







目录
进行数据处理之后,我们得到了x_train和y_train,我们就可以用来进行回归或分类模型训练啦~
一、模型选择
我们这里可能使用的是回归模型(Regression),值得注意的是,回归和分类不分家。分类是预测离散值,回归是预测连续值,差不多。
我们需要注意,目标函数(损失函数)和在评估度量时的准确率,召回率等的区别。
目标函数是训练时,训练模型优劣的依据,即如果是损失函数,则训练时要求使得损失函数更小。而准确率和召回率是在测试集上测评模型的最终性能的。
展示这些是为了看到,不同的任务,可能需要不用的评分标准,评分时别乱套用。

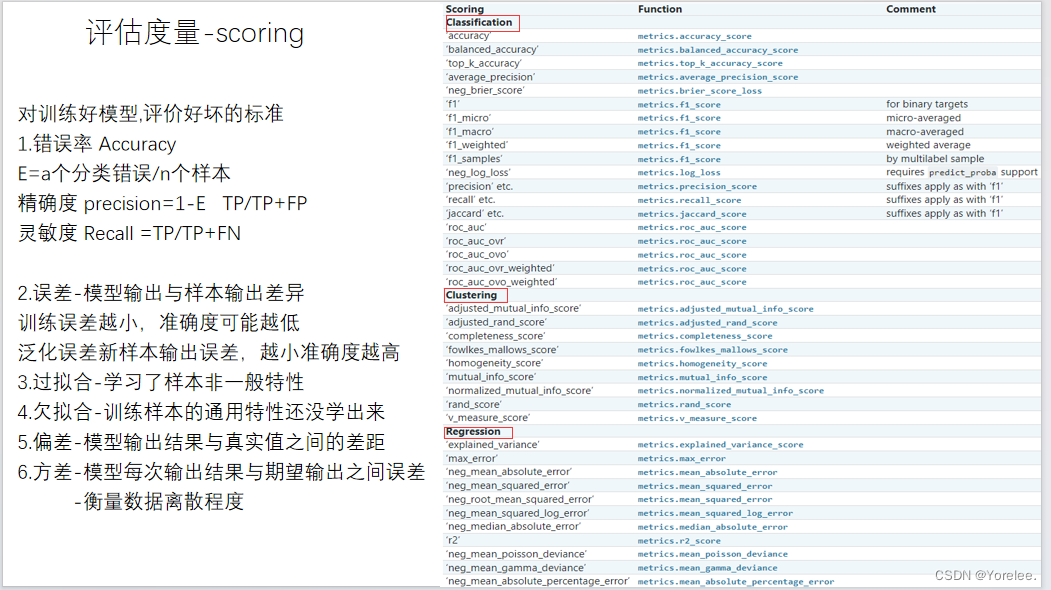
评估度量

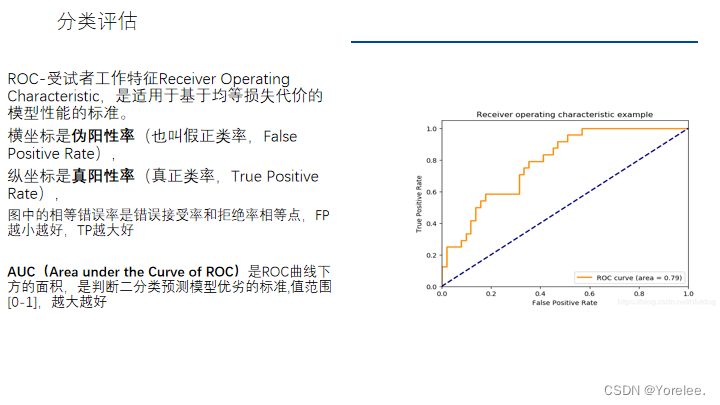
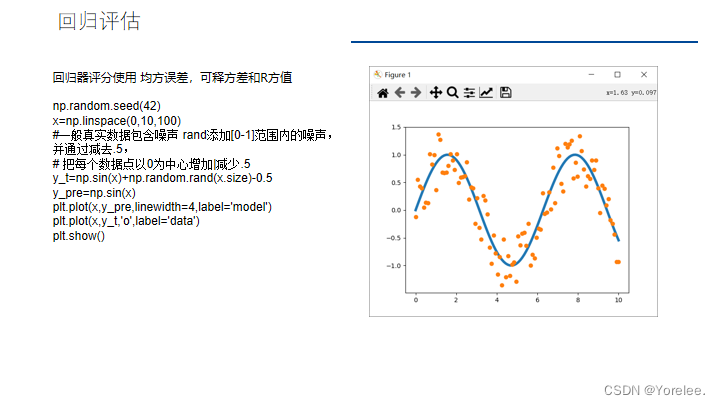
一、默认参数模型对比
一、无标准化
①K折交叉验证 模型评估
K折交叉验证 模型评估,不重复抽样将原始数据随机分为 k 份。每一次挑选其中 1 份作为训练集,剩余 k-1 份作为训练集用于模型训练。计算测试集上的得分。在这种情况下它只是用来计算模型得分的。
(这里说的测试集,严格上来讲属于整个机器学习过程中的验证集)
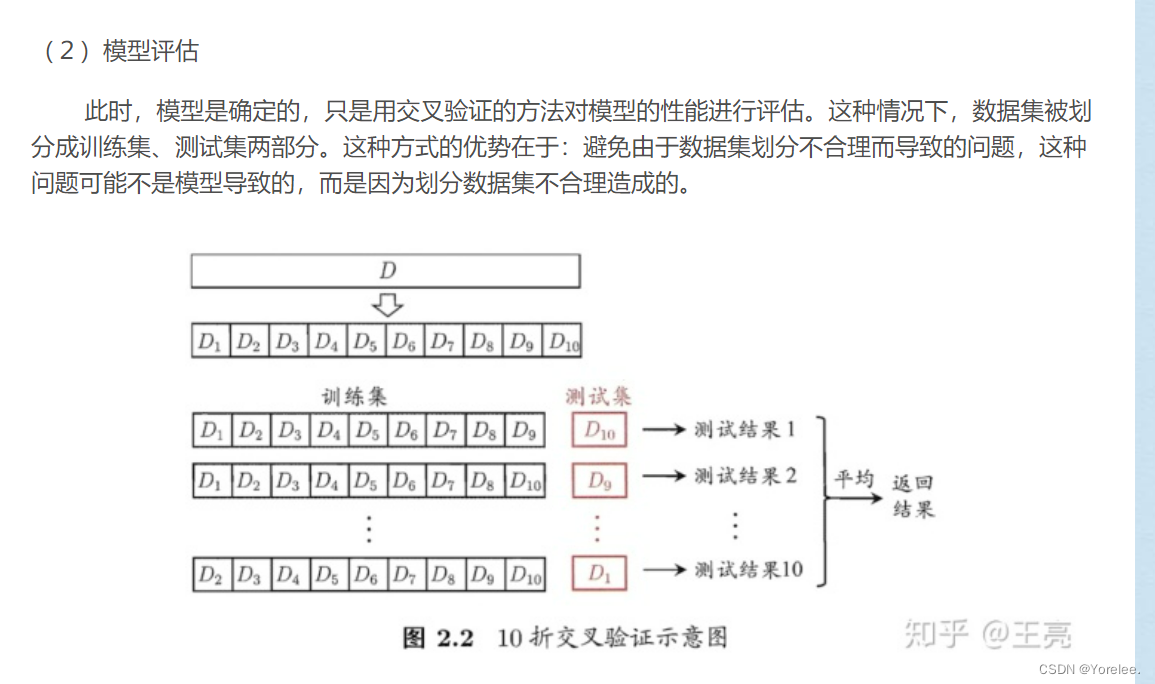
回归任务:
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error #MSE
from sklearn.model_selection import cross_val_score
models = {} #dict={k:v,k1:v1} list=[1,2,3,4] set=(1,2,3,4)
models['LR'] = LinearRegression()
models['LASSO'] = Lasso()
models['EN'] = ElasticNet()
models['KNN'] = KNeighborsRegressor()
models['CART'] = DecisionTreeRegressor()
models['SVM'] = SVR()
scoring='neg_mean_squared_error'
#回归模型,这里用均方误差得分作为模型的优化标准,模型会尽量使得该指标最好
#比较均方差
results=[]
for key in models:
cv_result=cross_val_score(models[key],x_train,y_train,cv=10,scoring=scoring)
#cv指定的是交叉验证的折数,k折交叉验证会将训练集分成k部分,然后每个部分计算一个分数。
results.append(cv_result) #list.append(t),这行语句的目的是为了以后画图用,但实际上print就能看到分数啦
print('%s: %f (%f)'%(key,cv_result.mean(),cv_result.std()))
#model = RandomForestClassifier(n_estimators= n_estimators)
#model.fit(X_train,y_train)
#mse = mean_squared_error(y_test,model.predict(X_test))分类任务:(XGB和LGB是集成模型)
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
models = {} #dict={k:v,k1:v1} list=[1,2,3,4] set=(1,2,3,4)
models['RFC'] = RandomForestClassifier()
models['XGB'] = XGBClassifier()
models['LGB'] = LGBMClassifier(verbose= -1)
scoring='roc_auc'
#使用AUC评估
#比较均方差
results=[]
for key in models:
cv_result=cross_val_score(models[key],x_train,y_train,cv=10,scoring=scoring)
#cv指定的是交叉验证的折数,k折交叉验证会将训练集分成k部分,然后每个部分计算一个分数。
print('%s: %f (%f)'%(key,cv_result.mean(),cv_result.std()))②先对模型进行训练,然后计算得分
分类问题:
from lightgbm import LGBMClassifier
model = LGBMClassifier(verbose= -1)
model.fit(X_train,y_train)
#具体算什么得分,就靠你自己选了
#model.score() 函数通常计算的是模型的准确度(accuracy)
print('LGBM的训练集得分:{}'.format(model.score(X_train,y_train)))
print('LGBM的测试集得分:{}'.format(model.score(X_test,y_test)))from sklearn.metrics import roc_auc_score
# 预测概率
y_train_proba = model.predict_proba(X_train)[:, 1]
y_test_proba = model.predict_proba(X_test)[:, 1]
# 计算训练集和测试集的AUC
train_auc = roc_auc_score(y_train, y_train_proba)
test_auc = roc_auc_score(y_test, y_test_proba)
print('LGBM的训练集AUC:{:.4f}'.format(train_auc))
print('LGBM的测试集AUC:{:.4f}'.format(test_auc))
回归问题:
model = RandomForestRegressor(n_estimators= n_estimators)
model.fit(X_train,y_train)
mse = mean_squared_error(y_test,model.predict(X_test))
print('RandomForest_Regressor的训练集得分:{}'.format(model.score(X_train,y_train)))
print('RandomForest_Regressor的测试集得分:{}'.format(model.score(X_test,y_test)))
print('RandomForest_Regressor的mse得分:{}'.format(model.score(X_test,y_test)))二、pipeline正态化再训练
Pipeline类似于一个管道,输入的数据会从管道起始位置输入,然后依次经过管道中的每一个部分最后输出。没啥区别其实()
from sklearn.pipeline import Pipeline
pipelines={}
pipelines['ScalerLR']=Pipeline([('Scaler',StandardScaler()),('LR',LinearRegression())])
pipelines['ScalerLASSO']=Pipeline([('Scaler',StandardScaler()),('LASSO',Lasso())])
pipelines['ScalerEN'] = Pipeline([('Scaler', StandardScaler()), ('EN', ElasticNet())])
pipelines['ScalerKNN'] = Pipeline([('Scaler', StandardScaler()), ('KNN', KNeighborsRegressor())])
pipelines['ScalerCART'] = Pipeline([('Scaler', StandardScaler()), ('CART', DecisionTreeRegressor())])
pipelines['ScalerSVM'] = Pipeline([('Scaler', StandardScaler()), ('SVM', SVR())])
#这个pipeline包含一个正态化~
scoring='neg_mean_squared_error'
results=[]
for key in pipelines:
kfold=KFold(n_splits=num_flods,random_state=feed)
cv_result=cross_val_score(pipelines[key],x_train,y_train,cv=kfold,scoring=scoring)
results.append(cv_result)
print('pipeline %s: %f (%f)'%(key,cv_result.mean(),cv_result.std()))二、集成模型
#调参外,提高模型准确度是使用集成算法。

import numpy as np
from sklearn.model_selection import KFold, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import AdaBoostRegressor, RandomForestRegressor, GradientBoostingRegressor, ExtraTreesRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
num_folds = 10
seed = 7
scoring = 'neg_mean_squared_error'
ensembles = {}
ensembles['ScaledAB'] = Pipeline([('Scaler', StandardScaler()), ('AB', AdaBoostRegressor())])
ensembles['ScaledAB-KNN'] = Pipeline([('Scaler', StandardScaler()),
('ABKNN', AdaBoostRegressor(base_estimator=KNeighborsRegressor(n_neighbors=3)))])
ensembles['ScaledAB-LR'] = Pipeline([('Scaler', StandardScaler()), ('ABLR', AdaBoostRegressor(LinearRegression()))])
ensembles['ScaledRFR'] = Pipeline([('Scaler', StandardScaler()), ('RFR', RandomForestRegressor())])
ensembles['ScaledETR'] = Pipeline([('Scaler', StandardScaler()), ('ETR', ExtraTreesRegressor())])
ensembles['ScaledGBR'] = Pipeline([('Scaler', StandardScaler()), ('RBR', GradientBoostingRegressor())])
results = []
for key in ensembles:
kfold = KFold(n_splits=num_flods, random_state=feed)
cv_result = cross_val_score(ensembles[key], x_train, y_train, cv=kfold, scoring=scoring)
results.append(cv_result)
print('%s: %f (%f)' % (key, cv_result.mean(), cv_result.std()))二、模型优化(网格搜索,随便写写)
使用GridSearchCV进行网格搜索
一、普通模型网格搜索——随机森林
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
param_grid= {'n_estimators':[1,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,125,150,200],
'max_features':('auto','sqrt','log2')}
#最佳迭代次数
#最大特征数
m = GridSearchCV(RandomForestRegressor(random_state=827),param_grid)
m = m.fit(X_train,y_train)
mse = mean_squared_error(y_test,m.predict(X_test))
print("该参数下得到的MSE值为:{}".format(mse))
print("该参数下得到的最佳得分为:{}".format(m.best_score_))
print("最佳参数为:{}".format(m.best_params_))二、集成模型网格搜索——XGB
%%time
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
# xgb 网格搜索,参数调优
# c初始参数
params = {'learning_rate': 0.1, 'n_estimators': 500, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
XGB_Regressor_Then_params = {
'learning_rate': 0.1, 'n_estimators': 200, 'max_depth': 6, 'min_child_weight': 9, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0.3, 'reg_alpha': 0, 'reg_lambda': 1}
# 最佳迭代次数:n_estimators、min_child_weight 、最大深度 max_depth、后剪枝参数 gamma、样本采样subsample 、 列采样colsample_bytree
# L1正则项参数reg_alpha 、 L2正则项参数reg_lambda、学习率learning_rate
param_grid= {'n_estimators':[50,100,150,200,250,300,350,400,450,500,550,600,650,700,750,800,850,900,950,1000,1250,1500,1750,2000],}
m = GridSearchCV(XGBClassifier(objective ='reg:squarederror',**params),param_grid,scoring='roc_auc')
m = m.fit(X_train,y_train)
mse = mean_squared_error(y_test, m.predict(X_test))
print('该参数下得到的最佳AUC为:{}'.format(m.best_score_))
print('最佳参数为:{}'.format(m.best_params_))
print('XGB的AUC图:')
lr_fpr, lr_tpr, lr_thresholds = roc_curve(y_test,m.predict_proba(X_test)[:,1])
lr_roc_auc = metrics.auc(lr_fpr, lr_tpr)
plt.figure(figsize=(8, 5))
plt.plot([0, 1], [0, 1],'--', color='r')
plt.plot(lr_fpr, lr_tpr, label='XGB(area = %0.2f)' % lr_roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.show()














 4453
4453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











