







目录
作者的碎碎念
嘿,搞NLP的小伙伴,今天我们要聊一聊那个在自然语言处理(NLP)领域掀起了轰动的风暴——Transformers。别急,我们会从头到尾慢慢解剖这家伙的内部构造和它在NLP中的一些惊人应用。
首先,Transformers是啥?咱们跳进时光机,回到2017年,Vaswani等科学家们提出了这个东西。它可不是某个系列电影里的机器人,而是一种深度学习模型的架构。为啥有了LSTM、RNN,还得搞这个呢?原因很简单,之前的那帮模型有点不给力,训练不好调,而且处理长距离依赖关系也不行。于是,Transformers登场了。
Transformers有个看家本领,叫做“自注意力机制”。简单说,就是它能在处理序列数据时,动态地关注不同位置的信息。这怎么做到的呢?通过一个数学公式,叫做自注意力公式。别被这个名词吓到,其实就是一个复杂的关系权重计算,把输入序列中不同位置的信息融合在一块。

在这个模型的大舞台上,编码器和解码器是两位主角。编码器负责把输入序列转成上下文表示,它有两个小弟:自注意力子层和全连接前馈子层。前者让每个位置都能关注到全局信息,后者则通过一层全连接网络处理上下文信息。
解码器则更牛,不仅包含编码器的两个子层,还有一个额外的自注意力子层。这家伙的任务可不简单,要生成目标序列,得在每个时间步输出一个符号,逐步造出目标。
别忘了多头注意力机制,这是Transformers的另一大杀招。通过使用多个不同的投影,同时执行自注意力,然后把结果拼接起来,再通过线性映射,增强了模型对不同特征尺度的表示能力。
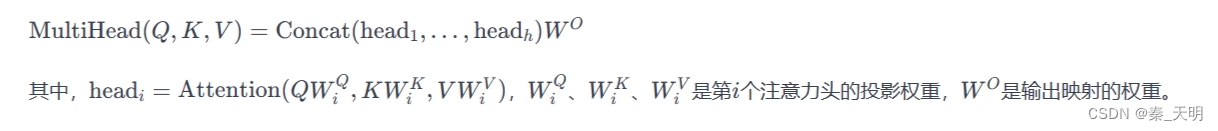
那个位置编码也不能忽视。因为Transformers模型不擅长处理序列的顺序信息,所以引入了位置编码,一种把位置信息嵌入到输入表示的方法。
好了,这些都是理论知识,够废话了吧?让我们来看看Transformers在实战中的表现。它在NLP任务中可谓是风头无两,比如机器翻译、文本生成、情感分析等等。你瞧,这家伙可不只是在文字玩得转,还能在图像领域大显身手,比如图像分类、目标检测等。
Transformers的成功催生了一大波“儿子”,比如BERT、GPT等,它们在不同任务上都表现得相当抢眼。
咱们聊一下训练,Transformers模型一般是通过监督学习来的,最小化损失函数,用反向传播和优化算法不断更新模型参数。训练的时候,要用上学习率调度和正则化技术,别让模型跑偏了。
最后,咱们得承认,Transformers在NLP领域可谓是一匹黑马,红遍大江南北。不仅性能好,而且灵活,所以在各种任务上都能大显身手。嗯,懂了吗?这就是Transformers,横扫NLP领域的一匹“神马都不怕”的黑马。
实践
喂喂喂,别急别急,我们现在就来揭秘一些NLP中Transformers的常用函数。拿起你的键盘,准备好迎接代码的冲击!
1. 自注意力机制
首先得搞清楚自注意力机制,这可是Transformers的灵魂所在。在Python里,我们可以用下面这个函数来实现:
import torch
import torch.nn.functional as F
def self_attention(query, key, value):
# 计算注意力权重
attention_weights = F.softmax(torch.matmul(query, key.transpose(-2, -1)) / torch.sqrt(query.size(-1)), dim=-1)
# 加权求和,得到上下文表示
context = torch.matmul(attention_weights, value)
return context
这个函数接收三个参数:query、key、value,分别是查询、键和值的矩阵。通过一些矩阵运算,我们就能得到自注意力的上下文表示。
2. 多头注意力
别忘了Transformers的杀手锏之一——多头注意力。看这个函数:
class MultiHeadAttention(torch.nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.query_linear = torch.nn.Linear(d_model, d_model)
self.key_linear = torch.nn.Linear(d_model, d_model)
self.value_linear = torch.nn.Linear(d_model, d_model)
self.final_linear = torch.nn.Linear(d_model, d_model)
def forward(self, query, key, value):
# 线性映射得到多头的query、key、value
query = self.query_linear(query)
key = self.key_linear(key)
value = self.value_linear(value)
# 拆分成多个头
query = query.view(query.size(0), -1, self.num_heads, self.head_dim).transpose(1, 2)
key = key.view(key.size(0), -1, self.num_heads, self.head_dim).transpose(1, 2)
value = value.view(value.size(0), -1, self.num_heads, self.head_dim).transpose(1, 2)
# 多头自注意力
context = self_attention(query, key, value)
# 拼接多头的结果
context = context.transpose(1, 2).contiguous().view(context.size(0), -1, self.num_heads * self.head_dim)
# 线性映射得到最终结果
output = self.final_linear(context)
return output
这个类实现了多头注意力,接收三个参数:d_model是模型的维度,num_heads是头的数量。通过一系列线性映射和拆分,最终得到多头注意力的输出。
3. 位置编码
位置编码也是个重要家伙。看看这个函数:
class PositionalEncoding(torch.nn.Module):
def __init__(self, d_model, max_len=512):
super(PositionalEncoding, self).__init__()
self.encoding = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
self.encoding[:, 0::2] = torch.sin(position * div_term)
self.encoding[:, 1::2] = torch.cos(position * div_term)
self.encoding = self.encoding.unsqueeze(0)
def forward(self, x):
return x + self.encoding[:, :x.size(1)].detach()
这个类实现了位置编码。通过一些数学运算,把位置信息嵌入到输入表示中。
4. 编码器和解码器
好了,有了上面这些基础,我们可以组装编码器和解码器了。这里简化一下,给你看个伪代码:
class TransformerEncoderLayer(torch.nn.Module):
def __init__(self, d_model, num_heads):
super(TransformerEncoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.feedforward = torch.nn.Sequential(
torch.nn.Linear(d_model, 4 * d_model),
torch.nn.ReLU(),
torch.nn.Linear(4 * d_model, d_model)
)
self.norm1 = torch.nn.LayerNorm(d_model)
self.norm2 = torch.nn.LayerNorm(d_model)
def forward(self, x):
# 自注意力
attention_output = self.self_attention(x, x, x)
# 残差连接和层归一化
x = self.norm1(x + attention_output)
# 前馈网络
ff_output = self.feedforward(x)
# 残差连接和层归一化
x = self.norm2(x + ff_output)
return x
这个类就是一个Transformer编码器层的伪代码。解码器层其实也差不多,就是多了一个注意力子层,自己可以动手试试。
5. 应用示例
最后,我们来看看一个简单的NLP任务中如何使用Transformers。比如,文本分类:
import torch
import torch.nn as nn
from transformers import DistilBertTokenizer, DistilBertModel
class TextClassifier(nn.Module):
def __init__(self, num_classes):
super(TextClassifier, self).__init__()
self.tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
self.bert = DistilBertModel.from_pretrained('distilbert-base-uncased')
self.fc = nn.Linear(768, num_classes)
def forward(self, text):
input_ids = self.tokenizer(text, return_tensors='pt')['input_ids']
output = self.bert(input_ids)[0][:, 0, :]
logits = self.fc(output)
return logits
# 初始化分类器
classifier = TextClassifier(num_classes=2)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
# 假设有训练数据 X_train, y_train,这里省略数据加载过程
# 训练模型
for epoch in range(epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = classifier(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 在测试数据上评估模型
with torch.no_grad():
for inputs, labels in test_dataloader:
outputs = classifier(inputs)
predicted_labels = torch.argmax(outputs, dim=1)
accuracy = (predicted_labels == labels).float().mean()
print(f'Test Accuracy: {accuracy.item()}')
这是一个简单的文本分类器,使用了Hugging Face的Transformers库中的DistilBERT模型。在这里,我们加载了预训练的DistilBERT模型和分词器,然后通过模型得到文本的表示,最后通过一个全连接层进行分类。
这就是一些基本的Transformers函数和代码示例。当然,实际应用中会根据具体任务进行更多的调整和优化。希望这点简单的示例对你有帮助,让你更好地驾驭这个黑马!

















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











