








🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
摘要
随着时代的发展,人们对生活品质的要求不断提高,更加追求健康的生活方式。近年来,随着水果茶消费需求激增,将年轻消费者喜爱的水果饮品与中老年消费者偏好的茶以一种喜闻乐见的方式结合起来,开辟了传统茶饮的新市场。在传承与创新中,水果茶饮接受着消费浪潮的助推迅速崛起,越来越成为符合人群消费需求的新饮品品类。但目前水果茶饮品市场为使得水果茶茶饮从视觉效果上看起来更富有层次感,使口感和味道更加丰富,多数传统现制茶饮通过简单“堆料”来吸引消费者;且为了压缩原料成本,商家多使用水果罐头等水果加工品而不采用新鲜水果,使得消费者出于对原生本味和天然健康的追求难以被满足。本次实验使用因子分析对水果茶调查问卷中的一道量标题进行分析,最终用两个因子品质追求型和品牌效益型来表示量表题的9个因子。
1.项目背景
1.中国水果茶文化背景
中国是茶的故乡,无论是文人骚客的“琴棋书画诗酒茶”,还是普通百姓的“柴米油盐酱醋茶”,茶都是必不可少的。在中国饮食历史上,茶和果有着密切的联系。早在魏晋南北朝时期就出现了“茶果”这一名词,既指饮茶时以果为茶食,也指以果入茶的茶叶饮用方式。饮茶时用各种果品作为茶食在历代典籍中多有记载。《晋书》载,东晋桓温“每宴惟下七奠,拌茶果而已”。吴兴太守陆纳招待谢安将军时也只是“所设惟茶果而已”。唐代以后以果佐茶更为普遍,如韦应物“茶果邀真侣,觞酌洽同心”,陆游“瓜冷霜刀开碧玉,茶香铜碾破苍龙”都描述了以茶待客,以果伴茶的情景。以果入茶的茶叶饮用方式在魏晋南北朝就已形成,这是现代水果茶的雏形。以果品入茶的记载在元代杂剧中频繁出现,有茶中放乌梅煎制的“梅茶”、茶汤中加杏仁等果干的“杏汤”、加木瓜的“木瓜茶”、用荔枝调制的“荔枝膏茶”、以橙子的果肉调制的“金橙茶”等。可以说,元代用各种果品调制茶汤已经相当普遍。以果入茶的饮茶方式一直流传至今,果品越来越丰富,茶饮形式也越来越多样,逐渐形成现在的新式水果茶。
2.水果茶饮品已成为当代潮流
随着时代的发展,人们对生活品质要求不断提高,追求更加健康的生活方式,而饮品作为一种生活消费的必需品,也被人们赋予了更高要求与期望。在传承与创新中,新式茶饮接受着消费浪潮的助推迅速崛起,越来越成为符合人群消费需求的新饮品品类。而水果茶饮品因其以鲜果及原叶茶作为原材料的特点,极大满足了人们对饮品的口感丰富、原料健康的预期要求,受到了大量消费者的喜爱与追捧。
水果茶的大热也在于它打破了以往新老消费者市场的明显界限,将年轻消费者喜爱的水果饮品与中老年消费者偏好的茶以一种喜闻乐见的方式结合起来,开辟了传统茶饮的新市场。水果茶不仅将茶饮转变成为了一种“续命神器”,更让其成为了一种消费热点、社交文化。喜茶、奈雪、茶颜悦色等全国知名茶饮店不断推陈出新,开辟出一系列高颜值、好口感的水果茶产品板块,如以霸王桶装水果茶作为产品核心的凝萃水果茶,无一不在将水果茶推向潮流顶端,无一不在改变着人们对于茶饮的传统认知。现在,水果茶饮品在人们的生活中已经越来越常见、越来越受欢迎,甚至成为了中老年人尝鲜的首选饮品与年轻人“养生局”的必备饮品。针对消费市场的高需求,水果茶的品质也将面临更高考验,因此水果茶原料的品质以及新鲜程度严重影响着水果茶行业的发展。如何选择质优量大价格优惠的果品、茶品也成为了水果茶商家关注的核心问题。
2.项目简介
2.1数据集介绍
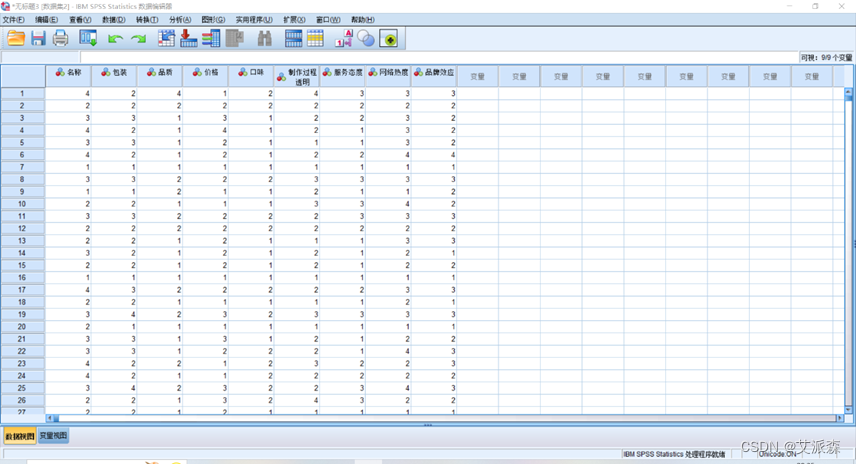
本次数据集来源于天池网,数据集是一份关于水果茶调查问卷中的一道量表题数据 ,共有1381条数据, 9个维度,每个维度值范围为1-5,具体信息如下表:
| 属性名称 | 数据类型 |
| 名称 | Int整数类型 值范围1-5 |
| 包装 | Int整数类型 值范围1-5 |
| 品质 | Int整数类型 值范围1-5 |
| 价格 | Int整数类型 值范围1-5 |
| 口味 | Int整数类型 值范围1-5 |
| 制作过程透明 | Int整数类型 值范围1-5 |
| 服务态度 | Int整数类型 值范围1-5 |
| 网络热度 | Int整数类型 值范围1-5 |
| 品牌效应 | Int整数类型 值范围1-5 |
2.2技术工具
SPSS数据分析软件
3.算法理论
因子分析(Factor Analysis)是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。
例如,在企业形象或品牌形象的研究中,消费者可以通过一个由24个指标构成的评价体系评价百货商城的24个方面的优劣。但消费者主要关心三个方面,即商店的环境、商店的服务和商品的价格。因子分析方法可以通过24个变量找出反映商店环境、商店服务水平和商品价格的3个潜在的因子,对商店进行综合评价。这3个公共因子可以表示为:
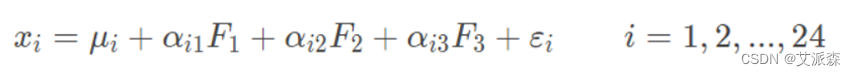
1.因子分析与主成分分析的区别
主成分分析仅仅是变量变换,而因子分析需要构造因子模型。
因子分析:潜在的假想变量和随机影响变量的线性组合表示原始变量。
主成分分析:原始变量的线性组合表示新的综合变量,即主成分。
因子分析数学模型
假设有P个变量X,有m个因子(m≤p),则因子分析的数学模型可以表示如下:
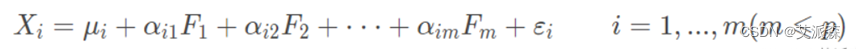
2.因子旋转
若因子分析中得出的各个因子有明确的含义,则因子分析的模型会更加易于解释和有实际意义。在因子分析中可以对因子载荷矩阵进行旋转,使每个变量仅在一个公共因子上有较大的载荷,而在其余的公共因子上的载荷比较小。通过旋转,因子可以有更加明确的含义。常用的一种方法是方差最大旋转。
3.因子得分及其计算
前面我们主要解决了用公共因子的线性组合来表示一组观测变量的有关问题。如果要使用这些因子做其他的研究,比如把得到的因子作为自变量来进行回归分析,对样本进行分类或评价,就需要计算每个个体在每个因子上的得分。
要计算因子得分,需要估计以下表达式:
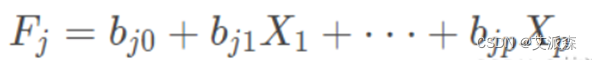
4.因子分析的步骤
因子分析解决的3个基本问题:
因子载荷阵A的估计
当因子难以得到合理的解释时,对因子载荷阵进行正交变换,即因子旋转。对因子的实际意义做出合理的解释。
给出每个变量(或样品)关于m个公共因子的得分,通常表示为原始变量的线性组合,即因子得分函数。对公共因子做出估计。
因子分析的步骤:
(1)根据问题选取原始变量。
(2)求其相关阵R,探讨其相关性,
(3)从R求解初始公共因子F及其因子载荷矩阵A(主成分法)。
(4)因子旋转,分析因子的含义。
(5)计算因子得分函数。
(6)根据因子得分值进行进一步分析(例如综合评价)。
5.因子分析与主成分分析的区别和联系
(1)因子分析、主成分分析都是重要的降维方法(即数据简化技术),因子分析可以看作主成分分析的推广和发展。
(2)主成分分析不能作为一个模型来描述,它只能作为一般的变量变换,主成分是可观测的原始变量的线性组合。因子分析需要构造因子模型,公共因子是潜在的不可观测的变量,一般不能表示为原始变量的线性组合。
(3)因子分析是用潜在的、不可观测的变量和随机变量的线性组合来表示原始变量,即通过这样的分解来分析原始变量的协方差结构(相依关系)。
4.实验过程
4.1数据探索
首先使用SPSS软件打开数据集如下:
查看数据描述性统计

从描述性统计中我们可以看出每个变量的个数总计、最大最小值、合计总数、均值、标准差、方差、偏度和峰度等信息。
4.2因子分析
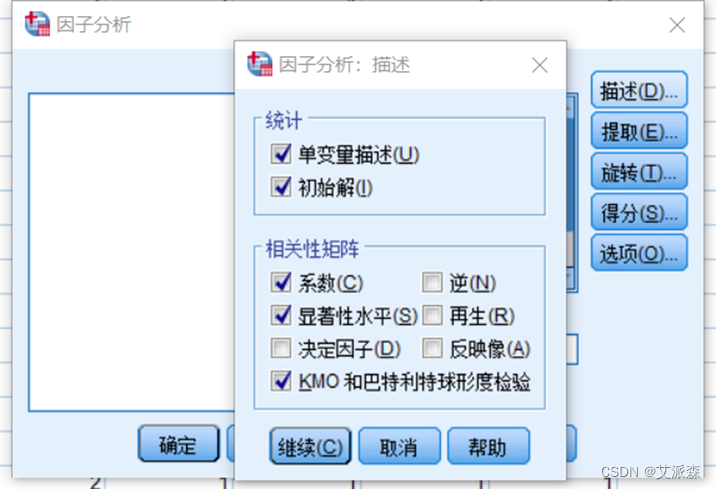

结果如下:
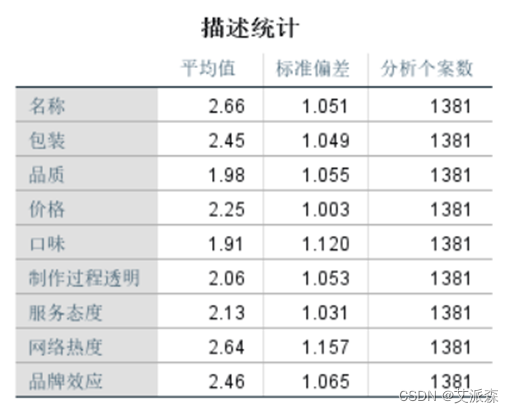
从描述性统计结果中我们可以看见每个变量的平均值、标准偏差、个案数等信息。
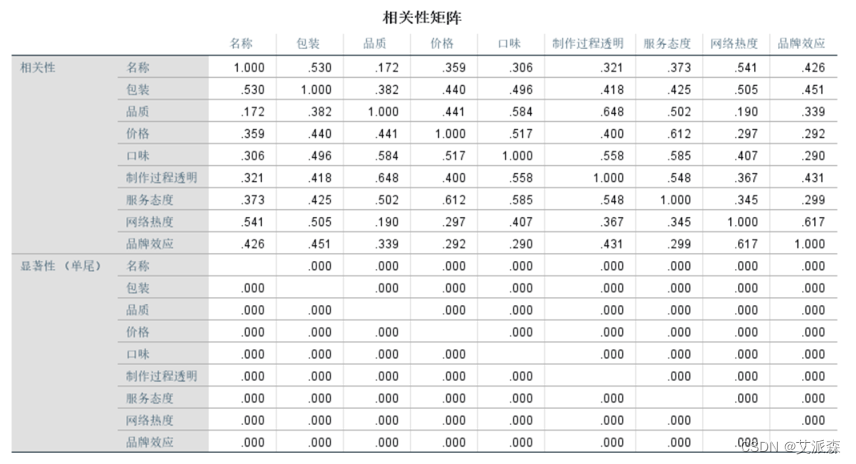
从相关性矩阵中可以看到,每个变量与每个变量之间的相关性高。如从表中可以看到包装与名称的相关系数是 0.530。从显著性值可以看每个变量与每个变量之间是否显著相关。如包装和名称的显著性0.000<0.05,说明这两个变量相关性显著。从表中发现全部的概率P值都是小于 0.05的,说明这些变量之间相关性显著。

KMO 检验统计量是用于比较变量间简单相关系数和偏相关系数的指标。主要应用于多元统计的因子分析。KMO 统计量是取值在0和1之间。0.9 以上表示非常适合;0.8 表示适合;0.7 表示一般;0.6 表示不太适合;0.5 以下表示极不适合。对于此实验的KMO值为0.846说明数据适合做因子分析。从巴特勒球形检验看出显著性水平为0,小于0.05,拒绝原假设,综合这两个结果,说明此数据很适合做因子分析。
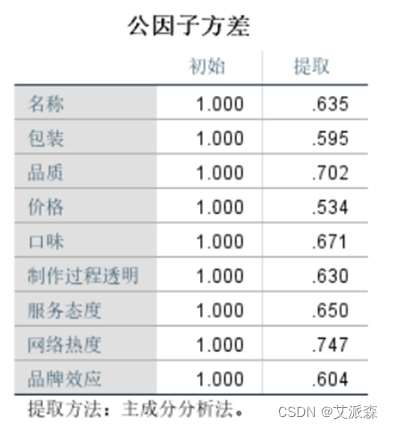
从公因子方差表中可以看到提取值都比较高,表明变量中大部分信息能被因子所提取,说明因子分析结果有效。
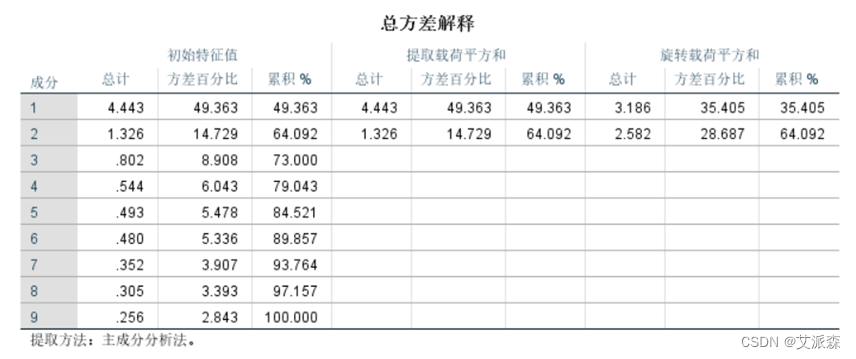
总方差解释图表,也称主成分列表。一个因子所解释的方差比例越高,这个因子包含原有变量信息的量就越多。第一个成分的初始特征值为4.443能解释的方差比例为49.363%,第二个特征 值为1.326,能解释的方差比例为14.729。其余成分都小于1,说明这几个成分的解释力度还不如直接引入原变量大。这九个变量只需要提取出头两个成分即可。
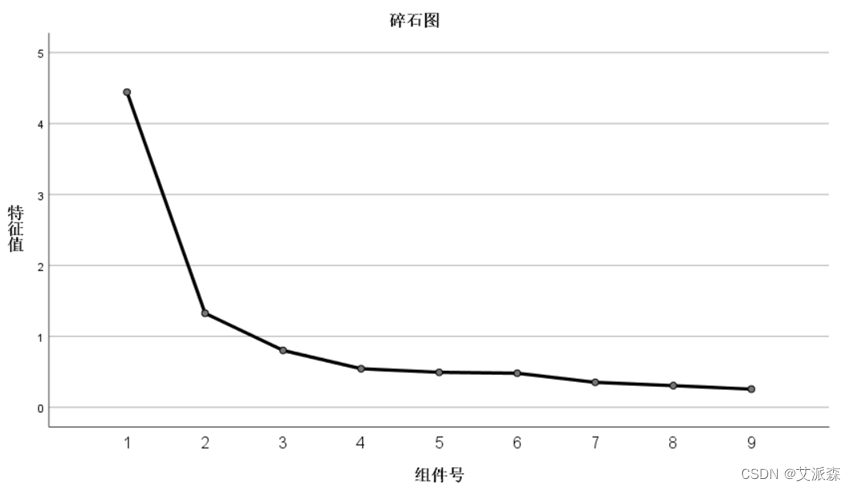
碎石图中,从第二个成分以后的特征值就降得非常低。第二个成分就是这一图形的“拐点”。在这一实例中,只需要提取两个主要成分就行了。
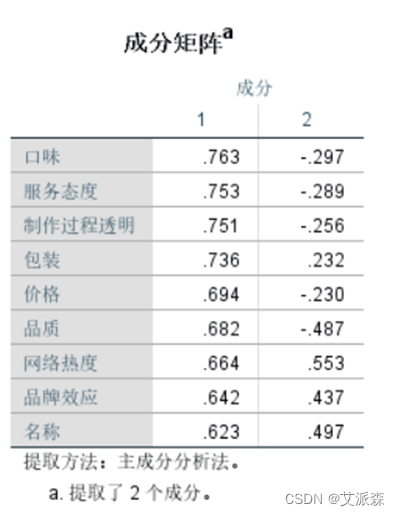
表中列出未使用旋转方法时使用因子能解释的各个变量的比例(各变量的信息被主成分提取了多少)
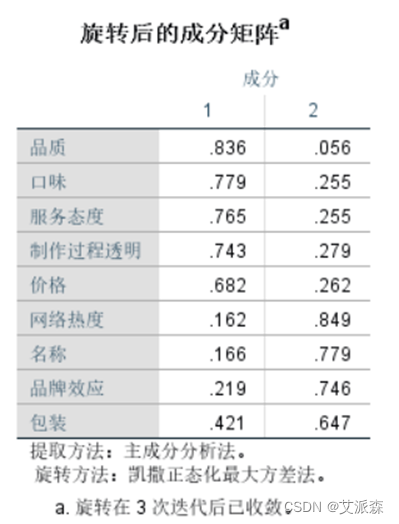
表中列出了使用旋转方法后因子能解释的各个变量的比例。和上面未旋转对比可以看出,旋转后,原先较大的比例值仍然大,较小的比例则变得更小。
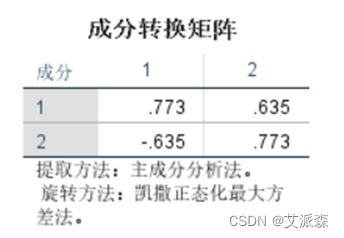
成分转换矩阵表,用来说明旋转前后主成份间的系数对应关系。
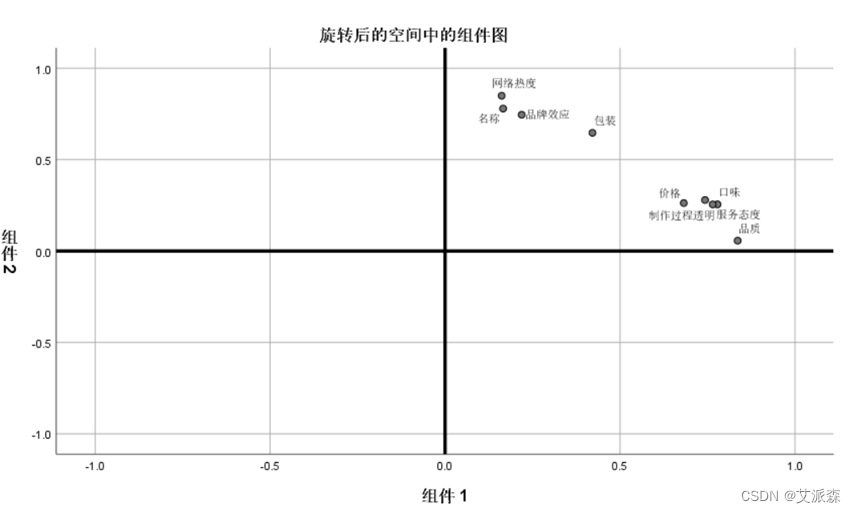
从旋转后的空间中的组件图中可以看到,网络热度、名称、品牌效应、包装属于一类成分,其余属于另外一类。
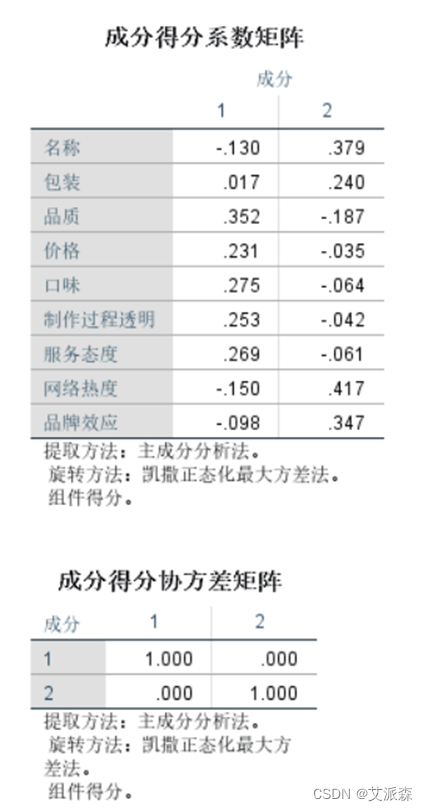
4.3因子命名
通过以上的因子分析,我们可以看出,品质、价格、口味、制作过程透明、服务态度归属到一类因子,我们可以命名为“品质追求型”;将名称、包装、网络热度、品牌效应命名为“品牌效益型”。
5.总结
通过本次因子分析实验,我们将一份关于水果茶调查问卷中的一道量表题9个维度的数据,最终用了两个因子来表示,用品质追求型因子来表示品质、价格、品味、制作过程透明和服务态度这几个因子,用品牌效益型来表示名称、包装、网络热度、品牌效应这几个因子。
资料获取,更多粉丝福利,关注下方公众号获取




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











