






本文是解决过拟合问题的相关学习历程,该问题还未解决!期待有缘人为我答疑解惑,必有重谢!!!
TensorFlow2.x深度学习入门笔记
一、基础知识
1、jupyter的使用
1.1、jupyter指令:jupyter notebook
蓝色:命令模式;绿色编辑模式。esc和ctrl健可以实现两者相互转化
1.2、cuda和cudnn关系?
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
1.3、计算机GPU配置

1.4、python环境

1.5、如何查看python版本
(1)python --version
C:\Users\Lenovo>python --version
Python 3.9.7
(2)where python
C:\Users\Lenovo>where python
D:\software\anaconda\Ana\python.exe
C:\Users\Lenovo\AppData\Local\Programs\Python\Python39\python.exe
C:\Users\Lenovo\AppData\Local\Microsoft\WindowsApps\python.exe
2、CNN逻辑关系
2.1、什么是卷积神经网
以卷积结构为主,搭建起来的深度网络。将图片作为网络的输入,自动提取特征,并且对图片的变形(如平移,比例缩放,倾斜)等具有高度不变性
2.2、卷积神经网络(CNN)架构
输入层 —> 隐藏层 —> 输出层 :输入 -> 卷积 -> 池化 -> 激活 -> BN -> loss -> FC -> 输出
神经 = 网络结构 + 参数
2.3、反向传播(BP)算法起到监督学习的作用,简单说就是优化CNN。BP:计算输出层与真实值之间的偏差,进行逐层调节参数,类似于PID算法。
2.4、梯度下降算法
梯度为函数在山坡上A点无数个变化方向中变化最快到达最低点B的那个方向,梯度下降算法即为寻找最优解的算法。
2.5、步长/学习率(stride)
若没有合适的步长和学习率,则在梯队下降算法中会导致错过最低点,从而产生loss,所以目前可以认为训练模型调参的过程就是学找最佳步长的过程。
3、对CNN的深入再认识
3.1、卷积层
对图像和滤波矩阵做内积(逐个元素相乘再求和)的操作,可以理解为滤波器filters。每一个卷积核都对应一种特征,且一般使用3*3的卷积核。
CNN中的重要参数(这些参数的了解对日后的调参有很大帮助):
(1)filters:一般采用33的,2个33的卷积核和1个55的卷积核都输出1,但是33的计算量和参数量会小得多,卷积核越大,感受野就越大。
(2)stride:步长,见2.5
(3)pad:确保feature map整数倍变化,对尺度相关的任务尤为重要,否则会产生偏差,如目标检测。
F
=
3
=
>
z
e
r
o
p
a
d
w
i
t
h
1
F = 3 => zero pad with1
F=3=>zeropadwith1
在外围形成一圈0
3.2、池化层
对输入的特征图feature map进行压缩,使特征图变小,简化网络计算复杂度,进行特征压缩,提取主要特征,增大感受野。主要方法为:
m
a
x
p
o
o
l
w
i
t
h
2
∗
2
f
i
l
t
e
r
s
a
n
d
s
t
r
i
d
e
2
max pool with 2*2 filters and stride 2
maxpoolwith2∗2filtersandstride2
,即用2*2的卷积核配合2的步长取每个窗口中的最大值。
tf.keras.layers.MaxPooling2D(2, 2),
3.3、激活函数
增加卷积神经网的非线性,进而提升网络的表达能力。
(1)sigmoid函数

常用于分类任务,但sigmoid函数往往不用在网络中间层,因为容易出现梯度饱和甚至消失问题,即图中道数变成0的现象!多用于输出层,将计算结果约束到0~1之间。
(2)tanh函数

与sigmoid函数相似,同样不用与网络中间层,多用于循环神经网中,可忽略。
(3)relu函数

原理:将小于0的值置零,优势在于,梯度不会那么容易消失,但输入都是负数时relu就会死掉。此时就需要调整学习率来保证网络一直处于激活状态
# 卷积层,该卷积层的输出为32个通道,卷积核的大小是3*3,激活函数为relu
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
3.4、BatchNorm层
通过一定的规范化手段,将每层神经网络任意神经元输入值的分布强行拉回均值为0方差为1的标准正态分布中。
BatchNorm层优点:
(1)减少了人为选择,可以取消Dropout和L2正则项参数,或者采取更小的L2正则项约束参数;
(2)减少了对学习率的要求;
(3)可以不再使用局部响应归一化,BN本身就是归一化网络(局部响应归一化—AlexNet);
(4)破坏原来的数据分布,一定程度上缓解过拟合,相当于给数据加入了noise。
3.5、全连接层
连接所有的特征,将输出值送给分类器(如softmax分类器)
(1)将网络的输出变成一个向量
(
n
,
h
,
w
,
c
)
−
>
F
C
−
>
[
.
.
.
.
.
.
]
(n,h,w,c) -> FC -> [......]
(n,h,w,c)−>FC−>[......]
将输入层的所有节点与输出层的所有节点一一相连,这使得全连接层参数几乎占了整个网络的80%
(2)可以采用卷积代替全连接层
待定…
(3)全连接层对尺度敏感
对输入尺度敏感,输入数据不要轻易变化
(4)配合使用dropout层
随机杀死一些节点,防止网络因为参数量过大产生过拟合
3.6、Dropout层
在训练过程中,随机丢弃一部分输入,此时丢弃部分对应的参数不会更新。Dropout层可以很好地缓解过拟合问题,减少神经元之间复杂的共适应关系。
3.7、损失层
3.7.1、损失函数:用于评估模型的预测值和真实值(样本标签)的不一致程度
(1)经验风险最小,即数据拟合的程度
(2)结构风险最小
正则项或者惩罚项用于优化模型,降低结构风险如L0、L1、L2范式
(3)交叉熵损失、softmax loss等
3.7.2、损失层
损失层定义了使用的损失函数,通过最小化损失来驱动网络的训练。损失层通常定义的是经验风险最小。
(1)分类任务损失:交叉熵损失
(2)回归任务损失:L1损失、L2损失
3.7.3、交叉熵损失
# 指明模型的训练参数,优化器为sgd优化器,损失函数为交叉熵损失函数
# 随机梯度下降(SGD)优化器是一种迭代方法,用于求解损失函数的最小值(可以防止过分追求损失函数最小值造成过拟合)
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
3.7.4、Smooth L1损失函数
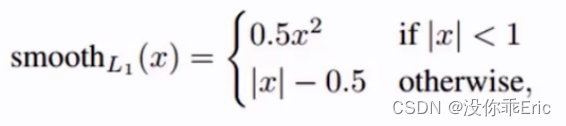
越接近最优解梯度越小,这样就不容易错过最优解。x>1时相当于L1正则式,相当于y=|x|函数;x<1时相当于L2正则式,相当于二次函数。所以Smooth L1损失函数兼顾了网络收敛速度和网络学习的稳定性。
4、常见的卷积神经网络
4.1、LeNet
用于解决手写数字识别,10分类。输入层 -> (conv pooling) -> FC(10) -> Softmax(0~1) -> 输出层
4.2、AlexNet
con - relu - pooling(下采样) - LRN(归一化) - fc - relu - dropout(防止过拟合) - fc - softmax
4.3、VggNet
![[p]](https://img-blog.csdnimg.cn/direct/dafac49f52194bb796119aa77ebe2250.png)
4.4、GooLeNet
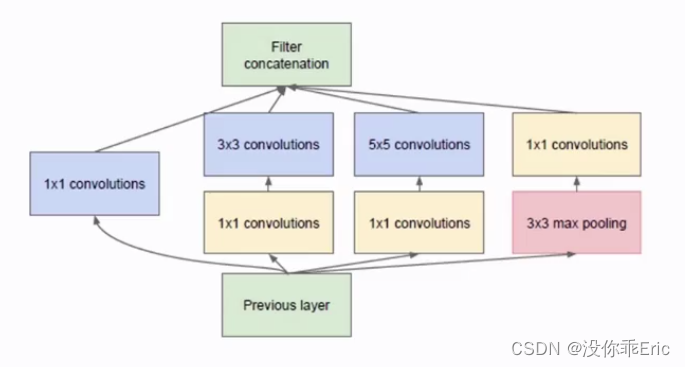
在设计网络结构时,不仅强调网络深度,也会考虑网络宽度,并将这种结构定义为Inception结构(一种网中网结构)。
GooLeNet告诉我们如何从卷积的角度减少计算量:
-
(1)用小的卷积核对大的卷积核进行拆分,大的卷积核一般用于输入层对原始数据处理。
-
(2)stride=2代替pooling层,减少计算量。
-
(3)灵活运用1*1的卷积核来进行通道(channel)降维,减少计算量。
4.5、ResNet
Bottleneck:跳连结构(Short-Cut)恒等映射,解决梯度消失问题。
ResNet中的BatchNorm:
- 每个卷积之后都会配一个BatchNorm层
- 对数据尺寸和分布进行约束
- 简单的正则化,提高网络泛化能力
ResNet的设计特点(这对我们以后设计网络有很大参考价值):
- 核心单元简单堆叠
- 跳连结构解决网络梯度消失问题
- Average Pooling层代替FC层
- BN层加快网络训练速度和收敛时的稳定性
- 加大网络深度,提高模型特征抽取能力
4.6、CNN结构对比
AlexNet 加深 -> VGG 加宽 -> GoogLeNet 加深 -> ResNet
5、轻量型卷积神经网
- 更少的参数量
- 更少的计算量
- 更易运行在移动端、嵌入式平台
5.1、SqueezeNet
- 1*1卷积核减少计算量
- 不同size的卷积核,类似Inception
- 深度压缩(deep compression)技术使模型更小,以达到在移动端或嵌入式平台运行的目的
5.2、MobileNet(常用的轻量型模型)
- Depth-wise Separable Convoluction(深度可分离)的卷积方式替代传统卷积方式,以达到减少网络权值参数的目的。
- Point-wise Convoluction,点卷积学习channel之间的信息,实际上就是1*1的卷积核
![[p]分组卷积](https://img-blog.csdnimg.cn/direct/e2f13905b34741f0bd93899a9d481b2b.png)
5.3、ShuffleNet
- 深度卷积来代替标准卷积
- 分组卷积+通道shuffle(通道打乱)
5.4、轻量型卷积神经网络设计标准
- 相同的通道宽度可最小化内存访问成本(MAC)
- 过度的分组卷积会增加MAC
- 网络碎片化(例如GoogLeNet的多路径结构)会降低并行度
- 元素级运算不可忽略
5.5、Xception
Xception先进行11卷积,再进行主通道卷积,而MobileNet是先主通道再11
Xception在1*1卷积之后加入relu
6、卷积神经网络中的Attention机制
soft软分布(0.2/0.3)或者one-hot分布(0/1分布),由于这两种分布则会产生Soft-Attention和Hard-Attention两种模式。
Attention实现机制:
- 保留所有分量均做加权(即Soft-Attention)
- 在分布中以某种采样策略选取部分分量(即Hard-Attention)
在原图、特征图、空间尺度、通道、特征图上的每个元素、不同历史时刻等都可以进行加权。
7、模型压缩
7.1、模型减枝
7.1.1减枝流程
除去无意义的权重和激活来减少模型的大小
- 贡献度排序
- 去除小贡献单元
- 重新fine-tuning(重新训练)
![[p]](https://img-blog.csdnimg.cn/direct/de75077765434418801a509c95fb0f61.png)
7.1.1减枝技巧
- 全连接部分通常会产生大量的参数冗余
- 对卷积窗口进行减枝的方式,可以是减少卷积窗口权重,或者直接丢弃卷积窗口的某一维度
- 丢弃稀疏的卷积窗口,但这并不会使模型运行速度有数量级提升
- 首先训练一个较大的神经网络模型,再逐步减枝得到更小的模型
7.2、模型量化/定点化
- 减少数据在内存中的位数操作,可以采用8位类型来表示32位浮点(定点化)或者直接训练低于8位的模型,比如:2bit模型
- 减少内存开销,减少更多带宽
- 对于某些定点运算方式,甚至可以消除乘法运算,只做加法运算,某些二值模型,直接使用位运算
- 代价是位数越低,通常精度下降越明显
tensorflow当中的量化操作示意图:
![[p]](https://img-blog.csdnimg.cn/direct/8e67e251b6564ad5b6145dde052d7249.png)
float输入 -> 定点运算 -> float输出
7.3、模型蒸馏
采用一个大的、复杂的网络模型来指导一个小的、精简之后的网络模型进行模型训练和学习。即教师网络和学生网络
8、tensorflow模型大全
8,1、网站:https://github.com/tensorflow/models
8.2、其中的slim文件夹下有一个模型训练脚本程序:models/research/slim/train_image_classifier.py。框架中提到的models/research/slim/nets
/nets_factory.py、dataset_factory.py和cifar10.py均围绕他展开。
- download_and_convert_cifar10.py为cifar10数据下载程序
- eval_image_classifier.py为模型测试程序
- train_cifarnet_on_cifar10.sh为命令脚本,可以快捷执行上面程序
注意:train_cifarnet_on_cifar10.sh当中的python改成python3
8.3、在Linux系统中的具体操(具体操作参照极客空间4中51-5.10/1:37处):
- cd /home/aiserver/muke/models/research/slim/
- sh scripts/train_cifarnet_on_cifar10.sh
8.4、train_cifarnet_on_cifar10.sh使用以技巧
此处训练需要很长时间,我们可以用:ls /tmp/cifarnet-model/直接进入模型文件夹,然后执行sh scripts/train_cifarnet_on_cifar10.sh当中#Run evalustion里面的命令快速评估模型
二、人脸识别应用
在学习人脸检测算法之前,先学习一下Linux操作系统的相关知识!
1、人脸匹配业务
- 人脸验证:ROC曲线、PR曲线
- 人脸识别:CMC曲线
CMC曲线:模式识别分类器评价指标之CMC曲线-CSDN博客
2、人脸匹配方法
- 人脸特征表示
- 人脸特征度量
…
3、人脸匹配解决思路
…
4、FaceNet模型
CASIA-faceV5:亚洲人脸数据集
此处我们使用LFW数据集来训练我们的人脸匹配模型
4.1、人脸匹配数据准备
-
git clone https://github.com/davidsandberg/facenet
-
sudo pip3 install -r requirements.txt
-
export PYTHONPATH=$(pwd)/src
在src当中存放了我们会用到的一些脚本
-
python3 src/align/align_dataset_mtcnn.py lfw lfw_160-image_size 160 --margin 32 --random_order - gpu_memory_fraction 0.25
人脸对齐和人脸裁剪的脚本
dlib库用来进行人脸检测+关键点定位
根据关键点或人脸检测结果,提取人脸图像















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









