







数据集的构建与处理
将用户的评分显式反馈转换为隐式反馈

作者是在MovieLens数据集和Pinterset数据上进行实验验证,我们在实验中只选择了MovieLens。在我的代码实现中,有记录的为交互过,记录为1,没有记录为未交互,记为0,核心代码如下。这个我的理解是,在rating表中,记录的是交互记录,那么user-item的笛卡尔积减去这些交互记录,就是没有交互记录,
添加负样本

作者在论文中采用的方式是统一采样,从未交互在每一轮的迭代中,确定的采样率。采样方式选择随机采样即可。(作者提到,这样是统一的看待到剩余交互,其实可以考虑物品流行度偏置等等),这篇论文中,作者点到为止,没有再继续讨论。
我在我的代码中通过控制负样本的个数来实现,随机采样。

核心模型构建
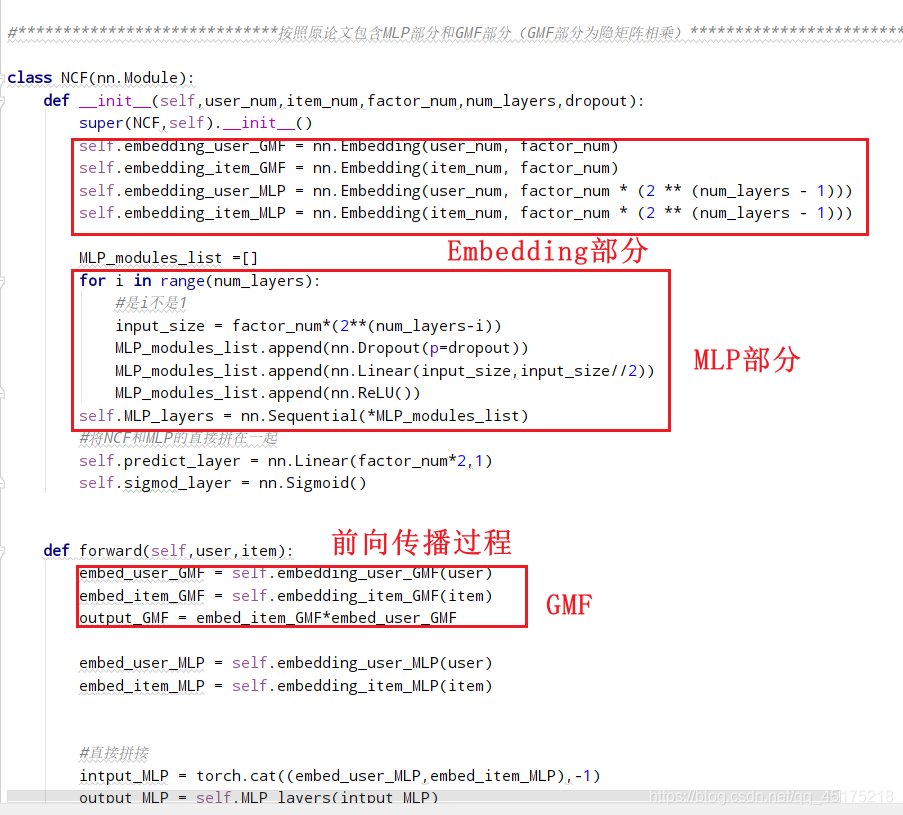
作者在论文与实现中的模型有两部分组成GMF和MLP
GMF部分

作者在实现时,非常简单,直接将User和Item的Embbending层相乘就可。这样的简单处理,但是作者在论文中提到了一个很重要的思想就是,GMF如何泛化为MF?就是相乘只是一种最朴素的交互关系,交互关系甚至可以是复杂的函数关系**。

MLP部分
简单概括MLP部分就是全连接网络。
全连接网络一些设定,首先,作者在论文中详细阐述了为什么选择了Relu函数作为激活函数,并且实验证明Relu好于tanh,远好于sigmoid,相关原因与比较我用红线进行了标出。我在实现中按照论文思路也选择了Relu激活函数。

作者说明了网络的设计结构。每次减少一半神经元数量。这是一种常见的随着层数增加神经元数量减少的塔形结构。

GMF和MLP的融合
如图标红部分所示,在GMF部分是将user的Embedding和item的Embedding对应元素相乘,MLP部分是将user的Embedding和item的Embedding直接拼接,最后在输出部分将模型两部分输出再次拼接。

共享嵌入层,在输入维度必须保持一致,最后输出使用sigmoid激活函数。

为了模型的灵活(flexibility)
在作者的论文和实现中GMF和MLP是独立实现的。也是可以独立训练的。
同时提供了预训练方式和非预训练方式

最终模型部分实现

损失函数构建
BPRloss损失函数如下

实现效果如下图所示

1.推荐系统中的两类损失函数,point-wise损失函数和pair-wise损失函数之间有什么区别?
首先,我最大的感受是,point-wise损失函数,大多数情况下你可以直接调用深度学习框架中已经实现好的部分。Pointwise 方法非常简单,也容易实现。在训练时候,也可以指定Shuffle。因为本身与顺序并无太大关系。
而pair-wise首先就需要自己去构造这样的pair,所以需要自己去实现计算逻辑。因为是一组,自然不能全局Shuffle,可以每个batch读入若干pair。
2.基于深度学习方法的推荐对比之前传统的推荐算法的改进体现在哪里?
这一点在我前面的关于GMF部分泛化MF部分的阐述中就有所体现。相乘只是一种最朴素的交互关系,交互关系甚至可以是复杂的函数关系。传统的方法只是一些简单的相乘或者其他矩阵运算,而深度学习方法通过Embedding物品和用户向量,利用神经网络强大的学习表征能力,来实现物品与用户的特征挖掘,和他们之间复杂交互关系的抽取。
在数据读入部分
在pytorch的实现中,数据读取在pytorch数据集构造中,需要继承DataSet,需要重写len方法和getitem方法。pandlepandle部分比较特殊,它是需要返回一个数据迭代器。**
在pytorch的实现中,数据读取在pytorch数据集构造中,需要继承DataSet,需要重写len方法和getitem方法。pandlepandle部分比较特殊,它是需要返回一个数据迭代器。**
模型搭建,两个深度学习框架在使用细节上有所不同,但是通过查阅API文档,和官网提供的案例,基本一致。自定义损失函数,也采用BPR_loss,所以这一部分需要根据自己在数据读入时的逻辑来写。在上面有详细的介绍。训练与评估逻辑,训练逻辑依照按照,计算出loss,深度学习框架根据我们定义好的前向传播过程帮助我们自动进行反向传播。评估采用HR命中率来进行评估

















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









