








🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
在智能手机市场日益繁荣的今天,红米与华为手机作为国产手机品牌的佼佼者,凭借其各自独特的品牌魅力和技术实力,赢得了广泛的用户群体和高度关注。随着技术的不断进步和消费者需求的日益多样化,用户对手机的期望已不仅限于基本的通讯功能,更涵盖了性能、拍照、续航、用户体验等多个方面。因此,深入探究红米与华为手机在用户长期使用过程中的实际表现,尤其是用户评论中所反映出的真实反馈,对于理解市场需求、优化产品设计及提升用户体验具有重要意义。
本实验的背景正是基于这样的市场环境和技术发展趋势。我们旨在通过收集并分析红米与华为手机的用户评论,全面、客观地揭示两款手机在性能、拍照、续航、用户体验等多个维度的真实表现。这些用户评论来自不同渠道,包括官方网站、社交媒体、电商平台等,涵盖了广泛的用户群体和多样化的使用场景,为实验提供了丰富而真实的数据基础。
通过本次实验,我们期望能够解答以下问题:在长期使用过程中,红米与华为手机在哪些方面表现出色?哪些方面仍有改进空间?用户对于两款手机的整体满意度如何?以及用户评论中反映出的共同需求和痛点是什么?基于以上背景,本实验将采用文本挖掘、情感分析等方法,对用户评论进行深入挖掘和分析,以揭示出隐藏在海量数据背后的有价值信息。通过对比红米与华为手机的用户评论,我们可以更加清晰地看到两款手机在市场上的竞争态势和用户需求的差异,为手机厂商提供有益的参考和启示。同时,本次实验也将为消费者在选择手机时提供更加全面、客观的参考依据,帮助他们根据自己的实际需求和预算做出更加明智的决策。
2.数据集介绍
本次实验数据集来源于京东网,采用Python爬虫获取了红米和华为手机的用户评论,共计1570条数据,10个变量,变量含义分别为用户ID、用户昵称、IP属地、评论时间、产品颜色、产品大小、评分、评论点赞量、评论回复量和评论内容。

3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据


查看数据大小

查看数据基本信息
查看数值型变量的描述性统计
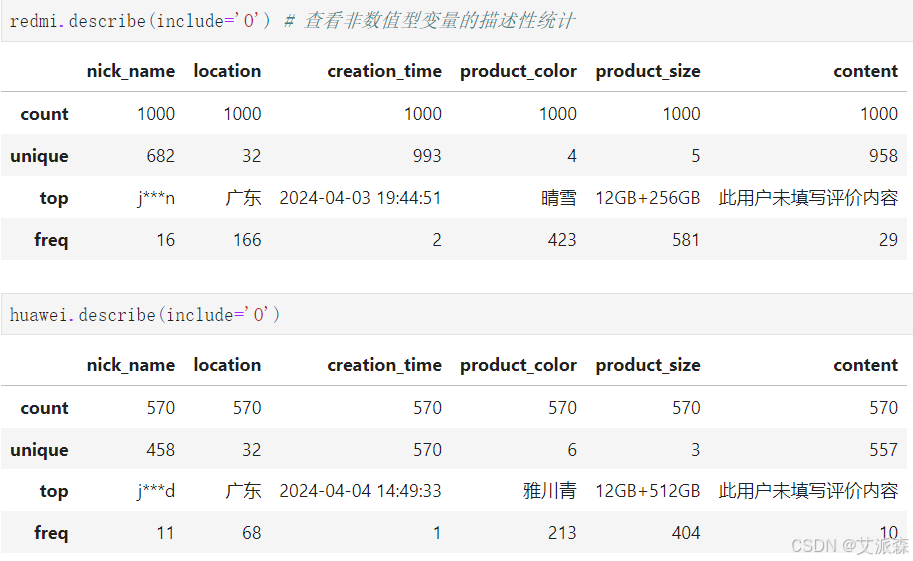
查看非数值型变量的描述性统计
4.2数据预处理
统计缺失值情况
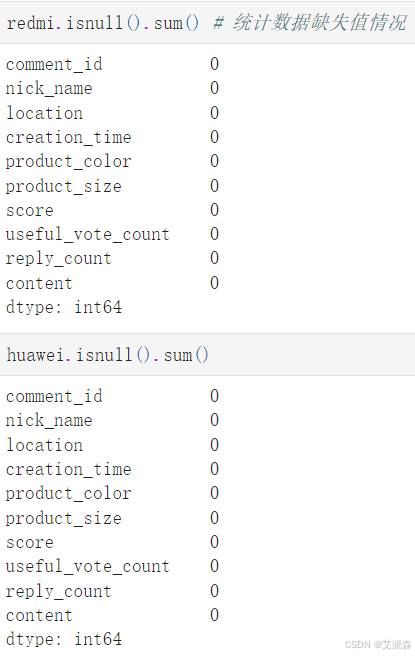
发现没有缺失值
统计重复值情况

发现红米数据集中存在7个重复值,删除即可


4.3数据可视化










因与地图相关的图片会被和谐,所有这里自行运行即可!
因与地图相关的图片会被和谐,所有这里自行运行即可!
import collections
import stylecloud
import re
import jieba
from PIL import Image
def draw_WorldCloud(df,pic_name,color='white'):
data = ''.join([re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',item) for item in df])
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
with open(f'{pic_name}词频统计.txt','w',encoding='utf-8')as f:
for i in word_counts_top:
f.write(str(i[0]))
f.write('\t')
f.write(str(i[1]))
f.write('\n')
print(word_counts_top)
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(result_list),
collocations=False, # 是否包括两个单词的搭配(二字组)
font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为
size=800, # stylecloud 的大小
palette='cartocolors.qualitative.Bold_7', # 调色板
background_color=color, # 背景颜色
icon_name='fas fa-cloud', # 形状的图标名称
gradient='horizontal', # 梯度方向
max_words=2000, # stylecloud 可包含的最大单词数
max_font_size=150, # stylecloud 中的最大字号
stopwords=True, # 布尔值,用于筛除常见禁用词
output_name=f'{pic_name}.png') # 输出图片
# 打开图片展示
img=Image.open(f'{pic_name}.png')
img.show()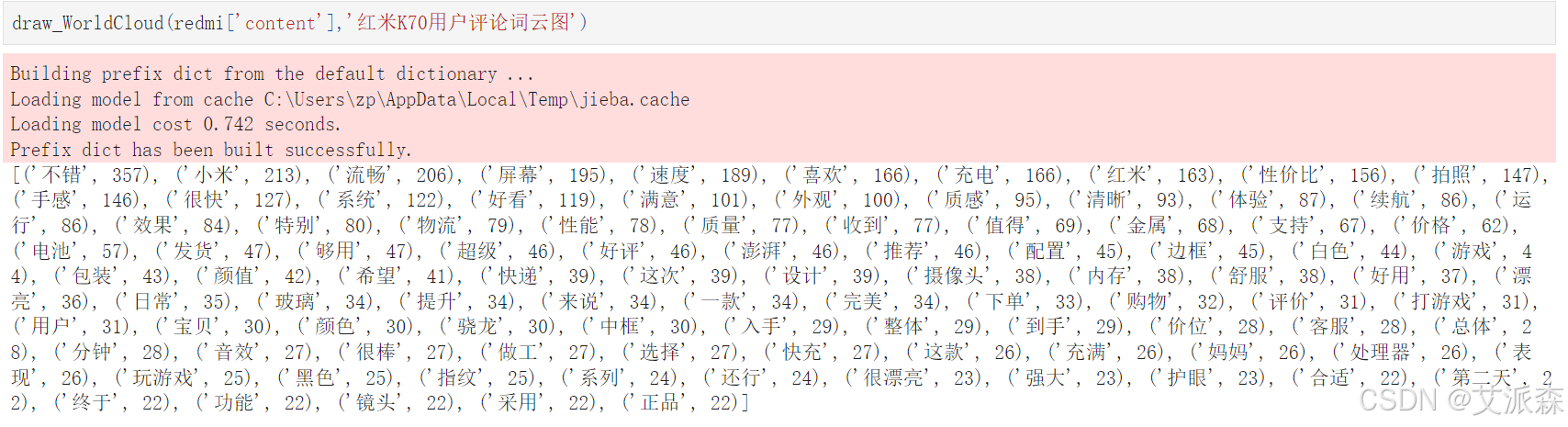



4.4snowmlp情感分析












源代码
import pandas as pd
import matplotlib.pylab as plt
import numpy as np
import seaborn as sns
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
import warnings
warnings.filterwarnings('ignore')
redmi = pd.read_csv('JD_comment_100075799823--0-时间排序.csv')
huawei = pd.read_csv('JD_comment_100064695864--0-时间排序.csv')
redmi.head(5)
huawei.head()
redmi.shape # 查看数据大小
huawei.shape
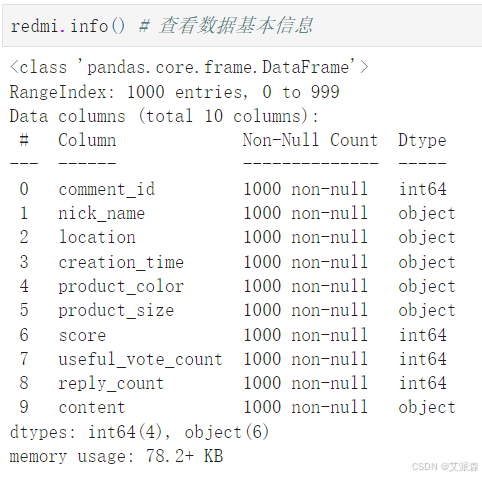
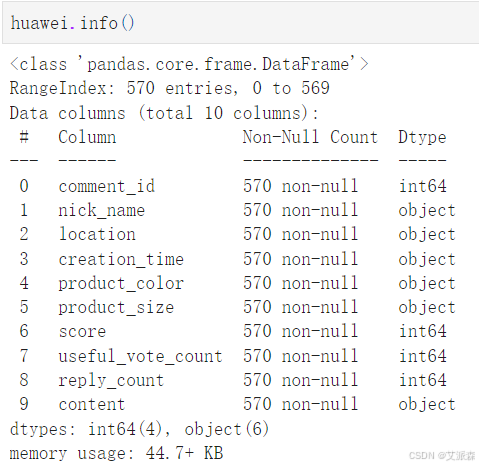
redmi.info() # 查看数据基本信息
huawei.info()
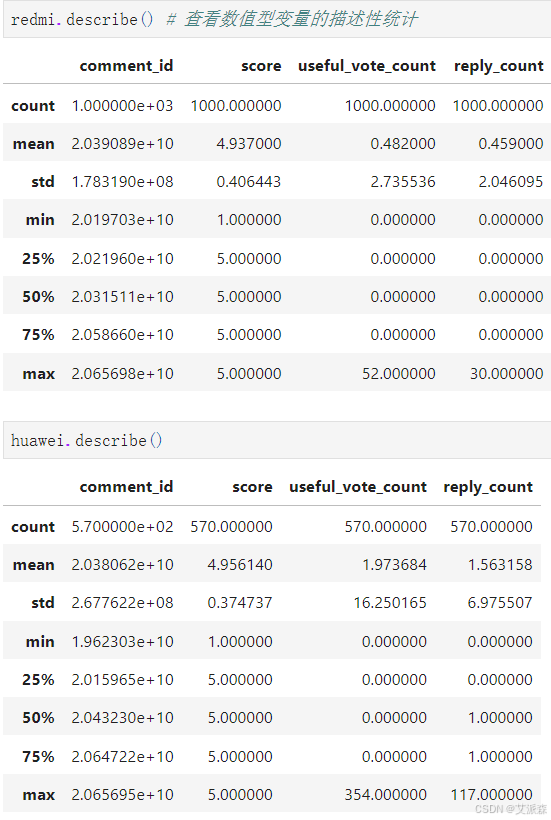
redmi.describe() # 查看数值型变量的描述性统计
huawei.describe()
redmi.describe(include='O') # 查看非数值型变量的描述性统计
huawei.describe(include='O')
redmi.isnull().sum() # 统计数据缺失值情况
huawei.isnull().sum()
redmi.duplicated().sum() # 统计数据重复值情况
huawei.duplicated().sum()
redmi.drop_duplicates(inplace=True) # 删除重复值
# 去除评论为“此用户未及时填写评价内容”的数据
redmi = redmi[redmi['content']!='此用户未填写评价内容']
huawei = huawei[huawei['content']!='此用户未填写评价内容']
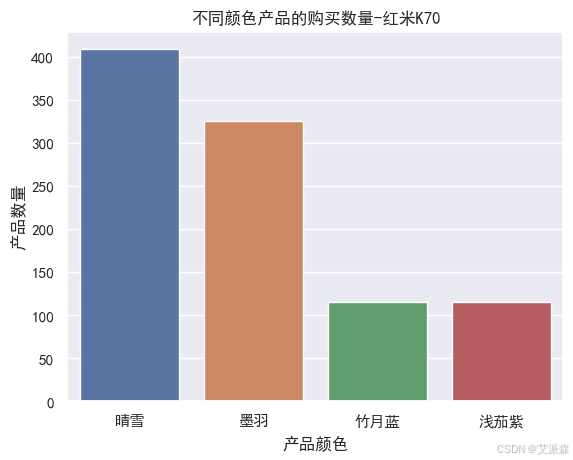
# 不同颜色产品的购买数量
sns.countplot(redmi['product_color'])
plt.xticks()
plt.xlabel('产品颜色')
plt.ylabel('产品数量')
plt.title('不同颜色产品的购买数量-红米K70')
plt.show()
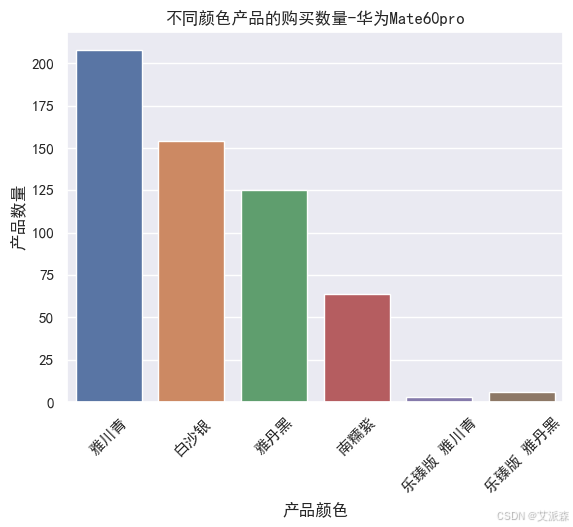
# 不同颜色产品的购买数量
sns.countplot(huawei['product_color'])
plt.xticks(rotation=45)
plt.xlabel('产品颜色')
plt.ylabel('产品数量')
plt.title('不同颜色产品的购买数量-华为Mate60pro')
plt.show()
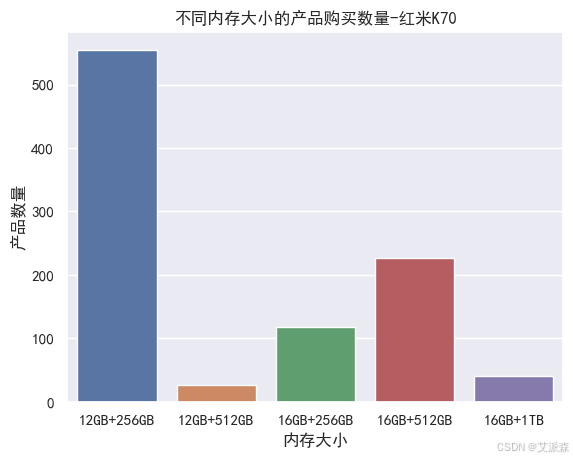
# 不同内存大小的产品购买数量
sns.countplot(redmi['product_size'])
plt.xlabel('内存大小')
plt.ylabel('产品数量')
plt.title('不同内存大小的产品购买数量-红米K70')
plt.show()
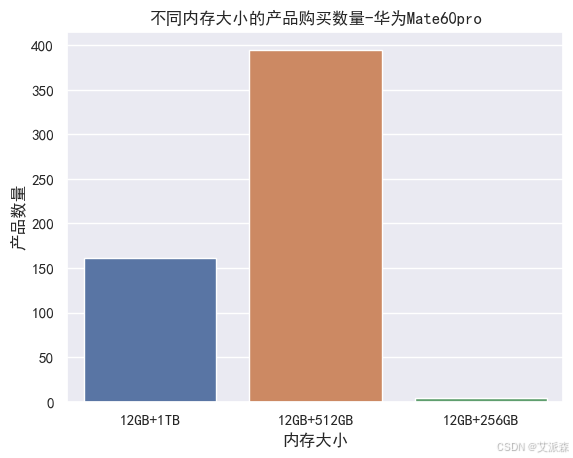
# 不同内存大小的产品购买数量
sns.countplot(huawei['product_size'])
plt.xlabel('内存大小')
plt.ylabel('产品数量')
plt.title('不同内存大小的产品购买数量-华为Mate60pro')
plt.show()
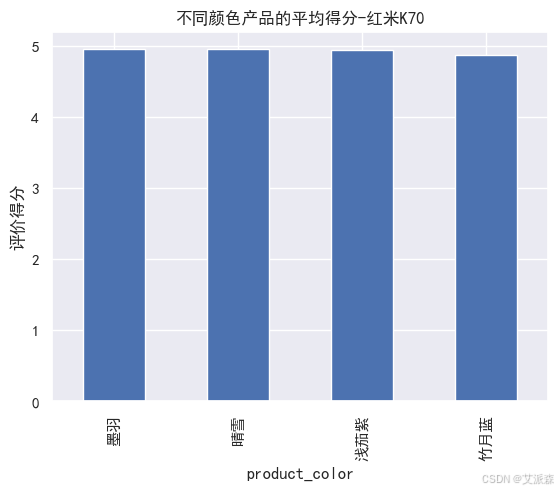
# 不同颜色产品的平均得分-红米K70
redmi.groupby('product_color').mean()['score'].plot(kind='bar')
plt.xticks()
plt.ylabel('评价得分')
plt.title('不同颜色产品的平均得分-红米K70')
plt.show()
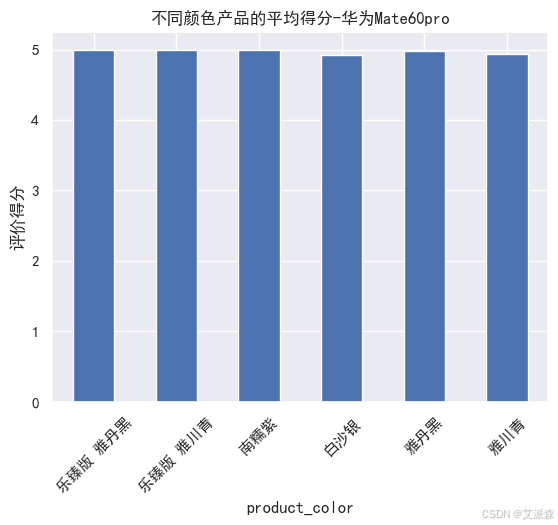
# 不同颜色产品的平均得分-华为Mate60pro
huawei.groupby('product_color').mean()['score'].plot(kind='bar')
plt.xticks(rotation=45)
plt.ylabel('评价得分')
plt.title('不同颜色产品的平均得分-华为Mate60pro')
plt.show()
# 不同型号产品的平均得分-红米K70
redmi.groupby('product_size').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('评价得分')
plt.title('不同型号产品的平均得分-红米K70')
plt.show()
# 不同型号产品的平均得分-华为Mate60pro
huawei.groupby('product_size').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('评价得分')
plt.title('不同型号产品的平均得分-华为Mate60pro')
plt.show()
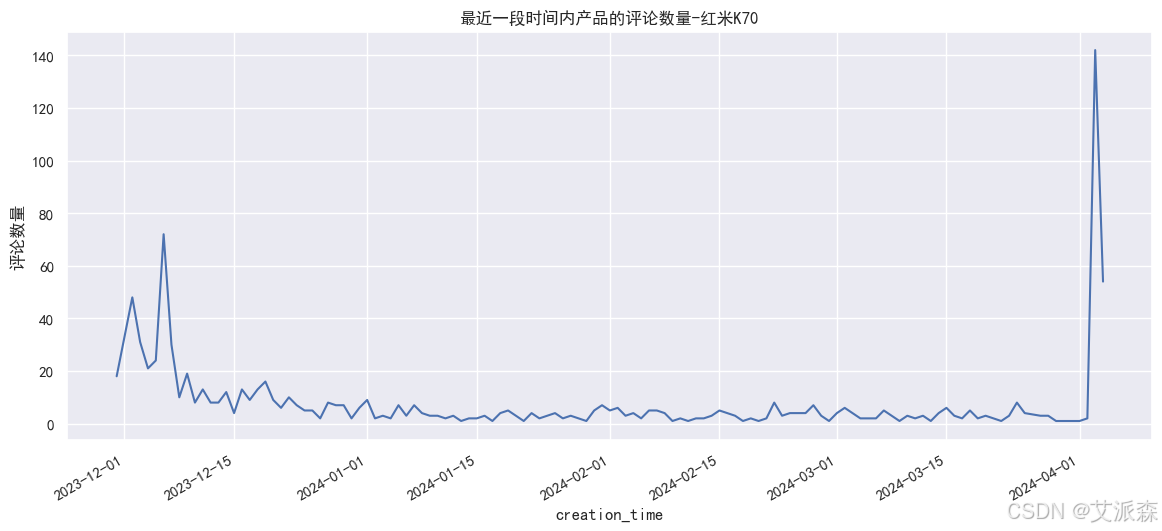
# 最近一段时间内产品的评论数量
redmi['creation_time'] = redmi['creation_time'].astype('datetime64[D]')
plt.figure(figsize=(14,6))
redmi.groupby(redmi['creation_time']).count()['content'].plot()
plt.ylabel('评论数量')
plt.title('最近一段时间内产品的评论数量-红米K70')
plt.show()
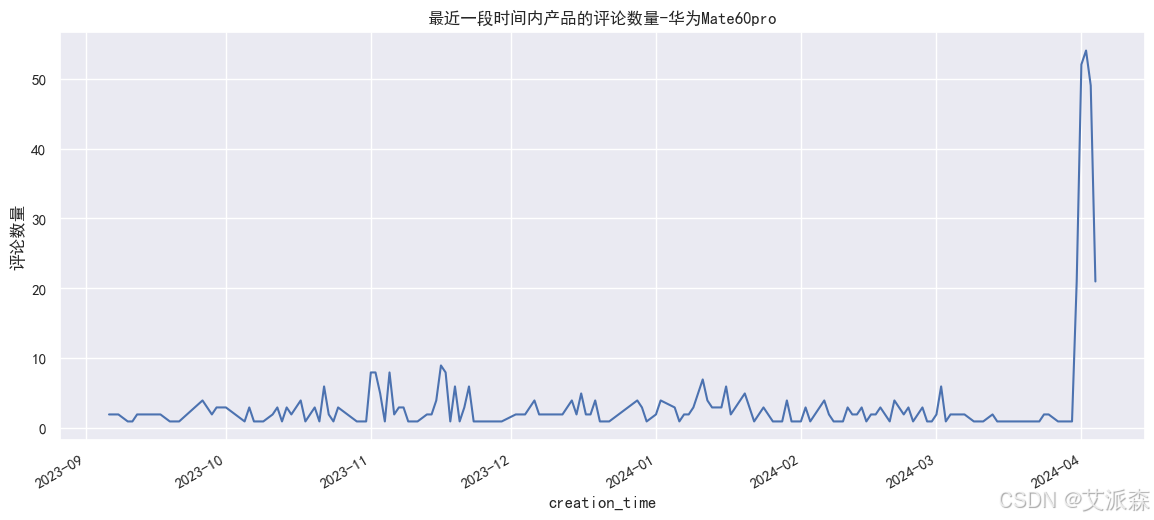
# 最近一段时间内产品的评论数量
huawei['creation_time'] = huawei['creation_time'].astype('datetime64[D]')
plt.figure(figsize=(14,6))
huawei.groupby(huawei['creation_time']).count()['content'].plot()
plt.ylabel('评论数量')
plt.title('最近一段时间内产品的评论数量-华为Mate60pro')
plt.show()
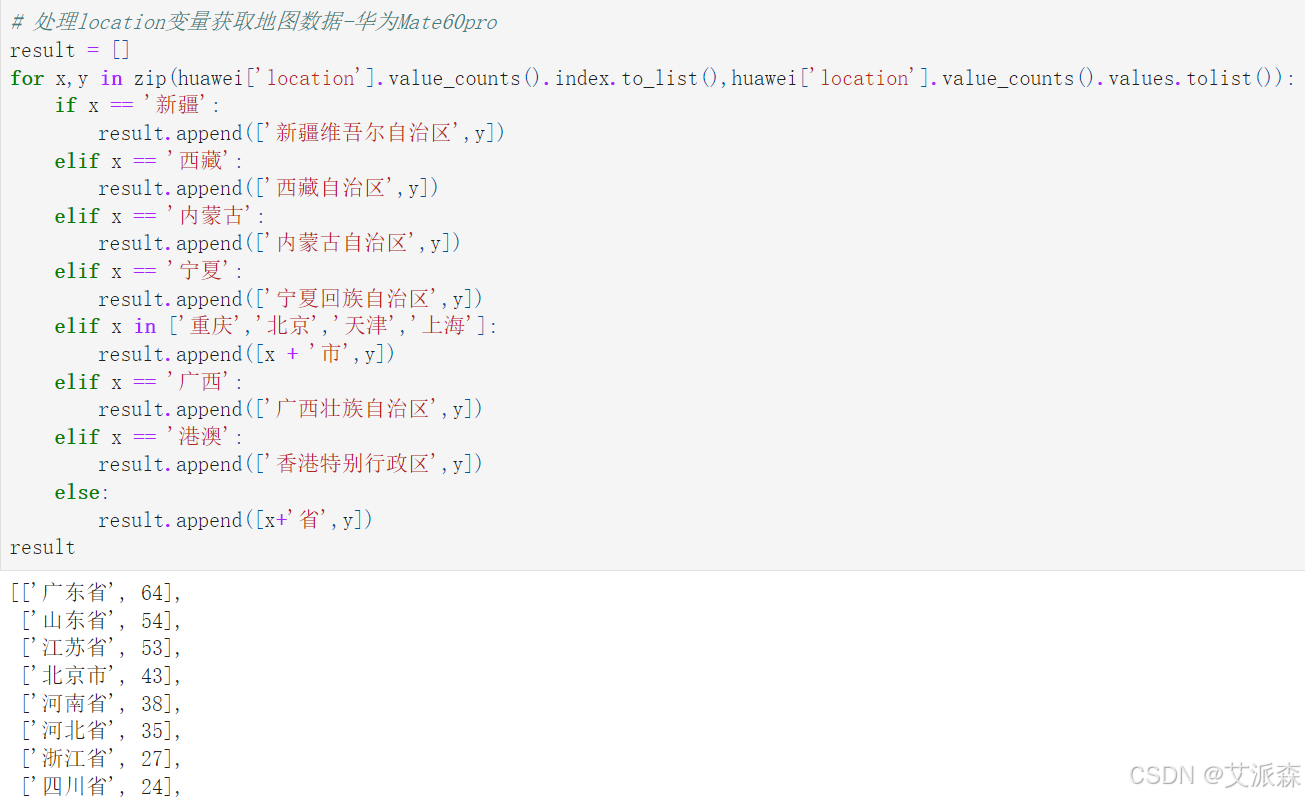
# 处理location变量获取地图数据-红米K70
result = []
for x,y in zip(redmi['location'].value_counts().index.to_list(),redmi['location'].value_counts().values.tolist()):
if x == '新疆':
result.append(['新疆维吾尔自治区',y])
elif x == '西藏':
result.append(['西藏自治区',y])
elif x == '内蒙古':
result.append(['内蒙古自治区',y])
elif x == '宁夏':
result.append(['宁夏回族自治区',y])
elif x in ['重庆','北京','天津','上海']:
result.append([x + '市',y])
elif x == '广西':
result.append(['广西壮族自治区',y])
elif x == '港澳':
result.append(['香港特别行政区',y])
else:
result.append([x+'省',y])
result
from pyecharts.charts import *
from pyecharts import options as opts
map = Map()
map.add('各省份购买数量-红米K70',result,
maptype='china',
is_map_symbol_show=False,
label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=100,min_=1)
)
map.render(path='各城市岗位数量分布-红米K70.html')
map.render_notebook()
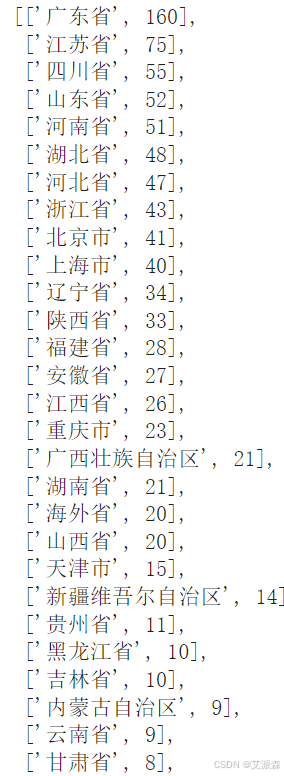
# 处理location变量获取地图数据-华为Mate60pro
result = []
for x,y in zip(huawei['location'].value_counts().index.to_list(),huawei['location'].value_counts().values.tolist()):
if x == '新疆':
result.append(['新疆维吾尔自治区',y])
elif x == '西藏':
result.append(['西藏自治区',y])
elif x == '内蒙古':
result.append(['内蒙古自治区',y])
elif x == '宁夏':
result.append(['宁夏回族自治区',y])
elif x in ['重庆','北京','天津','上海']:
result.append([x + '市',y])
elif x == '广西':
result.append(['广西壮族自治区',y])
elif x == '港澳':
result.append(['香港特别行政区',y])
else:
result.append([x+'省',y])
result
from pyecharts.charts import *
from pyecharts import options as opts
map = Map()
map.add('各省份购买数量-华为Mate60pro',result,
maptype='china',
is_map_symbol_show=False,
label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=50,min_=1)
)
map.render(path='各城市岗位数量分布-华为Mate60pro.html')
map.render_notebook()
import collections
import stylecloud
import re
import jieba
from PIL import Image
def draw_WorldCloud(df,pic_name,color='white'):
data = ''.join([re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',item) for item in df])
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
with open(f'{pic_name}词频统计.txt','w',encoding='utf-8')as f:
for i in word_counts_top:
f.write(str(i[0]))
f.write('\t')
f.write(str(i[1]))
f.write('\n')
print(word_counts_top)
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(result_list),
collocations=False, # 是否包括两个单词的搭配(二字组)
font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为
size=800, # stylecloud 的大小
palette='cartocolors.qualitative.Bold_7', # 调色板
background_color=color, # 背景颜色
icon_name='fas fa-cloud', # 形状的图标名称
gradient='horizontal', # 梯度方向
max_words=2000, # stylecloud 可包含的最大单词数
max_font_size=150, # stylecloud 中的最大字号
stopwords=True, # 布尔值,用于筛除常见禁用词
output_name=f'{pic_name}.png') # 输出图片
# 打开图片展示
img=Image.open(f'{pic_name}.png')
img.show()
draw_WorldCloud(redmi['content'],'红米K70用户评论词云图')
draw_WorldCloud(huawei['content'],'华为Mate60pro用户评论词云图')
snowmlp情感分析
#加载情感分析模块
from snownlp import SnowNLP
# 遍历每条评论进行预测
values=[SnowNLP(i).sentiments for i in redmi['content']]
#输出积极的概率,大于0.5积极的,小于0.5消极的
#myval保存预测值
myval=[]
good=0
mid=0
bad=0
for i in values:
if (i>=0.7):
myval.append("积极")
good=good+1
elif 0.2<i<0.7:
myval.append("中性")
mid+=1
else:
myval.append("消极")
bad=bad+1
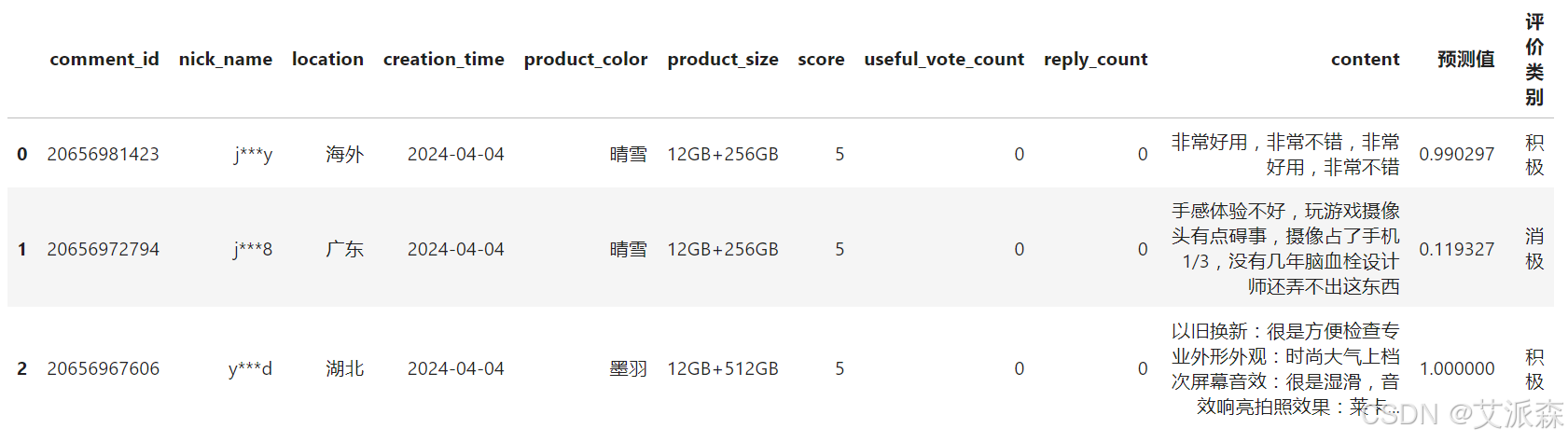
redmi['预测值']=values
redmi['评价类别']=myval
redmi.head(3)
rate=good/(good+bad+mid)
print('好评率','%.f%%' % (rate * 100)) #格式化为百分比
#作图
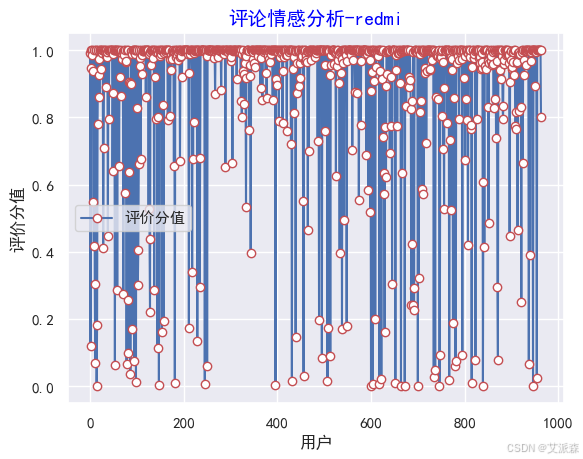
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'评价分值')
plt.xlabel('用户')
plt.ylabel('评价分值')
# 让图例生效
plt.legend()
#添加标题
plt.title('评论情感分析-redmi',family='SimHei',size=14,color='blue')
plt.show()
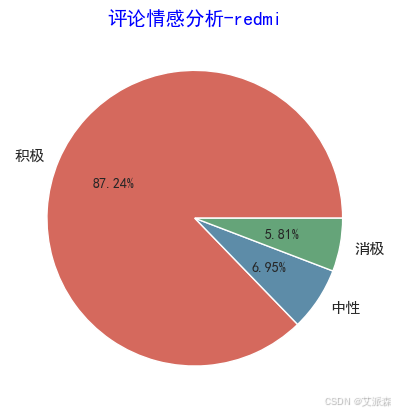
y = redmi['评价类别'].value_counts().values.tolist()
plt.pie(y,
labels=['积极','中性','消极'], # 设置饼图标签
colors=["#d5695d", "#5d8ca8", "#65a479"], # 设置饼图颜色
autopct='%.2f%%', # 格式化输出百分比
)
plt.title('评论情感分析-redmi',family='SimHei',size=14,color='blue')
plt.show()
draw_WorldCloud(redmi[redmi['评价类别']=='积极']['content'],'红米K70用户评论词云图-好评')
draw_WorldCloud(redmi[redmi['评价类别']=='消极']['content'],'红米K70用户评论词云图-差评')
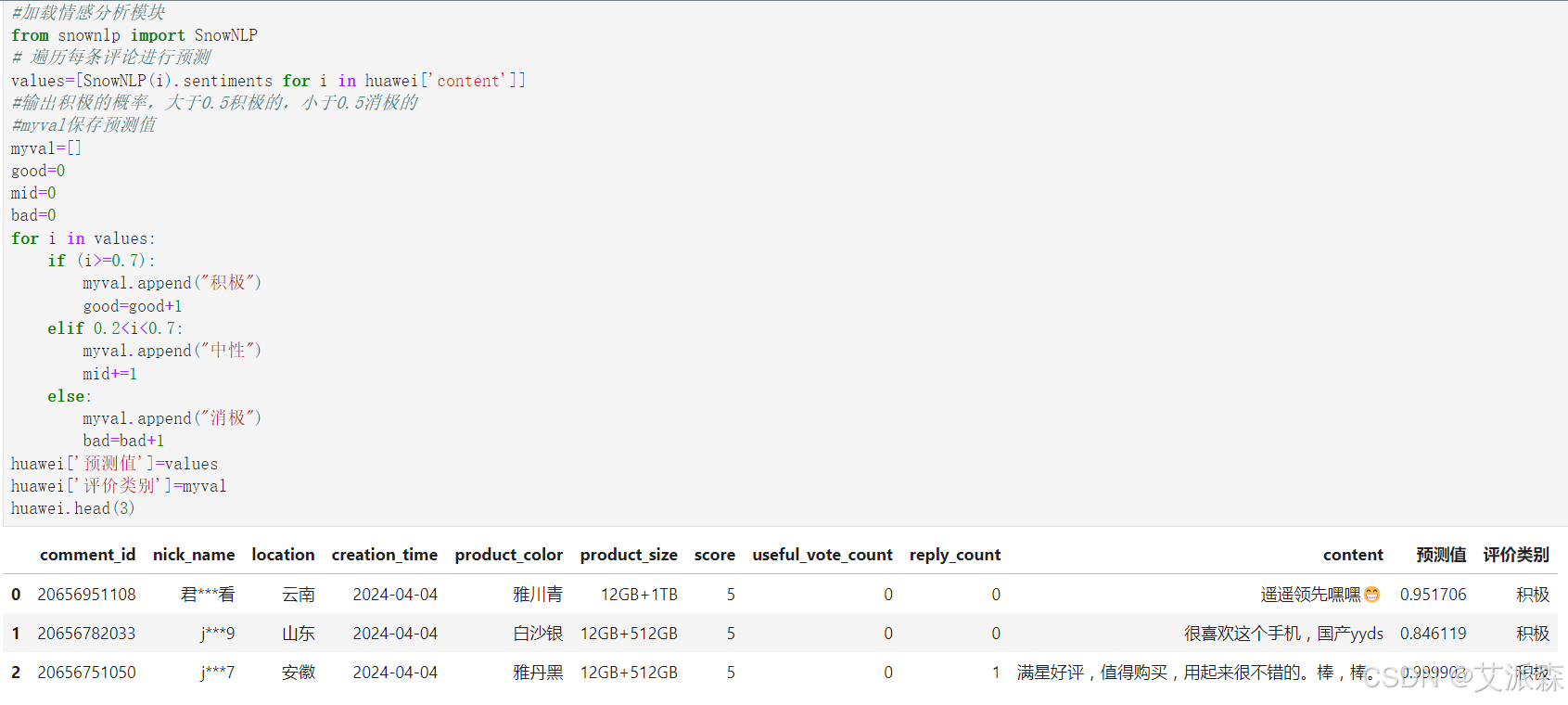
#加载情感分析模块
from snownlp import SnowNLP
# 遍历每条评论进行预测
values=[SnowNLP(i).sentiments for i in huawei['content']]
#输出积极的概率,大于0.5积极的,小于0.5消极的
#myval保存预测值
myval=[]
good=0
mid=0
bad=0
for i in values:
if (i>=0.7):
myval.append("积极")
good=good+1
elif 0.2<i<0.7:
myval.append("中性")
mid+=1
else:
myval.append("消极")
bad=bad+1
huawei['预测值']=values
huawei['评价类别']=myval
huawei.head(3)
rate=good/(good+bad+mid)
print('好评率','%.f%%' % (rate * 100)) #格式化为百分比
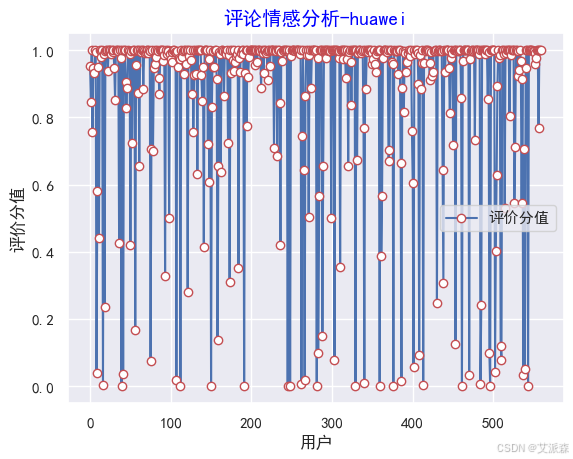
#作图
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'评价分值')
plt.xlabel('用户')
plt.ylabel('评价分值')
# 让图例生效
plt.legend()
#添加标题
plt.title('评论情感分析-huawei',family='SimHei',size=14,color='blue')
plt.show()
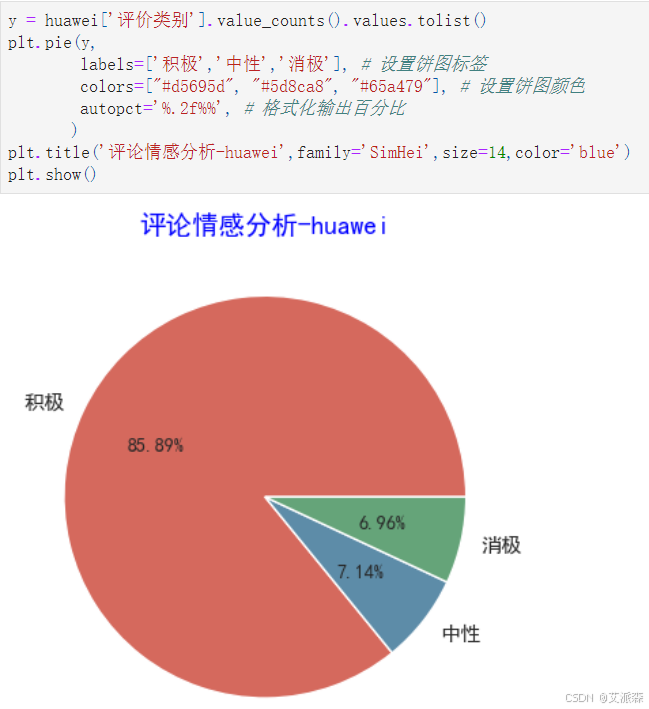
y = huawei['评价类别'].value_counts().values.tolist()
plt.pie(y,
labels=['积极','中性','消极'], # 设置饼图标签
colors=["#d5695d", "#5d8ca8", "#65a479"], # 设置饼图颜色
autopct='%.2f%%', # 格式化输出百分比
)
plt.title('评论情感分析-huawei',family='SimHei',size=14,color='blue')
plt.show()
draw_WorldCloud(huawei[huawei['评价类别']=='积极']['content'],'华为Mate60pro用户评论词云图-好评')
draw_WorldCloud(huawei[huawei['评价类别']=='消极']['content'],'华为Mate60pro用户评论词云图-差评')
LDA主题分析
import re
import jieba
def chinese_word_cut(mytext):
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: # 可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
return " ".join(result_list)
test = '在这里选购安全方便快捷💜,快递小哥态度非常好,这个价格非常给力💪,十分推荐,会继续回购😃大品牌!值得信赖!效果超级好!贵有贵的道理!很棒的商品!'
chinese_word_cut(test)
# 中文分词
redmi["content_cutted"] = redmi.content.apply(chinese_word_cut)
redmi.head()
# 中文分词
huawei["content_cutted"] = huawei.content.apply(chinese_word_cut)
huawei.head()
import tomotopy as tp
def find_k(docs, min_k=1, max_k=20, min_df=2):
# min_df 词语最少出现在2个文档中
scores = []
for k in range(min_k, max_k):
mdl = tp.LDAModel(min_df=min_df, k=k, seed=555)
for words in docs:
if words:
mdl.add_doc(words)
mdl.train(20)
coh = tp.coherence.Coherence(mdl)
scores.append(coh.get_score())
plt.plot(range(min_k, max_k), scores)
plt.xlabel("number of topics")
plt.ylabel("coherence")
plt.show()
find_k(docs=redmi['content_cutted'], min_k=1, max_k=10, min_df=2)
find_k(docs=huawei['content_cutted'], min_k=1, max_k=10, min_df=2)
# 初始化LDA
mdl = tp.LDAModel(k=2, min_df=2, seed=555)
for words in redmi['content_cutted']:
#确认words 是 非空词语列表
if words:
mdl.add_doc(words=words.split())
#训 练
mdl.train()
# 查看每个topic feature words
for k in range(mdl.k):
print('Top 20 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=20))
print('\n')
# 查看话题模型信息
mdl.summary()
import pyLDAvis
import numpy as np
# 在notebook显示
pyLDAvis.enable_notebook()
# 获取pyldavis需要的参数
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freq
prepared_data = pyLDAvis.prepare(
topic_term_dists,
doc_topic_dists,
doc_lengths,
vocab,
term_frequency,
start_index=0, # tomotopy话题id从0开始,pyLDAvis话题id从1开始
sort_topics=False # 注意:否则pyLDAvis与tomotopy内的话题无法一一对应。
)
# 可视化结果存到html文件中
pyLDAvis.save_html(prepared_data, 'ldavis-redmi.html')
# notebook中显示
pyLDAvis.display(prepared_data)
# 初始化LDA
mdl = tp.LDAModel(k=5, min_df=2, seed=555)
for words in huawei['content_cutted']:
#确认words 是 非空词语列表
if words:
mdl.add_doc(words=words.split())
#训 练
mdl.train()
# 查看每个topic feature words
for k in range(mdl.k):
print('Top 20 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=20))
print('\n')
# 查看话题模型信息
mdl.summary()
import pyLDAvis
import numpy as np
# 在notebook显示
pyLDAvis.enable_notebook()
# 获取pyldavis需要的参数
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freq
prepared_data = pyLDAvis.prepare(
topic_term_dists,
doc_topic_dists,
doc_lengths,
vocab,
term_frequency,
start_index=0, # tomotopy话题id从0开始,pyLDAvis话题id从1开始
sort_topics=False # 注意:否则pyLDAvis与tomotopy内的话题无法一一对应。
)
# 可视化结果存到html文件中
pyLDAvis.save_html(prepared_data, 'ldavis-huawei.html')
# notebook中显示
pyLDAvis.display(prepared_data)
资料获取,更多粉丝福利,关注下方公众号获取



















 8383
8383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











