







机器学习是实现人工智能的方法,深度学习是实现机器学习的技术
人工神经网络:是一种模仿生物神经网络的结构和功能的数学模型或计算模型
1、感知器:提出最早的“人造神经元"

多个输入产生一个输出
重要的因素:权重和阈值
权重:各因素的不同重要性
阈值:因素和权重的总和大于阈值,感知器输出1,否则输出0
- 神经元接收N个外界的输入信号
- 输入信号通过带权重的连接进行传递,给本神经元
- 本神经元收到的总输入与本神经元的阈值进行比较
- 通过激活函数处理,产生输出
弊端:感知器网络只能处理线性问题,无法解决异或问题
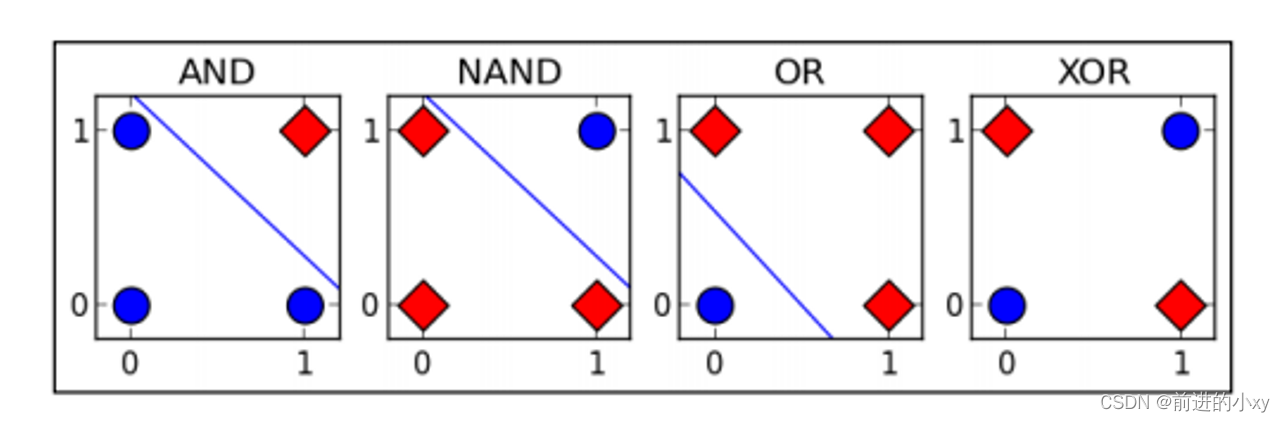
前三种都是线性问题,感知器可以解决,第四种感知器无法解决
2、多层前馈神经网络(所有神经网络鼻祖):比感知器多了一层隐藏层,每个隐藏层中有多个神经元(至少一个),隐藏层不直接接受外界信号也不直接向外界发送信号
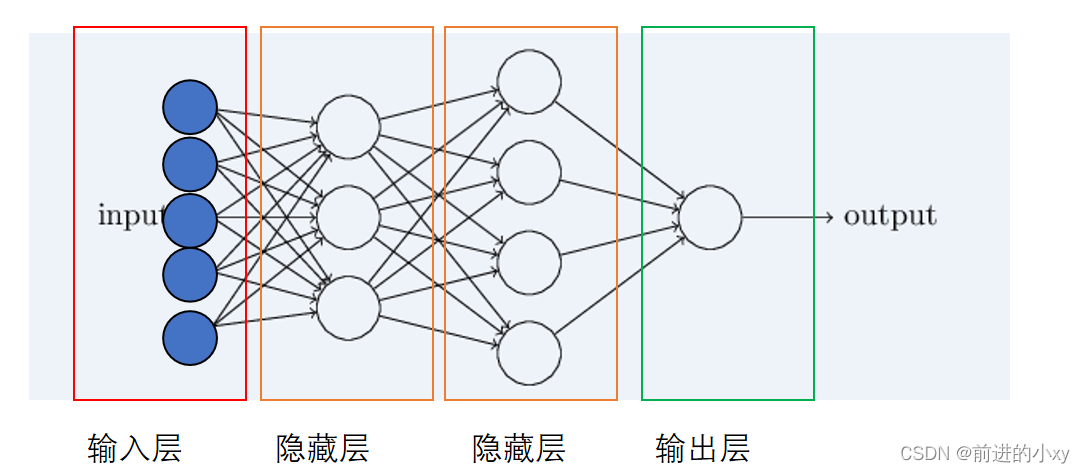
每个隐藏层都有多个神经元,每个神经元都可以对应一个激活函数。解决了感知器不能解决非线性问题的问题。
每一个输入都与所有神经元连接,每个隐藏层之间的神经元又相互连接称全连。导致计算量过大。
弊端:过多的参数,训练时间长。网络的数据单向流动,没对前一层进行反馈。
3、BP神经网络:误差反向传播算法
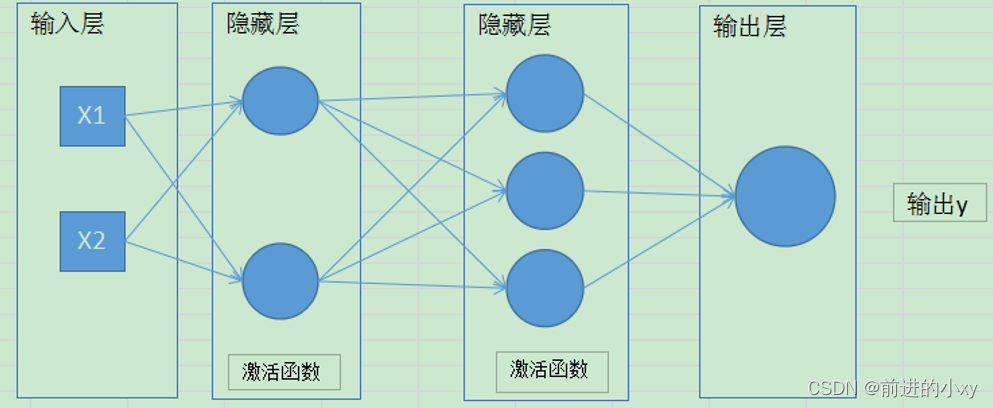
输出值与标记值进行比较,有误差,将误差反向由输出层向输入层传播,利用梯度下降算法对权值进行调整
流程:
- 正向传播:在这个过程中,我们根据输入的样本,给定的初始化权重值W和偏置项的值b, 计算最终输出值以及输出值与实际值之间的损失值.如果损失值不在给定的范围内则进行反向传播的过程; 否则停止W,b的更新。
- 反向传播:将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
先进行正向传播,根据对比目标的误差,方向计算层传递权值的误差,调整权值,再进行正向传播,反复迭代,实现拟合
总结:将输出逐层反转,分摊给各层的所有单元
正向传播:求误差
返向传播:把误差通过音长层逐层向上传导至输入层
模型构建:
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
import tensorflow as tf
import numpy as np
# 加载数据
digits_data = load_digits()
# 查看数据
# print(digits_data)
# print(digits_data.data.shape)
# plt.imshow(digits_data.image[0])
# plt.show()
# 1、数据分割
# 前40做测试
x_test = digits_data.data[:40]
y_test = digits_data.target[:40]
# 剩余训练
x_train = digits_data.data[40:]
y_train = digits_data.target[40:]
# 数据转化:变二维
y_train_2 = np.zeros(shape=(len(y_train), 10))
# 对应的分类——将当前行对应的列变为1
for index, row in enumerate(y_train_2):
row[int(y_train[index])] = 1
hidden_num = 80
input_size = digits_data.data.shape[1]
# 网络搭建
# 占位符 输入到图片中进行计算
# x:输入特征值64像素
x = tf.placeholder(np.float32, shape=[None, input_size])
# y:识别的数字,由几个类别就输入几个
y = tf.placeholder(np.float32, shape=[None, 10])
# 第一层隐藏层:神经元的个数决定输出的个数
# 参数:输入个数 输出个数【神经元个数】
w1 = tf.Variable(tf.random_normal([input_size, hidden_num], stddev=0.1))
# b的个数为隐藏神经元的个数
b1 = tf.Variable(tf.constant(0.01), [hidden_num])
# 第一层计算 w1*x+b1
one = tf.matmul(x, w1) + b1
# 激活函数 当max(0,x) >0就被激活
opt1 = tf.nn.relu(one)
# 第二层隐藏层
w2 = tf.Variable(tf.random_normal([hidden_num, 10], stddev=0.1))
# b的个数为隐藏神经元的个数
b2 = tf.Variable(tf.constant(0.01), [10])
two = tf.matmul(opt1, w2) + b2
opt2 = tf.nn.relu(two)
# 构建损失函数 y预y_predict两者交叉熵
# 衡量损失函数的指标
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=opt2))
# 优化器 求最小损失
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.005).minimize(loss)
init = tf.global_variables_initializer()
train_count = 500
batch_size = 100
data_size = x_train.shape[0]
# 开始会话:
with tf.Session() as sess:
sess.run(init)
for i in range(train_count):
# 数据分组 start,end 第i次训练集开始的位置
start = (i * batch_size) % data_size
# 第i次训练集结束的位置
end = min(start + batch_size, data_size)
batch_x = x_train[start:end]
batch_y = y_train_2[start:end]
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
train_loss = sess.run(loss, feed_dict={x: batch_x, y: batch_y})
print(train_loss)
obj = tf.train.Saver()
obj.save(sess, 'digits/model-digits.ckpt')
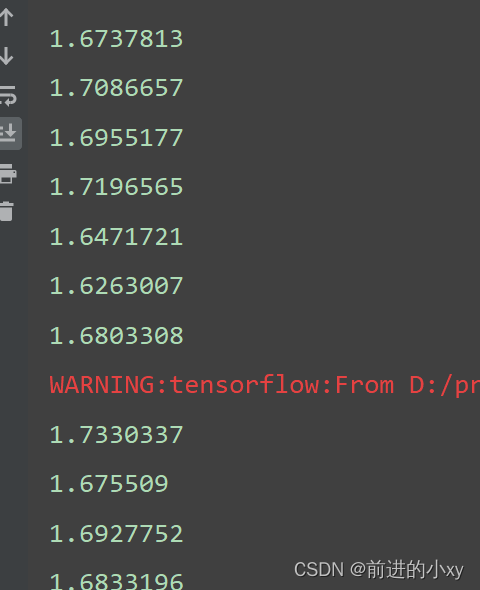
损失率过高
减小误差率方法:
1、适当增加网络隐藏层层数
2、修改参数:学习率、w、b

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









