







引言:
在正文开始之前,首先给大家介绍一个不错的人工智能学习教程:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。
1. 算法介绍
朴素贝叶斯是一种基于贝叶斯定理的分类算法,广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。它是一种简单但非常有效的分类方法,特别适用于高维度特征空间的分类问题。
朴素贝叶斯分类器的"朴素"来源于它对特征之间独立性的假设。尽管这个假设在现实中往往不成立,但该算法在许多实际应用中仍然表现出色。
2. 算法原理
朴素贝叶斯分类器基于贝叶斯定理:
P ( A ∣ B ) = P ( B ∣ A ) ∗ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) * P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)∗P(A)
在分类问题中,我们关心的是给定特征 X X X,类别 Y Y Y的后验概率 P ( Y ∣ X ) P(Y|X) P(Y∣X):
P ( Y ∣ X ) = P ( X ∣ Y ) ∗ P ( Y ) P ( X ) P(Y|X) = \frac{P(X|Y) * P(Y)}{P(X)} P(Y∣X)=P(X)P(X∣Y)∗P(Y)
由于朴素贝叶斯假设特征之间相互独立,因此:
P ( X ∣ Y ) = P ( X 1 ∣ Y ) ∗ P ( X 2 ∣ Y ) ∗ . . . ∗ P ( X n ∣ Y ) P(X|Y) = P(X_1|Y) * P(X_2|Y) * ... * P(X_n|Y) P(X∣Y)=P(X1∣Y)∗P(X2∣Y)∗...∗P(Xn∣Y)
分类时,我们选择使 P ( Y ∣ X ) P(Y|X) P(Y∣X)最大的类别 Y Y Y作为预测结果。
3. 案例分析
我们使用著名的鸢尾花(Iris)数据集来演示朴素贝叶斯分类器的应用。
首先建立朴素贝叶斯分类模型训练数据进行分类并打印分类结果:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, classification_report
from sklearn.decomposition import PCA
# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建并训练模型
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# 预测
y_pred = gnb.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
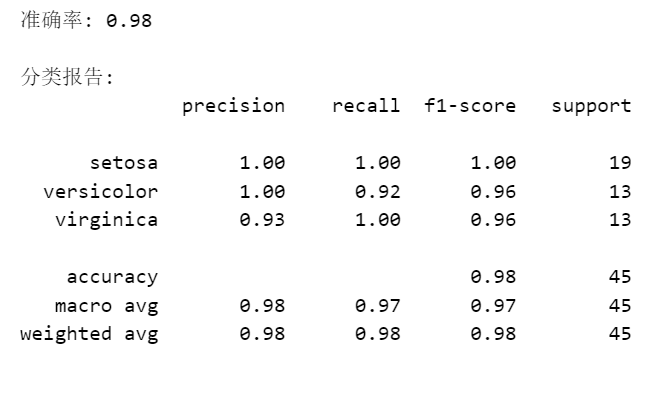
print(f"准确率: {accuracy:.2f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
打印出模型的准确率和分类报告如下:
接下来对分类结果进行可视化:
# 可视化
# 使用PCA降维到2D
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 绘制散点图
plt.figure(figsize=(10, 8))
colors = ['red', 'green', 'blue']
for i, c in zip(range(3), colors):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], c=c, label=iris.target_names[i])
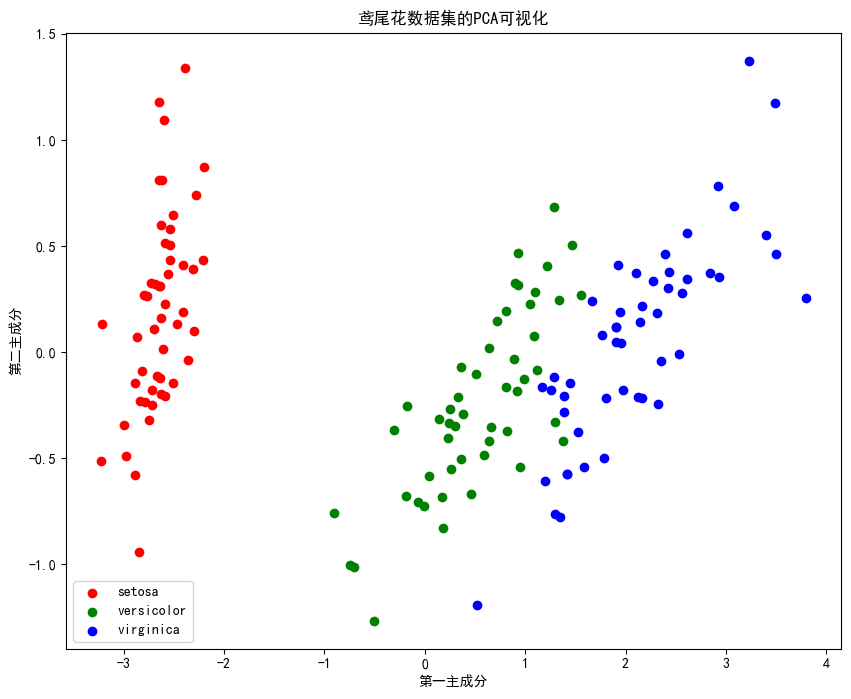
plt.title('鸢尾花数据集的PCA可视化')
plt.xlabel('第一主成分')
plt.ylabel('第二主成分')
plt.legend()
plt.show()
# 绘制决策边界
x_min, x_max = X_pca[:, 0].min() - 0.5, X_pca[:, 0].max() + 0.5
y_min, y_max = X_pca[:, 1].min() - 0.5, X_pca[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = gnb.predict(pca.inverse_transform(np.c_[xx.ravel(), yy.ravel()]))
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdYlBu)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap=plt.cm.RdYlBu, edgecolor='black')
plt.title('朴素贝叶斯分类器的决策边界')
plt.xlabel('第一主成分')
plt.ylabel('第二主成分')
plt.show()
绘制数据降维后的数据散点图:
绘制朴素贝叶斯分类结果图:
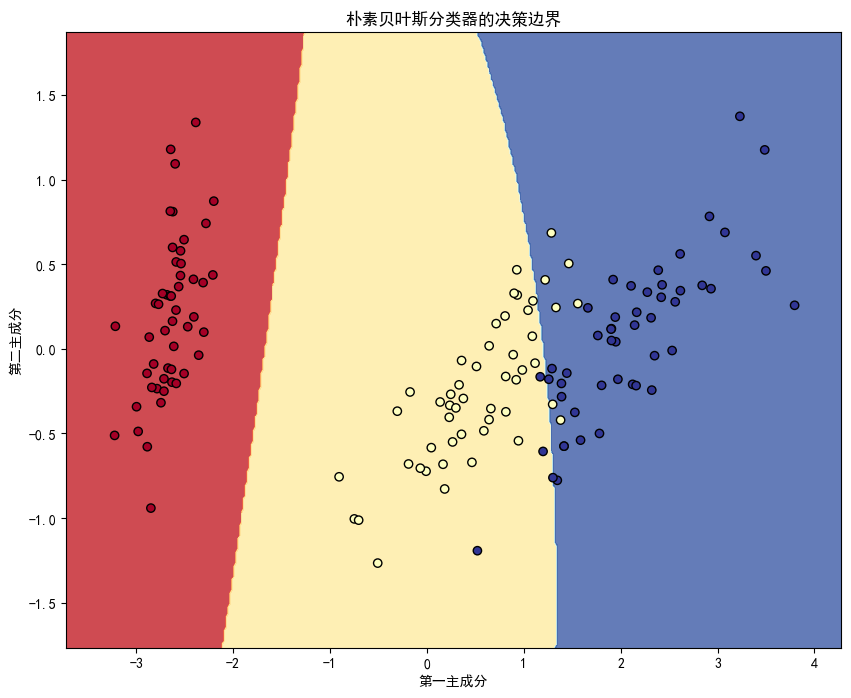
在这个例子中,我们使用了高斯朴素贝叶斯分类器(GaussianNB),它假设特征的条件概率分布服从高斯分布。模型在测试集上达到了98%的准确率,表现相当不错。
4. 总结
朴素贝叶斯分类器的优点包括:
- 简单,易于实现
- 训练速度快
- 对小规模数据表现良好
- 对高维数据有很好的分类性能
然而,它也有一些局限性:
- 特征独立性假设在实际中往往不成立
- 对数值型特征的处理不如某些其他算法
总的来说,朴素贝叶斯是一种简单而强大的分类算法,特别适用于文本分类等高维度特征空间的问题。在实际应用中,它常常作为基准模型或快速原型开发的首选算法。
















 2410
2410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











