和K为何使用不同权重矩阵?
答:若Q和K共享权重,点积会偏向自身位置,导致注意力分布偏向对角线,降低模型关注其他位置的能力。分离参数使模型能更灵活地学习不同方向的交互。
3. 点乘 vs 加法注意力
答:点乘计算更高效(复杂度 O(n2d)O(n2d)),且缩放点乘可防止梯度消失;加法注意力(复杂度 O(n2d2)O(n2d2))计算成本高,但可能更灵活。实践中点乘效果更好。
4. Softmax前为何缩放(除以dkdk)?
答:点积结果随维度dkdk增大而方差变大,导致Softmax后梯度趋近于0。缩放后稳定梯度,公式推导:
Softmax(QKTdk).Softmax(dkQKT).
5. Padding的Mask操作
答:在计算注意力分数后,将Padding位置的得分设为−∞−∞(实际中替换为极大负数如-1e9),Softmax后这些位置的权重接近0,避免无效位置影响。
6. 多头注意力的降维原因
答:每个头的维度降为dk=dmodel/hdk=dmodel/h,保持总计算量与单头一致(如8头时,每头64维,总维度仍为512)。
7. Encoder模块结构
答:每个Encoder层包含多头自注意力子层(残差+LayerNorm)和前馈网络子层(全连接+残差+LayerNorm),堆叠N次(如6层)。
8. 输入词向量乘以dembeddembed
答:平衡嵌入向量与位置编码的数值范围,防止嵌入值过小(因嵌入矩阵通常用较小的初始化,如均匀分布)。
9. 位置编码(Sinusoidal)
答:使用正弦/余弦函数生成位置编码,使模型感知位置信息。优点:泛化性强;缺点:无法学习位置间复杂关系,长度固定。
10. 其他位置编码技术
答:
-
可学习位置编码:灵活但需更多数据;
-
相对位置编码:捕捉相对距离,但实现复杂;
-
RoPE(旋转位置编码):结合绝对与相对位置,效果优。
11. 残差结构及意义
答:每个子层输出为x+Sublayer(x)x+Sublayer(x),缓解梯度消失,加速深层网络训练,保留原始信息。
12. LayerNorm vs BatchNorm
答:LayerNorm对单样本所有特征归一化,适合变长序列;BatchNorm依赖Batch统计量,不适用于序列任务。LayerNorm位于残差连接后。
13. BatchNorm优缺点
答:优点:加速训练、减少对初始化的敏感;缺点:依赖Batch大小,对变长序列和在线学习不友好。
14. 前馈神经网络(FFN)
答:FFN为两层全连接层,中间用ReLU/GELU激活,公式:
FFN(x)=ReLU(xW1+b1)W2+b2.FFN(x)=ReLU(xW1+b1)W2+b2.
优点:增强非线性;缺点:参数量大。
15. Encoder-Decoder交互
答:Decoder通过Cross-Attention(Q来自Decoder,K/V来自Encoder)获取Encoder输出,实现信息交互,类似Seq2Seq的注意力机制。
16. Decoder自注意力与Encoder的区别
答:Decoder自注意力使用下三角掩码(Masked Multi-Head Attention),禁止关注未来位置,保证自回归生成;Encoder无此限制。
17. 并行化体现与Decoder并行
答:
-
并行化:Encoder和Decoder的训练可并行计算所有位置的注意力;
-
Decoder推理:只能串行(因依赖前一位置输出),但训练时可并行(通过掩码)。
19. 学习率与Dropout设定
答:
-
学习率:使用Warmup策略(如线性增长到峰值后衰减);
-
Dropout:应用于嵌入、注意力分数、FFN中间层及残差连接后;测试时需关闭Dropout或调整权重(如乘以1−p1−p)。
20. Decoder残差结构是否泄漏信息
答:不会。残差连接仅累加当前层输出,而Mask已确保当前位置不依赖未来信息,因此无泄漏。

















 2728
2728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









