






一、建议实验平台
操作系统:Ubuntu18.04(或Ubuntu16.04)。
Hadoop版本:3.1.3。
Hive版本:3.1.2。
JDK版本:1.8。
HBase版本:2.2。
建议使用的其他相关组件和工具: Kettle和IDEA编程工具,注意组件版本之间的兼容性,不建议用Sqoop,因为其不支持新版的Hadoop和Hive。
二、实验内容
本综合实验考查题目是论坛日志分析,主要涉及的技术有大数据处理架构Hadoop的关键技术及其基本原理、分布式数据库系统概念及其原理、关系型数据库概念与原理、Hive数据库的原理等;本实验考查综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。
(一)实验背景介绍
采集用户上网的操作日志信息,包括登录时间、用户编号、IP地址、登录区域等信息,使用爬虫的技术,爬取网易的访问日志数据,统计网页的浏览量,访问的用户数,访问的IP数量,跳出用户数等业务指标。
本次要实践的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖、回帖、评论等信息,如图所示:
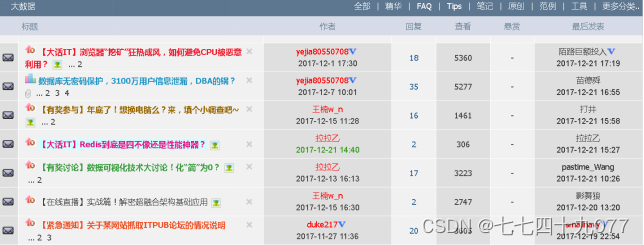
图1-1
(二)实验数据说明
本实验包含了一个大规模数据集log_2021-05-01.txt和一个小数据集example_data.log(只包含10条记录)等。小数据集example_data.log是从大规模数据集log_2021-05-01.txt中抽取的一小部分数据。实验数据集和相关参考文档请参考附件。日志的例子数据example_data.log,一共是10条数据,作为测试使用(访问者IP、访问时间、访问资源、访问状态(HTTP状态码)、本次访问流量(Byte))
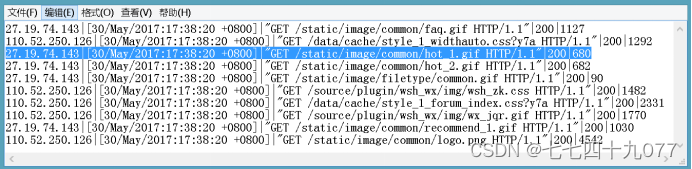
图1-2 日志记录数据格式
备注:数据是用”|”隔开
日志的真实数据log_2021-05-01.txt,作为正式环境使用。

(三)实验项目架构
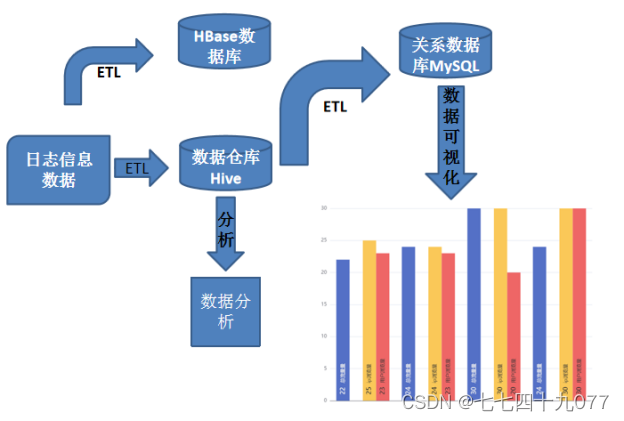
(四)实验内容分解
论坛日志分析综合实验项目完成需要以下8个步骤:
第1步:本地数据集上传到HDFS
第2步:使用MapReduce进行数据清洗
第3步:在Linux上执行MR数据清洗
第4步:使用Hive访问HDFS的例子数据
第5步:使用Hive访问HDFS的真实数据
第6步:使用Kettle把数据存储到HBase
第7步:使用sqoop把Hive数据导出到mysql
第8步:使用EChart进行可视化
三、实验要求
1.实验完成度。 按要求独立完成实验准备、程序调试、实验报告撰写。
2.实验内容。代码功能完善、可正常运行,测试数据正确,分析正确,结论正确。
3.实验报告。内容齐全,步骤详细,符合要求。
4.总结。对实验过程遇到的问题能初步独立分析,解决后能总结问题原因及解决方法,有心得体会。
四、实验过程、内容
论坛日志分析综合实验项目完成需要以下8个步骤:
第1步:本地数据集上传到HDFS
进入 Hadoop 安装目录,启动 hadoop
![]()
新建HDFS目录input_log(若input_log存在,则先删除)
![]()
上传本地的真实数据文件到HDFS目录
hadoop fs -put ~/下载/数据/log_2021-05-01.txt /input_log
![]()
上传本地的真实数据文件到HDFS目录

查看input_log目录,确认数据文件存在

第2步:使用MapReduce进行数据清洗
步骤01 新建Maven工程。打开IntellijIDEA工具,选择new → Project → Maven,单击Next按钮。
步骤02 设置工程名称为BBS_log,输入GroupId、ArtifactId,单击Finish按钮。
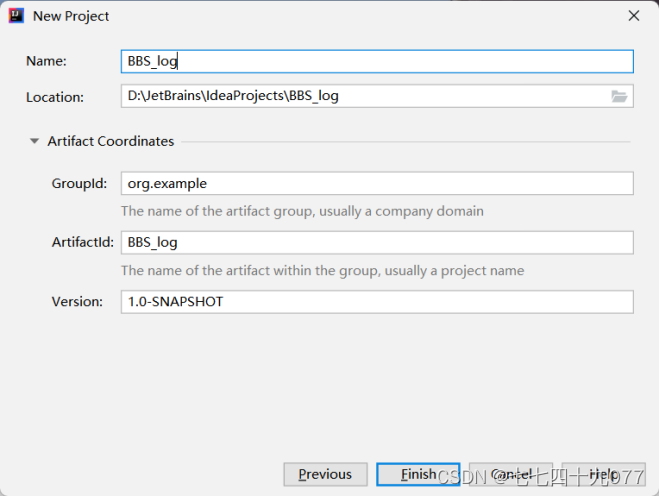
步骤03 设置文件属性。进入项目BBS_log目录中,删除test文件夹,修改main文件夹的名字为BBS_log,再进入File→Project Structure→Modules,修改文件夹src属性为resources。
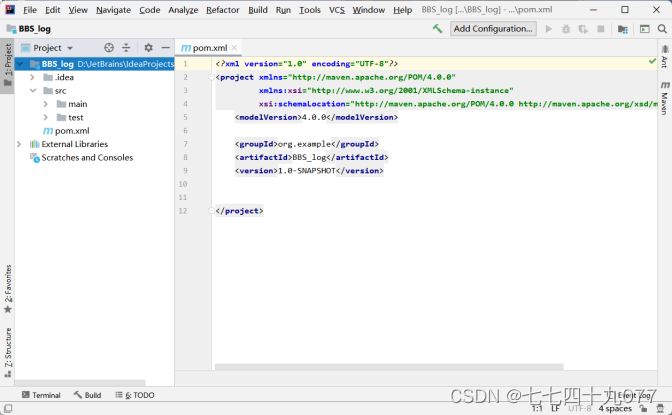
结果如下图:
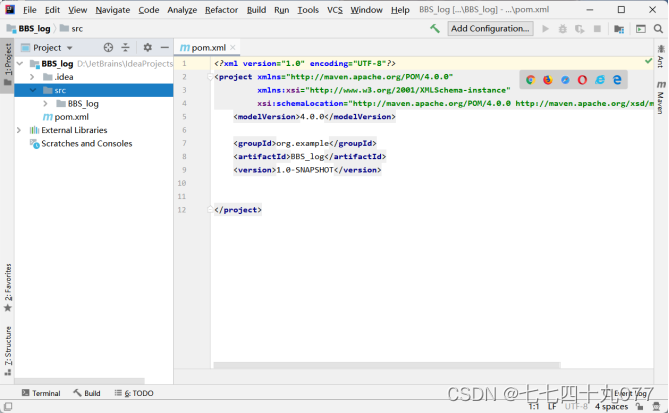
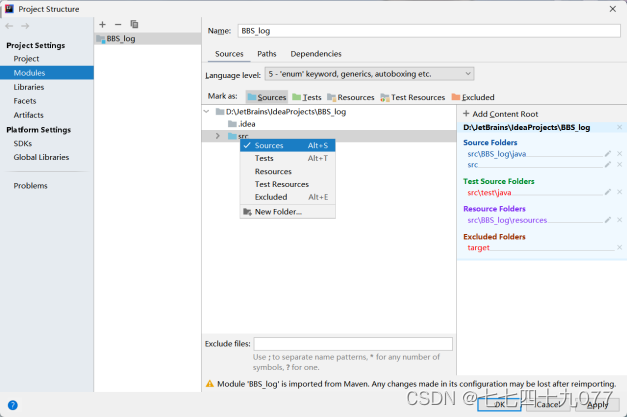
步骤04 编写Java代码。在src下新建Java程序(执行new→Java class),编写 数据清洗的Java代码LogClean.java。
结果如下图:
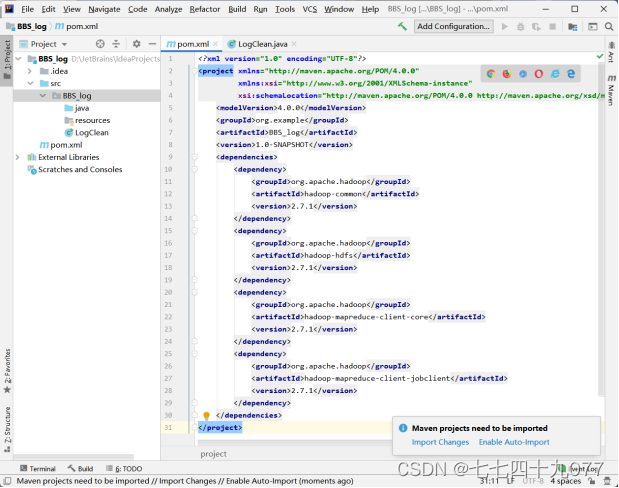
步骤05 修改pom.xml文件,并执行Import Changes,把对应的组件下载到项目工程内。
步骤06 添加Artifact包。进入File→Project Structure→Artifacts,找到对应的Main的Class文件,把不要的包remove掉。
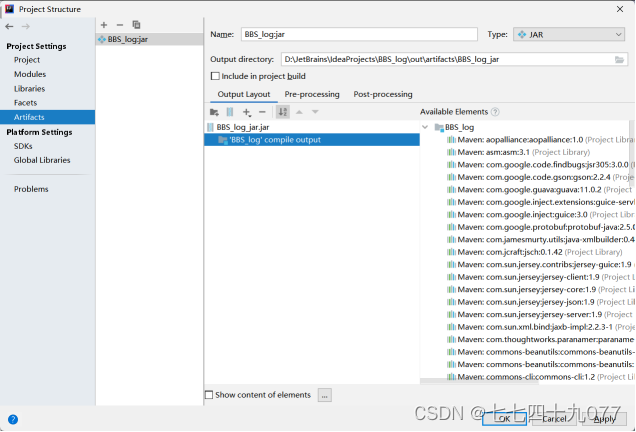
结果如下:
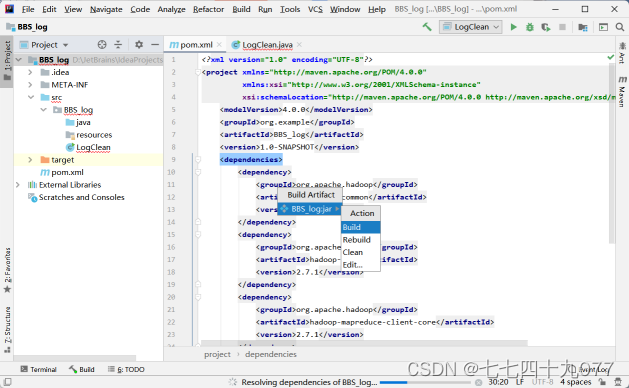
步骤07 生成Artifact包。单击Build→Build Artifact→BBS_log:jar→Build,表示生成指定的jar包文件。
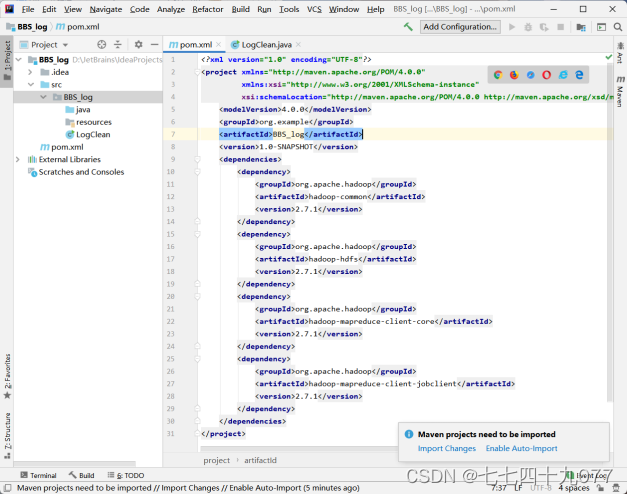
结果如下:
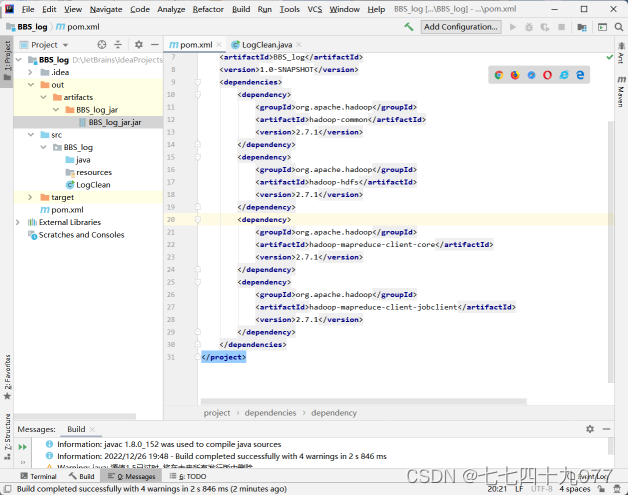
第3步:在Linux上执行MR数据清洗
步骤01 使用SFTP工具上传文件,在“文件→管理器→新站点”中输入IP地址等信息,单击连接按钮,传输jar包到ubuntu的目录下。
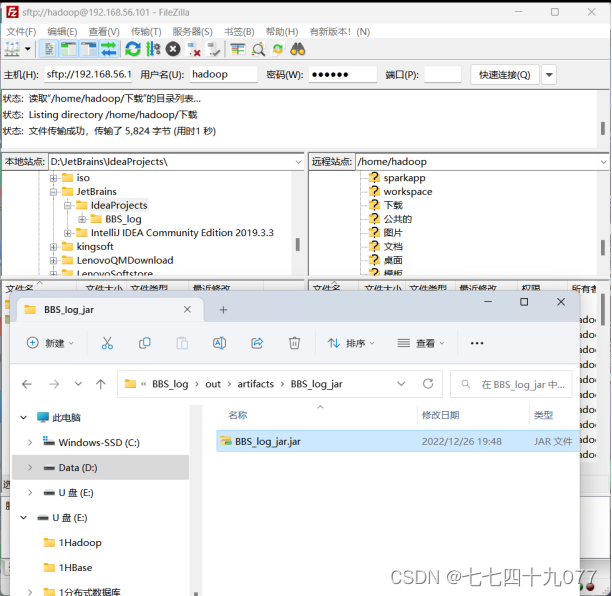
结果如下:
![]()
步骤02 进入到远程环境,使用XShell工具,进入到Hadoop开发环境,确保HDFS 是正常状态。

步骤03 执行MR程序,确保Hadoop是正常状态后,执行下面命令。
(1)创建HDFS目录/BBS_log/cleaned。

(2)执行MR程序
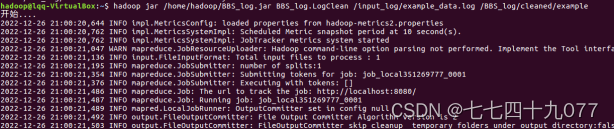
(3)运行结果
![]()

第4步:使用Hive访问HDFS的例子数据
步骤说明:此步骤是用example数据把整个流程跑通,以便进行真实的数据处理。
步骤01 建立一张Hive表,将HDFS目录inout_log中的数据存入Hive。
(1)进入 Hadoop 目录,启动 Hadoop。
![]()
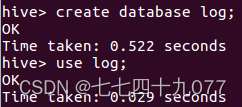
(2)切换到 Hive 目录下,启动 MySQL 和 Hive。

(3)创建并使用Hive数据库log。
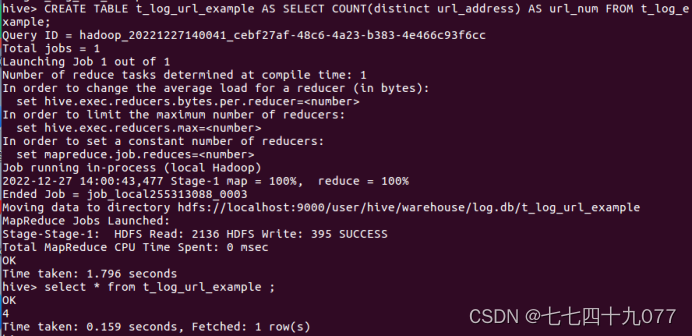
(4)创建表t_log_example,指定HDFS数据存放路径。

步骤02 使用hive的统计语言,统计URL浏览数量,简称URL_NUM。统计访问url的数量
步骤03 使用hive的统计语言,统计用户对网页浏览量PageViews,简称PV。PV指的是所有用户浏览页面的总和,1个用户每次打开1个页面就会被记录1次。运行的hive脚本如下:
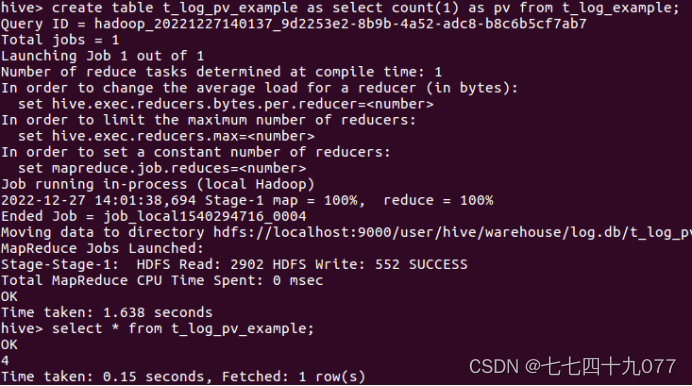
步骤4:使用hive统计语言,注册用户数RegisteredUsers,简称RU。表示用户访问注册的页面的个数。脚本如下:
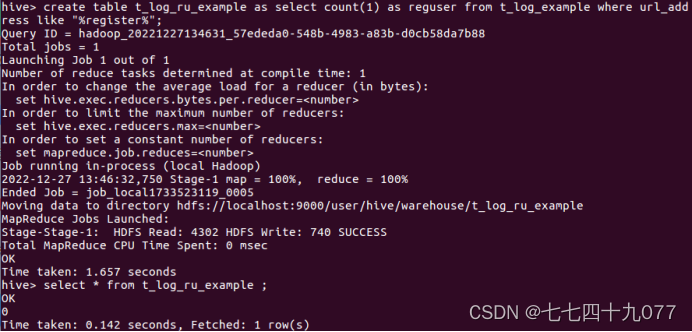
步骤5:使用Hive统计语言,统计访问的IP数量。IP数量表示某个时间段,访问页面的不同的IP 个数的总和。其中同1个IP无论访问几个页面,独立IP 数均算作1个。所以,只需要统计日志中处理的不同的IP个数,执行的hive命令如下:
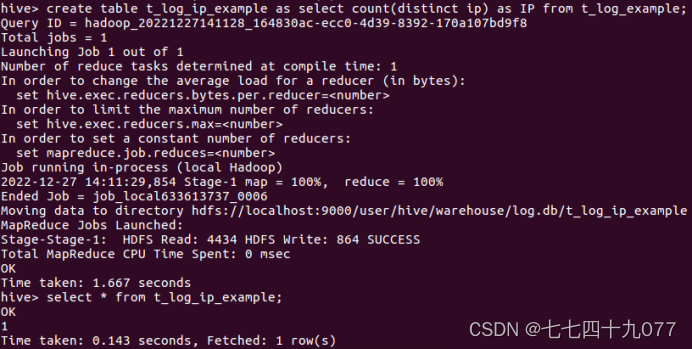
步骤6:将所有的统计指标存放到1张汇总的表里里面。借助1张汇总表将统计到的结果整合起来,Hive的脚本如下:


第5步:使用Hive访问HDFS的真实数据
步骤1:建立1张hive表,需要将数据存入HIVE里面,新建一张表。
(1)创建表t_log,指定HDFS数据存放路径。

(2)查看表数据。
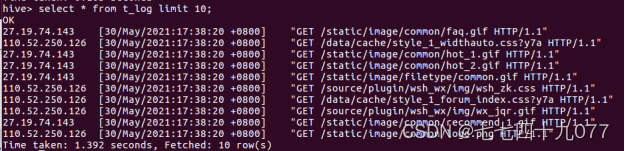
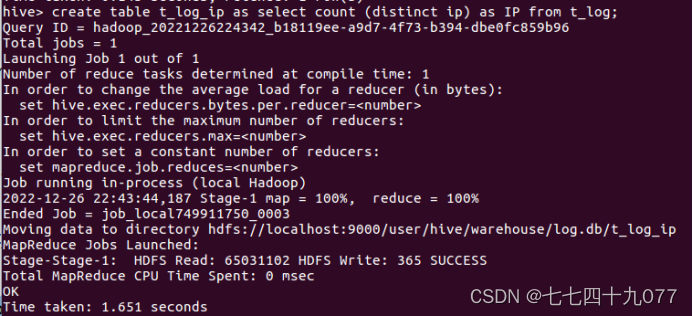
步骤2:使用hive的统计语言,统计URL浏览数量,简称URL_NUM。统计访问url的数量,Hive的代码如下:
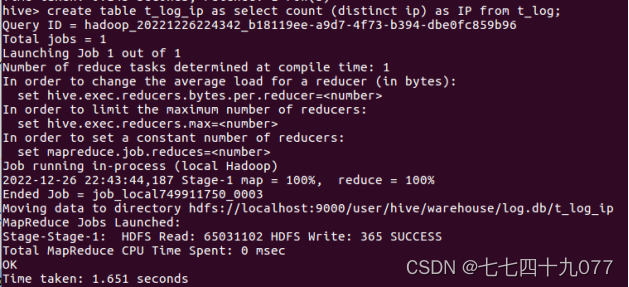
步骤3:使用hive的统计语言,统计用户对网页浏览量PageViews,简称PV。PV指的是所有用户浏览页面的总和,1个用户每次打开1个页面就会被记录1次。运行的hive脚本如下:
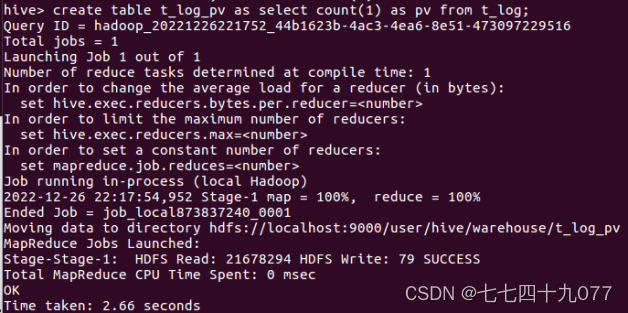

步骤4:使用hive统计语言,注册用户数RegisteredUsers,简称RU。表示用户访 问注册的页面的个数。脚本如下:
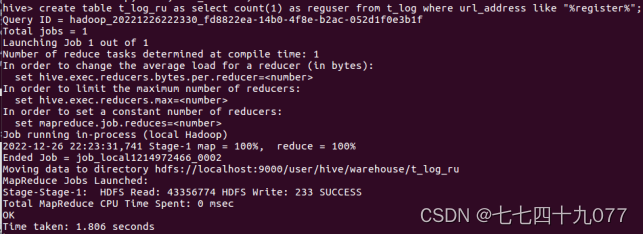

步骤5:使用Hive统计语言,统计访问的IP数量。IP数量表示某个时间段,访问页面的不同的IP 个数的总和。其中同1个IP无论访问几个页面,独立IP 数均算作1个。所以,只需要统计日志中处理的不同的IP个数,执行的hive命令如下:

步骤6:将所有的统计指标存放到1张汇总的表里里面。借助1张汇总表将统计到的结果整合起来,Hive的脚本如下
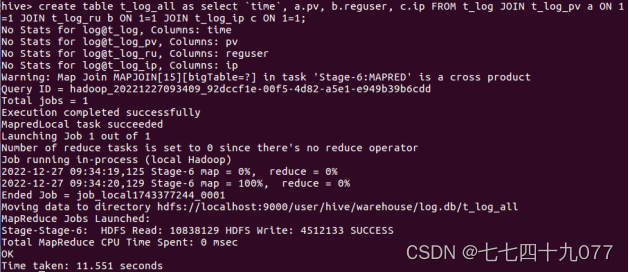
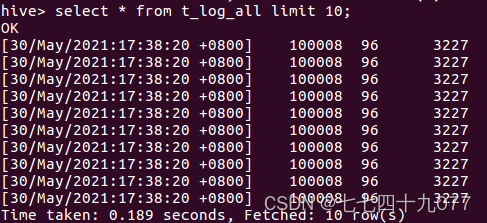
第6步:使用Kettle把数据存储到HBase
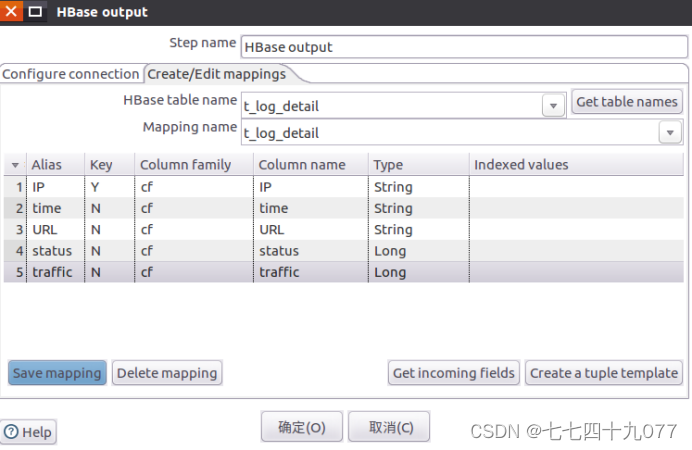
步骤1 进入Hbase Shell 创建t_log_detail表,并设置CF列族,执行的命令如下:

步骤2:打开kettle这个ETL数据处理工具,新建1个空白的转换,如图1-23所示。kettle是由转换和作业组成,转换表示实际数据处理的过程,比如数据过滤、数据组合、增加、修改等功能;作业大部分是为了定时调度转换的所用。
![]()
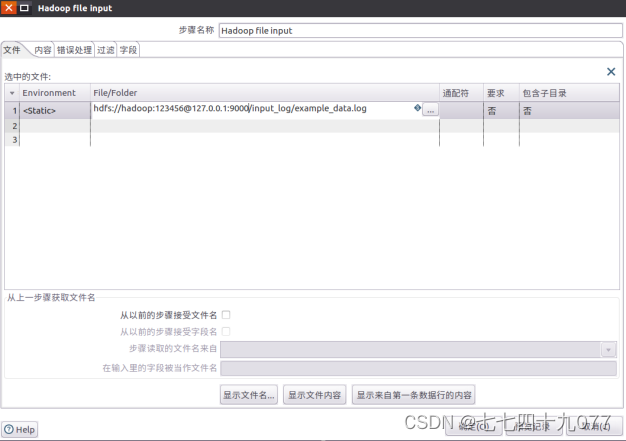
步骤3:从“Big Data”菜单里面拉1个“Hadoop File Input”组件到设计区域,并进行编辑,各个属性的设置。
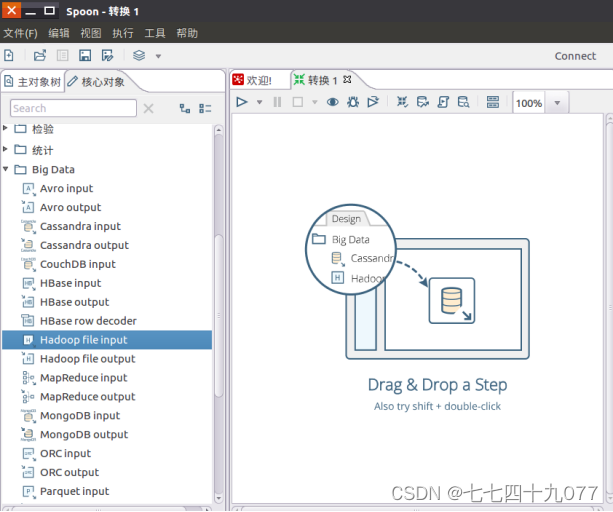
文件输入设置内容如下:
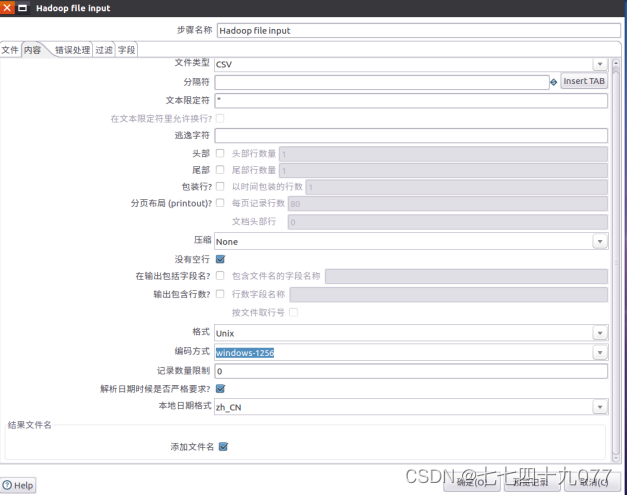
步骤4:从“Big Data”菜单里面拉一个“Hbase Output”组件到设计区域里面,再进行属性设置。
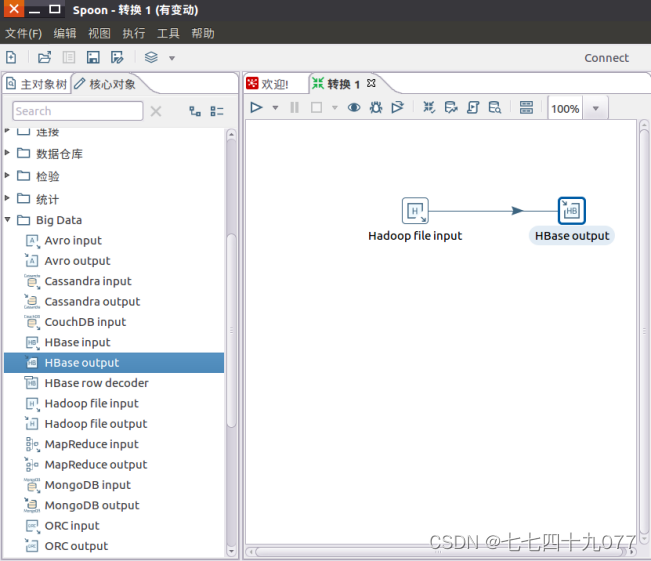
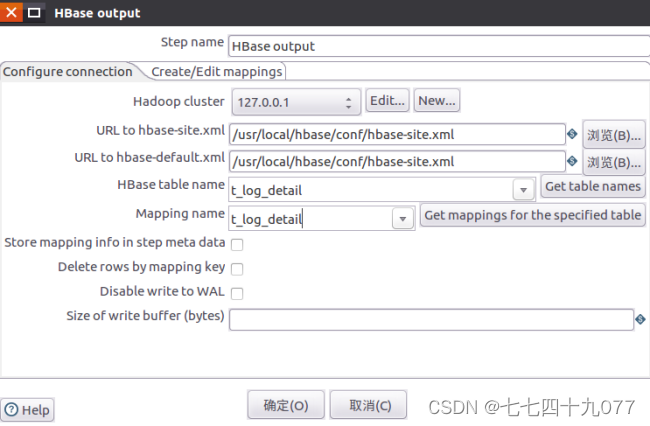
Hadoop集群配置:
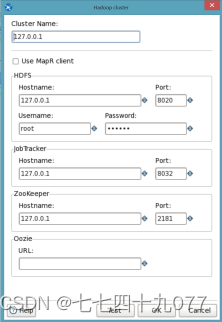
映射配置:
步骤5:点击运行的案例,点击“”,运行此转换.
步骤6:查看运行结果。

步骤7:查看结果数据是否是正确的,运行下面的命令.
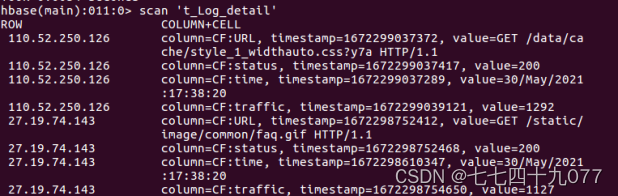
第8步:使用sqoop把Hive数据导出到mysql
步骤1 登录到MySQL数据库的命令界面。
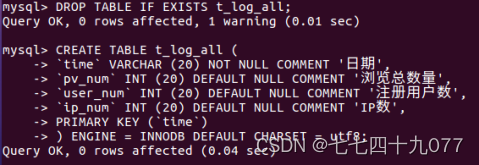
步骤2:创建1张数据汇总表,执行命令。
步骤3:把用hive产生的表,导出到mysql里面,导出的执行脚本如下。(这里的--export-dir是指定的hive目录下的表所在位置)
![]()
步骤4 查看到运行结果后的数据。
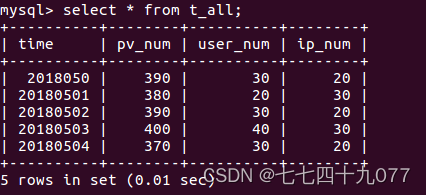
任务七:使用ECharts实现可视化
步骤1 使用IDEA工具新建1个Maven工程。
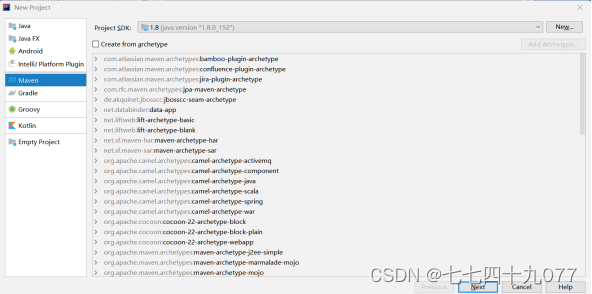
步骤2 新建一个application.yml文件,并写入代码。
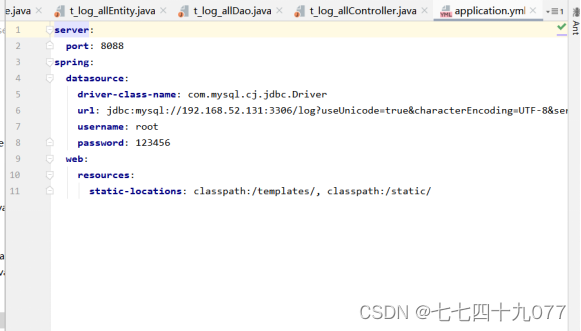
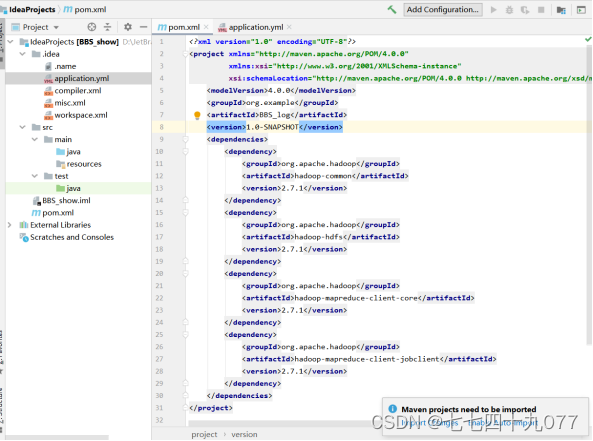
步骤3 修改pom.xml文件,写入代码后,单击Maven→Download Sources。
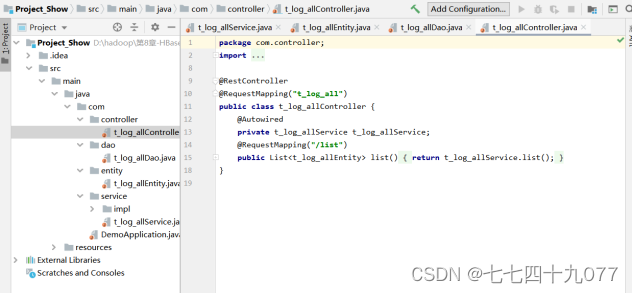
步骤4 新建几个程序包,并分别编写controller、dao、entity、service等层的程序。
步骤5 新建一个index.html,在/resources/static/js目录下增加二charts。Js和jquery-3.5.1.min.js的包。
步骤6 右击启动代码。
步骤7 输入http://localhost:8080/t_log_all/list后台服务器

步骤8 打开index.html查看可视化界面。
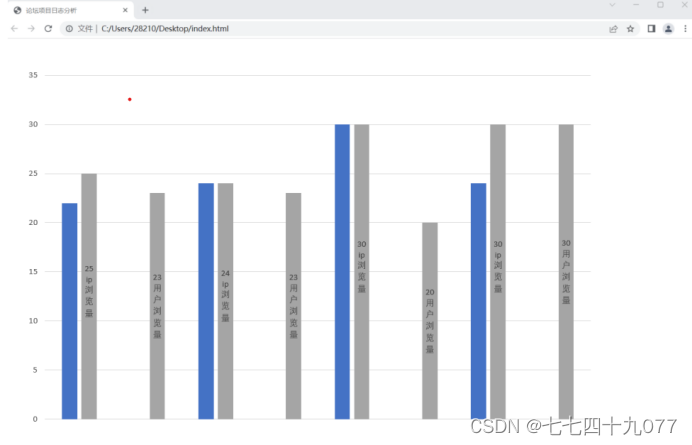
五、实验结果(运行结果截图)
实验结果如上!
- 实验心得和总结(列出遇到的问题和解决办法,列出没有解决的问题,可以是个人相关知识点总结,要求300字以上)
总结:项目涵盖了Linux、Mysql、Hadoop、Map Reduce、Hbase、Hive、Sqoop、Kettle、IDEA、ECharts等系统和软件安装和使用方法。遇到报错,要先查看报错内容,再针对性的调整环境、配置。
问题一:启动hive时(./bin/hive)

解决方案:
一般是Hadoop中的guava的相关jar包与hive中的不适配,将hive中的删除,然后Hadoop中的guava-27.0-jre.jar,复制到hive里面就可以了,操作如下:
$cd /usr/local/hadoop/share/hadoop/common/lib
$rm guava-40.jar
$cd /usr/local/hadoop/share/hadoop/common/lib
$ cp -r guava-27.0-jre.jar /usr/local/hive/lib
问题二:在hive中在确保命令语句正确的前提下,创建数据库报错
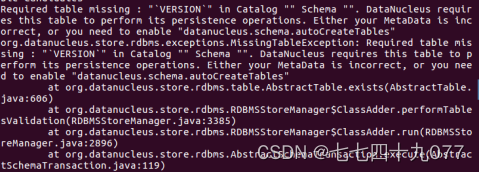
解决办法:手动初始化元数据库
$cd /usr/local/hadoop/share/hadoop/common/lib
$bin/schematool -dbType mysql -initSchema
问题三:kettle连接Hbase显示无法连接
解决办法:Hbase是通过zookeeper驱动连接,所有在kellter的配置目录plusgins配置
问题四:进入hbase shell命令出现下述错误。
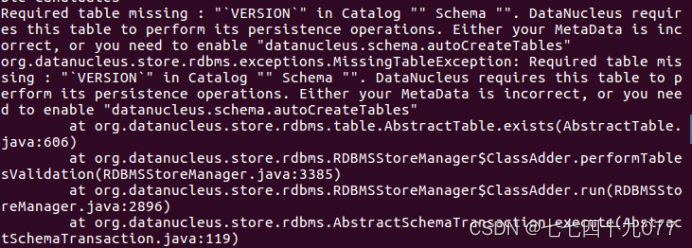
解决方案:关闭终端重新启动hadoop\hbase
















 2438
2438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









