






什么是OpenAI o1?
OpenAI o1(后面简称o1)是OpenAI在2024.9.12号发布的最新大模型,主要针对的任务是复杂任务推理,比如竞赛难度的编程问题,奥赛难度的数学问题等。参考OpenAI原始介绍:
https://openai.com/index/learning-to-reason-with-llms/openai.com/index/learning-to-reason-with-llms/
OpenAI o1最大的技术特征是什么?
在训练阶段,会通过强化学习,让o1完善其思维链并优化所使用的策略。例如:识别并纠正错误,将复杂步骤拆分为简单步骤,当前方法不work时,换一种方法
在推理阶段,模型同样会在呈现给用户的cot之外,做一个更深的的所谓的long internal chain of thought,所以推理时间会更长,相当于COT套娃了,给COT再加一个COT(猜测是把MCTS搜索过程序列化了,case放在文末)。

值得注意的是,这次OpenAI依然主打了他们一直信奉的Scaling Law,在训练和测试时的时间都能和性能形成对数线性关系。
OpenAI o1到底有多强?
效果不用多说了,跟GPT4-o已经是断崖式差距了,在最难的数学,code,物理化学生物等benchmark上遥遥领先。
- 在全美高中生数学竞赛AIME上,o1能达到74分(GPT4-o仅有12分),如果采样1000次,结合reward model加权投票能到93分,能排进全国前500名,超过USA Mathematical Olympiad的晋级分数线;
- 在GPQA,一个关于物理,化学和生物的智力测试上,OpenAI招募了一群相关领域有博士学位的专家和o1同台竞技, o1能够在GPQA-diamond questions.上超过这群专家。
- 在视觉感知能力后方面,o1 在 MMMU 上取得了 78.2% 的分数,成为第一个与人类专家媲美的模型。

- 值得注意的是,OpenAI在o1的基础上加强了模型的代码能力,以o1为初始化又训了一个o1-IOI,用于参加2024年的国际奥林匹克信息竞赛(2024 International Olympiad in Informatics), 在和人类选手相同的条件下,在10h内解决6道非常难的竞赛问题,每个问题最多允许提交50次。最终,o1-IOI能获得一个216分的分数,在放开提交次数后,o1-IOI能获得362.14,超过了金牌线。这种和人类顶尖选手同台竞技,才是最能反映模型能力的benchmark吧。在CodeForce上,打出了惊人的1807分。

人们更喜欢GPT4-o还是OpenAI-o1?
OpenAI测试了在不同领域的问答上,用GPT4-o和o1匿名回答,大家投票,结果显示,o1只是在理工科方面显著高于4o,比如编程,数据分析和数学题,但是在写作和文本编辑方面和4o相差无几,看起来o1确实是一个偏科的理工科选手。

OpenAI o1的安全性怎么样?
- 将模型需要遵循的准则融入内在COT中,可以高效且稳健鲁棒地教会模型人类偏好的价值和需要遵循的原则,不管是OpenAI内部的安全benchmark还是外部公开的benchmark,o1都能达到极高的水平。更具体的好处有两点:(1)可以让我们(不是,是OpenAI,我们看不到)更清晰地看到模型内在的思维过程;(2)o1关于安全规则的模型推理对于分布外场景(OOD)更加稳健.

OpenAI o1为什么要对用户隐藏internal COT?
翻译了一下OpenAI的原话,主要是为了用户体验和安全问题:
“我们认为隐藏的思维链为监控模型提供了独特的机会。如果思维链忠实且易于理解,它允许我们“读懂”模型的内心并理解其思维过程。例如,将来我们可能希望监控思维链,以识别是否存在操纵用户的迹象。然而,为了实现这一点,模型必须能够以未经过滤的形式表达其想法,因此我们不能将任何政策合规性或用户偏好嵌入到思维链中。同时,我们也不希望让不对齐的思维链直接展示给用户。因此,在权衡用户体验、竞争优势以及追求思维链监控的选项后,我们决定不向用户展示原始的思维链。我们承认这一决定存在缺点。我们努力通过教模型在回答中重现思维链中的有用观点部分来弥补这一不足。对于o1模型系列,我们展示了模型生成的思维链摘要。”
但是实际上,我认为主要是不想让大家蒸馏它的内在思维过程作为训练数据。
一些关于内在思维链的Cases
都太长了,展示不下,知道最重要的一点就行:内在思维链比思维链长的长的多。
-
编程题目
-
- Write a bash script that takes a matrix represented as a string with format ‘[1,2],[3,4],[5,6]’ and prints the transpose in the same format.
- 思维链

-
- 内在思维链

总结
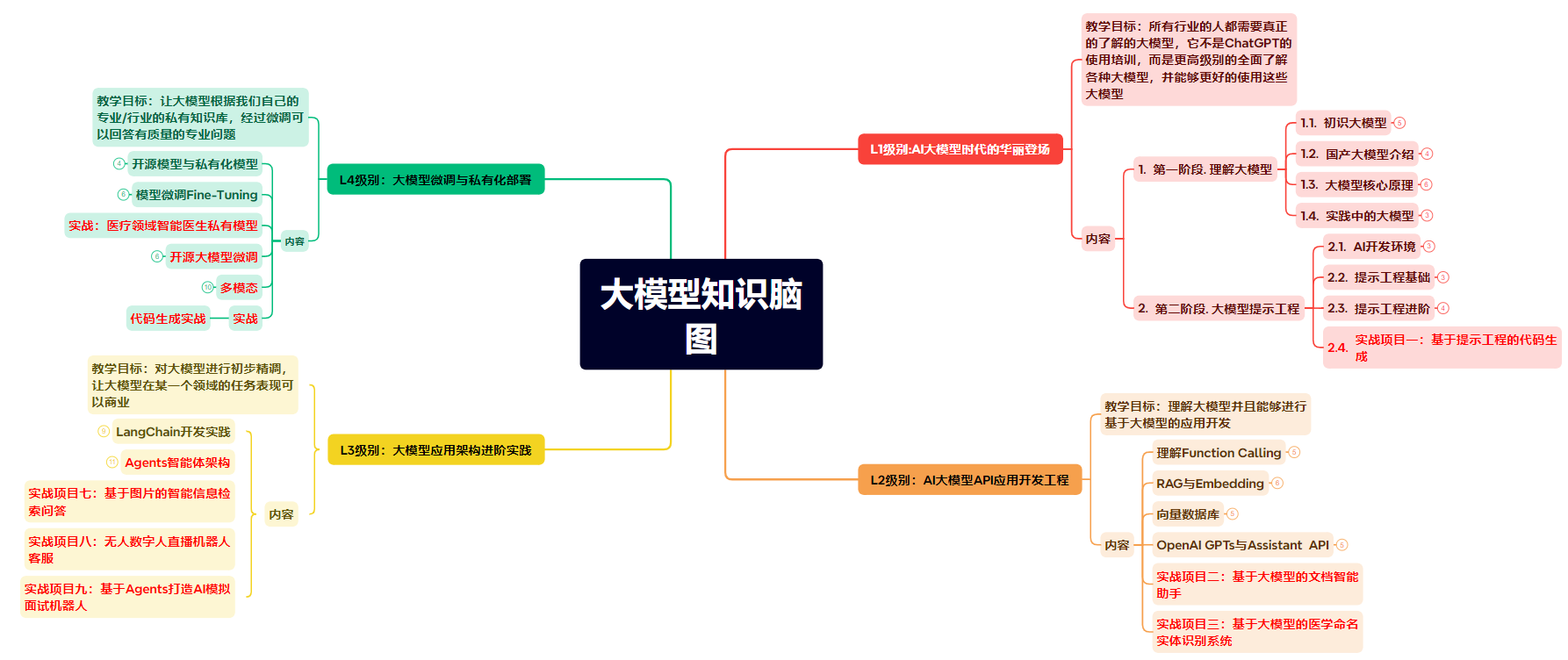
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









