






 本文介绍了如何在Nootbook中使用PyTorch运行模型,探讨了Qwen模型的开源实现及其社区支持,涉及RAG在增强生成中的应用,以及LlamaIndex和LoRA/QLoRA等技术在降低大模型微调成本和提高准确性的角色。
本文介绍了如何在Nootbook中使用PyTorch运行模型,探讨了Qwen模型的开源实现及其社区支持,涉及RAG在增强生成中的应用,以及LlamaIndex和LoRA/QLoRA等技术在降低大模型微调成本和提高准确性的角色。
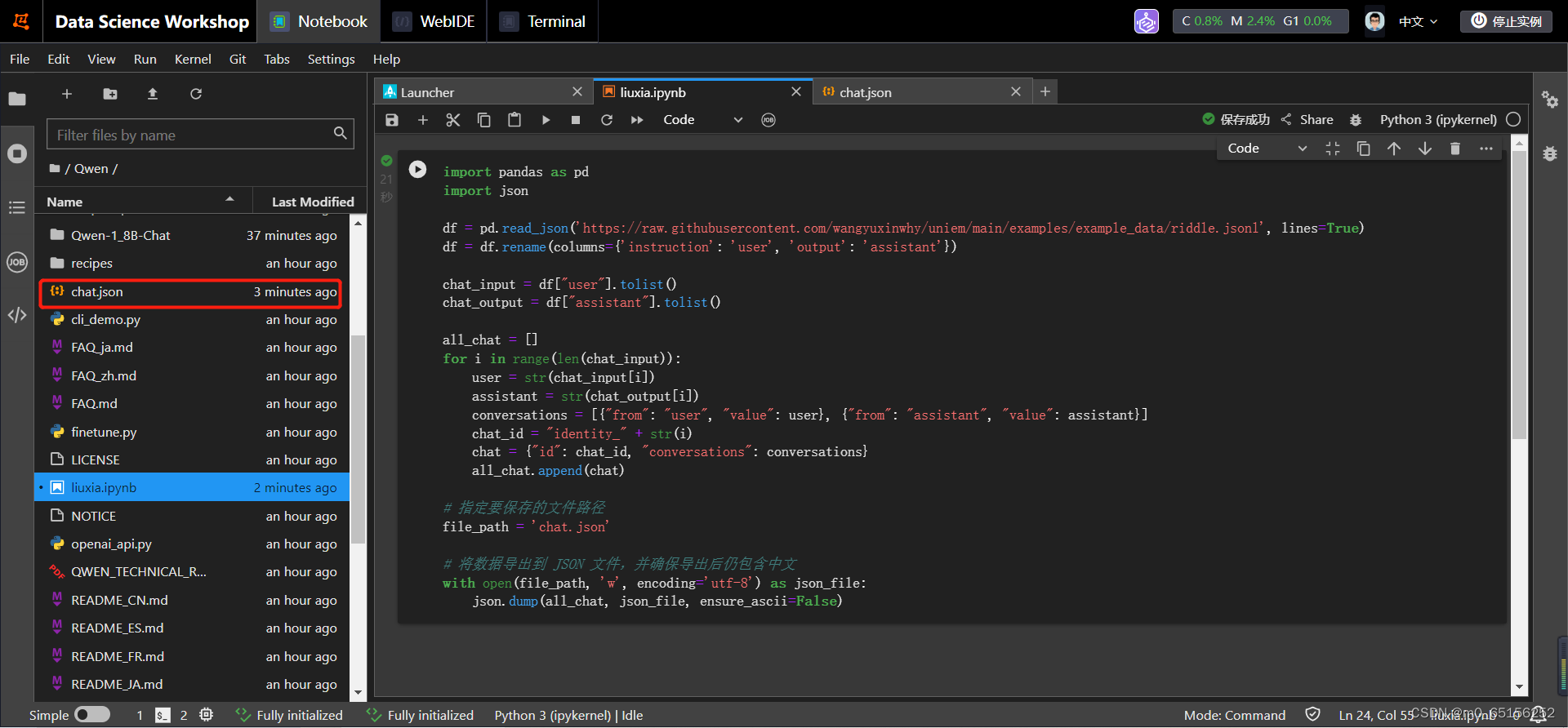
1,在nootbook中新建liuxia.ipynb文件,将内容复制进去点击运行,成功后会出现创建成功的chat.json文件
2,Qwen模型的开源仓库中,提供的示例代码就是基于PyTorch编写的。PyTorch是一个广泛使用的深度学习框架,它的易用性和灵活性都非常高,适合于各种类型的神经网络模型。
此外,PyTorch还有一个庞大的社区,提供了大量的教程和资源,可以帮助你快速上手并掌握PyTorch的使用。而且,PyTorch也支持GPU加速,可以大大提高模型训练的效率。
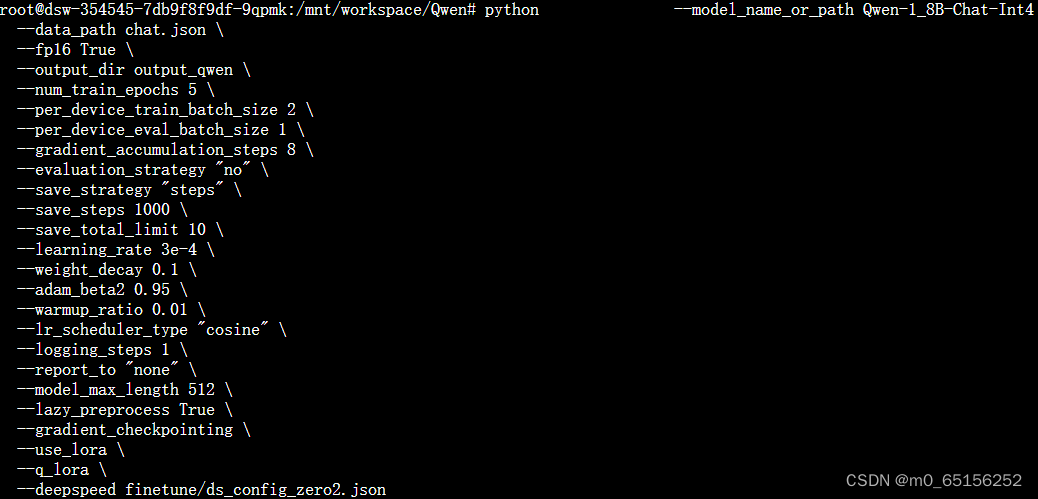
3,针对执行:bash finetune_qlora_single_gpu.sh出现的一个路径找不到问题,更换执行语句为:
python finetune.py \ --model_name_or_path Qwen-1_8B-Chat-Int4 \ --data_path chat.json \ ......
4,检索增强生成 (RAG) 是一种人工智能框架,用于通过将模型建立在外部知识源的基础上来补充 LLMs 的内部信息表示,从而提高 LLMs 生成的响应的质量。 RAG 是一种利用从外部来源获取的事实来提高生成式 AI 模型的准确性和可靠性的技术,它对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。在基于 LLM 的问答系统中实施 RAG 有两个主要好处:1. 它确保模型能够访问最新、可靠的事实;2. 用户能够访问模型的来源,确保可以检查其声明的准确性和准确性,最终得到信任。
RAG 将信息检索组件与文本生成器模型相结合。 RAG 可以进行微调,并且可以有效地修改其内部知识,而无需重新训练整个模型。
5,LlamaIndex是一个用于连接大语言模型(LLMs)和外部数据源的数据框架,它可以让LLMs访问和利用私有或领域特定的数据。
6,大模型微调技术LoRA和QLoRA都是为了解决大规模模型微调成本高昂的问题而提出的。LoRA技术通过使用低精度权重降低了存储需求和计算成本,但在准确性上有所牺牲。而QLoRA技术则通过使用高精度权重和可学习低秩适配器,既降低了微调成本,又提高了模型的准确性。
7,模型微调的主要作用是在已经预训练好的模型基础上,通过进一步的训练来适应特定的任务或领域。















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









