






JVM
1、JVM介绍
Java Virtual Machine Java程序的运行环境(Java二进制字节码的运行环境)
优点:
1、一次编写,到处运行
2、自动内存管理、垃圾回收机制
作用:
类加载器:用于装载字节码文件(.class文件)
运行时数据区:用于分配存储空间
执行引擎:执行字节码文件或本地方法
垃圾回收器:用于对JVM中的垃圾内容进行回收

2、什么是程序计数器
线程私有的(不存在线程安全问题),每个线程都有一份,内部保存字节码的行号。用于记录正在执行的字节码指令的地址。
3、介绍一下Java堆
1、Java堆是一个线程共享区域,主要用于保存对象实例,数值等,内存不够则抛出OutOfMemoryError异常
2、组成:年轻代+老年代
年轻代被划分为三部分,Eden区和两个大小严格相同的survivor区
老年代主要保存生命周期长的对象,一般是一些老的对象
3、jdk1.7和1.8的区别
①1.7中有一个永久代,存储的是类信息、静态变量、常量、编译后的代码
②1.8移除了永久代,把数据存储到本地内存的元空间中,防止内存溢出


4、什么是虚拟机栈
每个线程运行所需要的内存,称为虚拟机栈
每个栈由多个栈帧(frame)组成,对应着每次方法调用时所占用的内存(每个方法执行时会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口等信息)
每个线程只能有一个活动栈帧,对应着当前正在执行的方法
局部变量表里存储基本数据类型、returnAddress类型(指向一条字节码指令的地址)、对象引用。局部变量所需的内存空间编译期间确定。
操作数栈存储运算结果以及运算的操作数,不同于局部变量表通过索引的方式来访问,而是通过压栈和出栈的方式
1、垃圾回收是否涉及栈内存
不涉及,垃圾回收主要指堆内存,当栈帧弹出栈后,栈内存就会释放
2、栈内存分配越大越好吗
不是,默认栈内存通常是1024k(1M)
每个线程都会创建一个虚拟机栈,栈内存过大会导致线程数变少。例如,机器总内存为512m,目前能活动的线程数则为512个,如果把栈内存改为2048k,能活动的栈帧就会减半。
3、方法内的局部变量是否线程安全
不一定
如果方法内的局部变量没有逃离方法的作用范围,他是线程安全的
如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全问题
4、栈溢出和堆溢出的情况
栈溢出
栈帧过多导致栈内存移除(递归调用)
堆溢出
启动参数内存值设置太小
内存中加载的数据量太大,如一次性从数据库取出大量数据
5、堆栈的区别
栈内存一般用来存储局部变量和方法调用,但堆内存用来存储Java对象和数组。
堆会GC垃圾回收,而栈不会
栈内存是线程私有的,而堆内存是线程共有的
两者异常错误不同:
栈内存不足:java.lang.StackOverFlowError
堆内存不足:java.lang.OutOfMemoryError


5、解释下方法区/永久代
1、介绍下方法区
方法区(Method Area)是各个线程共享的内存区域
主要存储类的信息、运行时常量池
虚拟机启动时创建,关闭虚拟机时释放
如果方法区中内存无法满足分配需求,会抛出OutOfMemoryError:Metaspace
很少发送GC,在这里的GC主要是对方法区内常量池和对类型的卸载
2、介绍常量池与运行时常量池
常量池:可以看作是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息。
当类被加载,他的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。


6、直接内存
并不属于JVM的内存结构,不由JVM进行管理。是系统内存
常见于NIO操作时,用于数据缓冲区,分配回收成本较高,但读写性能高,不受JVM内存回收管理
使用传统的io操作进行文件拷贝时,拷贝的文件先由磁盘读入系统缓冲区,java不能直接操作系统缓冲区,所以需要将系统缓冲区内容读入java缓冲区,这样会有两个缓冲区,造成不必要的数据的复制。NIO操作时,java代码能直接访问直接内存,避免了数据的重复复制。



7、本地方法栈
为Native方法服务,和虚拟机栈类似
8、什么是类加载器
JVM只会运行二进制文件,类加载器的作用就是将字节码文件加载到JVM中,从而让Java程序能够启动。
启动类加载器(BootStrap ClassLoader):加载JAVA_HOME/jre/lib目录下的库(Java核心库)
扩展类加载器(ExtClassLoader):加载JAVA_HOME/jre/lib/ext目录中的类(Java扩展库),由Java语言编写,是ClassLoader的子类
应用类加载器(AppClassLoader):加载classPath下的类,是ClassLoader的子类,加载我们写的类
自定义类加载器(CustomizeClassLoader):自定义类继承ClassLoader,实现自定义类加载规则,如tomcat、spring等框架的内部实现
9、双亲委派机制
类的加载器体系并不是继承关系,而是委派体系。
当类的加载器接收到加载类的请求时,首先不会自己尝试加载这个类,而是委托自己的父类加载器完成,直到启动类加载器,然后向下加载。如果上级类加载器加载了,子类加载器就不会加载,没有子类加载器尝试加载。
原因:
1、避免某个类被重复加载(父类已经加载的不许重复加载)
2、保证类库API不会被修改
10、 类的生命周期(类的装载过程)
类在内存中完整的生命周期为:加载——>使用——>卸载。其中加载,分为装载、链接,初始化三个阶段。
装载:将.class文件读入内存,使用类的加载器为之创建一个Class对象
链接分为三个阶段:
验证:确保加载的类的信息符合JVM规范(以cafebabe开头)
准备:为类变量(static)分配内存并初始化默认值
初始化:类中的符号引用替换为直接引用(比如:方法中调用了其他方法,方法名可以理解为符号引用,直接引用就是用指针直接指向方法)
初始化:执行类的构造器<clinit>方法的过程,同时对静态变量,静态代码块初始化
使用:JVM开始从入口方法执行用户代码
卸载:Class对象的销毁,最后JVM退出内存
子类初始化时,如果父类还没初始化,会引发父类先初始化
子类访问父类静态变量,只触发父类初始化

11、对象什么时候可以被垃圾器回收
如果对象没有任何的引用指向它了,那么这个对象就是垃圾,如果定位了垃圾,就可能会被垃圾回收器回收。
如果要定位什么是垃圾,有两种方式确定:引用计数法、可达性分析算法
引用计数法:一个对象被引用了一次,在当前对象递增一次引用次数,如果这个对象引用次数为0,代表这个对象可回收
可达性分析算法:扫描堆中的对象,看能否沿着GC Root对象为起点的引用链找到该对象,找不到,表示可以回收



12、JVM回收算法有哪些
标记清除算法
垃圾回收分为2个阶段,分别是标记和清除,效率高,有磁盘碎片,内存不连续,用的比较少
复制算法
标记清除算法一样,将存活对象都向内存另一端移动,然后清除边界之外的垃圾,无碎片,对象需要移动,效率低,常用于老年代的垃圾回收
标记整理算法
将原有内存空间一分为二,每次只用其中的一块,正在使用的对象复制到另一个内存空间中,然后将该内存空间清空,交换两个内存的角色,完成垃圾回收,无碎片,内存使用率低,常用于年轻代的垃圾回收



13、JVM的分代回收
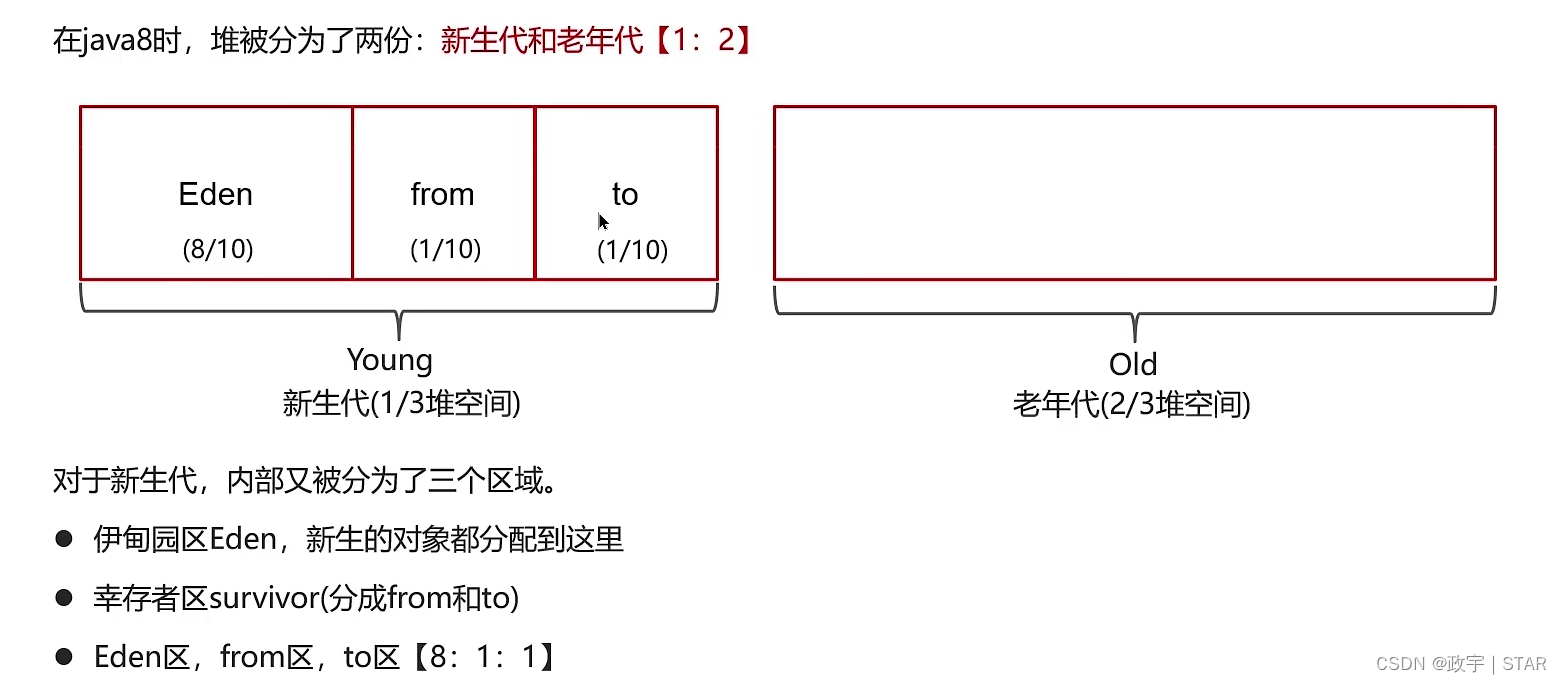
1、堆的区域划分
①堆被分成了两份:新生代和老年代【1:2】
②对于新生代,内部被分成了三个区域。Eden区,两个幸存者区(分成from和to)【8:1:1】
2、对象的回收策略
①新创建的对象,都会先分配到eden区
②当eden区内存不足,使用可达性分析算法标记eden区与from(现阶段没有)的存活对象
③将存活对象采用复制算法复制到to中,复制完毕后,eden区和from区内存被释放
④经过一段时间后eden区再次内存不足,标记eden区和to区存活的对象,将其复制到from区
⑤当幸存区的对象熬过几次回收(最多15次),晋升到老年代(幸存区内存不足或大对象会提前晋升)
MinorGC、MixedGC、FullGC的区别是什么
MinorGC【young GC】:发生在新生代的垃圾回收,暂停时间短(STW)
Mixed GC:新生代和老年代部分区域的垃圾回收,G1收集器特有
FullGC:新生代和老年代完整垃圾回收,暂停时间长,应尽力避免
STW(Stop-The-World):暂停所有应用线程,等待垃圾回收的完成
14、JVM有哪些垃圾回收器
jvm中,实现了多种垃圾回收器,包括:
串行垃圾收集器:Serial GC、Serial Old GC
并行垃圾收集器:Parallel Old GC、ParNew GC
CMS(并发)垃圾收集器:CMS GC,作用于老年代
G1垃圾收集器,作用于新生代和老年代
串行垃圾收集器

并行垃圾收集器

CMS并发垃圾收集器

15、G1垃圾回收器
1、应用于新生代和老年代,jdk9之后默认使用G1
2、将堆划分成多个区域,每个区域都可以充当eden、survivor、old、humongous(巨型对象)
3、采用复制算法
4、响应时间和吞吐量兼顾
5、分成三个阶段:新生代回收、并发标记、混合收集
6、如果并发失败(即回收速度跟不上创建速度),会触发Full GC
第一阶段:新生代回收
初始时,所有区域都处于空闲状态
当创建了一些对象,挑出一些空闲区域作为eden区存储对象
当eden区需要回收时,挑出一些区作为幸存者区,使用复制算法复制存活的对象(需要暂停用户线程)
一段时间后,eden区内存又不够了
将eden区幸存者对象以及幸存者区幸存的对象,采用复制算法,复制到新的幸存者区,其中比较老的晋升到老年代。
第二阶段:并发标记阶段
当老年代占用内存超过阈值(默认45%)后,触发并发标记,这时无需暂停用户进程,并发标记完成后进入到第三阶段
第三阶段:混合回收
并发标记后,会有重新标记解决漏标问题,此时需要暂停用户线程
之后就知道了老年代有哪些存活的对象,随后将新生代和老年代的部分垃圾对象进行回收(根据预期的暂停时间优先回收价值高即存活对象少的区域)
(6)强引用、软引用、弱引用、虚引用
垃圾回收时,不同引用垃圾回收情况不同
强引用:GC Root直接关联的对象,不会被回收
软引用:需要配合SoftReference使用,当垃圾多次回收,内存依然不够时会回收
弱引用:需要配合WeakReference使用,只要进行垃圾回收,就会回收
虚引用:必须配合引用队列使用,被引用对象回收时,会将虚引用入队,由Reference Handler线程调用虚拟引用相关方法释放直接内存(使用了不属于JVM管理的资源,所以先回收对象,再通过队列里面的找到外部资源释放)



16、JVM实践
(1)JVM调优的参数在哪里设置
war包部署在tomcat中设置
jar包部署在启动参数中设置
(2)JVM调优参数有哪些
对于jvm调优,主要是调整年轻代、老年代、元空间的内存大小以及使用的垃圾回收器类型
设置堆空间的大小
虚拟机栈的设置
年轻代eden区和两个幸存者区的大小比例
年轻代晋升老年代的阈值
设置垃圾回收器




(3) JVM调优工具

(4)Java内存泄漏排查思路
堆内存泄漏排查:
1、获取堆内存快照dump文件(jmap命令/使用vm参数获取)
2、VisualVM分析dump文件
3、定位内存溢出问题
(5)CPU飙高排查方案与解决思路
1、使用top命令查看cpu占用情况,找到哪一个进程占用cpu较高
2、使用ps命令查看进程中的线程信息
3、使用jstack命令查看进程中哪些线程出了问题
多线程
1、线程与进程的区别
进程是正在运行程序的实例,进程中包含了线程
不同的进程使用不同内存空间,当前进程下所有的线程可以共享内存空间
线程更轻量,线程上下文切换成本一般比进程低
进程是操作系统调度和分配资源的最小单位,线程是cpu调度和执行的最小单位
2、并发与并行的区别
并行(parallel):多条指令同一时刻运行,宏观微观都是同一时刻运行
并发(concurrency):多条指令同一时段运行,宏观上同一时刻,微观上依次执行
3、线程创建的方式
1、继承Thread类重写run方法(线程执行体)
2、实现Runable接口重写run方法
3、实现Callable接口
4、使用线程池
4、runable和callable的区别
1、Runable接口run方法没有返回值
2、Callable接口call方法有返回值,是个泛型,能够获取线程执行的结果
3、Callable的call方法允许抛出异常,Runable的run方法只能内部try catch
5、线程包括哪些状态,状态之间如何变化
JDK1.5之前有5种状态:新建、就绪、运行、阻塞和死亡,之后有6种状态:新建(new)、可运行(Runable)、锁阻塞(Blocked)、无限等待(waiting)、计时等待(timed_waiting)、终止(terminated)
1.5之前线程状态:
新建一个线程对象就是新建状态
调用start()进入就绪态
获得cpu执行权就由就绪态进入运行态
失去cpu执行权或调用yield方法就从运行态切换为就绪态
线程正常执行结束或者执行stop方法或者出现Error/Exception线程会死亡
运行态进入阻塞态有很多方法,比如wait方法,调用方法notify就进入就绪态
1.5之后可以理解为将阻塞态分为三个状态:锁阻塞、无限等待和计时等待
在可执行状态过程中,如果没有获取cpu执行权,可能会切换到这三个状态中的一个:
比如:
①如果没有获取锁(synchronized或lock)进入锁阻塞状态,获得锁在切换为可执行状态
②如果调用了没设置时间的wait方法,就进入无限等待状态,调用notify方法可切换为可执行状态
③如果调用了设置超时时间的sleep方法,进入计时等待状态,超时后切换为可执行状态
为什么1.5之后就绪态和运行态合并为可运行态:
因为对Java对象来说,只能标记为可运行,至于什么时候运行,不是由JVM控制,而是由操作系统来调度的,而且时间十分短暂,因此对于Java对象的状态来说,没必要区分。
运行——>阻塞:suspend(挂起)、wait()、join(在A中通过B调用join,阻塞A直到B运行完成)、sleep()、等待同步锁
阻塞——>就绪:resume(恢复)、wait时间到、notify()/notifyAll()、join线程结束、sleep时间到、获取同步锁


6、sleep与wait的区别
共同点:都能将线程阻塞
不同点:
sleep方法属于Thread类,wait方法属于Object类
两个方法都可以设置超时时间,但wait方法可由notify方法唤醒
sleep方法进入阻塞状态不会释放锁(我放弃cpu,你们也用不了),wait方法进入阻塞状态会释放锁
wait方法调用必须先获取wait对象的锁(配合synchronized使用,不然会IllegalMonitorStateException),而sleep方法没有这个限制
7、新建三个线程,如何保证他们按顺序执行
可以使用线程中join方法解决
在A中通过B调用join,阻塞A直到B运行完成
8、notify和notifyAll的区别
notify唤醒一个进程
notifyAll唤醒全部进程
9、线程的run和start的区别
调用run方法和调用普通方法没区别,可以调用多次
start用来启动线程,通过该线程调用run方法里面的逻辑,start()只能调用一次
10、如何停止一个正在运行的线程
1、使用退出标注(volatile boolean flag=false),使线程正常退出
2、使用stop方法强制退出
3、使用interrupt方法中断线程
11、synchronized关键字的底层原理
synchronized对象锁,采用互斥的方式同一时刻最多有一个线程能持有对象锁,其他线程再想获取时就会阻塞。
底层是Monitor(监视器),由jvm提供,c++实现。其中有三个属性Owner、EntryList、WaitSet。owner关联获得锁的线程,entrylist关联处于阻塞状态的线程,waitset关联处于waiting状态的线程。
当一个线程进入synchronzied代码块之后,会让对象锁与Monitor进行关联。检查一下Oener是否为null,如果为null就可以持有这个锁,如果不为null,就在EntrySet中等待,也就是阻塞。如果线程调用了wait方法,就会进入waitSet。

Monitor实现的锁属于重量级锁,了解过锁升级吗
Java中的synchronized锁有偏向锁、轻量级锁、重量级锁三种
重量级锁:底层使用Monitor实现,多线程竞争锁,会升级为重量级锁。里面涉及用户态和内核态的切换,性能较低
轻量级锁:不同线程交替持有锁,加锁的时间是错开的。每次添加锁记录都是CAS操作,保证原子性。
偏向锁:一段很长时间内只有一个线程使用锁。在第一次获得锁,会有一个CAS操作,之后该线程获得锁,只需判断mark word中是否是自己的线程id即可。
12、JMM(Java内存模型)
JMM(Java内存模型),定义了共享内存(eg:成员变量,数组等)中多线程读写操作的行为规范,通过这些规范来规范对内存的读写操作从而保证指令的正确性。
JMM将内存分为工作内存和主内存,工作内存是私有线程的工作区域,主内存是所有线程的共享区域。线程跟线程之间相互隔离,交互需要通过主内存。

13、CAS
CAS(Compare And Swap比较再交换),它体现一种乐观锁的思想,在无锁情况下保证线程操作共享数据的原子性。
CAS底层调用Unsafe类中的方法,操作系统提供的,C/C++实现
操作共享变量时使用自旋锁,效率上更高
线程A读取了主内存中的值比如100,进行+1操作变成101,此时意图同步进主内存,首先使用线程A的工作内存中旧的预期值也就是100和主内存中值进行对比,结果是相等,将更新的值101同步进主内存。如果在A操作同时B对数据进行修改,比如-1,此时B意图同步数据,B的工作内存中存在旧的预期值100,此时主内存中是101,不相等,会发生自旋。也就是线程B再次读取主内存中的值101,进行-1的操作,再次比较同步。

乐观锁与悲观锁:
CAS是基于乐观锁的思想:不怕别的线程来修改共享变量,就算修改了也没关系,继续重试
synchronized是基于悲观锁的思想:防着其他线程来修改共享变量,一个线程上了锁其他不能修改,直到释放锁。
14、AQS
AbstractQueueSynchronizer,抽象队列同步器。juc提供的一种锁机制。
synchronized AQS 关键字,c++实现 Java实现 悲观锁,自动释放锁 悲观锁,手动开启关闭 锁竞争激烈都是重量级锁,性能差 锁竞争激烈时提供了多种解决方案 AQS常见的实现类:
ReentrantLock 阻塞式锁
Semaphore 信号量
CountDownLatch 倒计时锁
什么是AQS
1、 AQS是多线程中的队列同步器,是一种锁机制,它是作为一个基础框架使用的,像ReenteantLock、Semaphore是基于AQS实现的
2、AQS中有一个属性state,用volatile修饰的保证线程之间的可见性。这个属性有两种状态:0和1,0是无锁状态,1是加锁状态。线程获取锁之前会判断是否是0,如果是就获取锁,如果不是:AQS内部维护了一个先进先出的双向队列,队列中存储排队的线程。
多个线程共同抢这个资源如何保证原子性
CAS
AQS是公平锁还是非公平锁
两种都实现了
新的线程与队列中的线程共同来抢资源,就是非公平锁
新的线程到队列中等待,只让队列中的head线程获取锁,是公平锁
15、ReentrantLock的实现原理
ReentrantLock支持重新进入的锁,调用lock方法获得锁后,再次调用lock,不会阻塞
ReentrantLock主要利用CAS+AQS实现
支持公平锁和非公平锁,在提供的构造器中无参默认是非公平锁,也可以传参true设置为公平锁


16、synchronized和Lock有什么区别
语法层面
synchronized是关键字,源码在jvm中,用c++实现
Lock是接口,源码由jdk提供,用java语言实现
使用synchronized时,退出同步代码块会自动释放锁,而使用Lock时需要手动调用unlock方法释放锁
功能层面
二者都属于悲观锁、都具备互斥、同步、锁重入功能
Lock提供许多synchronized不具备的功能,例如公平锁、可打断、可超时、多条件变量
Lock有适合不同场景的实现,如ReentrantLock、ReentrantReadWriteLock(读写锁)
性能层面
在没有竞争激烈时,synchronized做了优化,如偏向锁、轻量级锁
在竞争激烈时,Lock通常性能更高
可打断
线程在等待锁时直接打断,不再等待锁
可超时
超过某个时间不在等待锁
多条件变量
按照条件进行等待和唤醒
17、死锁产生的条件
不同的线程分别占用对方需要的同步资源不放弃 , 都在等待对方放弃自己需要的同步资源,就形成了线程的死锁。
诱发死锁的原因:
互斥条件:基本无法破坏,线程需要互斥来保证安全
占用且等待:一次性分配所有资源,就不存在等待的问题
不可抢占:占用部分资源的线程在进一步申请其他资源时,如果申请不到,就主动释放自身资源
循环等待:将资源改为线性顺序,按序申请
18、如何进行死锁诊断
当程序出现了死锁现象,可以使用jdk自带的工具:jps和jstack
jps:输出jvm中运行的进程状态信息
jstack:查看进程中线程的堆栈信息,查看日志,检查是否有死锁
可视化工具jconsole、VisualVM可以检查死锁问题
19、volatile的理解
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,就具备两层含义:
①保证线程之间的可见性
volatile修饰的共享变量,能够防止编译器等优化的发生,让一个线程对共享变量的 修改对另一个线程可见
②禁止进行指令重排序
用volatile修饰共享变量会在读、写共享变量是加入不同的屏障,阻止其他读写操作越过屏障,从未达到阻止指令重排的效果
保证线程之间的可见性
boolean stop=false; while(!stop){ i++; } JVM中有一个即时编译器JIT,会优化代码: while(true){ i++; }在stop变量加上volatile,jit不会对volatile进行优化,其他线程修改stop值,能够共享。
禁止指令重排序
添加规则:
写变量让volatile修饰的变量在代码的最后位置
读变量让volatile修饰的变量在代码最开始的位置


20、ConcurrentHashMap
ConcurrentHashMap是线程安全的HashMap
jdk1.7
采用分段的数组+链表实现
Segment数组不可扩容,默认容量16
计算key的hash值定位到Segment数组的下标,使用ReentrantLock锁住这个节点,当并发添加元素时,使用CAS来获取锁,当某一个线程获得CAS锁,用hash值定位hashEntry数组的下标从而添加元素
jdk1.8
放弃了Segment数组,采用和hashmap一样的结构,数组+链表+红黑树
采用CAS添加新的节点,采用synchronized锁锁定链表或红黑树的首节点,相对Segment分段锁粒度更细,性能高



21、导致并发程序出现问题的根本原因
Java程序中怎么保证多线程的执行安全
Java并发编程的三大特性:
原子性:一个线程在CPU中操作不可暂停,也不可中断,要么执行完成,要么不执行
,使用synchronized或lock锁来实现
可见性:一个线程对共享变量的修改对另一个线程可见,使用volatile关键字实现
有序性:指令顺序执行,使用volatile关键字实现
22、线程池的执行原理
线程池的核心参数
corePoolSize核心线程数
maximunPoolSize最大线程数=核心线程数+救急线程的最大数目
keepAliveTime生存时间:救急线程的生存时间,生存时间内没有新任务,此资源会释放
unit时间单位:救急线程的生存时间单位,如秒、毫秒等
workQueue阻塞队列:当没有空闲核心线程时,新来的任务会加入此队列排队,队列满会创建救急线程执行任务
threadFactory线程工厂:可以定制线程对象的创建,例如是否守护线程等
handler拒绝策略:当所有线程都在繁忙,workQueue也放满时,会触发拒绝策略

首先提交一个任务,先判断核心线程是否满了,没有就添加到工作线程并执行,满了判断阻塞队列是否满了,没有添加到阻塞队列排队,满了判断线程数是否大于最大线程数,小于就创建非核心线程执行任务,大于就执行拒绝策略。
23、线程池中常见的阻塞队列
workQueue-当没有空闲核心线程时,新来的任务会加入到阻塞队列
1、ArrayBlockingQueue:基于数据的有界阻塞队列,FIFO,强制有界(创建必须给大小)。一把锁。
2、LinkedBlockingQueue:基于链表的有界阻塞队列,FIFO,默认无界,支持有界。两把锁,出队入队互不影响,效率高。
3、DelayedWorkQueue:优先级队列,任务可以设置时间,每次出队列的都是时间靠前的
4、SynchronousQueue:不存储元素的阻塞队列,每个插入必须等待一个移出操作
24、如何确定核心线程数
并发不高、任务执行时间长
IO密集型任务:核心线程数=2N+1(N为CPU核心数)
比如:文件读写、DB读写、网络请求等
CPU密集型任务:核心线程数=N+1 (需要大量使用cpu,设置少一点,减少线程切换)
比如:计算型代码、BitMap抓换、Gson转换等
高并发、任务执行时间短
N+1 减少上下文切换
高并发、任务时间长
解决方案不在于线程池,而在于缓存、服务器
25、线程池的种类
java.util.concurrent.Executors类中提供了创建线程池的静态方法,常见4种:
1、固定线程数的线程池FixedThreadPool:核心数和最大线程数一样,超出的线程会在队列中等待
2、单例化的线程池SingleThreadPool:唯一的工作线程来执行,所有任务按FIFO执行
3、可缓存线程池CacheThreadPool:用临时线程来执行任务
4、可执行延迟任务的线程池ScheduledThreadPool
26、为什么不建议用Executors建立线程池
不建议使用Executors创建,而是ThreadPoolExecutor的方式,这样让开发者明确线程池的参数,避免内存溢出。比如FixedThreadPool和SingleThreadPool的阻塞队列是无界的,可能会导致内存溢出。

27、线程池的使用场景
CountDownLatch:倒计时锁,等待其他线程完成倒计时,才会运行
构造器初始化等待计数值
await() 用来等待技术归零
countDown() 计数减一
使用场景一(es数据批量导入)
项目上线之前,需要把数据同步到es索引库中,但是一次性读取数据会发生内存溢出,可以使用线程池的方式,利用CountDownLatch来控制,就能避免一次性加载过多。
使用场景二(数据汇总)
在电商网站中,用户下单,需要查询数据,数据包含三个部分:订单信息、包含的商品、物流信息。这三块在不同微服务中实现。使用Future获得各个服务的返回值。(多接口汇总数据,使用线程池+Future)

28、如何控制某个方法允许并发访问线程的数量
多线程中提供了一个工具类Semaphore,信号量。在并发情况下,可以控制方法的访问量:
1、创建Semaphore对象,并初始化容量
2、acquire()可以请求一个信号量
3、release()释放一个信号量
29、对ThreadLocal的理解
1、ThreadLocal是一个线程内部存储类,让每个线程各用各自的资源对象,避免争用引发线程安全问题
2、ThreadLocal同时实现了线程内的资源共享
3、每个线程内有一个ThreadLocalMap类型的成员变量,用来存储资源对象
①调用set方法,以ThreadLocal自己作为key,资源对象作为value,放入当前线程的ThreadLocalMap集合中
②调用get方法,就是以ThreadLocal自己作为key,到当前线程中查找关联的资源值
③调用remove方法,以ThreadLocal自己作为key,移除当前线程关联的资源值
4、ThreadLocal内存泄漏问题
ThreadLocalMap中key是弱引用,值为强引用;key会被GC释放内存,value不会。可能会发生内存泄漏。主动remove释放key,value就会避免。

设计模式
1、工厂方法模式
简单工厂模式
抽象产品Coffee
工厂SimpleCoffeeFactory

工厂方法设计模式


抽象工厂模式
工厂方法,只能创建同一种对象,改进须抽象工厂。一个超级工厂创建其他工厂,该超级工厂又称其他工厂的工厂

总结
作用:用于解耦
1、简单工厂
所有的产品都共有一个工厂,如果新增产品,则需要修改代码,违反开闭原则
是一种编程习惯,可以借鉴这种思路
2、工厂方法模式
给每个产品提供一个工厂,让工厂专门负责对于产品的生产,遵循开闭原则
项目中用的最多,Spring也用到
3、抽象工厂方法模式
如果多个纬度的产品需要配合生产,优先采用抽象工厂(工厂的工厂)
2、策略模式

不同登陆方式的选择(微信、手机号、短信)
解析不同类型的excel(xls格式、xlsx)
打折促销(满200减9、满300减39)
物流运费阶梯计算等

3、责任链模式


计算机网络
1、Http
HTTP(Hyper Text Transfer Protocol)超文本传输协议,规定浏览器与服务之间数据传输的规则
特点
1、Tcp
2、请求响应模型:一次请求一次响应
3、http协议是无状态的协议:对于事务没有记忆能力,每次请求响应独立。简单地说,每次请求服务器无法区分是否来源于同一个客户端
缺点:多次请求之间不能共享数据
优点:速度快
http请求数据的格式:
请求头:请求数据第一行(请求方式get/post、资源路径url、请求协议http1.1)
请求头:第二行开始,对本次请求进行详细说明,客户端对服务器的自我介绍,cookie在里面
请求体:post请求有,存放请求参数
get请求:请求参数在路径中,没有请求体
响应格式:
响应行:包含 协议、状态码、响应状态
响应头:服务器的描述信息
响应体:响应数据
响应状态码:
1xx:响应中,临时状态码,表示请求已经接收
2xx:成功
3xx:客户端重定向
4xx:客户端错误:请求不存在的资源404、客户端未被授权405
5xx:服务端错误:程序抛出异常等
Http和Https的区别
HTTP(Hyper Text Transfer Protocol)超文本传输协议,规定浏览器与服务之间数据传输的规则,基于TCP。
Https是http的加强版,可以认为是http+ssl(secure socket layer)。一方面保证数据传输安全,另一方面对访问者增加了验证机制。
主要区别:
1、http是连接是简单无状态的,https的数据传输是经过证书加密的,安全性更高
2、https需要申请证书,证书通常是需要收费的
3、默认端口不同,http默认80端口,https443端口
http1.0和1.1的区别
1、http1.0客户端与服务器端使用短连接,浏览器每次请求都需要需服务器建立一个TCP连接。http1.1使用长连接
2、每一次请求必须在前一个请求的响应到达之后发送,如果前一个请求的响应不到达,后面的请求都会阻塞。http1.1支持管道传输,支持多个请求并行发送,但服务端还是会顺序响应前面的请求
3、http1.0不支持断点续传,每次都会发送全部数据,http1.1支持
http1.1和http2.0的区别
1、http2支持多路复用,允许多个请求和响应在单个TCP连接上并行传输,不用按照顺序一一响应
http1.1需要在一个时间点内处理一个请求
2、头部压缩,http2压缩了请求和响应的头部
3、http2支持流控制,客户端和服务端可以限制传输速率
4、http2使用二进制传输,http1使用文本协议
2、TCP/UDP
Tcp和UDP的区别
相同点:都是传输层的协议
不同点:
1、TCP是面向连接的
通信之前需要三次握手,通信结束四次挥手
点对点通信,每一条TCP连接只能有两个端点,不能广播
全双工通信
UDP是无连接的
无需三次握手
支持一对一、一对多、多对一、多对多方式的通信
2、TCP基于字节流传输
完整的用户消息可能会拆分成多个tcp报文段进行传输
UDP基于报文传输
应用层传下来的数据都是完整的数据,不会差分
3、TCP是可靠传输
tcp会在传输层对大数据包进行分段
tcp报文包含序列号,确保完整接收,丢失重复数据,排序
确认应答机制,收到数据包之后会进行确认
滑动窗口,流量控制,防止包丢失
拥塞控制
超时重传
UDP不可靠传输
不保证消息交付
不保证交付顺序
不进行拥塞控制
不进行流量控制
4、UDP效率高
超时重传时间RTTS
发送端没有受到接收方的确认
TCP采用自适应的算法,动态改变重传时间
最少是RTT(一个往返时间)
Tcp的三次握手和四次挥手
1、客户端发送连接请求报文段。SYN同步位,=1时表示连接请求或连接接收报文,seq=x随机序号
2、服务端返回确认报文段,允许连接。SYN同步位 置1,ACK确认位 置为1,seq=y(随机),ack=x+1(确认号,期待接下来客户端发送的第一个字节)
3、客户端向服务端发送确认的确认,可以携带数据。SYN=0,ACK=1,seq=x+1,ack=y+1
为什么三次握手而不是两次?
防止已失效的请求报文传输到服务端造成请求错误。客户端发送了一个请求连接报文但由于某种原因未到达服务端,客户端重新请求连接,此时服务端接收到了第二次请求连接并建立连接,这时服务端收到了第一次的请求连接报文,造成状态不一致。解决信道不可靠的问题。
四次挥手
1、客户端发送连接释放报文段,表示要关闭tcp连接
2、服务端发送确认字段
此时服务端继续发送未发送完的数据,客户端继续接受数据
3、服务端发送完数据,发送连接释放报文段
4、客户端发送确认报文段,超过一段时间后关闭连接,服务器受到客户端的确认后立即关闭连接
为什么客户端要等待一段时间后才关闭连接?
如果服务端没有受到客户端最后的确认报文,会一直等待,并发送连接释放报文段,此时客户端只需要发送确认报文,服务端就能正常关闭。
3、7层OSI参考模型
物联网输会示用
应用层 与用户产生交互的程序 文件传输FTP、电子邮件SMTP、万维网HTTP
表示层 处理两个通信系统中信息的表示方式(数据格式变换、数据加密解密、数据的压 缩恢复)
会话层 建立、管理、终止会话
传输层 负责两个进程的通信,及端到端的通信(端口号)。传输单位:报文段 Tcp/udp
可靠传输、不可靠传输;差错控制;流量控制(控制发送方的速度);复用分用
网络层 负责不同主机间的通信,把分组从源端发送到目的端。传输单位:数据报
路由选择(最佳路径)、流量控制、差错控制、拥塞控制
IP、IPX、ICMP、IGMP、ARP、RARP、OSPF
数据链路层 把网络层传下来的数据报组装成帧
物理层 在物理媒体上实现比特流的透明传输
4层TCP/IP参考模型
应用层、传输层、网际层、网络接口层
Redis
1、Redis缓存穿透、击穿、雪崩
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查询数据库
解决方案:
①缓存空数据,查询结果为空,仍把这个空结果进行缓存
②布隆过滤器:查询时,先查询布隆过滤器,没有就直接返回,存在继续查询redis。
使用redission实现布隆过滤器,底层是bitmap
缓存击穿:当某个key设置了过期时间,当key过期时,恰好有大量并发请求请求这个key,这些请求可能会把数据库击垮
解决方案:
①添加互斥锁:缓存未命中时,添加互斥锁,查询数据库并写入缓存,释放锁。线程一持锁时,其他线程查询缓存未命中时,获取不到互斥锁,等待一会再查询缓存。
保证数据强一致性,性能差
②逻辑过期:
在设置key时,设置一个过期时间字段一起存入缓存,不给当前key设置过期时间
当查询时,从redis取出数据后判断时间是否过期
如果过期,则获取一个互斥锁,开通另一个线程进行数据同步,当前线程正常返回旧的数据。如果其他线程发现key过期,试图获取互斥锁,获取失败后直接返回旧的数据。等到数据同步之后,释放锁,此时新数据更新完成。
缓存雪崩:同一时段大量的key同时失效或Redis宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
大量key同时失效原因是大量key设置的相同的过期时间,解决方案就是给不同key设置不同过期时间
Redis宕机:Redis集群来解决
给缓存业务添加降级限流策略
2、双写一致(MySQL与Redis同步)
双写一致性:当修改了数据库的数据同时也要更新缓存的数据
允许延时一致的业务,采用异步通知/延时双删:
①使用MQ中间件,更新数据之后,通知缓存删除
②利用canal中间件,不需要修改业务代码,伪装为mysql的一个从节点,canal通过读取binlog数据更新缓存
延时双删:
如果是写操作,先把缓存中数据删除,然后更新数据库,最后延时删除缓存中的数据。
为什么需要需要删两次缓存?
降低脏数据的出现:如果先删除缓存,此时有另一个线程读数据,就会造成数据不一致。如果先操作数据库,线程一查询缓存发现key过期,在查询数据库的过程中,线程二介入更新了数据库,并更新了缓存,此时线程一查询的并要更新的旧数据就和缓存中不一致。
为什么延时双删?
一般情况下,数据库是主从模式,需要一段时间,把主节点的数据同步到从节点,也可能出现问题。
强一致性的,采用Redission提供的读写锁:
共享锁:读锁,加锁之后,其他线程可以读
排他锁:写锁,加锁之后,其他线程不能读写
我们当时是把套餐和菜品的数据存入缓存,这个业务对实时性要求并不高,只是用SpringCache简单处理了一下。

3、持久化
RDB(Redis DataBase Backup file),Redis数据备份文件(Redis数据快照)。把内存中的所有数据记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
命令:
save:主进程执行RDB,会阻塞其他进程
bgsave:子进程执行RDB,避免主进程受影响
AOF(Append Only File),追加文件。Redis每一个命令都会记录在AOF文件,可以看作是命令日志文件。
Redis中提供了两种数据持久化的操作:RDB和AOF
RDB是快照文件,他把redis内存存储的数据写到磁盘上,当Redis实例宕机恢复数据的时候,从RDB快照文件中恢复数据。
AOF是追加文件,记录Redis操作的命令,当Redis实例宕机恢复数据的时候,会从这个文件中再次执行一遍命令来恢复数据。
两种方式,哪种比较快?
RDB是二进制文件,在保存的时候体积比较小,恢复速度快,但有可能丢失数据。AOF有刷盘策略,可以设置每秒批量写入一次命令,丢失数据风险很低。

4、数据过期策略
Redis的key过期后,会立即删除吗?
惰性删除:设置key过期时间后,不去管他,当需要该key时,在检查他是否过期,过期的话删除,反之返回该key
定期删除:每隔一段时间,对一些key进行检查,删除过期的key。(SLOW模式+FAST模式)
Slow模式:定时任务,执行频率默认10hz,每次不超过25ms
Fast模式:执行频率不固定,两次间隔不低于2ms,每次不超过1ms
Redis过期策略:两种配合使用
5、数据淘汰策略
假如缓存过多,内存被占满了怎么办?
数据淘汰策略:当Redis内存不够了,此时在向Redis中添加新的key,那么Redis会按照某一种规则将内存中数据删除。
8种策略:
noeviction:默认 不删除任何数据,内存不足直接报错
LRU与LFU:
LRU:最近最少使用
LFU:最少频率使用
数据库中有1000万条数据,Redis只能缓存20w,如何保证Redis数据都是热点数据?
使用allkeys-lru:挑选最近最少使用的数据淘汰,留下来的都是热点数据


6、Redis是单线程的,为什么会执行这么快
Redis是基于内存操作,执行速度很快
采用单线程,避免不必要的上下文切换,多线程需要考虑线程安全问题
使用IO多路复用模型,非阻塞IO
IO多路复用模型:
Redis是纯内存操作,性能瓶颈是网络延迟,IO多路复用模型实现高效的网络请求。
利用单个线程同时监听多个Socket,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
技术场景
1、介绍下项目
本项目是为一家餐厅定制的一款软件产品,主要包括管理端和小程序端两部分:
管理端提供给餐饮内部员工使用,可以对菜品、套餐、订单、员工等进行管理。
小程序端提供给消费者使用,可以浏览菜品,套餐,添加购物车、下单、催单等操作。
使用到的技术栈有:SSM、SpringBoot、Redis对菜品和套餐数据缓存、JWT登录校验、Swagger做后端接口测试、SpringTask、阿里云对象存储
这是我的课程设计内容,实现了全部后端代码的编写。
2、单点登录
Single Sign On(SSO):只需登录一次,就可以访问所有信任的系统
单个tomcat服务(单体)session可以共享,多个(微服务)就不能共享
登录校验流程:
客户端请求登录接口,通过数据库判断用户是否存在
存在的话,生成jwt令牌,同时将用户id一起保存在令牌中,响应给客户端
客户端将令牌自动保存,请求服务端时,携带在请求头的token中
服务端使用拦截器对token进行校验,同时得到用户id
将用户id保存到ThreadLocal中
Session、Cookie、JWT区别
会话技术:浏览器与服务器的一次连接称一次会话,打开浏览器,访问服务器,会话建立,直到一方断开连接,会话结束(一次会话可以包含多个请求与响应)
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一浏览器,以便在同一会话的多次请求中共享数据为什么会话跟踪:http是无状态的,服务端无法区分请求是否来自同一客户端
跨域:协议,ip,端口号
会话跟踪方案:
1、客户端会话跟踪技术:cookie 存储在浏览器本地,http请求头携带cookie,响应头setCookie。第一次请求服务器会在响应头中响应给客户端cookie,客户端存储在本地,在之后的请求中需要携带cookie。优点:http协议支持
缺点:只能浏览器使用,移动app不支持;cookie存储在客户端,其中的数据不安全;用户可以禁用;不能跨域。
2、服务端会话跟踪技术:session 存储在服务器,基于cookie实现。第一次请求服务器,服务器会生成一个session,然后在响应头的SetCookie中响应给客户端一个JSessionID,浏览器收到之后会将jsessionid保存到本地,在之后请求中会携带。
优点:数据存储在服务端,安全
缺点:基于cookie实现,cookie的缺点几乎都有;服务器集群环境不适用。
3、令牌技术:用户第一次请求服务器,生成令牌(字符串)响应给浏览器,浏览器将令牌存储,可以存储在cookie中也可以存储在其他空间,之后的请求中客户端携带令牌,在服务端进行校验。
优点:服务端不需要存储令牌,只需要检验;支持pc,移动端;支持集群场景。
组成:头.有效载荷.签名 头Header:记录令牌类型,签名算法 有效载荷Payload:携带自定义信息、默认信息(令牌的有效期、签发日期等)等 签名Signature:防止token被篡改,确保安全。将header、payload,并入指定密钥,通过签名算法计算而来 json通过Base64编码成字符串

3、 权限认证
RBAC(Role-Based Access Control)基于角色的访问控制
3个基本部分组成:用户、角色、权限
5张表:用户表、角色表、权限表、用户角色中间表、角色权限中间表
用户登录系统,查询张三拥有的角色列表,在查询角色拥有的权限
权限框架:Spring Security
智慧校园系统用到了5张表来进行权限认证,外卖点餐系统这方面比较简陋,给每个员工和管理员数据库添加了权限字段,通过这个字段来决定权限。
4、上传数据的安全性
使用非对称加密(或对称加密),给前端一个公钥让他把数据加密传到后台,后端负责解密后处理数据。
对称加密:文件加密和解密使用相同的密钥,加密算法也相同。适合文件大的,不能保存敏感信息。比如DES、AES、RC4、IDEA等
非对称加密:公开密钥加密,私有密钥解密。适合文件小的。比如RSA、DSA
5、哪些棘手的问题,怎么解决的
在做管理端登录功能的时候,因为之前只做了账号密码登录,但是后来觉得这个做的过于简单,想加上邮箱登录、手机号登录这些功能。这样直接在业务层里使用if else判断很麻烦,代码也很臃肿。然后就在网上找了下策略,发现使用这个工厂模式和策略模式很容易扩展这个功能。具体方法:
1、定义一个策略接口,让不同的登录方式实现这个接口并实现其登录逻辑,然后把这些策略交给spring容器管理
2、定义一个工厂:工厂读取配置文件里的不同登录策略,通过配置文件定义的不同策略与ioc里的策略对应起来保存到集合中。在提供一个方法,根据不同参数返回集合中的具体策略。
3、业务层只需要注入工厂,根据前端的需要的登录策略从工厂中找到具体策略。
6、日志怎么采集的
@Slf4j注解
Logstash数据收集引擎+Elasticsearch全文搜索引擎+Kibana可视化平台
Linux命令查看日志
1、实时监控日志变化:tail命令
tail -n 100 -f xx.log实时查看日志最后100行日志
2、按照行号查询:tail命令和head命令
head -n 100 xx.log前面100行日志
tail -n 100 xx.log后100行命令
3、关键字查日志:cat命令
cat -n xx.log | grep "debug"包含debug的日志行号
4、按照日期sed
sed -n '/开始日期/,/结束日期/p' xx.log
5、分页查询,日志太多处理方式
cat -n xx.log | grep "debug" | more
7、已经上线的bug排查
分析日志,一般就能定位问题
8、 拦截器怎么配置
1、自定义拦截器类实现HandlerInterceptor接口
2、在配置类中注册自定义拦截器,定义拦截的地址与排除地址
9、nginx反向代理与负载均衡
niginx优点
1、提高访问速度
nginx可以进行缓存,如果访问同一接口,nginx可以直接把数据返回,不需要访问服务器
2、负载均衡
将请求通过一定策略分发给不同服务器
3、保证后端安全
后台服务地址不会暴露,所以浏览器不能直接访问
10、Swagger
Swagger 在开发阶段使用的框架,帮助后端开发人员做后端的接口测试。目前,一般都使用knife4j框架。
knife4j是Swagger的增强解决方案
常用注解:
@Api 类,controller,表示对类的说明 @Api(tags="员工相关接口")
@ApiModel 类,pojo
@ApiModelProperty 属性,描述属性信息
@ApiOperation 方法,说明方法用途 @ApiOperation (value="员工登录")
11、日期格式转换
当前端发送的数据过于长超过16位时,long的精度为16位,导致精度不准确,例如id为雪花算法的自动生成,导致前端发出的请求后端的接收的数据精度受到影响,转换为json格式,就解决了这个问题,包括日期型的相关转化(js对于long类型会造成精度损失)。
解决方案:
1、在pojo属性加注解@JsonFromat(pattern="yyyy-MM-dd HH:mm:ss")
2、使用Spring MVC消息转换器,统一对后端传给前端的数据进行格式化处理
12、公共字段填充
比如:create_time字段等
使用AOP实现
13、阿里云OSS
1、定义OSS配置文件endpoint、access-key-id、access-key-secret、bucket-name
2、定义配置类读取配置文件
3、创建AliOss工具类对象
14、Redis与SpringCache
Redis数据类型
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常见数据类型:
字符串:string
哈希:hash (field1 value1),也叫散列,类似于Java中HashMap
列表:list 类似LinkedList 按照插入排序排序,可以有重复元素
集合:set 类似HashSet,无序集合,没有重复元素
有序集合:sorted set / zset 集合中每个元素关联一个分数score,根据分数升序排序,没有重复元素
常用命令(不区分大小写)
字符串操作命令:
set key value 设置指定key的值,相当于插入
get key 查询
setex key seconds value 设置指定key的值,并将key的过期时间设置为seconds秒
setnx key value 只有在key不存在时设置key的值
常用注解:
@EnableCaching 启动类 开启缓存注解功能
@Cacheable 方法 在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据;如果没有缓存数据,调用方法并将方法的返回值放到缓存中,getById方法上
@CachePut 方法 将方法的返回值放到缓存中,insert方法上
@CacheEvict 将一条或多条数据从缓存删除,delete方法上
15、HttpClient与微信登录
HttpClient作用:
1、发送Http请求
2、接收响应数据
使用步骤:
1、导入依赖
2、创建HttpClient对象
3、创建Http请求对象
4、调用HttpClient的execute方法发送请求,接收结果
5、解析结果
6、关闭资源
微信登陆
微信登陆的核心是通过微信小程序提供的临时凭证code换取永久凭证openid的过程
1、小程序端,调用wx.login()获取code,就是授权码。
2、小程序端,调用wx.request()发送请求并携带code,请求开发者服务器(自己编写的后端服务)。
3、开发者服务端,通过HttpClient向微信接口服务发送请求,并携带appId+appsecret+code三个参数。
4、开发者服务端,接收微信接口服务返回的opendId。判断该用户是否新用户
5、开发者服务端,将openid等数据返回给小程序端,方便后绪请求身份校验。
6、后面的验证和前面用户验证一样了
16、Spring Task
Spring Task是Spring家族提供的任务调度工具,可以按照约定时间自动执行某个代码逻辑
作用:
超时订单处理:用户下单后,一直没有支付。超过我们设置的支付时限15分钟。
解决方案:定时任务每分钟检查一次
派送中订单处理:订单用户已经收到,订单一直处于“派送中”
解决方案:定时任务每天凌晨检查一次
17、WebSocket
WebSocket是基于TCP协议的一种新的 网络协议。实现了浏览器与服务器全双工通信-浏览器与服务器只需要完成一次握手,两者之间就能创建 持久性 连接,并进行双向数据传输。
作用:
用户催单、来单提醒
视频弹幕、网页聊天、实况更新等
18、Apache POI与Apache Echars
Apache poi:生成excel报表
echars:数据统计
19、自定义starter
1、创建xx-starter依赖管理功能,将来在pom文件中引入
2、创建xx-autoconfigure实现自动配置功能并在starter中引入
3、定义自动配置文件xxx.imports,将他放到META-INF/spring/目录下,spring启动会自动加载
4、利用@EnableConfigrationProperties注解将它导入















 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









