







以下针对pytorch版本的Mask-Rcnn,tensorflow版本的可以参考介个Mask RCNN训练自己的数据集——程序调试记录_张十三、的博客-CSDN博客
为啥要提出pytorch版本呢?因为本人换电脑了,显卡升级为30系列,而30系列显卡的 CUDA 版本要求是 11.x ,不能在 tensorflow1.x 上运行。恰巧,之前代码版本是tensorflow 1.13.0的。哎....
本来,尝试用tensorflow2.x 代替 tensorflow1.x,改一下 bug ,结果不一样的地方实在太多,还不好改,于是脱坑,建立 pytorch 版本的 mask rcnn 代码。
参考:https://blog.csdn.net/WYKB_Mr_Q/article/details/127005238
化学实验室自动化 - 1. 深度学习视觉检测(实例分割) - Mask-RCNN模型训练和预测_浙大炼金术士的博客-CSDN博客_maskrcnn预训练模型
代码连接:GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark
一、环境(win11 显卡 RTX 3060 12G)
Python 3.8
cuda 11.6
pytorch 1.12.0+cu116(利用官网语句下载即可)
labelme=5.0.1
二、mmdetection环境搭建
利用mim安装mmcv包:
pip install -U mim
mim install mmcv-full安装mmdet包:
pip install mmdet剩余的包缺什么按什么就可以。
三、数据准备(以coco数据集为例)
- 在 mmdetection-master 目录下新建一个 coco文件夹, 将处理好的 coco 格式数据集,按如下样式放入该文件夹中。( coco 文件夹,coco 文件夹下放 annotations 文件夹和 train, val以及 test文件夹,这三个文件夹下直接是图片。)
- 在mmdetection-master目录下新建 checkpoints 文件夹和 work_dirs 文件夹。

(重点!)自制的数据集,用 labelme 软件标注好,再转化为 coco 数据标注格式就行,数据制作方法参考:https://blog.csdn.net/wangjianwei19911218/article/details/126348135(巨好用!!)
四、源代码修改
4.1 如果是自制的数据集,需要修改数据集的类别名称和类别数量。这里以 mmdetection-master 为根目录,主要修改两个文件:
./mmdetection-master/mmdet/datasets/coco.py
./mmdetection-master/mmdet/core/evaluation/class_name.py
目前我的数据集只有 cow 样本,一个类别要加逗号,因此直接按照我的来: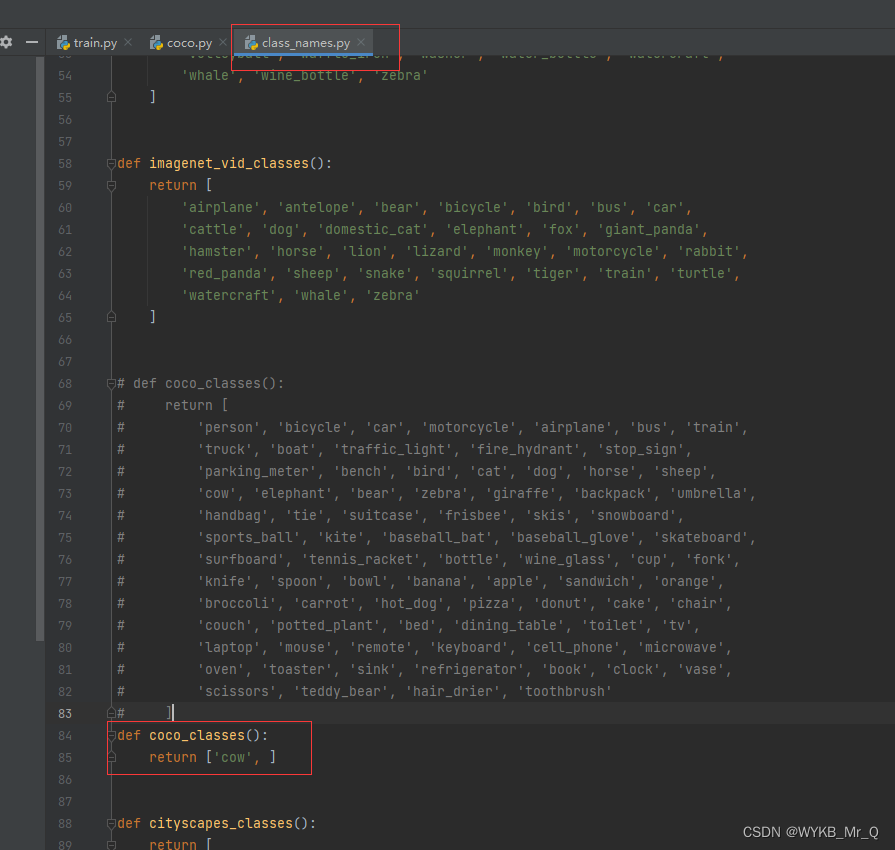
4.2 修改配置文件
首先打开文件配置文件,找到需要修改的文件路径:
./mmdetection-master/configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py
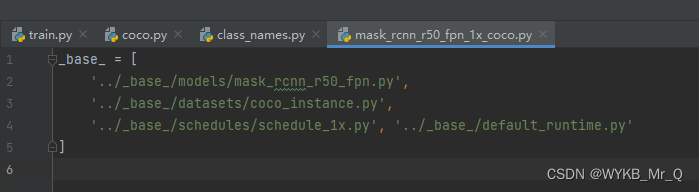
需要对这4个路径中的文件进行一一修改:
(1)修改 mask_rcnn_r50_fpn.py 文件
修改第 47 行和第 66 行的类别数,根据自己的数据集,我的是 1 类。
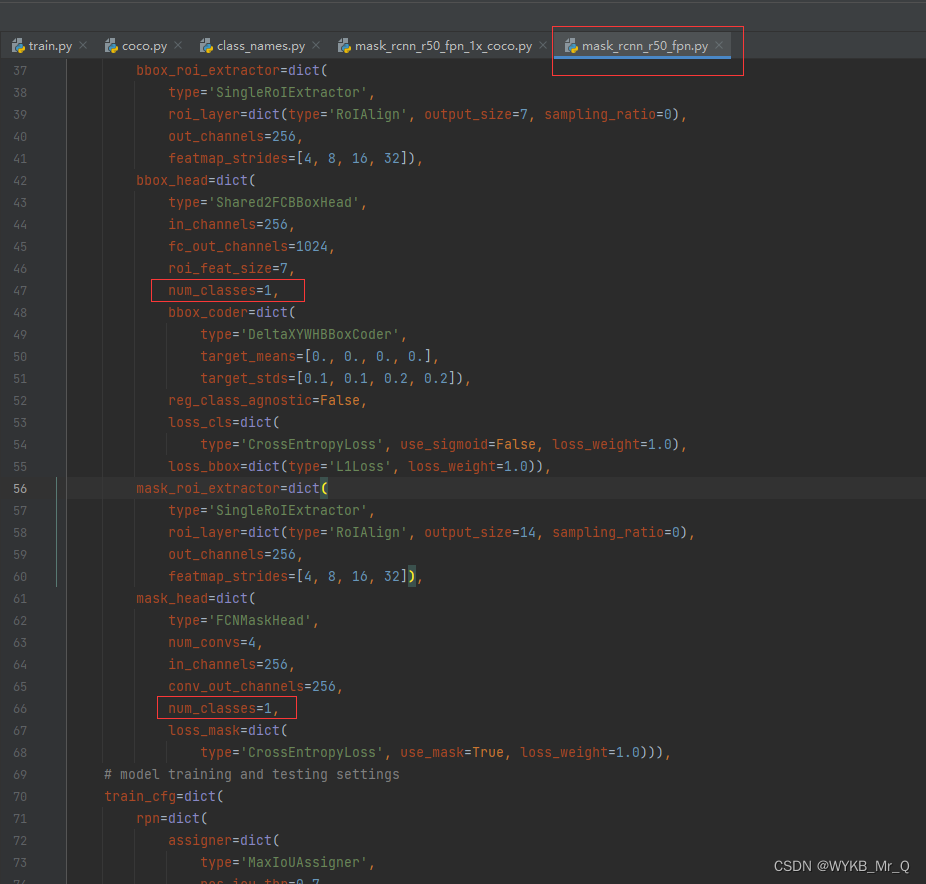
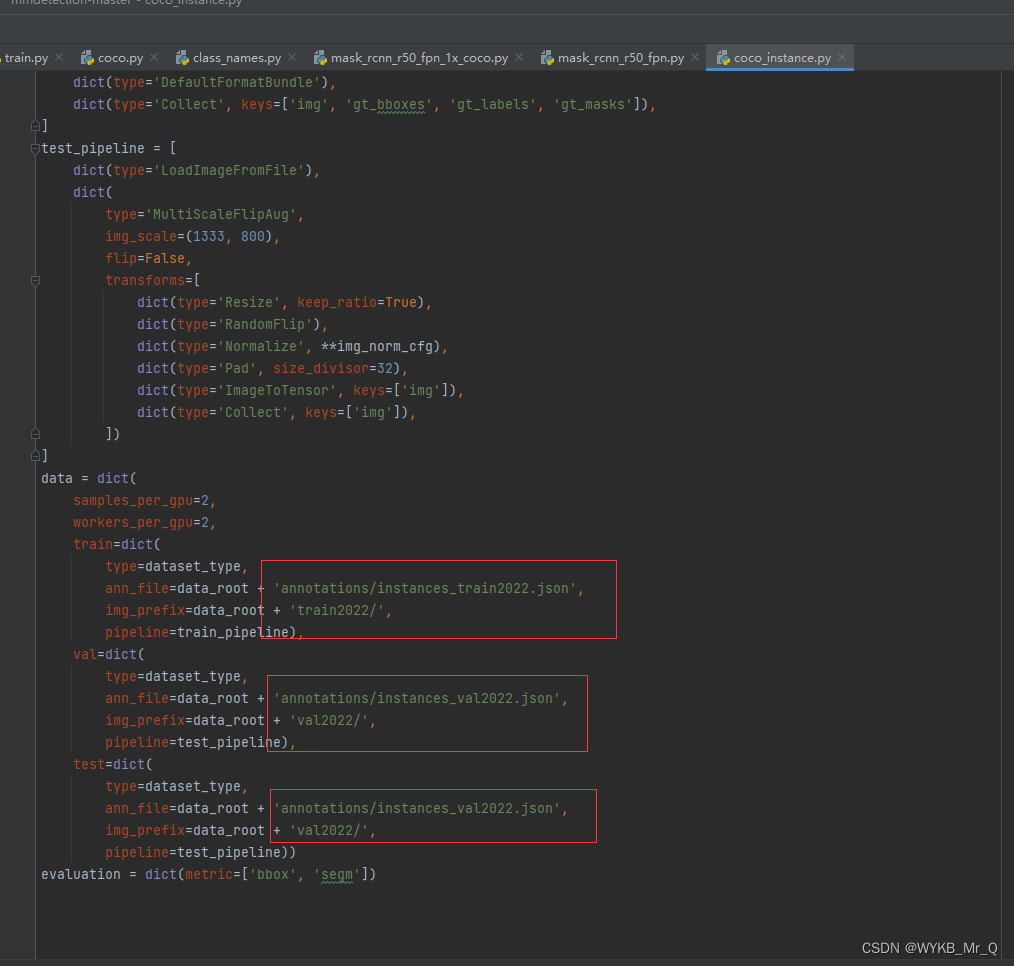
(2)修改 coco_instance.py 文件
data_root 路径改为 ‘ …/data/coco ', 文件路径按我的来。
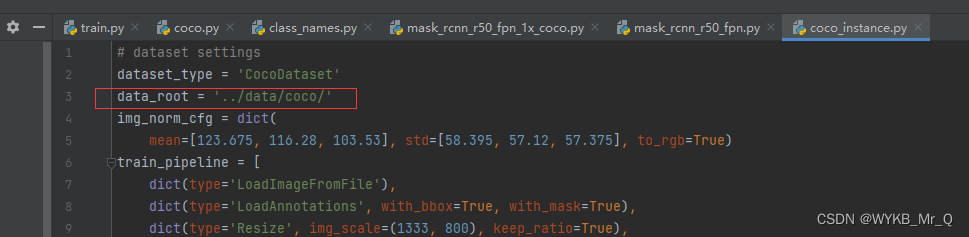
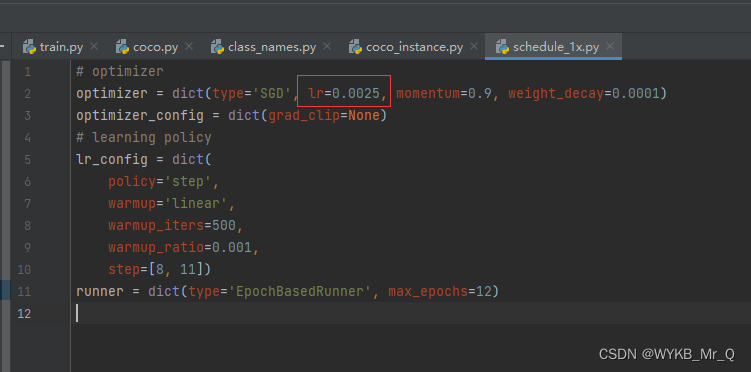
(3)修改 schedule_1x.py 文件
原文中 8 个 GPU,学习率为0.02,咱们一个GPU,因此设为0.0025.
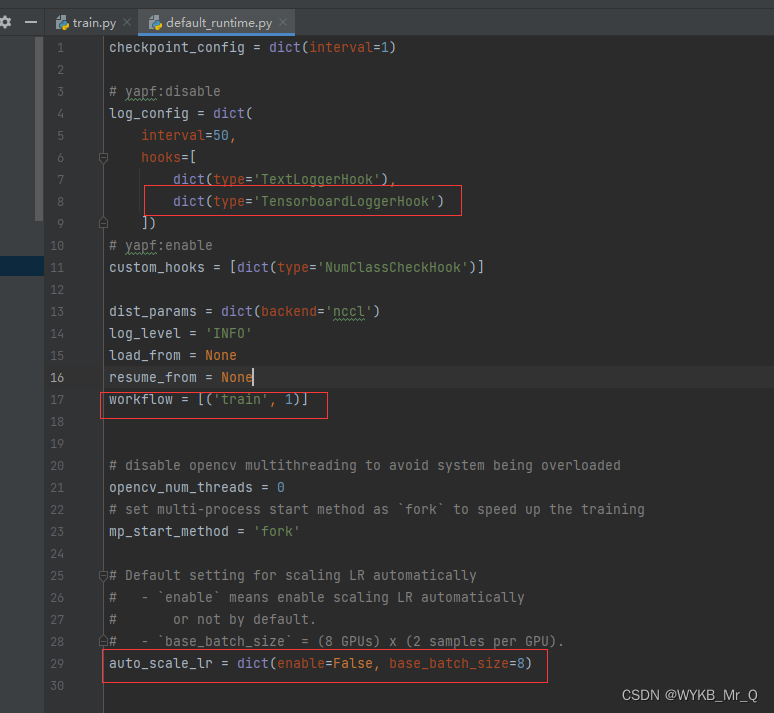
(4)修改 default_runtime.py 文件
我们主要用 tools 文件夹下的 train.py 文件进行训练。
在 pycharm软件下添加文件参数:
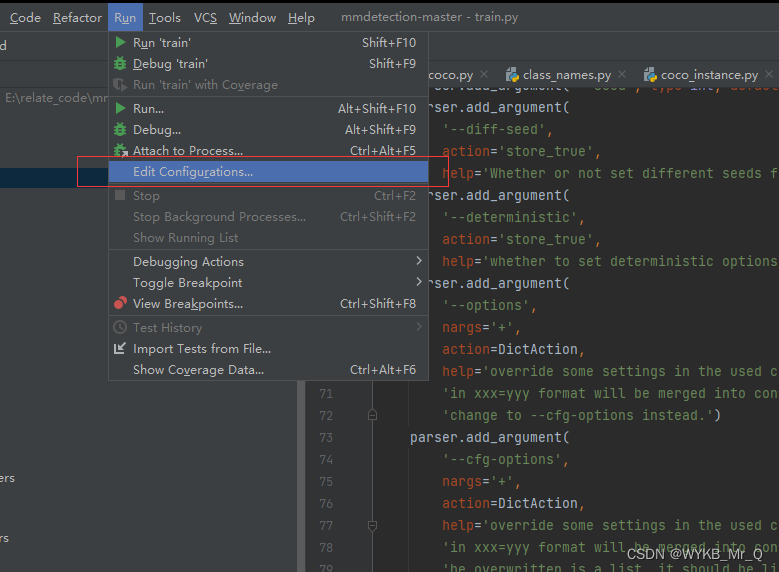
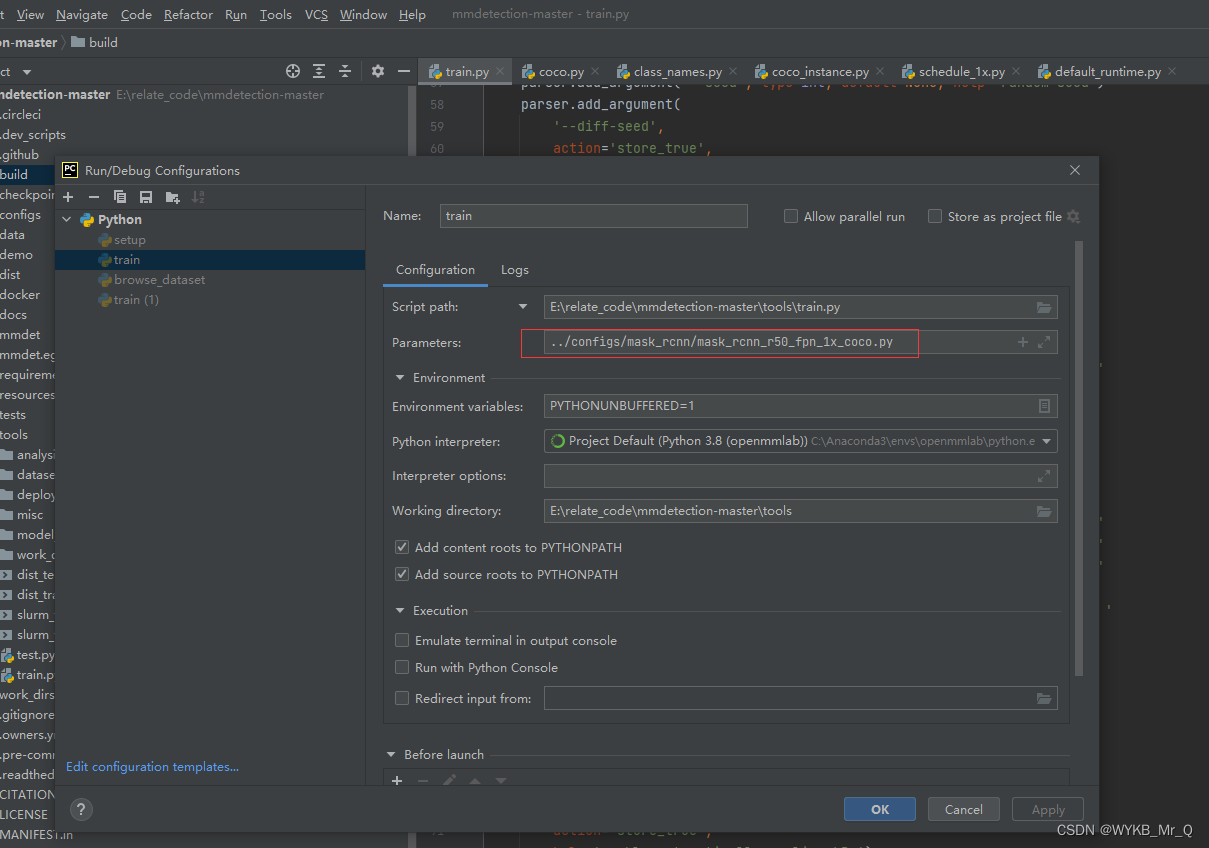
确定,点开始就可以训练了。
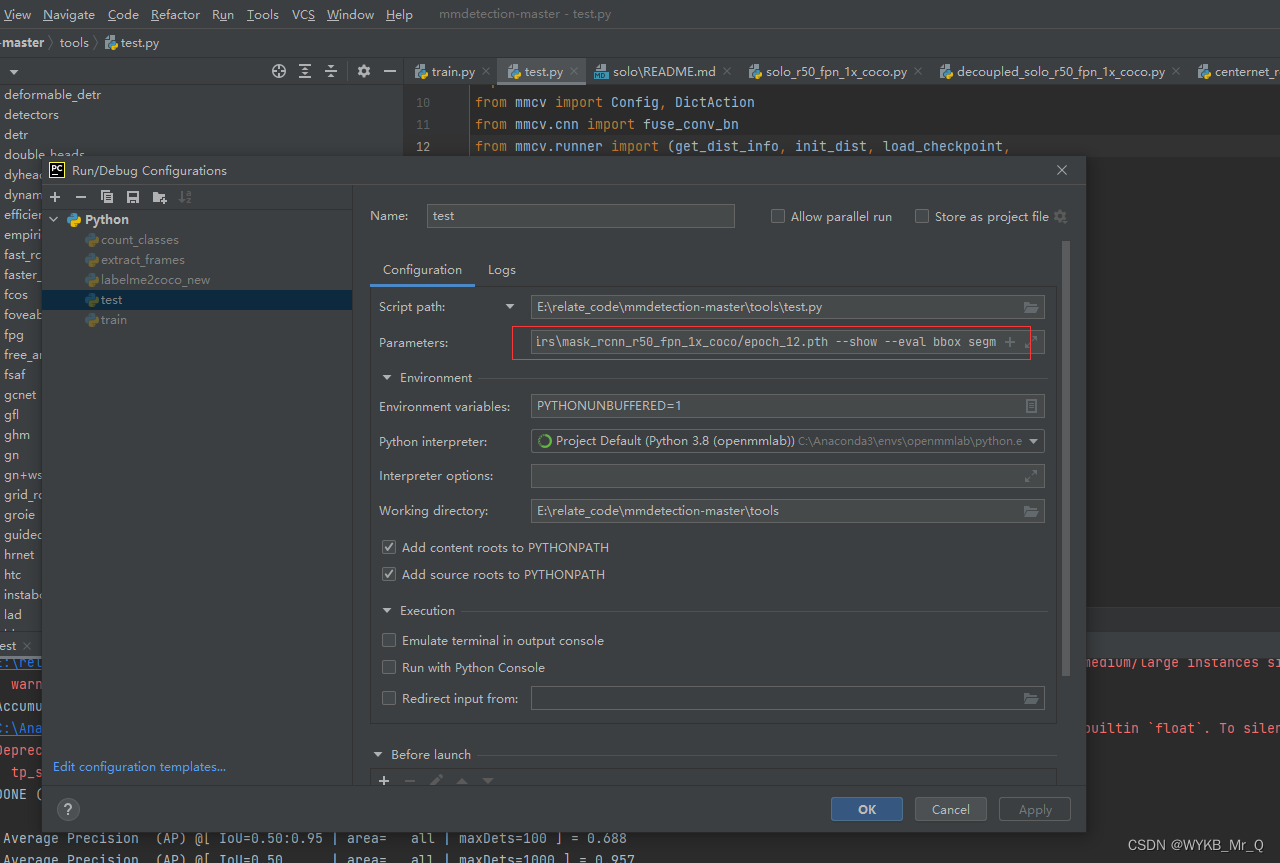
测试时,在config中加入如下代码:
../configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py E:\relate_code\mmdetection-master\tools\work_dirs\mask_rcnn_r50_fpn_1x_coco/epoch_12.pth --show --eval bbox segm
五、bug汇总
1 AttributrError:’ConfigDict‘ object has no attribute ’dataset‘
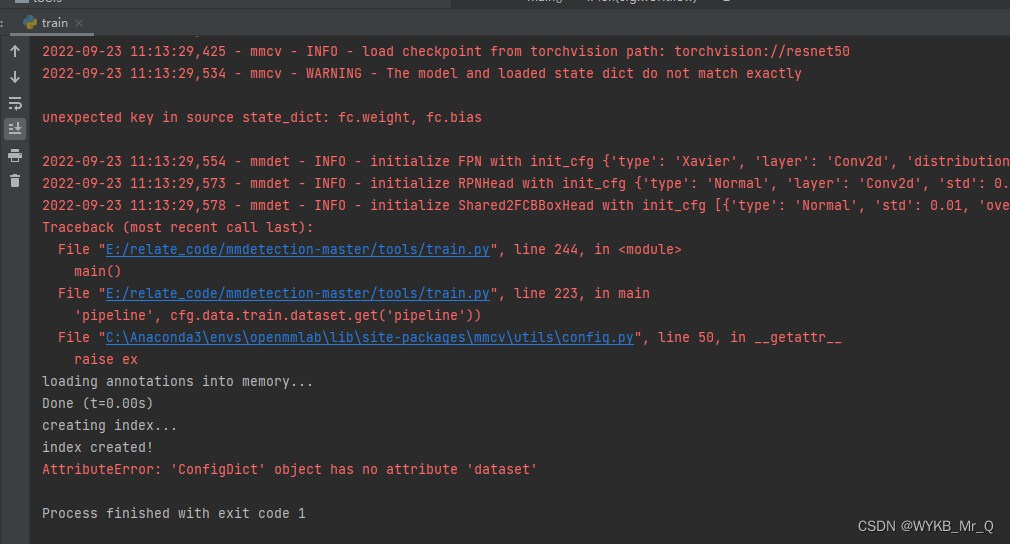
解决方法:
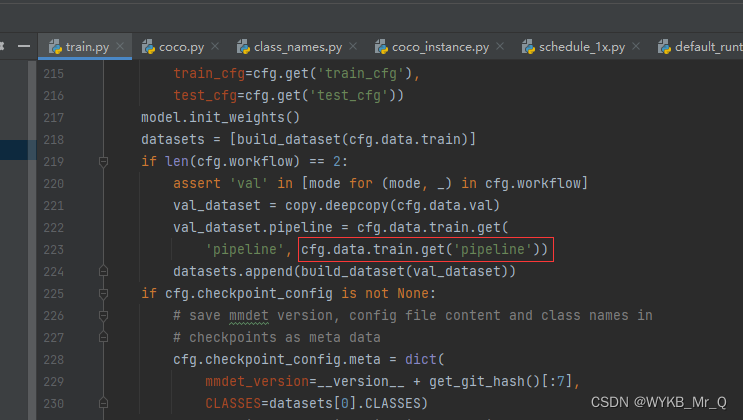
2 ValueError: need at least one array to concatenate
Traceback (most recent call last):
File "tools/train_chicken.py", line 142, in <module>
main()
File "tools/train_chicken.py", line 138, in main
meta=meta)
File "/home/zlee/下载/mmdetection-master/mmdet/apis/train.py", line 111, in train_detector
meta=meta)
File "/home/zlee/下载/mmdetection-master/mmdet/apis/train.py", line 225, in _non_dist_train
runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
File "/home/zlee/.local/lib/python3.5/site-packages/mmcv/runner/runner.py", line 359, in run
epoch_runner(data_loaders[i], **kwargs)
File "/home/zlee/.local/lib/python3.5/site-packages/mmcv/runner/runner.py", line 259, in train
for i, data_batch in enumerate(data_loader):
File "/usr/local/lib/python3.5/dist-packages/torch/utils/data/dataloader.py", line 193, in __iter__
return _DataLoaderIter(self)
File "/usr/local/lib/python3.5/dist-packages/torch/utils/data/dataloader.py", line 493, in __init__
self._put_indices()
File "/usr/local/lib/python3.5/dist-packages/torch/utils/data/dataloader.py", line 591, in _put_indices
indices = next(self.sample_iter, None)
File "/usr/local/lib/python3.5/dist-packages/torch/utils/data/sampler.py", line 172, in __iter__
for idx in self.sampler:
File "/home/zlee/下载/mmdetection-master/mmdet/datasets/loader/sampler.py", line 63, in __iter__
indices = np.concatenate(indices)
ValueError: need at least one array to concatenate解决方案:检查自己的Classname也就是修改源代码的第一步两个文件是不是同json文件中的label一致,我的是因为json中的label是”1“,而Classname=(cow,)不一致才出现报错,将其修改为(’1‘,)后可正常运行。
















 3192
3192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











