






目录
1、在卷积神经网络处理图像的过程中,通常需要经过以下几个步骤:
卷积神经网络(CNN)
摘要
1、在卷积神经网络处理图像的过程中,通常需要经过以下几个步骤:
输入层,卷积层,池化层,全连接层,输出层
-
首先,图像会通过卷积层,其中卷积核用于提取图像每个小部分的特征。每个卷积单元的参数都是通过反向传播算法优化得到的,这使得网络可以逐渐学习到更加复杂和精细的特征。
-
然后,提取出的特征会被送入池化层,这一层的主要作用是进一步提取主要特征,并且降低数据的空间大小。
-
接着,全连接层会将之前提取出的所有特征进行汇总,并产生分类器。
-
最后,这个分类器会对图像进行预测识别。
2、人脸表情识别:正常、愤怒、厌恶、恐惧、高兴、悲伤和惊奇
想要成功的进行人脸表情识别,要经历三个阶段。
第1个阶段是人脸检测阶段
#dlib.get_frontal_face_detector()是Dlib库中的一个函数,用于获取一个预训练的正面人脸检测器
self.detector = dlib.get_frontal_face_detector()Faster- R-CNN 的人脸检测算法[33],借鉴了两阶段物体检测算法 思想。Faceness-Net [34]则结合了非单子网络算法和双阶段算法,设置了 5 个 DCNN 网络 分别检测人脸的五个特征部位,最后汇聚 5 个网络的信息判断是否是人
第2个阶段是人脸表情特征(关键点)的提取阶段
#shape_predictor()函数 ==> # dlib的68点模型,使用训练好的特征预测器 :
self.predictor = dlib.shape_predictor("C:/Users/Lenovo/PycharmProjects/pythonProject/shape_predictor_68_face_landmarks.dat")注意:Dlib库中常用的面部特征检测器是One millisecond face alignment with an ensemble of regression trees。
第3个阶段是人脸表情的识别阶段
if round(mouth_higth >= 0.04 and mouth_higth <= 0.08 and mouth_width>=0.39):表情分类,VGGNet-19和ResNet-18是深度学习中广泛应用的卷积神经网络,它们在各自的领域内都取得了显著的成果。
VGGNet-19的主要特点是网络深度加深,通过使用全部都是3x3的小卷积核和2x2的池化核,不断增加网络的层数来提升模型的性能。因此,VGGNet-19常被用于处理图像分类、物体识别等任务。此外,VGGNet还可以通过重复使用简单的基础块来构建深度模型,这在tf.keras中可以实现。
相比之下,ResNet-18虽然网络较浅,但是通过引入残差结构解决了随着网络层数增多可能出现的梯度消失问题,从而为网络的深度加深打下基础。ResNet-18的主要应用包括图像分类、物体检测、人脸识别等。特别地,ResNet可以提取特征,其特征就是全连接层前一层的输出,可以作为分类器使用。
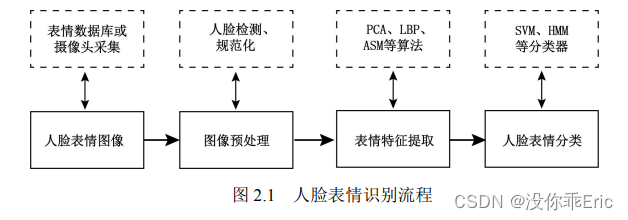
[p]

[p]
关键字:卷积神经网络,人脸情绪识别,AI照明
文章摘要:输入层,卷积层,池化层,全连接层,输出层。首先,图像会通过卷积层,其中卷积核用于提取图像每个小部分的特征。每个卷积单元的参数都是通过反向传播算法优化得到的,这使得网络可以逐渐学习到更加复杂和精细的特征。然后,提取出的特征会被送入池化层,这一层的主要作用是进一步提取主要特征,并且降低数据的空间大小。接着,全连接层会将之前提取出的所有特征进行汇总,并产生分类器。最后,这个分类器会对图像进行预测识别。
第一章、卷积核
卷积核可以提取出原图中与他相似的特征(特征提取器)
卷积核是卷积神经网络中的一种数学工具,它是一个小的矩阵,用于对输入数据进行卷积运算。在图像处理过程中,卷积核被定义为一个函数,这个函数可以计算输入图像一个小区域内像素的加权平均,并将结果作为输出图像对应像素的值。此外,卷积核也被视为传统图像处理中各种特征提取算子的一种形式,只不过在深度学习中,这些特征提取算子(即卷积核)是通过学习获得的。
在卷积神经网络中,通过不断地改变卷积核的参数,网络可以逐渐学习到更加抽象和高级的特征。这意味着卷积核的大小和形状可以根据具体的任务和输入数据的特性进行调整。尽管卷积核通常由神经网络自动学习得到,但在某些情况下,也可以手动设计和调整。
第二章、Pooling(池化)
在卷积神经网络中,池化操作通常紧跟在卷积操作之后,用于降低特征图的空间大小。池化操作的基本思想是将特征图划分为若干个子区域(一般为矩形),并对每个子区域进行统计汇总。池化操作的方式可以有很多种,比如最大池化(Max Pooling)、平均池化(Average Pooling)等。其中,最大池化操作会选取每个子区域内的最大值作为输出,而平均池化操作则会计算每个子区域内的平均值作为输出。
第三章、全连接层
全连接层在卷积神经网络中起到整合和分类的作用。它在整个网络的最后,将前面经过多次卷积和池化后高度抽象化的特征进行整合,然后输出一个概率,之后的分类器可以根据这个概率进行分类。
此外,全连接层还扮演着“分类器”的角色,它将学到的特征表示映射到样本标记空间,换句话说,就是将特征整合到一起(高度提纯特征),以方便交给最后的分类器或者回归。例如,VGG-16网络中的全连接层,对224x224x3的输入,最后一层卷积可以得到输出为7x7x512,如果后层是一层含4096个神经元的FC,则可以用卷积核为7x7x512x4096的全局卷积来实现这一全连接层。
然而,全连接层也存在一些问题,如参数冗余问题,仅全连接层的参数就可占整个网络参数的80%左右,这降低了训练的速度,并且容易导致过拟合。为了解决这些问题,有一些常见的方法,比如使用全局平均池化层或卷积层替换全连接层,或者在卷积层和全连接层之间加入空间金字塔池化。
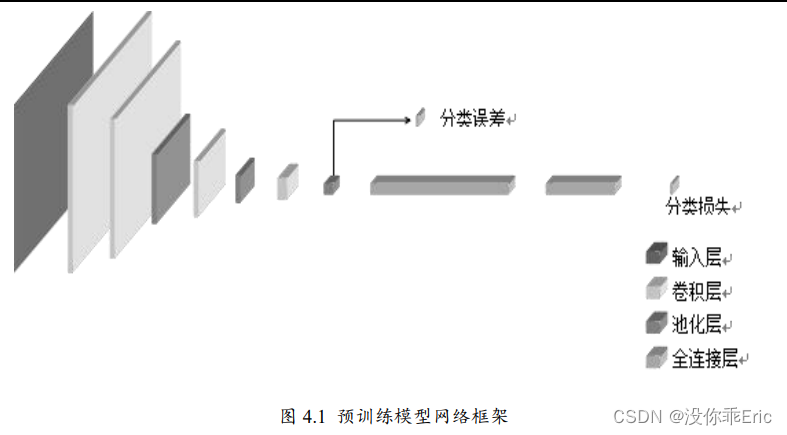
[p]
注:表情识别中最核心的环节为卷积神经网络框架的搭建,我参考了以下四篇文章:
 https://blog.csdn.net/juhanishen/article/details/123462838?spm=1001.2014.3001.5506
https://blog.csdn.net/juhanishen/article/details/123462838?spm=1001.2014.3001.5506第四章、卷积运算中的数学公式
卷积神经网络中主要涉及到的数学公式包括卷积操作、池化操作、前向传播计算和反向传播计算等。
-
卷积操作:卷积函数是一种数学运算,用于描述两个函数之间的相互作用。在卷积神经网络中,卷积核(也称为滤波器)与输入图像进行卷积操作,生成特征图。这个过程可以表达为一个积分运算。
-
池化操作:池化操作通常用于对特征图进行下采样,减少数据量并提取主要特征。常见的池化操作有最大池化和平均池化,它们分别取局部区域的最大值或平均值作为输出。
-
前向传播计算:前向传播计算是指网络在训练过程中,数据从输入层到输出层的传递过程。在这个过程中,每一层的神经元都会对输入数据进行加权求和,并通过激活函数进行处理。
-
反向传播计算:反向传播计算是神经网络中非常重要的一个环节,它通过梯度下降法来更新网络中的参数,使得网络的输出结果更接近期望的输出。在这个过程中,误差会从输出层向输入层反向传递,并根据链式法则计算出每个参数对误差的贡献程度。
激活函数ReLU、前向传播 、反向传播:冀聪聪. 基于卷积神经网络人脸表情识别的研究[D].广西师范大学,2020.
第五章、人脸表情数据库
Fer2013数据集是一个专门用于人脸识别和表情识别的大型数据库。它包含了超过35,000张人脸图像,涵盖了七种不同的基本情绪:愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。这些图像都是在自然环境下采集的,每个人有多个图像,每个图像都有标签。然而,对于这个数据集来说,一个主要的问题是,用于提取图像外观特征的人为设计的特征(如Gabor、LBP、LGBP、HOG和SIFT)往往在特定的小样本集中更有效,但在应用于新的人脸图像时可能会遇到困难。
另一方面,CK+数据库也是一个广泛应用于人脸识别和表情识别任务的数据集。该数据库包含了大量的正面人脸图像,这些人脸图像都是在自然环境下采集的。特别是,CK+人脸表情数据集包含3种情绪类别:惊讶、悲伤、恐惧等。
值得一提的是,还存在一种ck+48与fer2013融合的数据集,这种融合可能有助于提高表情识别的准确性和鲁棒性。
第六章、人脸表情分类器
人脸表情分类器是一种基于深度学习技术的系统,其主要目标是识别和分类人脸表情。这种分类器的工作流程通常包括以下步骤:首先,利用如OpenCV的函数进行人脸检测;然后,提取人脸表情特征;最后,根据提取的特征进行表情分类。此外,我们还需要大量的人脸表情图片来训练模型,这些图片需要被标注为不同的情绪类别。
在实现过程中,有多种神经网络结构可以用于构建表情分类器,例如VGG19和Resnet18等深度卷积神经网络。其中,VGG19网络的每一个小块通常由一个卷积层、一个BatchNorm层、一个relu层和一个平均池化层构成。为了进行训练,我们可以使用公开的表情数据库,如The Japanese Female Facial Expression (JAFFE) Database或者从Kaggle比赛获取的数据。
值得一提的是,我们也可以借助一些高级的API和框架来简化开发流程,例如在TensorFlow框架下,使用Keras搭建训练模型,并利用OpenCV库中的相关函数来实现人脸识别和表情识别等功能。
第七章、Dlib库
Dlib是一个包含机器学习算法的C++开源工具包。Dlib可以帮助您创建很多复杂的机器学习方面的软件来帮助解决实际问题。目前Dlib已经被广泛的用在行业和学术领域,包括机器人,嵌入式设备,移动电话和大型高性能计算环境。
Dlib是开源的、免费的;官网和git地址:
# 官网 http://dlib.net/ # github https://github.com/davisking/dlib
#####core code代码中的库
dlib:一个用于人脸识别的库。
numpy:一个用于数据处理的库。
cv2:Python中图像处理的库OpenCv的拓展库,用于计算机视觉任务。
socket:用于网络通信的库。
Thread:用于多线程编程的库。
time:用于时间相关的操作的库。
上面的语句中导入的库并没有直接包含卷积神经网络(Convolutional Neural Network,简称CNN)的内容。但是,dlib库是一个用于计算机视觉任务的库,其中包含了一些卷积神经网络的实现和算法。
在dlib库中,有一些函数和类可以用于构建和训练卷积神经网络模型。例如,可以使用dlib.cnn_trainer类来创建一个卷积神经网络的训练器对象,然后使用该对象的方法来定义网络结构、损失函数和优化器等参数。此外,dlib还提供了一些预训练的卷积神经网络模型,如AlexNet、VGG等,可以直接用于图像分类等任务。
需要注意的是,虽然dlib库提供了一些卷积神经网络的实现和算法,但它并不是专门用于深度学习任务的框架。如果需要进行更复杂的深度学习任务,可以考虑使用其他专门的深度学习框架,如TensorFlow或PyTorch。
####实现CNN的两种工具
PyTorch和TensorFlow都是深度学习领域流行且强大的框架。对于初学者来说,选择哪一个更合适可能取决于个人的需求和背景。
PyTorch:如果你已经熟悉Numpy、Python以及常见的深度学习概念(如卷积层、循环层、SGD等),那么PyTorch将非常容易上手。它的动态计算图允许更直观和灵活的代码编写,尤其适合需要快速原型设计和单步调试的研究者或开发者。
TensorFlow:TensorFlow被视为一个嵌入Python的编程语言。你写的TensorFlow代码会被Python编译成一张图,然后由TensorFlow执行引擎运行。这意味着TensorFlow在分布式训练和扩展性方面具有优势。此外,TensorFlow社区提供了大量的预训练模型和教程,有助于初学者快速入门。
卷积神经网络(CNN):无论是选择PyTorch还是TensorFlow,都可以通过它们实现卷积神经网络(CNN),这是一种主要用于处理图像、语音、文本等数据的深度学习模型。值得一提的是,这两个框架在CNN上都取得了卓越的成果,例如在ImageNet数据集上的表现。
####CNN卷积核(特征提取器)在dlib中的呈现
Dlib库中的68点人脸模型是专门用于人脸识别的,这个模型能够检测并标定出人脸上68个关键特征点的位置。
这些特征点均匀地覆盖了整个脸部,例如:鼻点=27–35,左眉点=22–26,右眼点=37–42等等。通过这些特征点,可以对人脸进行更准确的定位和识别。
此外,这些特征点的坐标还可以用于实现人脸对齐、融合等应用。在实际应用中,常常会利用如OpenCv的工具,将这些特征点在图像上可视化。
###dlib库中关于CNN的知识点
在Dlib库中,人脸识别的基本思路包括计算已知图片中所有人脸对应的特征向量,以及计算要识别的未知图片中所有人脸对应的特征向量。此外,dlib还提供了预训练模型进行人脸识别。
这个预训练模型是使用深度学习算法进行训练的卷积神经网络模型,但具体模型的详细信息没有明确给出。在使用dlib进行人脸识别时,我们可以直接使用这个训练好的人脸特征提取模型。
最后,通过计算人脸之间的欧式距离,来进行人脸识别。第八章、core code
# -*- coding: utf-8 -*-
"""
从视频中识别人脸,并实时标出面部特征点,简单判断情绪
"""
import dlib # 人脸识别的库dlib
import numpy as np # 数据处理的库numpy
import cv2 # Python中图像处理的库OpenCv的拓展库(计算机视觉库)
import socket
from threading import Thread
import time
global stop_flog
stop_flog = 0
global sock
def init_socket():
global sock
server_ip = "192.168.248.169"
server_port = 80
# 要发送的数据
# 创建一个TCP套接字
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((server_ip, server_port))
print("Connected to server")
# 发送数据到服务器
def send_data(data):
global sock
try:
sock.sendall(data)
time.sleep(5)
global stop_flog
stop_flog = 0
except Exception as e:
stop_flog = 0
print("Error sending data:", str(e))
class face_emotion(): # 类
def __init__(self): # 类在实例化成对象的时候首先调用的方法
# 使用特征提取器get_frontal_face_detector dlib.get_frontal_face_detector()是Dlib库中的一个函数,用于获取一个预训练的正面人脸检测器
self.detector = dlib.get_frontal_face_detector()
# dlib的68点模型,使用训练好的特征预测器
self.predictor = dlib.shape_predictor("C:/Users/Lenovo/PycharmProjects/pythonProject/shape_predictor_68_face_landmarks.dat")
# 使用电脑自带摄像头。
self.cap = cv2.VideoCapture(0)
# 设置视频参数,propId设置的视频参数,value设置的参数值
self.cap.set(3, 480)
def learning_face(self):
init_socket()
# 眉毛直线拟合数据缓冲
line_brow_x = []
line_brow_y = []
# cap.isOpened() 返回true/false 检查初始化是否成功
while (self.cap.isOpened()):
# cap.read()
# 返回两个值:
# 一个布尔值true/false,用来判断读取视频是否成功/是否到视频末尾
# 图像对象,图像的三维矩阵
flag, im_rd = self.cap.read()
# 每帧数据延时1ms,延时为0读取的是静态帧
k = cv2.waitKey(1)
# 取灰度
img_gray = cv2.cvtColor(im_rd, cv2.COLOR_RGB2GRAY)
# 使用人脸检测器检测每一帧图像中的人脸。并返回人脸数rects
rects = self.detector(img_gray, 0)
# 要显示在屏幕上的字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 如果检测到人脸(?)
if (len(rects) != 0):
# 对每个人脸都标出68个特征点
for i in range(len(rects)):
# enumerate方法同时返回数据对象的索引和数据,k为索引,d为faces中的对象
for k, d in enumerate(rects):
# 用红色矩形框出人脸
cv2.rectangle(im_rd, (d.left(), d.top()), (d.right(), d.bottom()), (0, 0, 255))
# 计算人脸热别框边长
self.face_width = d.right() - d.left()
self.face_higth = d.top() - d.bottom()
# 使用预测器得到68点数据的坐标
shape = self.predictor(im_rd, d)
# 圆圈显示每个特征点
for i in range(68):
cv2.circle(im_rd, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 8)
cv2.putText(im_rd, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(255, 255, 255))
# 分析点的位置关系来作为表情识别的依据
mouth_width = (shape.part(54).x - shape.part(
48).x) / self.face_width # 嘴巴咧开程度 矩形框和坐标来测量嘴的张开和闭合
mouth_higth = (shape.part(66).y - shape.part(62).y) / self.face_width # 嘴巴张开程度
# print("mouth_width:",mouth_width)
# print("mouth_higth:",mouth_higth)
# 通过两个眉毛上的10个特征点,分析挑眉程度和皱眉程度
brow_sum = 0 # 高度之和
frown_sum = 0 # 两边眉毛距离之和
for j in range(17, 21):
brow_sum += (shape.part(j).y - d.top()) + (shape.part(j + 5).y - d.top())
frown_sum += shape.part(j + 5).x - shape.part(j).x
line_brow_x.append(shape.part(j).x)
line_brow_y.append(shape.part(j).y)
tempx = np.array(line_brow_x)
tempy = np.array(line_brow_y)
# np.ployfit(x,a,n)拟合点集a得到n级多项式,其中x为横轴长度
z1 = np.polyfit(tempx, tempy, 1) # 拟合成一次直线
# round(x [,n])返回浮点数x的四舍五入值 round(80.23456, 2)返回80.23
self.brow_k = -round(z1[0], 3) # 拟合出曲线的斜率和实际眉毛的倾斜方向是相反的
brow_hight = (brow_sum / 10) / self.face_width # 眉毛高度占比
brow_width = (frown_sum / 5) / self.face_width # 眉毛距离占比
# print("眉毛高度与识别框高度之比:",brow_hight)
# print("眉毛间距与识别框高度之比:",brow_width)
# 眼睛睁开程度
eye_sum = (shape.part(41).y - shape.part(37).y + shape.part(40).y - shape.part(38).y +
shape.part(47).y - shape.part(43).y + shape.part(46).y - shape.part(44).y)
eye_hight = (eye_sum / 4) / self.face_width
# print("眼睛睁开距离与识别框高度之比:",eye_sum)
"""
默认: mouth_width: 0.33488372093023255
mouth_higth: 0.004651162790697674
默认: 眉毛高度与识别框高度之比: 0.12674418604651164
眉毛间距与识别框高度之比: 0.296124031007752
眼睛睁开距离与识别框高度之比: 0.035852713178294575
惊讶:眉毛高度为0.08~0.09左右 mouth_higt 0.10~0.15
高兴:眉毛高度为0.12~0.10左右 mouth_higt 0.03~0.07
悲伤:mouth_higt 0.03~0.07 眼睛睁开距离与识别框高度之比:
恐惧:眉毛高度为0.8~0.6左右 mouth_higt 0.01~0.03
厌恶:眉毛高度为0.8~0.6左右 mouth_higt 0.00~0.00
病痛:眉毛高度为0.8~0.6左右 mouth_higt 0.03~0.07
"""
# 分情况讨论and or 此处数据需要不断调试
# 张嘴,可能是开心或者惊讶`
if round(mouth_higth >= 0.04 and mouth_higth <= 0.08 and mouth_width>=0.39):
cv2.putText(im_rd, "happy", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
global stop_flog
if stop_flog == 0:
stop_flog = 1
t1 = Thread(target=send_data, args=([b"0x01"]))
t1.start()
elif round((mouth_higth >= 0.10 and mouth_higth<0.15) and (mouth_width<0.32 and mouth_width>0.28)):
cv2.putText(im_rd, "amazing", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
if stop_flog == 0:
stop_flog = 1
t1 = Thread(target=send_data, args=([b"0x02"]))
t1.start()
elif round(eye_sum <= 26 and mouth_higth<=0.02):
cv2.putText(im_rd, "pain", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
if stop_flog == 0:
stop_flog = 1
t1 = Thread(target=send_data, args=([b"0x03"]))
t1.start()
elif round(brow_width >= 0.40 and mouth_higth<=0.01):
cv2.putText(im_rd, "anger", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
if stop_flog == 0:
stop_flog = 1
t1 = Thread(target=send_data, args=([b"0x04"]))
t1.start()
# # 没有张嘴,可能是正常和生气
else:
cv2.putText(im_rd, "nature", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
if stop_flog == 0:
stop_flog = 1
t1 = Thread(target=send_data, args=([b"0x05"]))
t1.start()
# 标出人脸数
cv2.putText(im_rd, "Faces: " + str(len(rects)), (20, 50), font, 1, (0, 0, 255), 1, cv2.LINE_AA)
else:
# 没有检测到人脸
cv2.putText(im_rd, "No Face", (20, 50), font, 1, (0, 0, 255), 1, cv2.LINE_AA)
# 添加说明
# im_rd = cv2.putText(im_rd, "S: screenshot", (20, 400), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
# im_rd = cv2.putText(im_rd, "Q: quit", (20, 450), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
# 按下ESC键退出 (?)
if cv2.waitKey(10) == 27:
break
# 窗口显示
cv2.imshow("camera", im_rd)
# 释放摄像头
self.cap.release()
# 删除建立的窗口
cv2.destroyAllWindows()
if __name__ == "__main__":
my_face = face_emotion()
my_face.learning_face()第九章、esp8266
ESP8266是一款高性能的WIFI串口模块,广泛应用于物联网领域。它有两种主要的开发方式:一种是AT指令开发方式,另一种是SDK开发方式。
对于初学者来说,使用AT指令进行开发可能会相对简单一些。首先需要下载并安装ESP8266的固件到模块中,这可以通过刷固件工具如ESP8266Flasher来完成。然后,我们可以通过串口调试助手和网络调试助手来发送AT指令,控制ESP8266模块的各种功能。
然而,需要注意的是,ESP8266模块的使用可能需要对WIFI协议和相关知识有一定了解。因此,深入学习ESP8266的AT指令集以及相关的网络协议(如mqtt协议)是十分必要的。
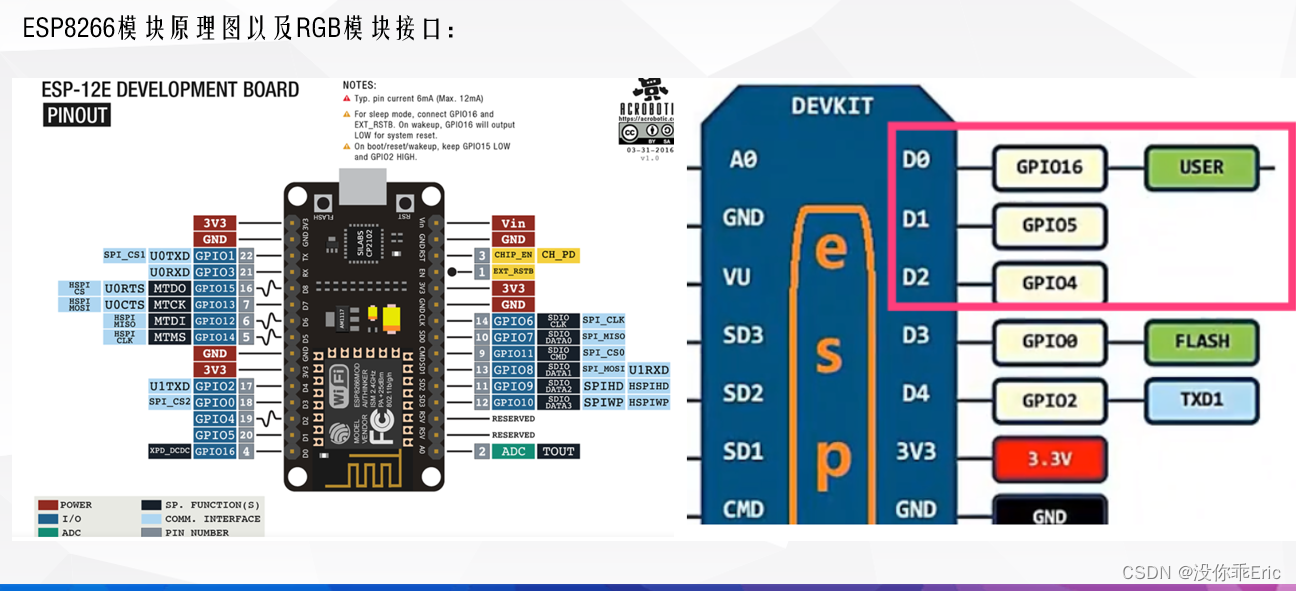
以下为卷积神经网络(CNN)基于dlib库和esp8266模块的应用代码:
#include <ESP8266WiFi.h>
#define RGBLED_G D1 //绿色的引脚号
#define RGBLED_R D2 //红色的引脚号
#define RGBLED_B D3 //蓝色的引脚号
// WiFi网络参数
const char* ssid = "vivo S17 Pro";
const char* password = "12345678";
/*
淡红色:增加红色分量,减小绿色和蓝色分量。例如,R=255,G=100,B=100。
淡黄色:增加红色和绿色分量,减小蓝色分量。例如,R=255,G=255,B=100。
淡绿色:增加绿色分量,减小红色和蓝色分量。例如,R=100,G=255,B=100。
淡暖色:增加红色和绿色分量,适度减小蓝色分量。例如,R=255,G=200,B=100。
*/
// 创建一个WiFi服务器
WiFiServer server(80);
void setup() {
Serial.begin(115200);
pinMode(RGBLED_R,OUTPUT);
pinMode(RGBLED_G,OUTPUT);
pinMode(RGBLED_B,OUTPUT);
// 连接WiFi网络
WiFi.begin(ssid, password);
while (WiFi.status() != WL_CONNECTED) {
delay(1000);
Serial.println("Connecting to WiFi...");
}
Serial.println("Connected to WiFi");
// 启动服务器
server.begin();
Serial.println("Server started");
Serial.print("当前接入点的IP地址为: ");
Serial.println(WiFi.localIP());
}
void color(unsigned char red,unsigned char green,unsigned char blue)//函数功能声明
{
analogWrite(RGBLED_R,red);
analogWrite(RGBLED_G,green);
analogWrite(RGBLED_B,blue);
}
void loop() {
// 等待客户端连接
WiFiClient client = server.available();
if (client) {
Serial.println("New client connected");
// 读取客户端发送的数据
while (client.connected()) {
if (client.available()) {
String data = client.readStringUntil('\n');
data.trim();
Serial.println("Received data: " + data);
// 根据接收到的数据进行相应的操作
if (data == "0x01") {
// 执行操作1 happy
Serial.println("Performing operation 1");
color(255,255,0);//yellow
// TODO: 在这里添加操作1的代码
} else if (data == "0x02") {
// 执行操作2 amazing
Serial.println("Performing operation 2");
color(0,0,255);//blue
// TODO: 在这里添加操作2的代码
} else if (data == "0x03") {
// 执行操作3 pain
Serial.println("Performing operation 3");
color(0,255,0);//green
// TODO: 在这里添加操作3的代码
} else if (data == "0x04") {
// 执行操作4 anger
Serial.println("Performing operation 4");
// TODO: 在这里添加操作4的代码
color(255,192,203);//pink
} else if (data == "0x05") {
// 执行操作5 nature
Serial.println("Performing operation 5");
color(255,105,0);//orange
// TODO: 在这里添加操作5的代码
}
else {
// 未知的数据
Serial.println("Unknown data");
}
}
}
// 断开客户端连接
//client.stop();
Serial.println("Client disconnected");
}
}第十章、部分成果展示
以下是几种常见的灯光对人情绪的影响:
-
白色灯光:白色灯光可以让人感到清晰和明亮,有助于提高警觉性和注意力。
-
黄色灯光:黄色灯光可以创造出一种温馨、舒适的氛围,有助于放松心情,缓解疼痛和不适感。
-
蓝色灯光:蓝色灯光可以让人感到平静和安宁,有助于降低紧张和焦虑情绪。
-
红色灯光:红色灯光具有较强烈的刺激性,给人以燃烧感和挑逗感,但过多接触容易产生焦虑和身心受压的情绪。
-
彩色灯光:城市街道上过多的彩色光源会对人体造成伤害,让人感到头晕目眩,出现恶心、呕吐、失眠等症状。
总之,不同的灯光颜色会产生不同的心理反应,从而影响人的情绪。因此,在设计照明环境时需要根据实际需求进行选择,避免过度使用某种颜色光源,以免对身心健康造成不必要的影响。
经研究,我们发现人类情绪与灯光颜色有着密切联系,因此我们着力根据人类面部情绪的反馈,进而及时调换灯光的颜色。如:当人脸表情识别系统识别出"pain"面部情绪时,我们会通过esp8266模块及时发出信号,将灯光调至黄色,以达到缓解疲劳,放松心情的目的。即在两者之间形成反馈与负反馈系统,使人类的情绪能够得到智能的调节。如果将这一理念投入到医学领域,其研究前景则极为广阔。"基于ai技术的情绪照明智能系统的研究"正是我们基于这一理念研发出的项目。它建立在卷积神经网络之上,并结合dlib库与esp8266,通过Pycharm、Arduino编写了核心代码,最终实现如下功能。
下图为遮挡情况下女性面部"nature"表情的识别:

[p]

第十一章、参考文献
[1]杨瀚霆. 基于轻量化卷积神经网络的人脸表情识别方法[D].北京建筑大学,2020.
[2]周涛. 基于卷积神经网络的静态图像人脸表情分类技术研究[D].内蒙古科技大学,2020.
[3]王帅. 基于卷积神经网络的人脸表情识别研究[D].长春工业大学,2020.
[4]辛阳阳. 基于深度学习的人脸表情识别方法的研究[D].山西大学,2020.
[5]冀聪聪. 基于卷积神经网络人脸表情识别的研究[D].广西师范大学,2020.
[6]朱宇祥. 基于量子神经网络的肢体动作识别研究[D].沈阳工业大学,2019.
[7]孙俊. 人脸图像分析和识别方法研究[D].清华大学,2004.
[8] 方冬冬. 基于深度学习的人脸检测算法研究 [D]. 成都: 电子科技大学,2019
[9] Jiang H, Learned-Miller E. Face detection with the faster R-CNN[C]. 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017). Washington:IEEE, 2017:650-657.
[10] Yang S, Luo P, Loy C C, et al. Faceness-net: Face detection through deep facial part responses [J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40 (8): 1845-1859.
[11] Devries T, Biswaranjan K, Taylor G W. Multi-task learning of facial landmarks and expression[C]. 2014 Canadian Conference on Computer and Robot Vision. Montreal:IEEE, 2014:98-103.
[12] Lu G, He J, Yan J, et al. Convolutional neural network for facial expression recognition [J]. Journal of Nanjing University of Posts and Telecommunica
[13]陆嘉慧. 基于集成卷积神经网络的面部表情识别研究与应用[D]. 青岛大学, 2020. DOI:10.27262/d.cnki.gqdau.2020.001767
第十二章 、致谢
感谢来自远方的学长在代码上的指导,以及引用的诸多论文的前辈们,感谢你们在人工智能领域奉献的智慧,我们都是站在巨人的肩上,如此才得以振翅高飞!!!

















 7256
7256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









