








🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

目录
一、Python处理Excel
-
Python处理Excel的好处
-
开源库支持:Python 有许多开源库(例如 openpyxl、xlrd、xlwt、pandas 等)可以用于读取、写入和操作 Excel 文件,这些库丰富而强大,支持各种 Excel 格式,包括 .xls 和 .xlsx。
-
数据处理能力:Python 具有强大的数据处理能力,可以轻松地从 Excel 文件中提取、转换和操作数据,包括数据清洗、筛选、合并、计算和可视化。
-
自动化:Python 可以用于自动化 Excel 任务,例如批量处理多个 Excel 文件,根据特定条件过滤和修改数据,自动生成报告和图表,以及自动发送电子邮件等。
-
与其他库集成:Python 可以与其他数据处理和分析库(如 NumPy、pandas、Matplotlib 等)无缝集成,使您能够在 Excel 数据上执行更复杂的分析和可视化。
-
跨平台性:Python 是跨平台的,可以在 Windows、Mac 和 Linux 等操作系统上运行,因此可以轻松地处理来自不同平台的 Excel 文件。
-
社区支持和文档:Python 社区非常庞大,有大量的文档、教程和示例代码可供学习和参考,帮助您解决与 Excel 处理相关的问题。
-
可扩展性:如果标准库中的功能不足以满足您的需求,您还可以使用其他第三方库来扩展 Python 的 Excel 处理功能,或者编写自定义脚本来执行特定的操作。
-
Python处理Excel主要有三大类库
-
openpyxl:
- 优势:openpyxl 是一个功能丰富的库,用于读取、写入和编辑 Excel 文件,特别适用于处理 .xlsx 格式的文件。它支持大多数 Excel 功能,包括工作表的创建、修改、格式化,单元格内容的读取和写入,以及图表的创建。
- 适用场景:如果您需要与 Excel 2007及更高版本的 .xlsx 文件进行交互,openpyxl 是一个很好的选择。
-
xlrd 和 xlwt:
- xlrd 用于读取 Excel 文件,而 xlwt 用于创建和写入 Excel 文件,主要支持 .xls 格式。
- 优势:虽然这两个库在处理 .xlsx 文件方面不如 openpyxl 强大,但它们在处理早期版本的 Excel 文件(.xls 格式)方面非常有用,而且它们简单易用。
- 适用场景:当您需要与较早版本的 Excel 文件进行交互时,或者需要在读取和写入操作中保持兼容性时,可以考虑使用这些库。
-
pandas:
- 优势:pandas 是一个强大的数据分析库,可以轻松地处理各种数据,包括从 Excel 文件中读取数据。它可以读取和写入 Excel 文件,支持 .xls 和 .xlsx 格式,并提供了丰富的数据处理和分析功能。
- 适用场景:pandas 特别适合在数据分析、数据清洗、数据转换和数据可视化等任务中处理 Excel 数据。它使得在 Python 中进行复杂的数据操作变得容易。
-
开发环境
操作系统:使用windows
Python版本:系统中需要安装Python3.8以上的版本
开发工具:选择 jupyter notebook
二、在Excel中按条件筛选数据并存入新的表
技术工具:
Python版本:3.9
代码编辑器:jupyter notebook
去年领用物料情况记录在278张Excel表中,老板希望按领用量从高到低排序并查看前10种领用最多的物料。手动操作需要合并表格并使用数据透视表,Python的pandas库可快速高效处理数据,演示如何用它统计一个Excel工作簿中278张表的数据并汇总排序。
import pandas as pd然后我们先用`pd.read_excel()`打开第一张工作表,试试水,打开后存入变量`df`。传入要打开的工作簿,即`'日领料单.xlsx'`。数据的字段名在第三行,指定`header=2`。因为header是用0表示第一行,所以第三行对应的索引为2。第一张表的名称叫`01-03`,所以指定参数`sheet_name = '01-03'`。打开后,用`df.head()`看一下效果,这个函数值看头几行数据,括号内不填具体数量,则默认头五行。相对应的,`df.tail()`则是看末尾5行。
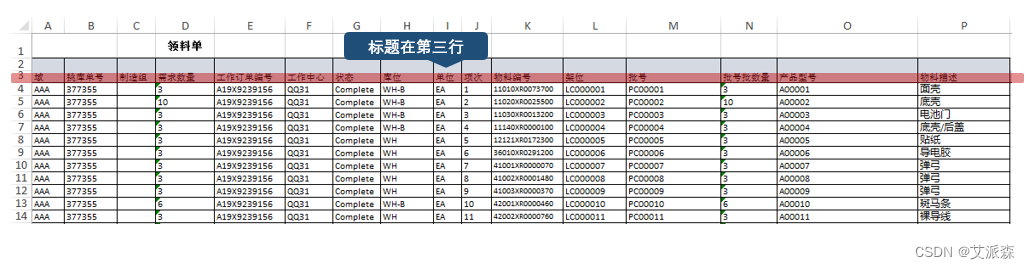
df = pd.read_excel('日领料单.xlsx' ,header=2, sheet_name = '01-03')
df.head()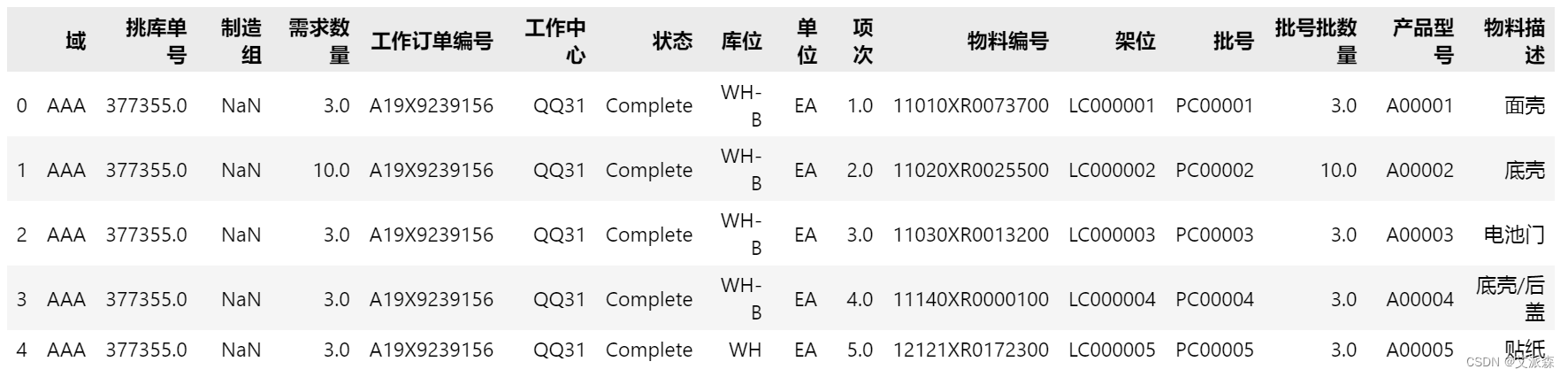
数据显示与Excel表中完全一致,那就可以开始下一步了,即按照“物料编号”和“物料描述”字段将“批号批数量”加总。这里将使用到`groupby()`,它的作用是分组聚合,有点类似数据透视表中的“行”。此处我们按“物料编号”和“物料描述”分组聚合数据,并按“批号批数量”加总`['批号批数量'].sum()`。因为汇总数据后,行会减少(从191行减少到163行),所以需要重设行编号`reset_index()`,按0~162重新编号。
#按物料编号加总领料数量
df_sum = df.groupby(['物料编号','物料描述'])['批号批数量'].sum().reset_index()
df_sum.tail() #看尾部5行的数据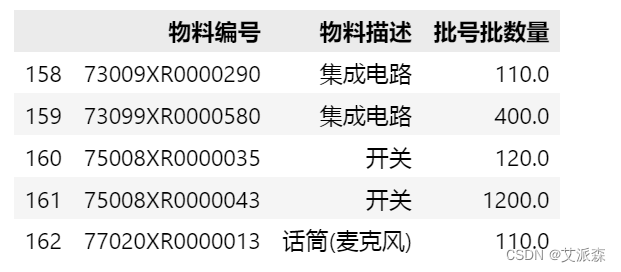
然后我们用`sort_values()`排序,排序规则是从大到小`ascending = False`,并看前10项的数据`head(10)`。这个跟Excel中的数据透视表得到的结果完全一致。
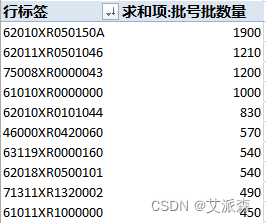
df_sum.sort_values('批号批数量',ascending = False).head(10)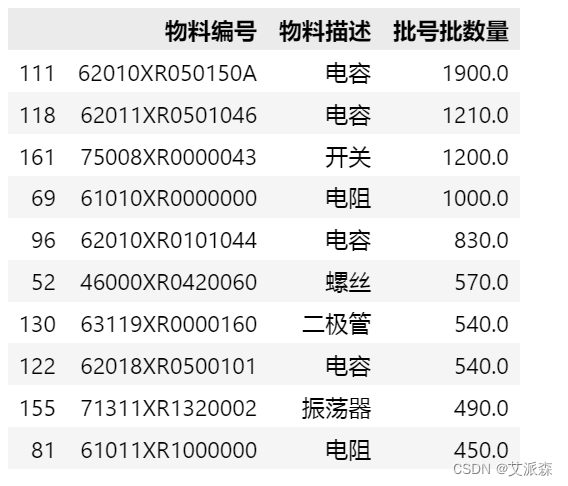
以上,是对单个工作表的处理,下面我们用同样的方式遍历全部278张工作表,然后汇总数据。先新建一个空的数据框`result`,用于存储汇总所有工作表的结果。然后通过传入参数`sheet_name = None`(即不指定工作表,则全部读取),读取整个Excel文件中的所有工作表。然后按工作表名遍历所有工作表,分组聚合,加总“批号批数量”,将汇总后的数据框`df_sum`通过连接函数`concat`增加到`result`中。在此处,`concat`有点类似于列表中的`append`增加元素的功能,这里增加的是DataFrame。其作用的示意图如下。
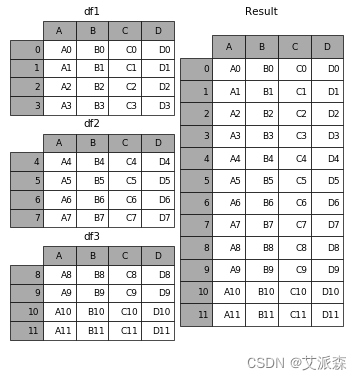
#新建一个DataFrame用于存储汇总所有工作表的结果
result = pd.DataFrame()
#读取整个Excel文件中的所有表
df = pd.read_excel('日领料单.xlsx', header=2, sheet_name = None)
#按表名遍历,处理数据
for sheet_name in df.keys():
#按物料编号加总领料数量
df_sum = df[sheet_name].groupby(['物料编号','物料描述'])['批号批数量'].sum().reset_index()
result = pd.concat([result,df_sum])
result.head()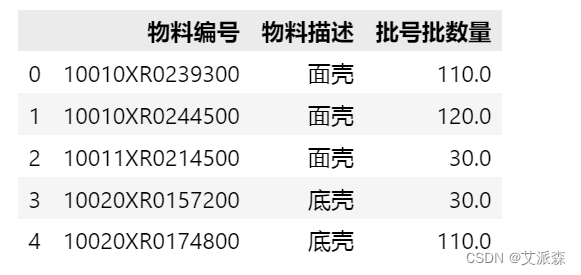
以上,`df.keys()`存有所有工作表名,共278个。通过`for`循环逐个从其中取出名字,然后通过名字读取数据及汇总。
df.keys()
数据汇总在一起后,需要再最后分类汇总一下(因为每天领取的物料是有重复的,需要将相同物料编号对应的数量加总),并降序排序。最终得到领用量最多的10个物料。
final = result.groupby(['物料编号','物料描述'])['批号批数量'].sum().reset_index().sort_values('批号批数量',ascending = False)
final.head(10) 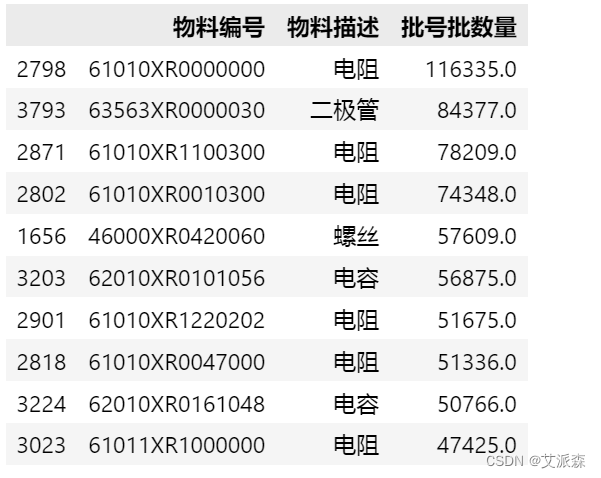
我们还可以将最终结果保存为Excel文件,以便在Excel中操作。
final.to_excel("汇总.xlsx")三、往期推荐
四、文末推荐与福利
《AI时代程序员开发之道》免费包邮送出3本!

内容简介:
《AI时代程序员开发之道:ChatGPT让程序员插上翅膀》是一本介绍如何使用ChatGPT的实用手册,它建立了一个新的程序员开发模式。《AI时代程序员开发之道:ChatGPT让程序员插上翅膀》从介绍 “ChatGPT第一次接触”开始,深入分析如何使用该工具来提高开发效率和质量。《AI时代程序员开发之道:ChatGPT让程序员插上翅膀》的每一章都涵盖了ChatGPT的不同应用场景,从编写各种文档,到辅助进行需求分析和系统设计,以及数据库设计和开发高质量代码等,均有详尽的讲解。读者将从中了解到,如何利用ChatGPT这一AI工具来辅助程序员更加高效地开发软件。
《AI时代程序员开发之道:ChatGPT让程序员插上翅膀》还特别介绍了如何使用ChatGPT辅助进行系统测试以及任务管理,并对源代码底层逻辑进行了深入分析。这个全面的框架将帮助读者在软件开发过程中更好地管理和优化代码。最后,《AI时代程序员开发之道:ChatGPT让程序员插上翅膀》以两个实战案例作为结尾:第一个是使用ChatGPT辅助开发PetStore宠物商店项目,第二个是使用ChatGPT辅助开发“我的备忘录”App。这两个实战案例将会帮助读者更好领悟如何将ChatGPT引入具体的软件开发中。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-10-14 20:00:00
名单公布时间:2023-10-14 21:00:00


















 1675
1675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











