







目录
1.缺失值的检测与处理
1.1缺失值的检测与统计
(1)通过isnull()函数可以直接判断某列中的哪个数据为缺失值。
import numpy as np
import pandas as pd
string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
print(string_data)
string_data.isnull()
#-----------------------------------------------------------------
0 aardvark
1 artichoke
2 NaN
3 avocado
0 False
1 False
2 True
3 False(2)使用isnull().sun()统计缺失值。
df = pd.DataFrame(np.arange(12).reshape(3,4),columns = ['A','B','C','D'])
df.iloc[2,:] = np.nan
df[3] = np.nan
print(df)
df.isnull().sum()
#-----------------------------------------------------------------------
A B C D 3
0 0.0 1.0 2.0 3.0 NaN
1 4.0 5.0 6.0 7.0 NaN
2 NaN NaN NaN NaN NaN
A 1
B 1
C 1
D 1
3 3(3)使用info方法查看DataFrame的缺失值。
df.info()
#-------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 5 columns):
A 2 non-null float64
B 2 non-null float64
C 2 non-null float64
D 2 non-null float64
3 0 non-null float64
dtypes: float64(5)
memory usage: 248.0 bytes1.2缺失值的处理
1.2.1删除缺失值
通过dropna方法可以删除具有缺失值的行
from numpy import nan as NA
data = pd.DataFrame([[1., 5.5, 3.], [1., NA, NA],[NA, NA, NA],
[NA, 5.5, 3.]])
print(data)
cleaned = data.dropna()
print('删除缺失值后的:\n',cleaned)
#-------------------------------------
0 1 2
0 1.0 5.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 5.5 3.0
删除缺失值后的:
0 1 2
0 1.0 5.5 3.0使用thresh参数,当传入thresh=N时,表示要求一行至少具有N个非NaN才能存在。
df = pd.DataFrame(np.random.randn(7, 3))
df.iloc[:4, 1] = NA
df.iloc[:2, 2] = NA
print(df)
df.dropna(thresh=2)
#----------------------------------------
0 1 2
0 -0.506363 NaN NaN
1 0.109888 NaN NaN
2 -1.102190 NaN 0.399151
3 0.757800 NaN 1.170835
4 0.350187 -0.315094 -2.319175
5 0.056101 0.256769 0.438723
6 -0.128135 -0.141123 -0.945234
0 1 2
2 -1.102190 NaN 0.399151
3 0.757800 NaN 1.170835
4 0.350187 -0.315094 -2.319175
5 0.056101 0.256769 0.438723
6 -0.128135 -0.141123 -0.9452341.2.2填充缺失值
有时候直接删除缺失值并不是一个很好的方法,因此可以使用特定的值来对缺失值进行填充。pandas中替换缺失值的方法是fillna。
用插值方法填充
df = pd.DataFrame(np.random.randn(6, 3))
df.iloc[2:, 1] = NA
df.iloc[4:, 2] = NA
print(df)
df.fillna(method = 'ffill')
#-------------------------------------
0 1 2
0 0.756464 0.443256 -0.658759
1 0.919615 0.492780 0.993361
2 1.362813 NaN -0.515228
3 -1.114843 NaN -0.622650
4 0.496363 NaN NaN
5 0.647327 NaN NaN
0 1 2
0 0.756464 0.443256 -0.658759
1 0.919615 0.492780 0.993361
2 1.362813 0.492780 -0.515228
3 -1.114843 0.492780 -0.622650
4 0.496363 0.492780 -0.622650
5 0.647327 0.492780 -0.622650用均值填充
df = pd.DataFrame(np.random.randn(4, 3))
df.iloc[2:, 1] = NA
df.iloc[3:, 2] = NA
print(df)
df[1] = df[1].fillna(df[1].mean())
print(df)
#--------------------------------------------
0 1 2
0 0.209804 -0.308095 1.773856
1 -1.021306 2.082047 -0.396020
2 0.835592 NaN -1.363282
3 -1.253210 NaN NaN
0 1 2
0 0.209804 -0.308095 1.773856
1 -1.021306 2.082047 -0.396020
2 0.835592 0.886976 -1.363282
3 -1.253210 0.886976 NaN2.重复值的检测与处理
使用duplicates方法判断各行是否有重复值
data = pd.DataFrame({ 'k1':['one','two'] * 3 + ['two'],'k2':[1, 1, 2, 3, 1, 4, 4] ,'k3':[1,1,5,2,1, 4, 4] })
print(data)
data.duplicated()
#-------------------------------
k1 k2 k3
0 one 1 1
1 two 1 1
2 one 2 5
3 two 3 2
4 one 1 1
5 two 4 4
6 two 4 4
0 False
1 False
2 False
3 False
4 True
5 False
6 True使用drop_duplicates删除重复的行
data.drop_duplicates()#每行各个字段都相同时去重
data.drop_duplicates(['k2','k3'])#指定部分列重复时去重
#--------------------------------------------------------
k1 k2 k3
0 one 1 1
1 two 1 1
2 one 2 5
3 two 3 2
5 two 4 4
k1 k2 k3
0 one 1 1
2 one 2 5
3 two 3 2
5 two 4 43.异常值检测与处理
异常值是指数据中存在的个别数值明显偏离其余数据的值。在数据统计方法中一般常用散点图,箱线图,3法则检测异常值。
3.1散点图方法
通过数据分布的散点图发现异常值。
import matplotlib.pyplot as plot
wdf = pd.DataFrame(np.arange(20),columns = ['W'])
wdf['Y'] = wdf['W']*1.5+2
wdf.iloc[3,1] = 128
wdf.iloc[18,1] = 150
wdf.plot(kind = 'scatter',x = 'W',y = 'Y
3.2箱线图分析
箱线图使用最小值、下四分位数Q1、中位数Q2、上四分位数Q3、和最大值来描述数据。最大值和最小值分别为与四分位数值间距为1.5个IQR(IQR=Q3-Q1)的值。即min=Q1-1.5IQR,max=Q3+1.5IQR ,小于min和大于max 的值被认为是异常值。
import matplotlib.pyplot as plt
plt.boxplot(wdf['Y'].values,notch = True)

3.3 3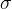 法则
法则
若数据服从正态分布,则在 3原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值,因为在正态分布的假设下,距离平均值 3
之外的值出现的概率小于0.003,因此可以认为超出 3
之外的值为异常数据。















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











