







 文章介绍了神经网络协同过滤框架NCF,它扩展了传统的矩阵分解方法,通过多层感知器增强非线性建模能力。NCF在两个现实世界数据集上的实验验证了其有效性。此外,讨论了矩阵分解、似然函数、激活函数的作用,以及欠拟合和过拟合的概念和解决方案。文章还涵盖了深度学习中的模型训练、数据预处理、特征工程和机器学习与深度学习的区别。
文章介绍了神经网络协同过滤框架NCF,它扩展了传统的矩阵分解方法,通过多层感知器增强非线性建模能力。NCF在两个现实世界数据集上的实验验证了其有效性。此外,讨论了矩阵分解、似然函数、激活函数的作用,以及欠拟合和过拟合的概念和解决方案。文章还涵盖了深度学习中的模型训练、数据预处理、特征工程和机器学习与深度学习的区别。
在解决在含有隐形反馈的基础上进行推荐的关键问题----协同过
协同过滤:对用户对项目的偏好进行建模,就是所谓的协同过滤
矩阵分解MF
论文贡献
1、我们提出了一种神经网络结构来模拟用户和项目的潜在特征,并设计了基于神经网络的协同过滤的通用框架NCF。
2、我们表明MF可以被解释为NCF的特例,并利用多层感知器来赋予NCF高水平的非线性建模能力。
3、我们对两个现实世界的数据集进行广泛的实验,以证明我们的NCF方法的有效性和对使用深度学习进行协作过滤的承诺。
名词解释:
内积:点积,数量积
数学解释:两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为a·b=a1b1+a2b2+……+anbn。
通俗理解:使用矩阵乘法并把(纵列)向量当作n×1 矩阵,点积还可以写为a·b=aT*b,这里的aT指示矩阵a的转置。
矩阵的内积参照向量的内积的定义是 两个向量对应分量乘积之和.
比如: α=(1,2,3), β=(4,5,6)
则 α, β的内积等于 14 +25 + 36 = 32
α与α 的内积 = 11+22+33 = 14.
拓展资料:内积(inner product),又称数量积(scalar product)、点积(dot product)是一种向量运算,但其结果为某一数值,并非向量。其物理意义是质点在F的作用下产生位移S,力F所做的功,W=|F||S|cosθ。
在数学中,数量积(dot product; scalar product,也称为点积)是接受在实数R上的两个向量并返回一个实数值标量的二元运算。它是欧几里得空间的标准内积。 两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为: a·b=a1b1+a2b2+……+anbn。 使用矩阵乘法并把(纵列)向量当作n×1 矩阵,点积还可以写为: a·b=a*bT,这里的bT指示矩阵b的转置。
Jaccard相似系数
Jaccard index , 又称为Jaccard相似系数(Jaccard similarity coefficient)用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,样本相似度越高。
库与框架:
库和框架都是一种有别于软件、面向程序开发者的产品形式。正因为如此,也有很多人误以为库就是框架,或者认为指定语言的库就是框架。是将代码集合成的一个产品,供程序员调用。面向对象的代码组织形式而成的库也叫类库。面向过程的代码组织形式而成的库也叫函数库。在函数库中的可直接使用的函数叫函数。开发者在使用库的时候,只需要使用库的一部分类或函数,然后继续实现自己的功能。框架则是为解决一个(一类)问题而开发的产品,框架用户一般只需要使用框架提供的类或函数,即可实现全部功能。可以说,框架是库的升级版。开发者在使用框架的时候,必须使用这个框架的全部代码。 框架和库的比较可以想像为:
假如我们要买一台电脑。框架为我们提供了已经装好的电脑,我们只要买回来就能用,但你必须把整个电脑买回来。这样用户自然轻松许多,但会导致很多人用一样的电脑,或你想自定义某个部件将需要修改这个框架。而库就如自己组装的电脑。库为我们提供了很多部件,我们需要自己组装,如果某个部件库未提供,我们也可以自己做。库的使用非灵活,但没有框架方便。
MF
协同过滤:
协同大家的反馈,评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程
利用相似函数,借鉴和用户相似的用户商品进行推荐:主要使用的是相似函数:sim(i,j),余弦相似度,皮尔逊相关系数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TDTdMgF2-1682756429804)(E:\qq下载\2837683881\FileRecv\MobileFile\IMG_20230411_195444.jpg)]
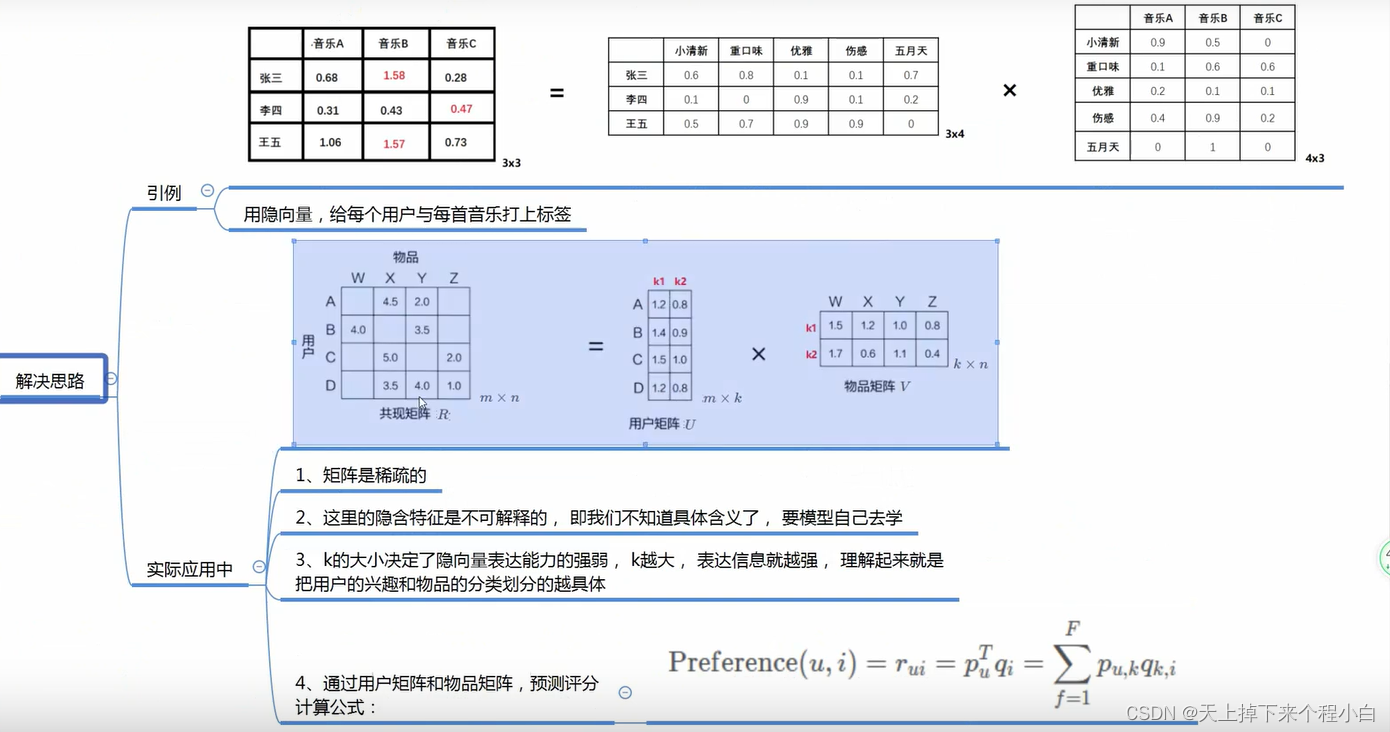
矩阵分解:
用户和物品的隐向量是通过分解协同过滤生产的共现矩阵得到的;这也是’矩阵分解‘名字的由来。
将U*I矩阵进行矩阵分解,为M=m * k,N=n * k,k为自定义的维度,k越大表达能力越强,但是其泛化能力越弱。M,N矩阵的数为随机数,之后利用损失函数,看估计值与实际差距。之后再利用梯度下降进行更新参数。也是和协同过滤相同,利用户和物品的相似度进行推荐。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IUP5ZBhP-1682756429805)(E:\qq下载\2837683881\FileRecv\MobileFile\qq_pic_merged_1681214851791.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lNKS3f9a-1682756429808)(E:\qq下载\2837683881\FileRecv\MobileFile\qq_pic_merged_1681214836621.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Iw3nEPkd-1682756429810)(E:\qq下载\2837683881\FileRecv\MobileFile\qq_pic_merged_1681214820098.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lSgyYoXU-1682756429812)(E:\qq下载\2837683881\FileRecv\MobileFile\IMG_20230411_200625.jpg)]
似然函数
似然函数在 推断统计学 (Statistical inference)中扮演重要角色,如在 最大似然估计 和费雪信息之中的应用等等。. “似然性"与"或然性"或” 概率 "意思相近,都是指某种事件发生的可能性,但是在 统计学 中,"似然性"和"或然性"或"概率"又有明确的区分。. 概率 用于在已知一些参数的情况下,预测接下来的观测所得到的结果,而似然性则是用于在已知某些观测所得到的结果时,对有关事物的性质的参数进行估计。.
偏执向量
首先从
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









