










🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
一、引言
随着信息技术的快速发展和互联网的普及,人们的生活方式发生了巨大的变化。特别是在餐饮行业,越来越多的消费者选择通过在线平台进行食品订购,这种趋势使得在线食品订单数据呈现出爆炸式的增长。这些数据中蕴含着丰富的消费者行为、市场趋势和商家运营策略等信息,对于餐饮企业和研究机构来说,具有重要的价值。因此,本研究旨在通过对在线食品订单数据进行可视化分析和建模分类,以揭示其中的潜在规律和价值,为餐饮行业的发展提供有力支持。
二、研究背景
1.在线食品订购市场的快速增长
近年来,随着移动互联网的普及和消费者生活节奏的加快,在线食品订购市场呈现出迅猛的增长态势。越来越多的消费者选择通过手机或电脑进行食品订购,享受便捷、快速的用餐体验。这种趋势使得在线食品订单数据呈现出大规模、高频率的特点,为数据分析和挖掘提供了丰富的素材。
2.数据驱动决策成为餐饮行业的重要趋势
在数字化时代,数据已经成为企业决策的重要依据。对于餐饮企业来说,通过对在线食品订单数据的分析,可以深入了解消费者的点餐偏好、消费习惯和市场趋势,从而制定更加精准的营销策略和运营策略。同时,数据分析还可以帮助餐饮企业优化菜品组合、定价策略和服务质量,提升竞争力和盈利能力。
3.数据可视化与建模分类技术的广泛应用
数据可视化与建模分类技术是现代数据分析的重要工具。通过数据可视化,可以将复杂的数据以直观、易懂的方式呈现出来,帮助用户快速识别数据中的模式和趋势。而建模分类技术则可以对数据进行深入挖掘和分析,发现数据之间的关联性和规律性,为决策提供有力支持。这些技术在各个行业都得到了广泛的应用,包括金融、医疗、零售等,但在餐饮行业的应用还处于起步阶段,具有广阔的研究空间和应用前景。
三、研究意义
本研究的意义在于通过在线食品订单数据的可视化分析和建模分类,为餐饮行业的发展提供新的视角和思路。具体来说,本研究可以帮助餐饮企业更好地了解消费者需求和市场趋势,优化菜品组合和定价策略,提升服务质量和用户体验。同时,本研究还可以为餐饮行业的监管和政策制定提供科学依据,促进行业的健康发展。
2.数据集介绍
本实验数据集来源于Kaggle
在线食品订单数据集
描述:该数据集包含一段时间内从在线订餐平台收集的信息。它包含与职业、家庭规模、反馈等相关的各种属性。
属性:
Age:顾客的年龄。
Gender:客户的性别。
Marital Status:客户的婚姻状况。
Occupation:客户的职业。
Monthly Income:客户的月收入。
Educational Qualifications:客户的教育资格。
Family size:客户家庭中的人数。
latitude:客户所在位置的纬度。
longitude:客户所在位置的经度。
Pin code:客户所在位置的 Pin 码。
Output:订单的当前状态(例如,待处理、已确认、已交付)。
Feedback:客户收到订单后提供的反馈。
目的:该数据集可用于探索人口统计/位置因素与在线订餐行为之间的关系,分析客户反馈以提高服务质量,并可能根据人口统计和位置属性预测客户偏好或行为。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
首先导入本次实验用到的第三方库并加载数据集,打印前五行数据

查看数据大小

原始数据共有388行,13列
查看数据基本信息
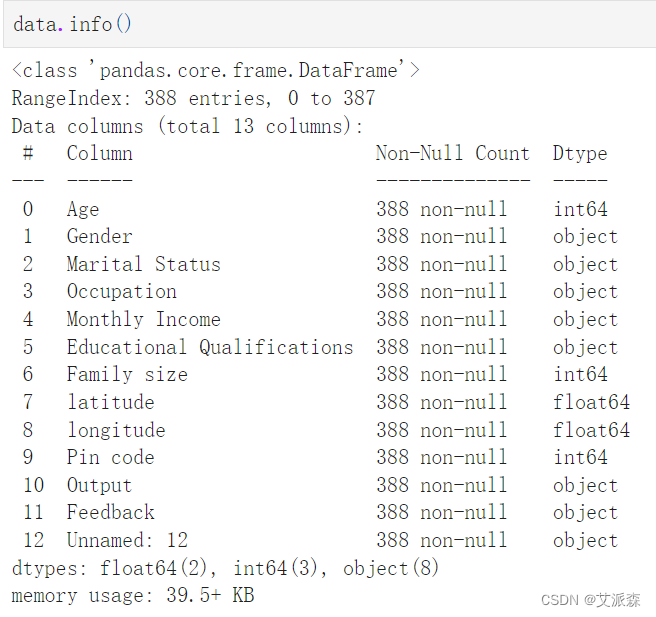
查看数值型变量的描述性统计
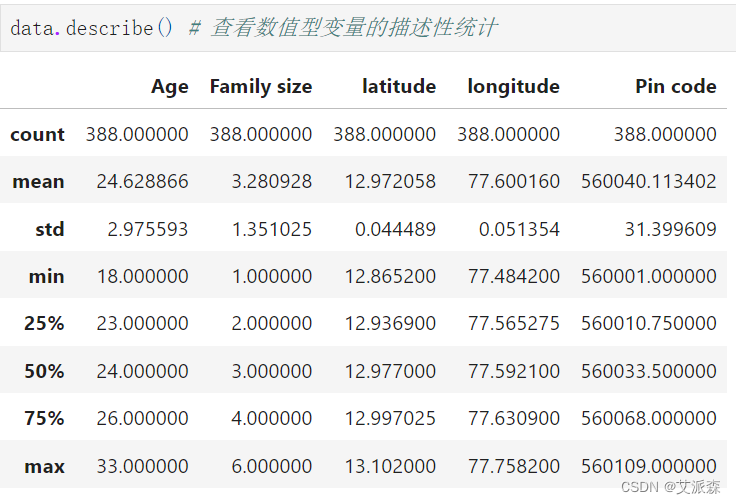
查看非数值型变量的描述性统计
查看数据缺失值情况
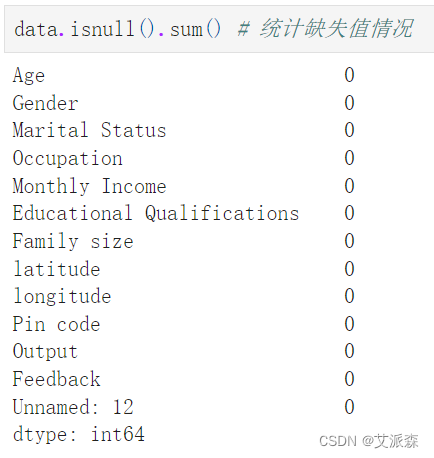
可以发没有缺失值
查看数据重复值情况
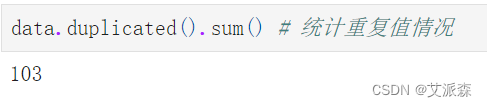
可以发现有103个重复数据,删除处理

5.数据可视化








6.建模分类

构建随机森林模型
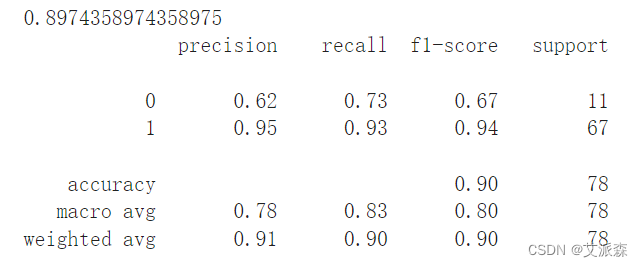
我们可以看到,我们得到了相当不错的90%的准确率。
源代码
在线食品订单数据集
描述:该数据集包含一段时间内从在线订餐平台收集的信息。它包含与职业、家庭规模、反馈等相关的各种属性。
属性:
Age:顾客的年龄。
Gender:客户的性别。
Marital Status:客户的婚姻状况。
Occupation:客户的职业。
Monthly Income:客户的月收入。
Educational Qualifications:客户的教育资格。
Family size:客户家庭中的人数。
latitude:客户所在位置的纬度。
longitude:客户所在位置的经度。
Pin code:客户所在位置的 Pin 码。
Output:订单的当前状态(例如,待处理、已确认、已交付)。
Feedback:客户收到订单后提供的反馈。
目的:该数据集可用于探索人口统计/位置因素与在线订餐行为之间的关系,分析客户反馈以提高服务质量,并可能根据人口统计和位置属性预测客户偏好或行为。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
import warnings
warnings.filterwarnings("ignore", "is_categorical_dtype")
warnings.filterwarnings("ignore", "use_inf_as_na")
data = pd.read_csv('onlinefoods.csv')
data.head()
data.shape
data.info()
data.describe() # 查看数值型变量的描述性统计
data.describe(include='O') # 查看非数值型变量的描述性统计
data.isnull().sum() # 统计缺失值情况
data.duplicated().sum() # 统计重复值情况
data.drop_duplicates(inplace=True)
data.duplicated().sum()
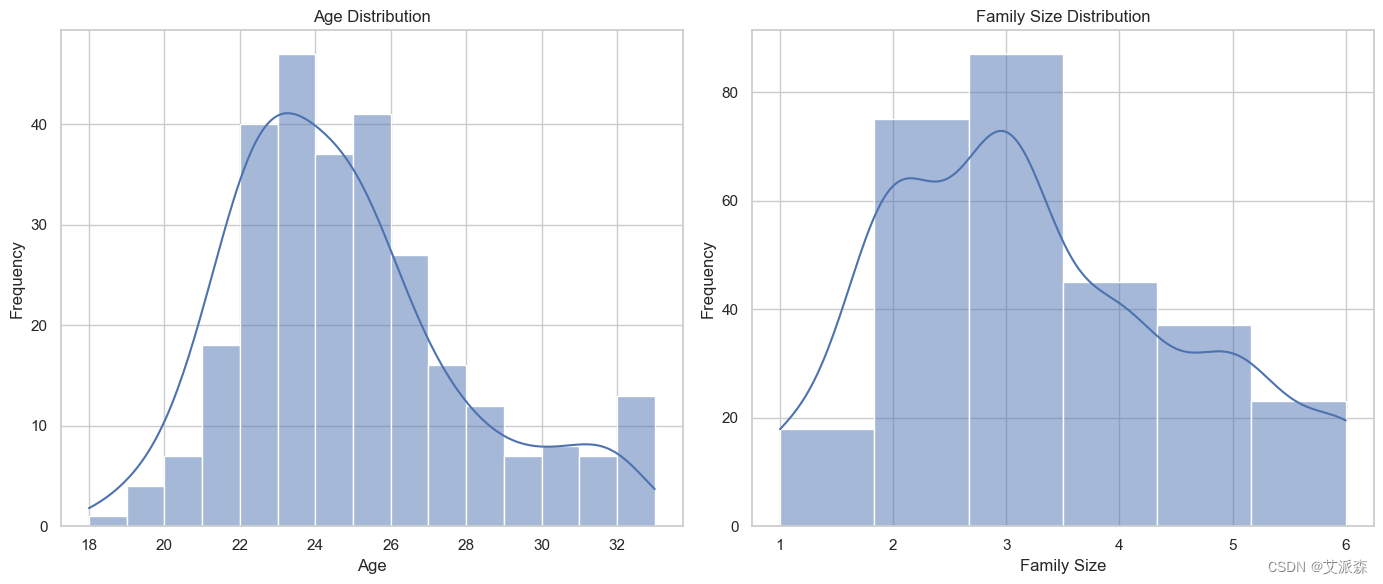
# 年龄和家庭规模的分布
sns.set(style="whitegrid")
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
sns.histplot(data['Age'], bins=15, kde=True, ax=ax[0])
ax[0].set_title('Age Distribution')
ax[0].set_xlabel('Age')
ax[0].set_ylabel('Frequency')
sns.histplot(data['Family size'], bins=6, kde=True, ax=ax[1])
ax[1].set_title('Family Size Distribution')
ax[1].set_xlabel('Family Size')
ax[1].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
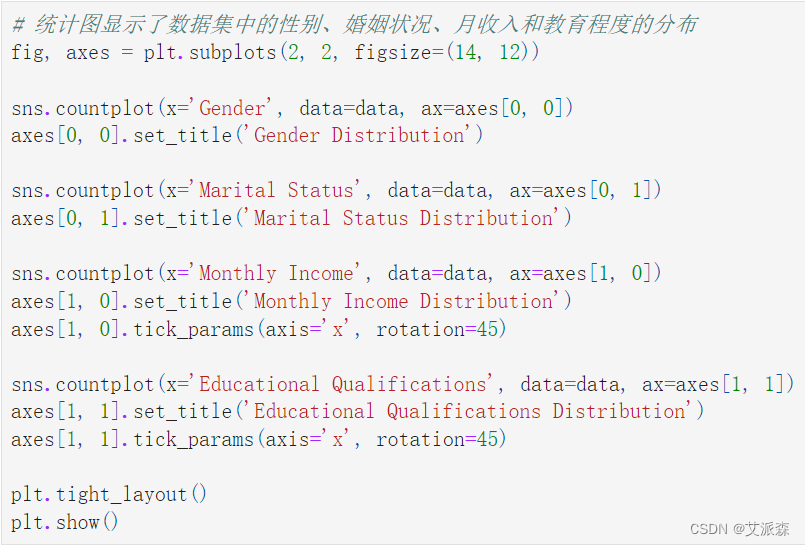
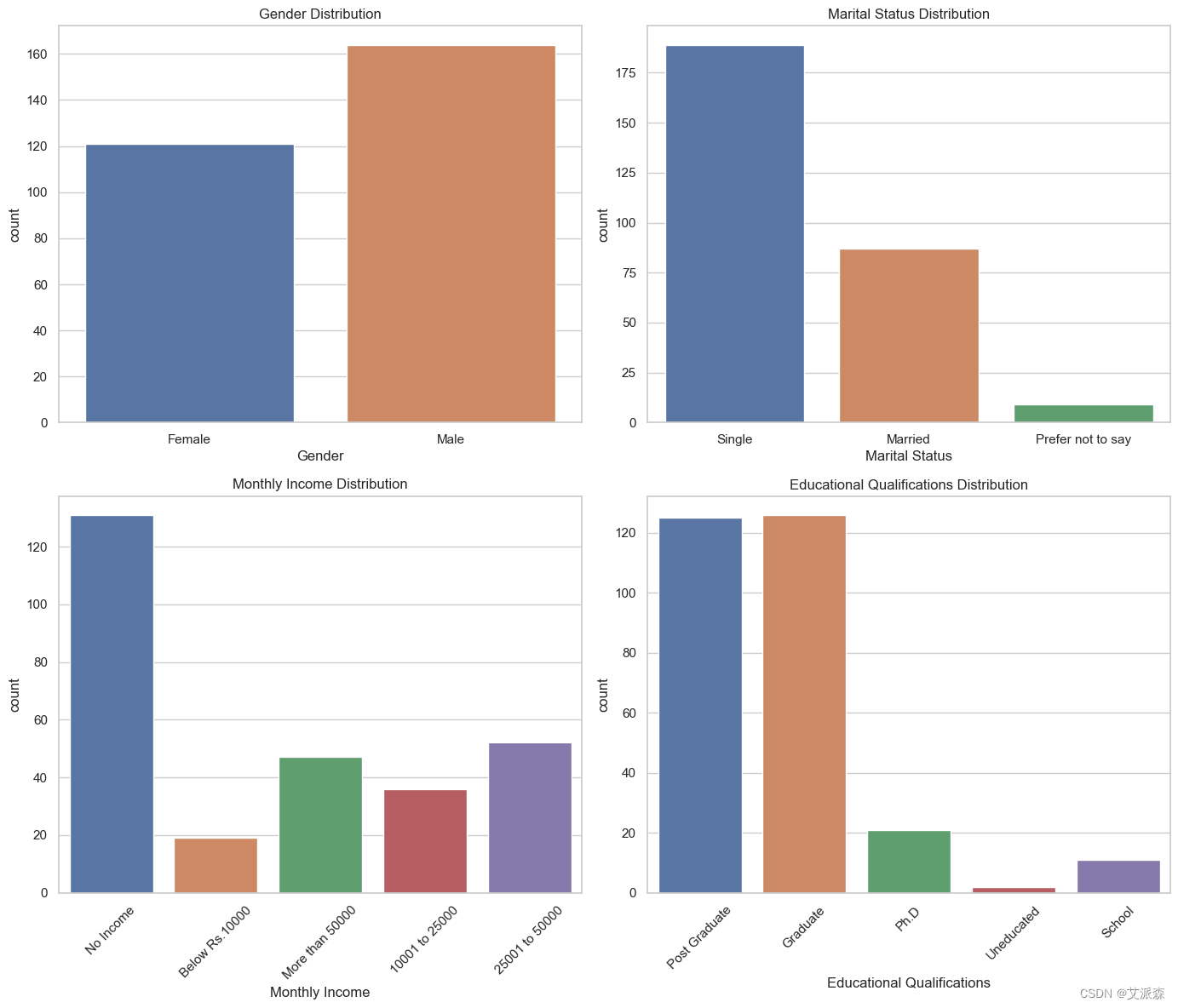
# 统计图显示了数据集中的性别、婚姻状况、月收入和教育程度的分布
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
sns.countplot(x='Gender', data=data, ax=axes[0, 0])
axes[0, 0].set_title('Gender Distribution')
sns.countplot(x='Marital Status', data=data, ax=axes[0, 1])
axes[0, 1].set_title('Marital Status Distribution')
sns.countplot(x='Monthly Income', data=data, ax=axes[1, 0])
axes[1, 0].set_title('Monthly Income Distribution')
axes[1, 0].tick_params(axis='x', rotation=45)
sns.countplot(x='Educational Qualifications', data=data, ax=axes[1, 1])
axes[1, 1].set_title('Educational Qualifications Distribution')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()
# 年龄与家庭规模的散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Age', y='Family size', data=data, hue='Gender', style='Marital Status', s=100)
plt.title('Relationship between Age and Family Size by Gender and Marital Status')
plt.xlabel('Age')
plt.ylabel('Family Size')
plt.legend(title='Gender / Marital Status', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
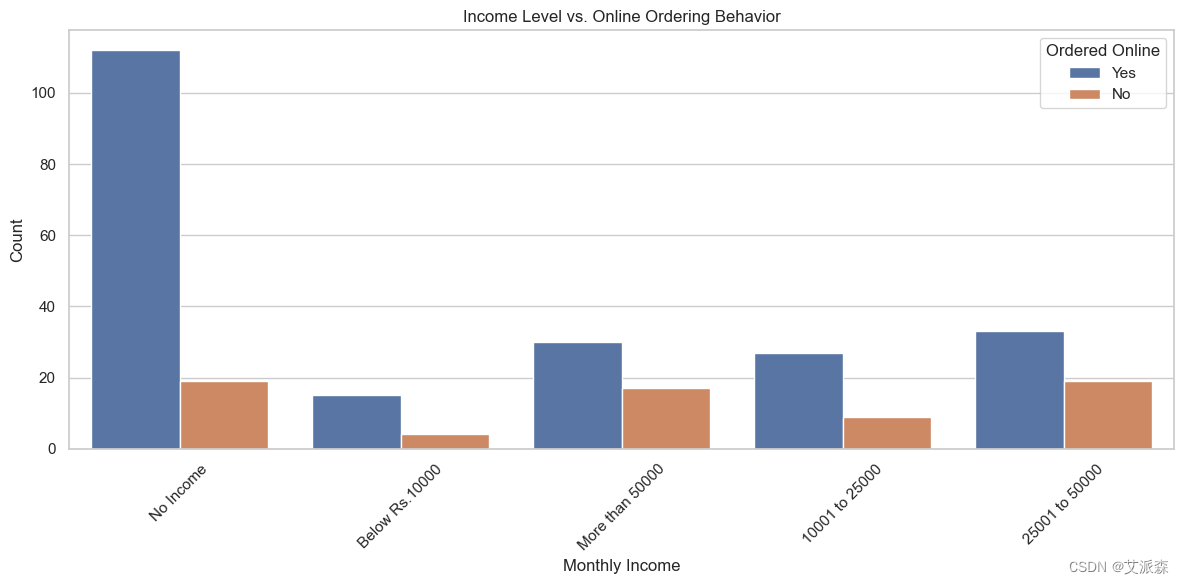
# 该图表显示了不同收入阶层的人下的订单数量
plt.figure(figsize=(12, 6))
sns.countplot(x='Monthly Income', hue='Output', data=data)
plt.title('Income Level vs. Online Ordering Behavior')
plt.xlabel('Monthly Income')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Ordered Online')
plt.tight_layout()
plt.show()
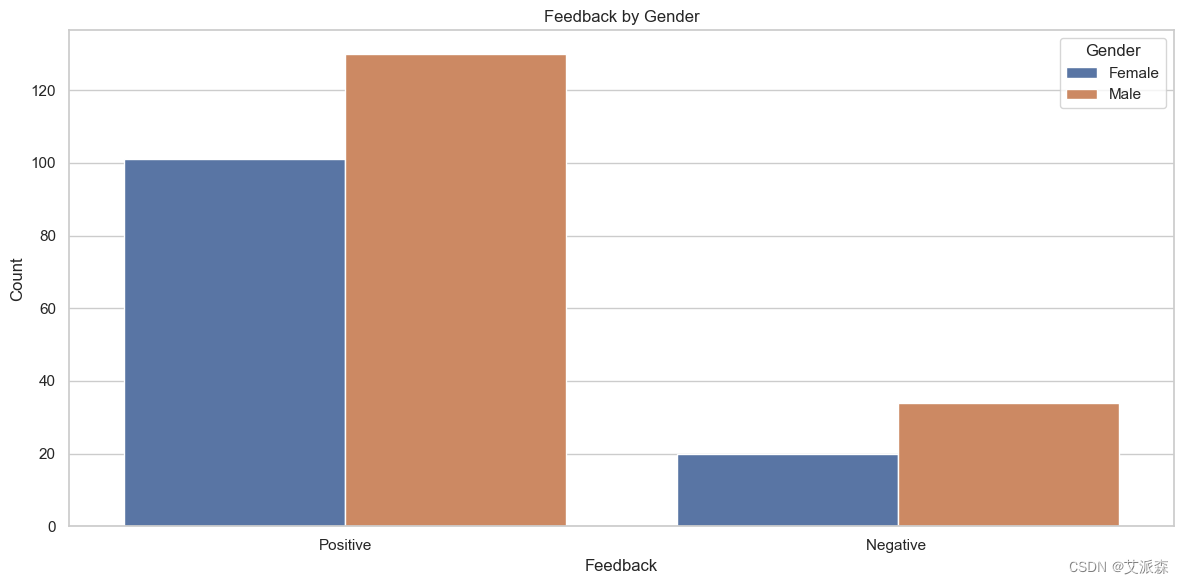
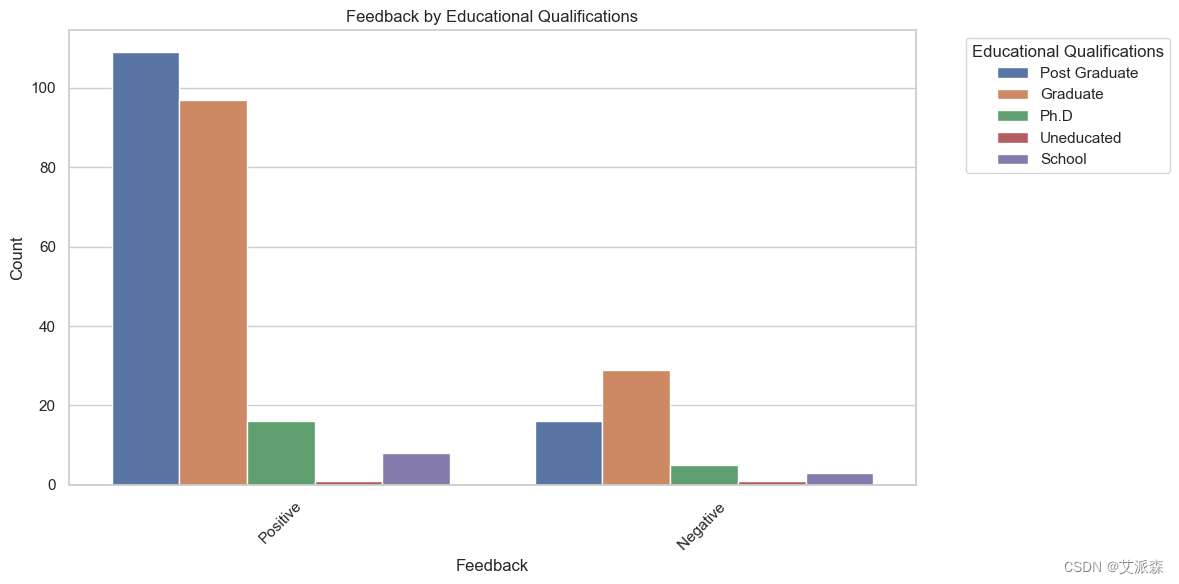
# 图表显示,根据他们的反馈,不同性别的人数以及根据他们的反馈,不同教育程度的人数
plt.figure(figsize=(12, 6))
sns.countplot(x='Feedback', hue='Gender', data=data)
plt.title('Feedback by Gender')
plt.xlabel('Feedback')
plt.ylabel('Count')
plt.legend(title='Gender')
plt.tight_layout()
plt.show()
plt.figure(figsize=(12, 6))
sns.countplot(x='Feedback', hue='Educational Qualifications', data=data)
plt.title('Feedback by Educational Qualifications')
plt.xlabel('Feedback')
plt.ylabel('Count')
plt.legend(title='Educational Qualifications', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
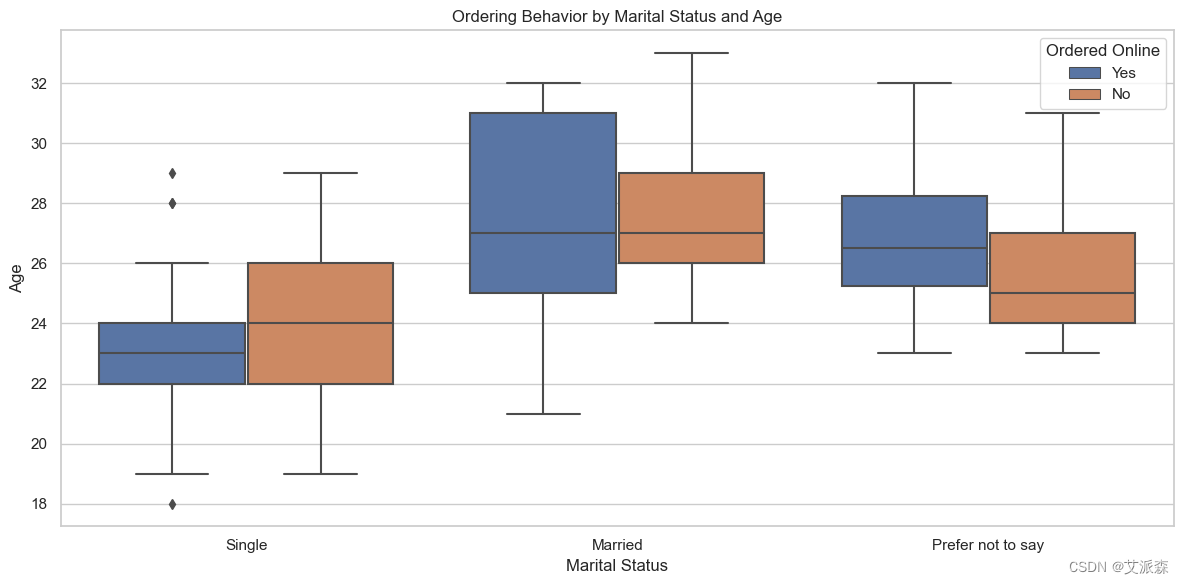
# 盒子图显示了不同婚姻状况和年龄的顾客的订购行为
plt.figure(figsize=(12, 6))
sns.boxplot(x='Marital Status', y='Age', hue='Output', data=data)
plt.title('Ordering Behavior by Marital Status and Age')
plt.xlabel('Marital Status')
plt.ylabel('Age')
plt.legend(title='Ordered Online')
plt.tight_layout()
plt.show()
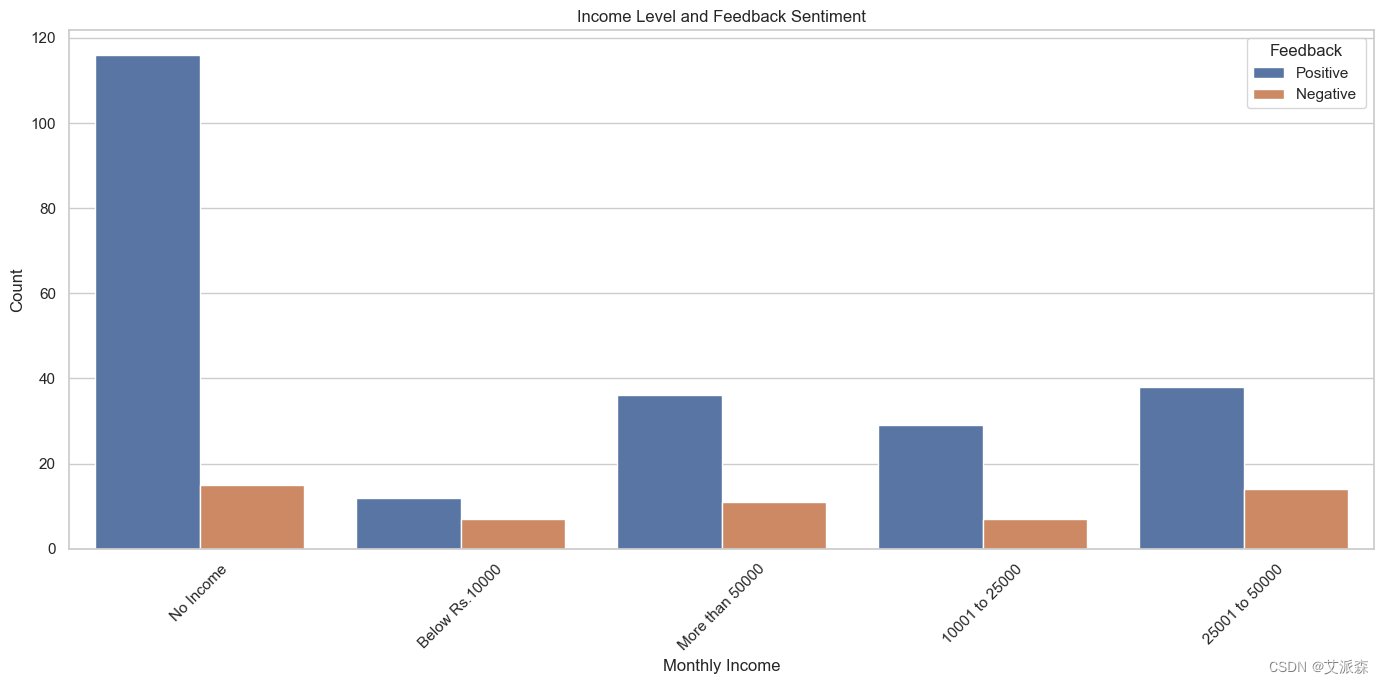
# 该图表显示了不同收入水平人群的正面和负面反馈数量
plt.figure(figsize=(14, 7))
sns.countplot(x='Monthly Income', hue='Feedback', data=data)
plt.title('Income Level and Feedback Sentiment')
plt.xlabel('Monthly Income')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Feedback', loc='upper right')
plt.tight_layout()
plt.show()
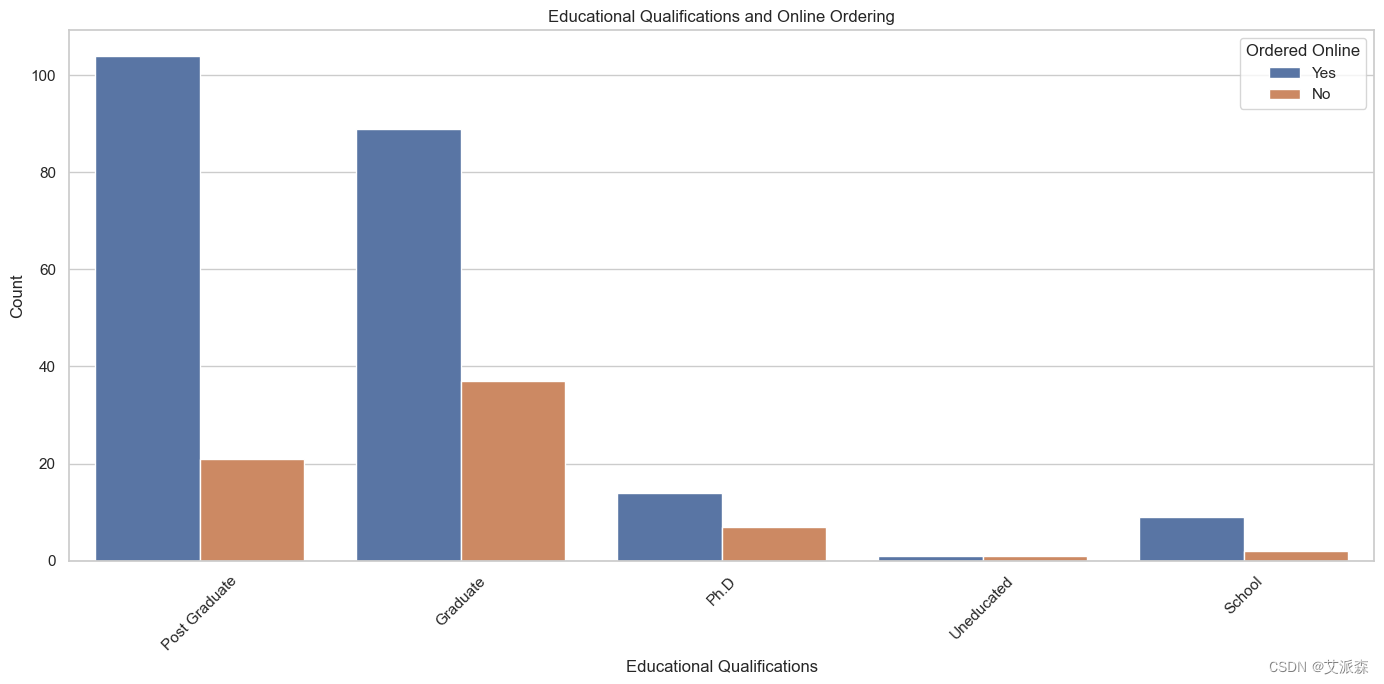
# 图表显示了不同学历的人在网上订餐的数量
plt.figure(figsize=(14, 7))
sns.countplot(x='Educational Qualifications', hue='Output', data=data)
plt.title('Educational Qualifications and Online Ordering')
plt.xlabel('Educational Qualifications')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Ordered Online', loc='upper right')
plt.tight_layout()
plt.show()
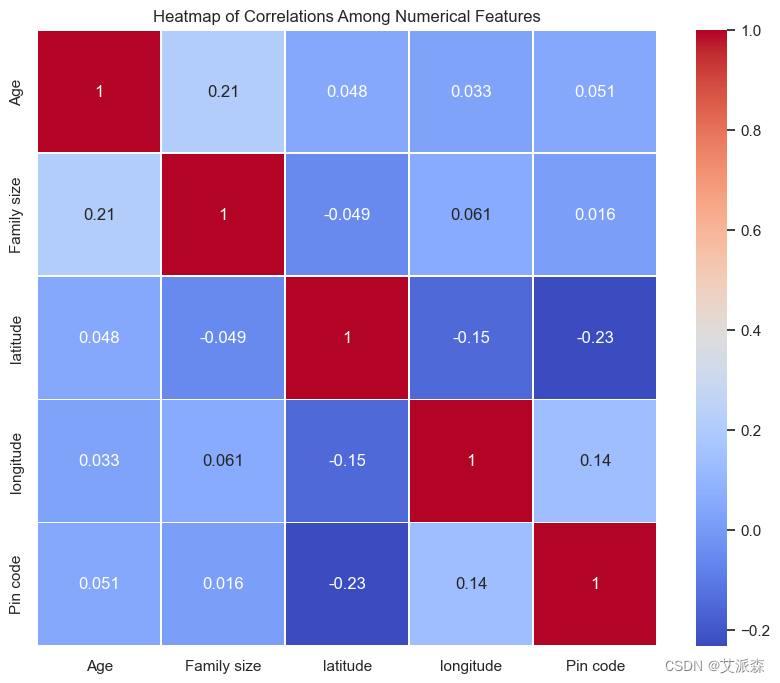
# 数据集中不同特征之间的热图
correlation_matrix = data[['Age', 'Family size', 'latitude', 'longitude', 'Pin code']].corr()
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', linewidths=.5)
plt.title('Heatmap of Correlations Among Numerical Features')
plt.show()
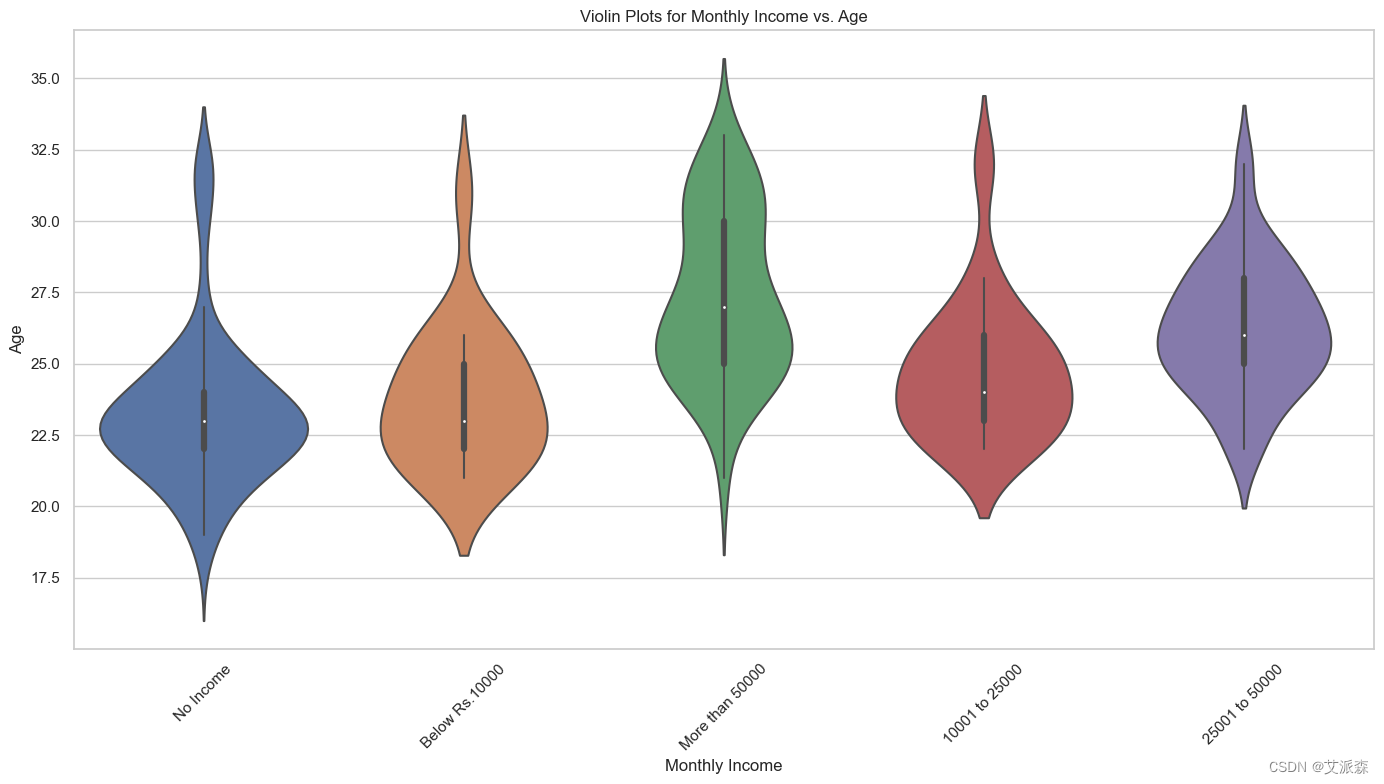
# 小提琴图显示月收入与年龄的关系
plt.figure(figsize=(14, 8))
sns.violinplot(x='Monthly Income', y='Age', data=data)
plt.title('Violin Plots for Monthly Income vs. Age')
plt.xlabel('Monthly Income')
plt.ylabel('Age')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
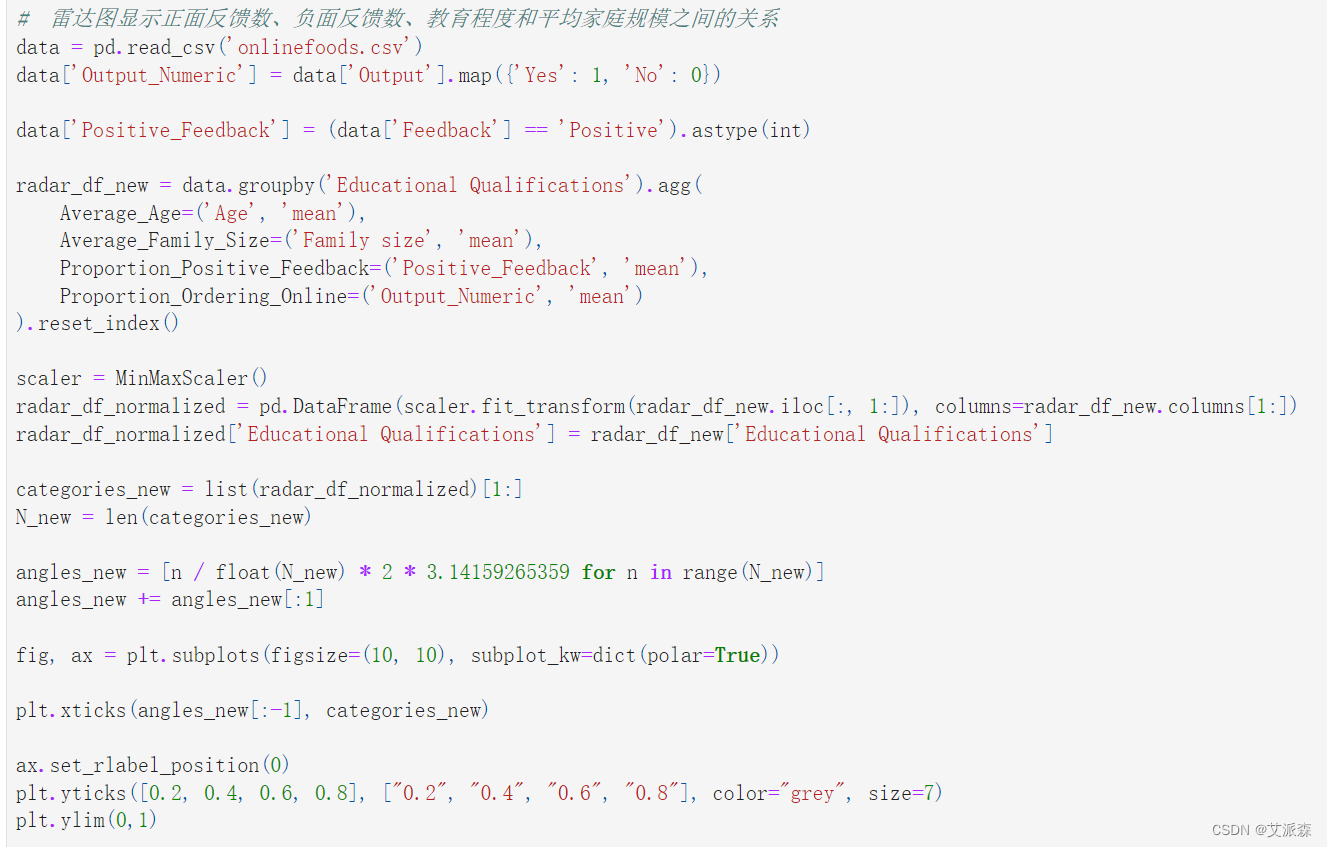
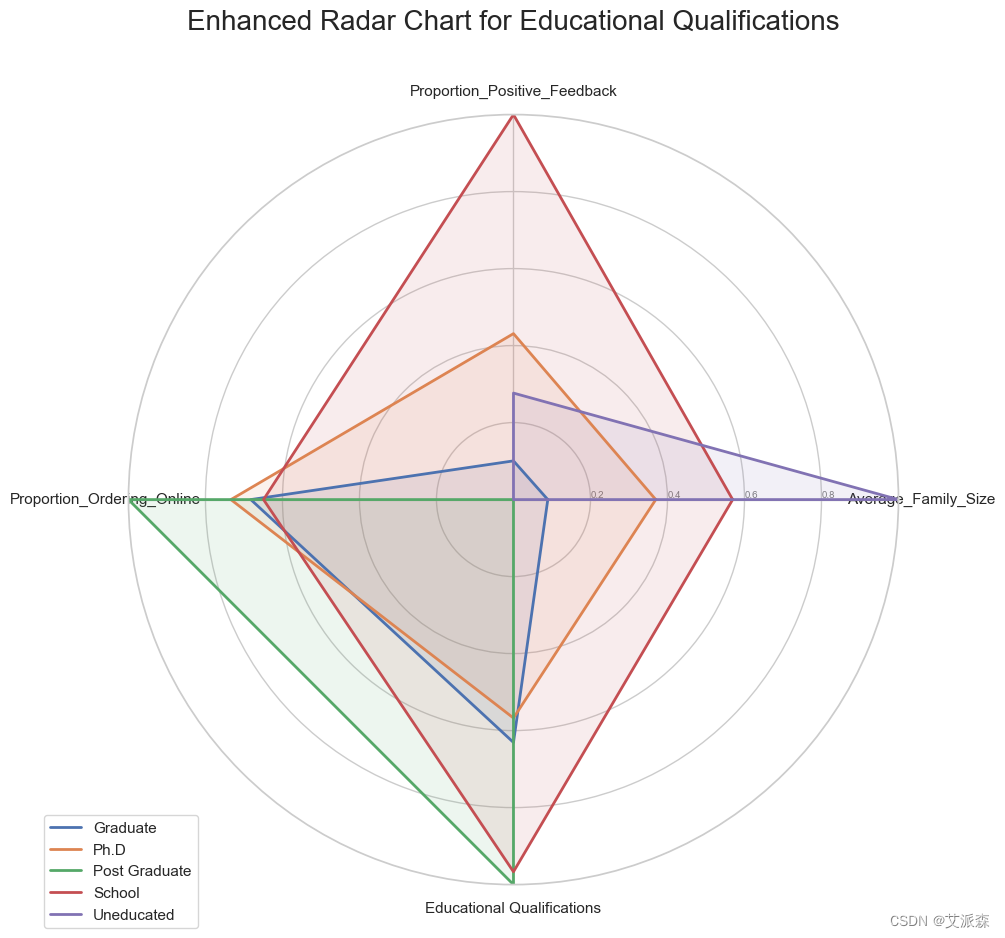
# 雷达图显示正面反馈数、负面反馈数、教育程度和平均家庭规模之间的关系
data = pd.read_csv('onlinefoods.csv')
data['Output_Numeric'] = data['Output'].map({'Yes': 1, 'No': 0})
data['Positive_Feedback'] = (data['Feedback'] == 'Positive').astype(int)
radar_df_new = data.groupby('Educational Qualifications').agg(
Average_Age=('Age', 'mean'),
Average_Family_Size=('Family size', 'mean'),
Proportion_Positive_Feedback=('Positive_Feedback', 'mean'),
Proportion_Ordering_Online=('Output_Numeric', 'mean')
).reset_index()
scaler = MinMaxScaler()
radar_df_normalized = pd.DataFrame(scaler.fit_transform(radar_df_new.iloc[:, 1:]), columns=radar_df_new.columns[1:])
radar_df_normalized['Educational Qualifications'] = radar_df_new['Educational Qualifications']
categories_new = list(radar_df_normalized)[1:]
N_new = len(categories_new)
angles_new = [n / float(N_new) * 2 * 3.14159265359 for n in range(N_new)]
angles_new += angles_new[:1]
fig, ax = plt.subplots(figsize=(10, 10), subplot_kw=dict(polar=True))
plt.xticks(angles_new[:-1], categories_new)
ax.set_rlabel_position(0)
plt.yticks([0.2, 0.4, 0.6, 0.8], ["0.2", "0.4", "0.6", "0.8"], color="grey", size=7)
plt.ylim(0,1)
for i, row in radar_df_normalized.iterrows():
data = radar_df_normalized.loc[i].drop('Educational Qualifications').tolist()
data += data[:1]
ax.plot(angles_new, data, linewidth=2, linestyle='solid', label=radar_df_normalized['Educational Qualifications'][i])
ax.fill(angles_new, data, alpha=0.1)
plt.title('Enhanced Radar Chart for Educational Qualifications', size=20, y=1.1)
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))
plt.show()
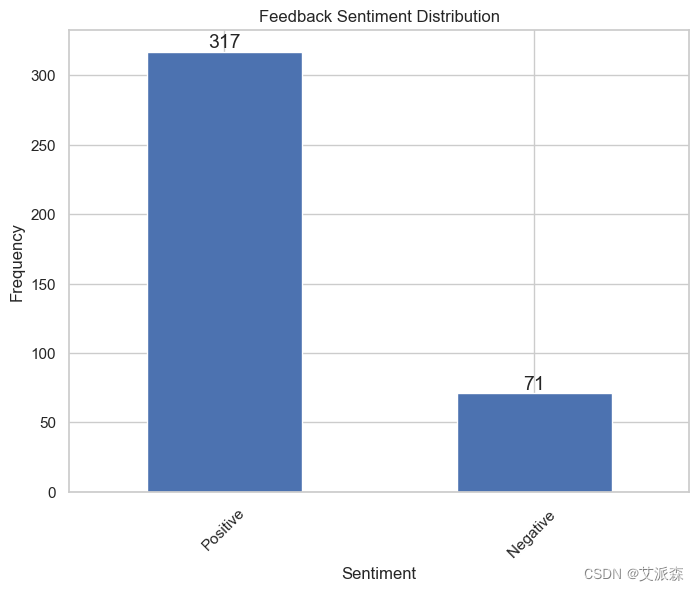
# 下面的条形图显示了正面和负面反馈的数量
data = pd.read_csv('onlinefoods.csv')
sentiment_counts = data['Feedback'].value_counts()
plt.figure(figsize=(8, 6))
sentiment_counts.plot(kind='bar')
plt.title('Feedback Sentiment Distribution')
plt.xlabel('Sentiment')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
for a,b in zip(range(2),sentiment_counts.values):
plt.text(a,b,'%d'%b,ha='center',va='bottom',fontsize=14)
plt.show()
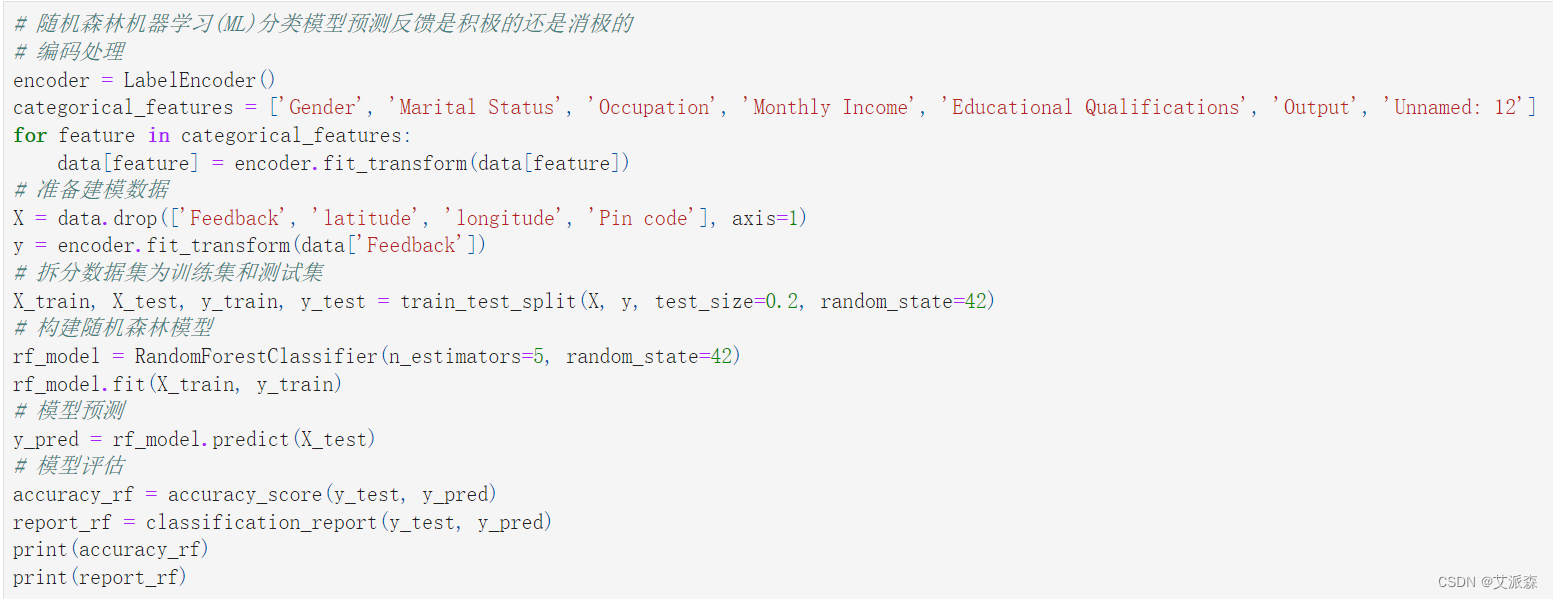
# 随机森林机器学习(ML)分类模型预测反馈是积极的还是消极的
# 编码处理
encoder = LabelEncoder()
categorical_features = ['Gender', 'Marital Status', 'Occupation', 'Monthly Income', 'Educational Qualifications', 'Output', 'Unnamed: 12']
for feature in categorical_features:
data[feature] = encoder.fit_transform(data[feature])
# 准备建模数据
X = data.drop(['Feedback', 'latitude', 'longitude', 'Pin code'], axis=1)
y = encoder.fit_transform(data['Feedback'])
# 拆分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建随机森林模型
rf_model = RandomForestClassifier(n_estimators=5, random_state=42)
rf_model.fit(X_train, y_train)
# 模型预测
y_pred = rf_model.predict(X_test)
# 模型评估
accuracy_rf = accuracy_score(y_test, y_pred)
report_rf = classification_report(y_test, y_pred)
print(accuracy_rf)
print(report_rf)
我们可以看到,我们得到了相当不错的90%的准确率资料获取,更多粉丝福利,关注下方公众号获取


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











