







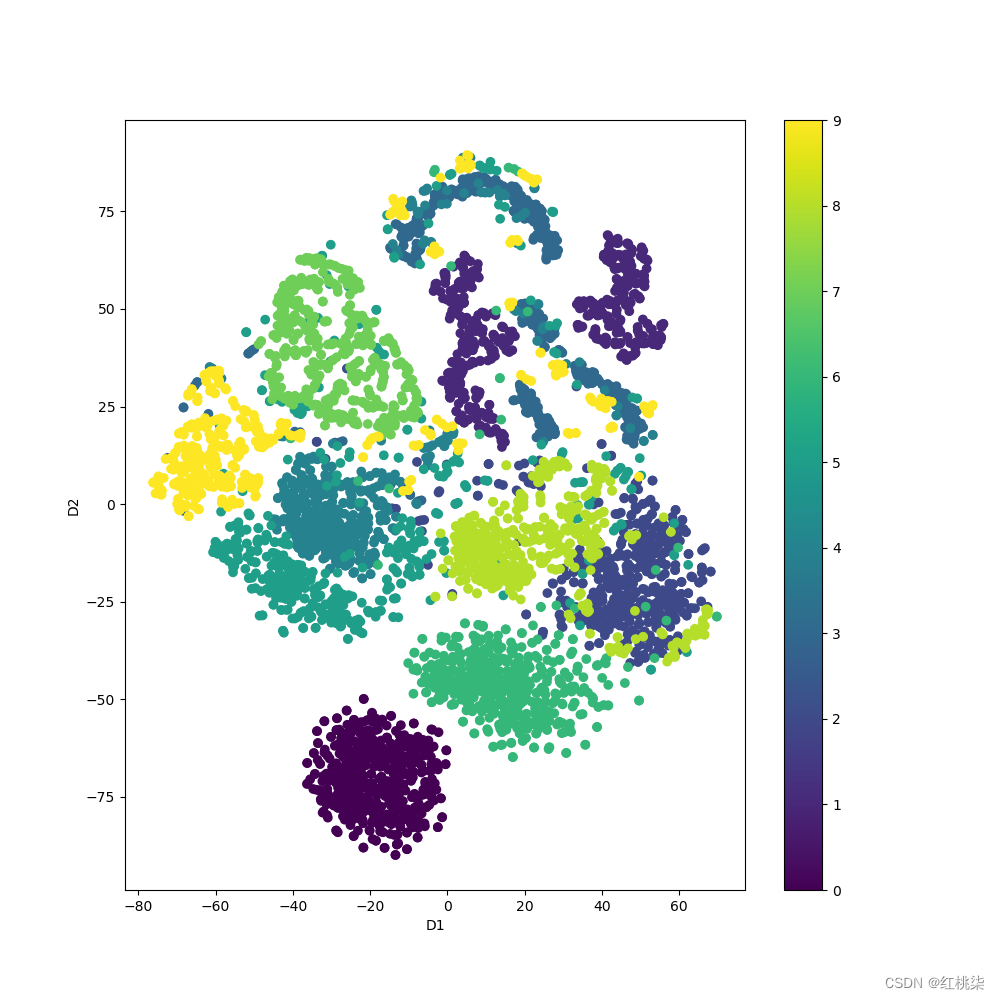
对于t-SNE可视化,有时需要对未训练前的原始数据集进行可视化,用来和训练后模型提取到的全局特征的t-SNE进行对比来验证模型的分类能力,对于原始点云数据的t-SNE可视化代码直接在ModelNetDataLodaer.py中修改如下:
#插入t-SNE函数
def start_tsne(x_train,y_train):
print("正在进行初始输入数据的可视化...")
X_tsne=TSNE().fit_transform(x_train)
plt.figure(figsize=(10,10))
plt.scatter(X_tsne[:,0],X_tsne[:,1],c=y_train)
font_dict=dict(fontsize=14,
family='TimesNewRoman',
weight='normal')
plt.xlabel('Dimension1',fontdict=font_dict)
plt.ylabel('Dimension2',fontdict=font_dict)
plt.colorbar()
plt.show()
#
def ModelNetDataLoader(root,args,split='train',process_data=False):
root=root
npoints=args.num_point
process_data=process_data
uniform=args.use_uniform_sample
use_normals=args.use_normals
num_category=args.num_category
if num_category==10:
catfile=os.path.join(root,'signal_shape_names.txt')
else:
catfile=os.path.join(root,'modelnet40_shape_names.txt')
cat=[line.rstrip()forlineinopen(catfile)]
classes=dict(zip(cat,range(len(cat))))
shape_ids={}
if num_category==10:
shape_ids['train']=[line.rstrip()forlineinopen(os.path.join(root,'signal_train.txt'))]
shape_ids['test']=[line.rstrip()forlineinopen(os.path.join(root,'signal_test.txt'))]
else:
shape_ids['train']=[line.rstrip()forlineinopen(os.path.join(root,'modelnet40_train.txt'))]
shape_ids['test']=[line.rstrip()forlineinopen(os.path.join(root,'modelnet40_test.txt'))]
assert(split=='train'orsplit=='test')
shape_names=['_'.join(x.split('_')[0:-1])forxinshape_ids[split]]
#print(shape_names)
datapath=[(shape_names[i],os.path.join(root,shape_names[i],shape_ids[split][i])+'.txt') for I in range(len(shape_ids[split]))]
print('Thesizeof%sdatais%d'%(split,len(datapath)))
#print(self.datapath.shape)
if uniform:
save_path=os.path.join(root,'modelnet%d_%s_%dpts_fps.dat'%(num_category,split,npoints))
else:
save_path=os.path.join(root,'signal%d_%s_%dpts.dat'%(num_category,split,npoints))
points_set=np.zeros((len(datapath)*npoints,3),dtype=np.float32)
labels_set=np.zeros(len(datapath),dtype=np.int32)
for idx in range(len(datapath)):
fn=datapath[idx]
cls=classes[datapath[idx][0]]
label=np.array([cls]).astype(np.int32)
start_idx=idx*npoints
end_idx=(idx+1)*npoints
point_set=np.loadtxt(fn[1],delimiter='').astype(np.float32)[:npoints]
#print('point_set:',point_set.shape)
points_set[start_idx:end_idx]=pc_normalize(point_set[:,:3])
labels_set[idx]=cls
points_set=points_set.reshape((len(datapath),npoints*3))
#points_set=np.concatenate(points_set)
print(points_set.shape)
returnpoints_set,labels_set
if__name__=='__main__':
def parse_args():
'''PARAMETERS'''
parser=argparse.ArgumentParser('training')
parser.add_argument('--use_cpu',action='store_true',default=False,help='usecpumode')
parser.add_argument('--gpu',type=str,default='0',help='specifygpudevice')
parser.add_argument('--batch_size',type=int,default=2,help='batchsizeintraining')
parser.add_argument('--model',default='pointnet2_cls_msg',help='modelname[default:pointnet_cls]')
parser.add_argument('--num_category',default=10,type=int,choices=[10,40],help='trainingonModelNet10/40')
parser.add_argument('--epoch',default=400,type=int,help='numberofepochintraining')
parser.add_argument('--learning_rate',default=0.001,type=float,help='learningrateintraining')
parser.add_argument('--num_point',type=int,default=10000,help='PointNumber')
parser.add_argument('--optimizer',type=str,default='Adam',help='optimizerfortraining')
parser.add_argument('--log_dir',type=str,default='pointnet2_cls_msg',help='experimentroot')
parser.add_argument('--decay_rate',type=float,default=1e-4,help='decayrate')
parser.add_argument('--use_normals',action='store_true',default=False,help='usenormals')
parser.add_argument('--process_data',action='store_true',default=False,help='savedataoffline')
parser.add_argument('--use_uniform_sample',action='store_true',default=False,help='useuniformsampiling')
returnparser.parse_args()
args=parse_args()
pointss,labelss=ModelNetDataLoader(r'F:\data\si_data',args=args,split='train')
start_tsne(pointss,labelss)
结果如下:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









