







矩阵分解:

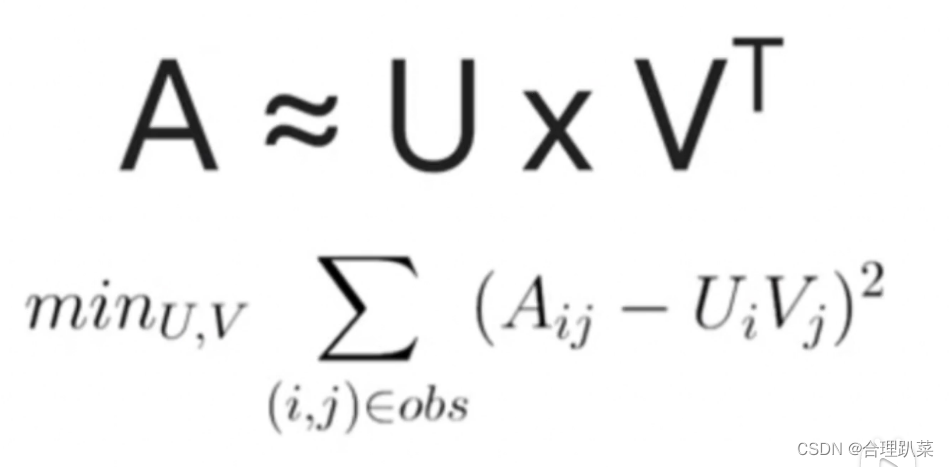
利用矩阵的分解,找出最合适的矩阵使他最接近接近原始矩阵,即以上的数学公式最小化,模式的训练就越成功。-------(扩展:SVD奇异值分解,SGD随机梯度下降,ALS交替最小二乘)
我的理解无论什么模型基本上都是使损失函数的值最小。
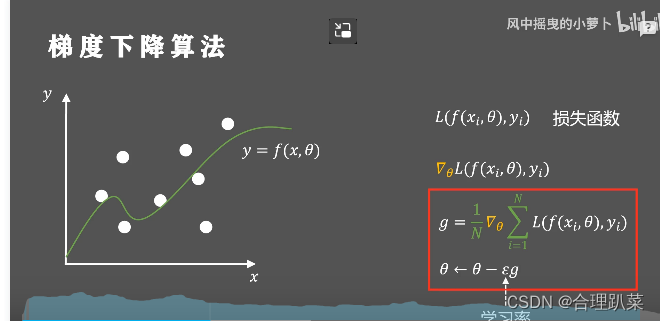
梯度下降算法
利用梯度下降算法使损失函数最小
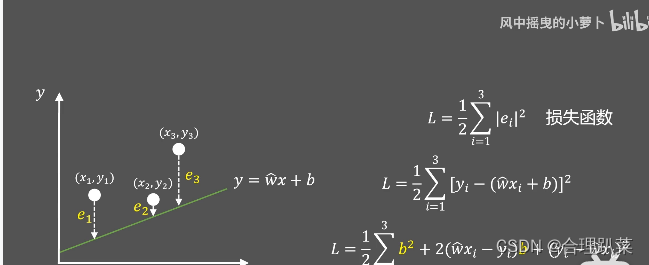
或者利用迭代优化的方式不断进行优化,以此来寻找最优解,

理解:
矩阵分解模型,通过已经存在的用户对项目的评分来训练模型,让模型先学会预测之前存在的评分,其实就是在学习用户兴趣。然后让模型中的用户向量和用户没有买过的项目向量做矩阵乘法,得到值就是用户对项目评分的预测值,这个预测评分高的话,说明用户可能喜欢这个项目,我们把项目就可以推荐给用户。
常见的损失函数模型:
文献中常用的有两种函数:逐点损失(pointwise loss)和成对损失(pairwise loss)。逐点损失一般通过最小化预测值y和目标值y之间的平方误差,使用回归的框架来估计参数。而成对损失的思想是观察到的条目应该比未观察到的条目的评分更高。

 ,激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。在神经元中,输入的input经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。
,激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。在神经元中,输入的input经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。
深度学习笔记:如何理解激活函数?(附常用激活函数) - 知乎 (zhihu.com)
Sigmoid 激活函数


训练模型
如何训练的,还是像矩阵分解一样,给每个用户和项目初始化专属的向量,训练过程中更新向量列表中的向量值,直到用户向量和项目向量做矩阵乘法得到的值能预测真实相关性得分Yu,i。
函数训练?
BPR叫贝叶斯个性化排名推荐
唯一理解的就是相关论文的就是不断的更新损失函数或者算法,使预测的推荐更加准确,其中基本上能够提升效率或者准确度,基本上就能发表一篇不错的论文。















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









