







1 统计量
1.1 集中量数
(1)平均值:最常用的集中趋势统计指标,包括算术平均值、几何平均值和调和平均值等。
①算术平均数:最常见的平均数,是所有数据的总和除以数据的个数。它能简单地反映数据的整体水平,但容易受到极端值的影响。
②几何平均数:用于乘法关系的数据,适合处理比例或百分比。例如,当我们希望求一组数据的平均增长率时,几何平均数比算术平均数更合适。
③调和平均数:用于处理速率或比率数据,尤其适合在计算平均速度或效率时使用。
(2)中位数(又称中点数、中数、中值)是集中趋势的一个度量,用来表示数据的中间位置。具体来说,当我们将数据从小到大排列时,位于中间位置的数就是中位数。中位数的特性是,在数据集中有一半的值小于它,另一半的值大于它。它适用于衡量不对称分布的数据,因为它不受极端值的影响。中位数可以是数据中的某个值,也可能是两个数的平均值(当数据量为偶数时)。
(3)众数是指一组数据中出现频率最高的数值,即在数据集中出现次数最多的那个(或那些)数。与平均数和中位数不同,众数更适用于描述类别或离散数据。众数的特点是它可以是唯一的,也可以有多个(即数据集有两个或更多众数时称为多众数)。众数不受极端值的影响,因此在分析分布较不均匀或分类数据时,众数是一个有用的统计量。
1.2 差异量数
全距:全距是指数据集中最大值与最小值之间的差异,计算方法是用最大值减去最小值。全距能够快速反映数据的分布范围,帮助了解数据的离散程度或数据值的广度。然而,由于全距只依赖于极端值,它容易受到异常值或极端数据的影响,无法充分反映数据的整体分布情况。因此,在分析数据的离散程度时,虽然全距提供了一个初步的参考,但通常还需要结合其他指标(如标准差或四分位距)来更全面地了解数据的变异性。
方差:方差是衡量一组数据与其平均值之间偏离程度的指标,反映了数据的波动性和离散程度。计算方差的过程是:先计算每个数据与平均值的差,再将这些差值平方,然后求这些平方值的平均。总体方差是将平方和除以总体样本数得到的结果。方差值越大,说明数据点之间的差异越明显,数据分布更为分散;方差值越小,则表示数据更集中在平均值附近。方差的平方处理使得正负差异不相互抵消,从而更准确地反映数据的变异程度。不过,方差的单位是原始数据单位的平方,因此它通常会与标准差一起使用,便于解释,公式如下所示:
但对于样本数据而言,方差是所有数据离均差的平方和除以自由度n-1,公示如下:
标准差:总体标准差+样本标准差;
总体标准差:
样本标准差:
百分位数:百分等级是指在一个分数分布中低于这个分数的人数百分比,用字母P表示。百分位数是指与某个百分等级P对应的那个分数点。百分位数可以分成很多种类,常用的百分位数有四分位数和十分位数,四分位数是将数据划分为四等份,每一等份包含25%的数据,处在各分位点的数值就是四分位数。四分位数就有三个,第一个四分位数称为下四分位数,第二个四分位数就是中位数,第三个四分位数称为上四分位数,分别用Q1,Q2,Q3表示。统计上利用四分位差来判断数据的离散情况,四分位差是将第三个四分位数减去第一个四分位数的一半,即QR=(Q3-Q1)/2,显然,其值越大说明数据离散程度越大,相反,其值越小离散程度距比起来,其优势是可以剔除两端的极值对离散程度的影响。
2 数据分布
2.1 正态分布
如果一组数据服从正态分布,其形状呈左右对称的钟形曲线。这意味着数据集中在平均值附近,远离平均值的数据点逐渐减少。
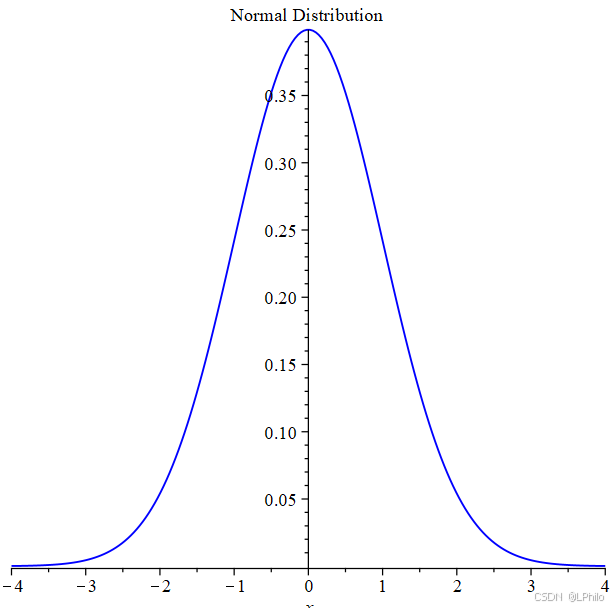
根据正态分布的特性:
①在距离平均值一个标准差范围内的数据约占总数的68%;
②在距离平均值两个标准差范围内的数据约占95%;
③ 在距离平均值三个标准差范围内的数据约占99%。
此外,所有的正态分布都可以通过标准化转化为标准正态分布。标准正态分布是一种特殊形式的正态分布,其均值为0、标准差为1,使得不同的正态分布可以进行比较和分析。标准化的过程主要是将原始数据减去其均值,再除以标准差,从而获得无量纲化的数值,便于分析和应用。
2.2 偏态分布
偏态分布是相对于正态分布的一种分布形式,特点是其分布曲线不对称。偏态分布在统计学中常见,通常是对连续随机变量的概率分布的一种描述,根据偏斜方向,偏态分布分为:
正偏态:分布曲线右侧较长,左侧较短。数据主要集中在较低的数值区间,但有少量较高的值向右延伸。
负偏态:分布曲线左侧较长,右侧较短。数据集中在较高的数值区间,少量较低的值向左延伸。
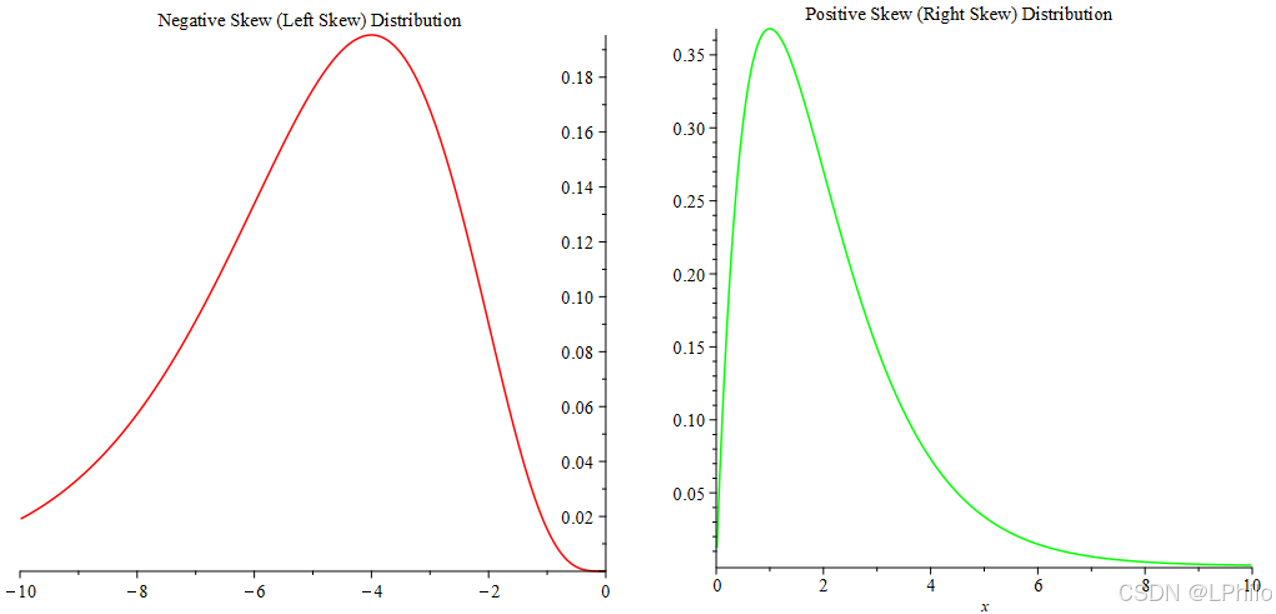
通过偏度和峰度的计算可以定量衡量偏态分布的程度。偏度表示分布的对称性,偏度为正时表示正偏态,为负时表示负偏态;而峰度则描述分布的“尖峭”或“平坦”程度,反映数据的集中或离散情况。
3 频率分析
在SPSS中,频率分析属于描述统计的一部分,它用于统计和显示每个类别或变量值出现的次数和比例。频率分析可以帮助我们快速了解数据的分布情况。描述统计的功能主要集中在“分析”菜单下的“描述统计”子菜单中,该子菜单提供了多种分析工具:
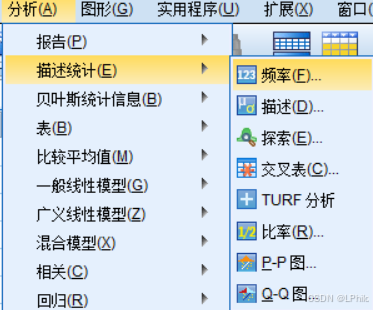
①频率:用于计算数据集中每个值或类别的出现频率和百分比。
②描述:用于生成一组变量的基本统计量,如均值、标准差等。
③探索:帮助深入了解数据分布情况,提供箱线图、均值比较等多种分析工具。
④交叉表:用于显示两个分类变量的分布及其交互关系。
⑤比率:用于计算和分析不同变量之间的比率。
⑥P-P图和Q-Q图:用于评估数据是否符合某种分布,通常用于正态性检验。
4 描述分析
描述命令用于对连续变量进行详细的统计分析,主要包括计算均值、标准差、方差、偏度、峰度等统计量。与频率命令相比,描述命令侧重于提供关于变量的详细统计描述,而不涉及类别数据的频数分布。具体来说:
①均值(Mean):数据的算术平均值。
②标准差(Standard Deviation):数据点相对于均值的离散程度。
③方差(Variance):标准差的平方,反映数据的总体离散程度。
④偏度(Skewness):数据分布的对称性,反映分布的偏斜程度。
⑤偏度(Skewness):数据分布的对称性,反映分布的偏斜程度。
⑥峰度(Kurtosis):数据分布的峰度,反映数据分布的尖峭程度。
⑦标准分(Z-scores):将原始数据转换为标准正态分布中的分数,以便于比较不同数据集的分布。
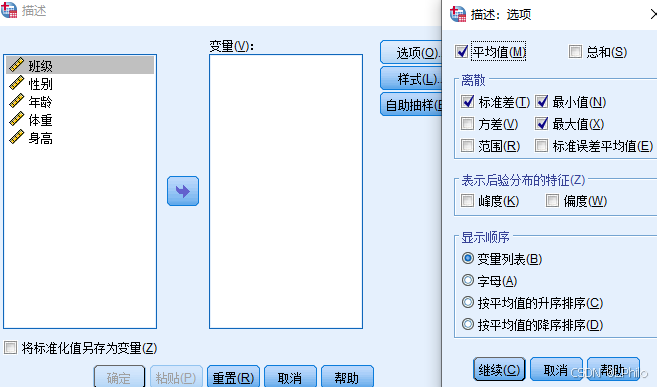
描述命令主要用于分析连续变量的集中趋势和离散程度,并提供转换成标准分的功能,这在频率命令中则不包含。使用描述命令时,您可以获取详细的统计信息和数据的分布特征,但它不包括图表功能,这一点与频率命令的图表功能有所不同。
4.1 标准化(Standardization)
单纯从一组数据的原始数值我们并不能了解这一数值在整个群体中的高低位置。为了反映某数值在一列变量数值中的相对位置,我们通常会将数据转换成标准分数,即Z分数。标准分是将个案的原始数值减去样本的平均值后除以样本的标准差所得到的数值,即它以平均数为参照点,以标准差为单位,其公式如下:
标准分代表个案的数值偏离样本平均值的标准差个数。
利用原始数据我们难以准确判断数据的高低好坏,但是如果把数据都转成标准分,我们就可以对分数做直观的判断了。
标准分取值在[-3,3]之间的面积占99%以上的数据,意味着凡是超出这个取值范围的数据是少见的,被称为极端值。数据中的极端值应该引起我们的重视。前面提到,有一些统计量,如算术平均数,容易受到两端极值的影响,如果我们利用![]() 分数将一些极端值做出筛选,那么分析的结果就会更稳定,也更可靠一些。
分数将一些极端值做出筛选,那么分析的结果就会更稳定,也更可靠一些。
4.2 归一化(Normalization)
归一化是将数据压缩到一个特定的范围(通常是[0,1]或[-1,1])。归一化后,数据的范围一致,但原本的分布信息可能会丢失。归一化的目的是将不同尺度的特征映射到同一范围,归一化的公式为:
5 数据探索
探索模块在SPSS中整合了频率分析和描述性统计功能,目的是在正式进行数据分析之前,帮助用户快速了解数据的基本分布情况,包括集中趋势、离散趋势、分布形态以及极端值的存在。通过探索模块,用户可以输出常见的统计量如平均值、标准差、中位数等,同时还会得到特有的分析结果,如95%的修整均值、极端值、正态性检验以及茎叶图和箱图等图形化展示。
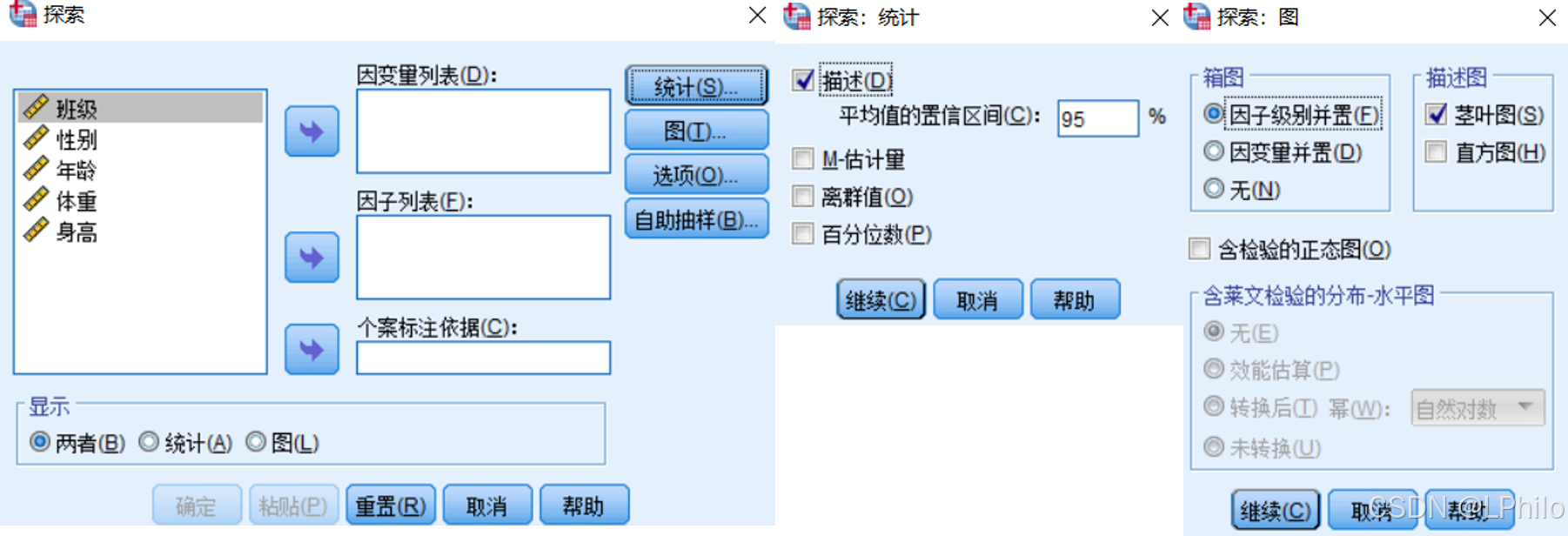
数据探索模块的几个重要功能:
①修整均值:95%的修整均值是将最高和最低各5%的数据剔除后计算的均值,目的是减少极端值对算术平均数的影响,使结果更加稳健。
②正态性检验:探索模块提供了“柯尔莫戈洛夫-斯米诺夫检验”和“夏皮洛-威尔克检验”两种正态性检验方式。如果显著性小于0.05,则表明该变量的数据不服从正态分布。
③极端值分析:通过探索模块,可以识别数据中的极端值,这对于判断数据的离群点非常重要。
④图形展示:茎叶图和箱图能够直观地展示数据的分布形态和离群点,有助于理解数据的整体分布情况。
茎叶图:一种将数据按位数拆分,直观呈现数据分布的统计图表。它通过将数据分为“茎”和“叶”两部分,分别表示数据的主干和尾数,既能显示数据的分布情况,又能保留原始数据的具体取值信息。
茎叶图的优势:
①保留原始数据:与直方图不同,茎叶图不仅展示了数据的分布情况,还完整保留了数据的具体值。
②显示数据频数:每一“茎”上的“叶”数量反映了该范围内数据的频数,因此可以直接从图中读出数据的分布密度。
③转换为直方图:将茎叶图逆时针旋转90度,能够得到类似于直方图的形态,这样可以同时直观理解数据的频数和分布形态。
箱图:一种用于可视化数据分布及检测离群点的统计图表。通过简单的图形表示,箱图能够展示数据的集中趋势、离散程度和对称性,帮助分析数据中的异常值。
箱图的关键元素包括:
①箱体:箱体的上下边分别代表上四分位数(Q3,75百分位数)和下四分位数(Q1,25百分位数),这表明数据分布的中间50%。
②中位数:箱体内部的横线表示数据的中位数(50百分位数),即数据的中心位置。
③四分位距(IQR):上四分位数与下四分位数之差称为四分位距(IQR = Q3 - Q1),用于衡量数据的离散程度。
④内限:箱体上下延伸的“须”表示数据的正常范围,通常为1.5倍IQR范围内的数据。超出此范围的数值称为异常值。
⑤异常值:超过1.5倍IQR之外的点称为异常值,用“○”表示。
⑥极端值:超过3倍IQR之外的点称为极端值,用“*”表示。
箱图的作用:
①展示数据的集中趋势和离散程度。
②检测数据中的异常值和极端值,便于进一步分析。
③可视化数据分布是否对称,帮助发现偏态分布。
6 交叉表分析
交叉表分析用于深入了解多个分类变量之间的关系,通过展示这些变量的交叉频数和百分比,帮助揭示变量之间的相关性或独立性。在实际应用中,交叉表分析不仅提供了单个分类变量的频数,还能够对多个分类变量进行综合分析。例如,如果我们想了解某地区不同民族在不同行业中的分布情况,交叉表分析能够展示每个民族在各行业中的频数及其百分比,这超出了单纯频率分析的范围。
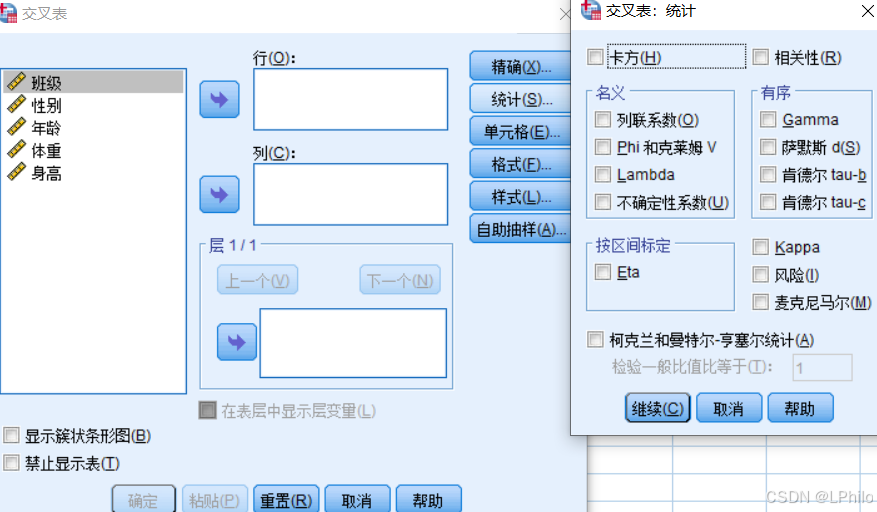
交叉表分析的主要用途包括:
①描述变量间的关系:揭示一个分类变量在不同水平上的分布情况,例如某地区的民族分布在各个行业中的情况。
②分析变量之间的关联性:评估两个或多个离散变量之间的相关性,检测它们是否独立或存在统计上的显著关系。
③检验独立性:利用卡方检验等方法,分析变量之间是否存在依赖关系,从而帮助理解变量之间的交互作用。
交叉表分析提供了一个结构化的方式来探索和理解分类数据之间的复杂关系,是数据分析中重要的一部分。

















 3912
3912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









