






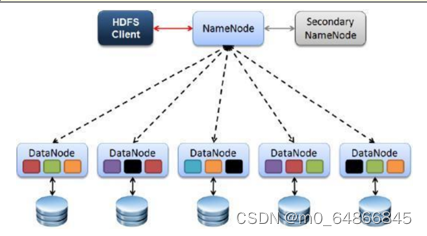
HDFS架构
四个基本组件
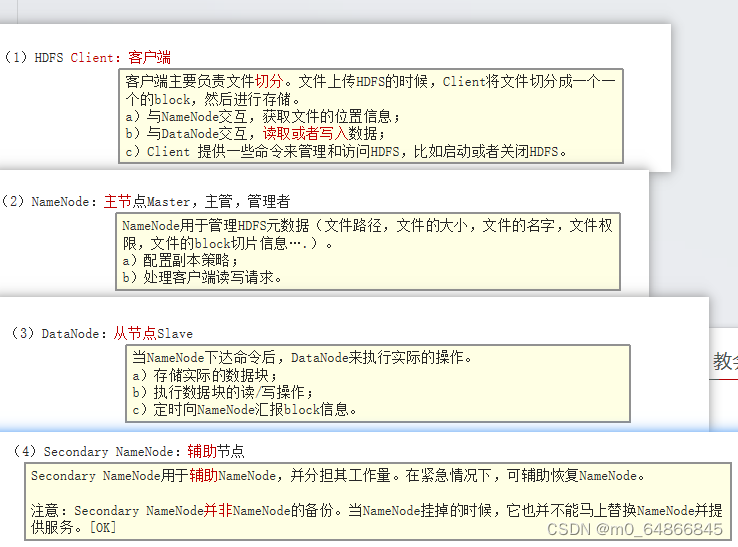
1)HDFS Client
2)NameNode
3)DataNode
4)Secondary NameNode
*
--------------------------------------------------------------------
HDFS的Shell命令
格式
hdfs dfs <args><args>可以是命令,比如ls查看目录、mkdir创建目录、touch创建文件等。
常用命令
例:hdfs dfs –mkdir [-p] /路径名
(1) -ls 查看文件
(2) –mkdir 创建目录
(3) -touch 创建文件
(4)-put 上传文件
(5)-get 下载文件
(6)-mv 移动文件或目录
(7)-rm 删除目录
(8)-cp 复制文件
(9)-cat 查看文件内容
----------------------------------------------------------------------------------------------------
HFDS工作原理及流程
A.分块管理
在存储数据时,HDFS将每个文件以128MB形式存储成一系列的block(数据块),除最后一个外,其他数据块都是128MB。

即三副本机制
B.edits与fsimage的作用
在HDFS中,文件是被划分了一堆堆的block块,如果文件很大且很多,那么NameNode主节点就会负责处理这些问题即: 记录及整理文件和block块的关系
在NameNode主节点中,有:
(1)edits:负责记录文件、块信息,有很多edits
(2)fsimage:会将多个edits合并为fsimage
1) edits是一个流水账文件,记录了HDFS中的每一次操作,以及本次操作影响的文件及对应的block信息。
2)fsimage 为了操作便捷,会将全部的edits,都合并为最终结果,此时,就得到了一个fsimage文件。
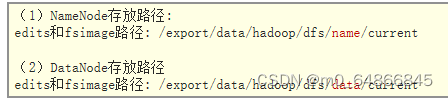
edits和fsimage存放
C.元数据文件
对于元数据的处理遵循:
(1)NameNode:元数据管理维护
(2)SecondaryNameNode:元数据合并
 D.元数据存储原理
D.元数据存储原理

-----------------------------------------------------------------------------------
HDFS存储原理
a.副本机制:
(1)第一副本保存在客户端所在服务器;
(2)第二副本保存在和第一副本不同机架服务器上;
(3)第三副本保存在和第二副本相同机架的不同服务器中
b.负载均衡机制:
对服务器平均分配任务
集群模式使用负载均衡
存储block信息块>>128M一个
此均衡是相对并不绝对
c.心跳机制(hdfs存储)
每隔几分钟发送固定信息,如数据报包(数据包)packet,服务端发送ack应答
三次握手协议
总结:hfds遵循3机制:副本机制\负载均衡\心跳机制
----------------------------------------------------------------------------------------
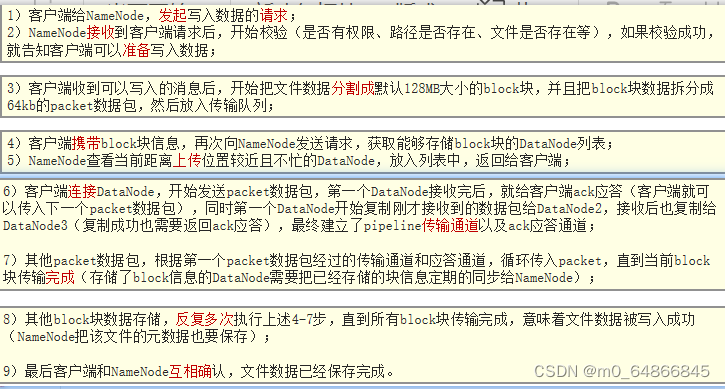
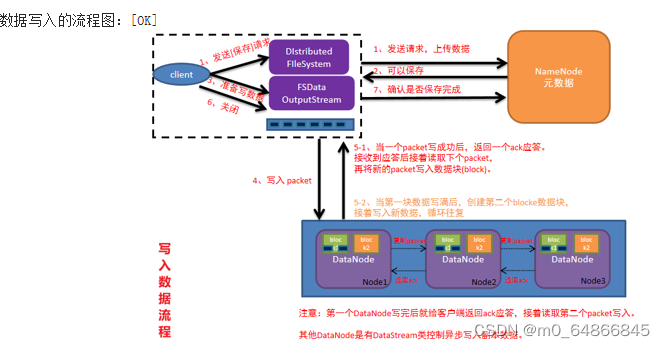
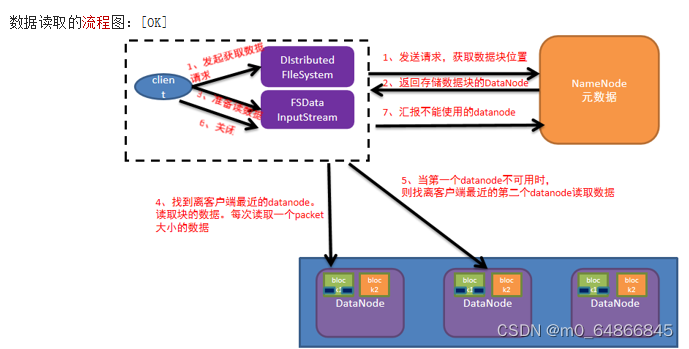
当使用HDFS分布式文件系统存储数据时,有核心的两个步骤:
(1)写入数据
(2)读取数据

写入流程
读数据操作

-------------------------------------------------------------------------------------------------
HDFS常见模式
1)安全模式
HDFS的安全模式指的是:不允许HDFS客户端进行任何修改文件或目录的操作。
2)归档模式
归档后文件结尾为.har
在存入数据文件到HDFS时,会发现每个小文件单独存放到HDFS都会占用一个block块,那么HDFS就需要依次存储每个小文件的元数据信息,浪费资源。当然,归档后也更加便于集中管理
hadoop archive -archiveName 归档名称.har -p 原始文件的目录 归档文件的存储目录
3)垃圾桶模式
所谓垃圾桶模式,类似于Windows系统的回收站















 8137
8137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









