






本博客为山东大学软件学院2024创新实训,25组可视化课程知识问答系统(VCR)的个人博客,记载个人任务进展
清洗后数据存储
在数据清洗和预处理之后,通常需要将数据格式化为适合模型训练的格式,并存储到目标位置,以便后续的分析或模型训练。
1. 格式化数据
分析:
数据格式化是将数据从一种格式转换为另一种格式的过程。在机器学习和数据科学中,常用的数据格式包括CSV(逗号分隔值)、JSON(JavaScript对象表示法)、NumPy数组、Pandas DataFrame等。选择哪种格式取决于具体需求,但CSV和JSON是最常见的,因为它们具有广泛的兼容性和可移植性。当将数据清洗并准备用于模型训练时,通常需要将数据格式化为模型可以理解的格式,如CSV、JSON或NumPy数组等。
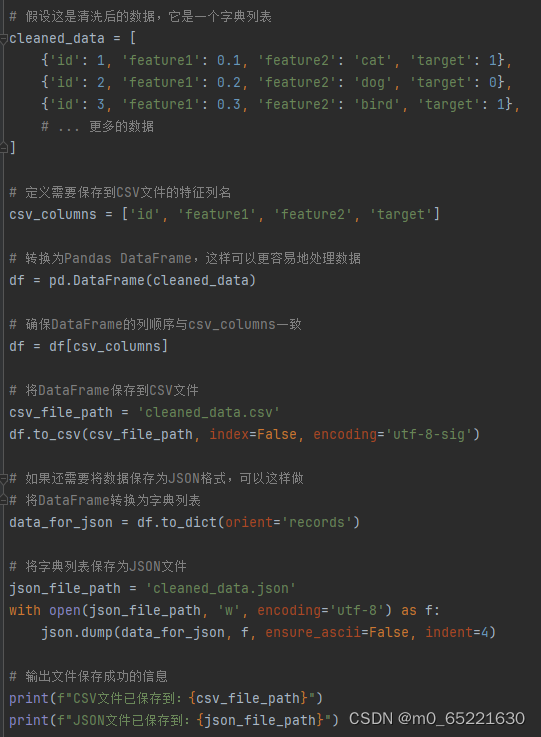
首先定义了一个清洗后的数据列表,然后将其转换为Pandas DataFrame,以便更容易地处理列名和顺序。然后,它分别将数据保存为CSV和JSON文件。接着,将特征和目标转换为NumPy数组,并将它们保存到NPY文件中,
2. 存储到目标位置
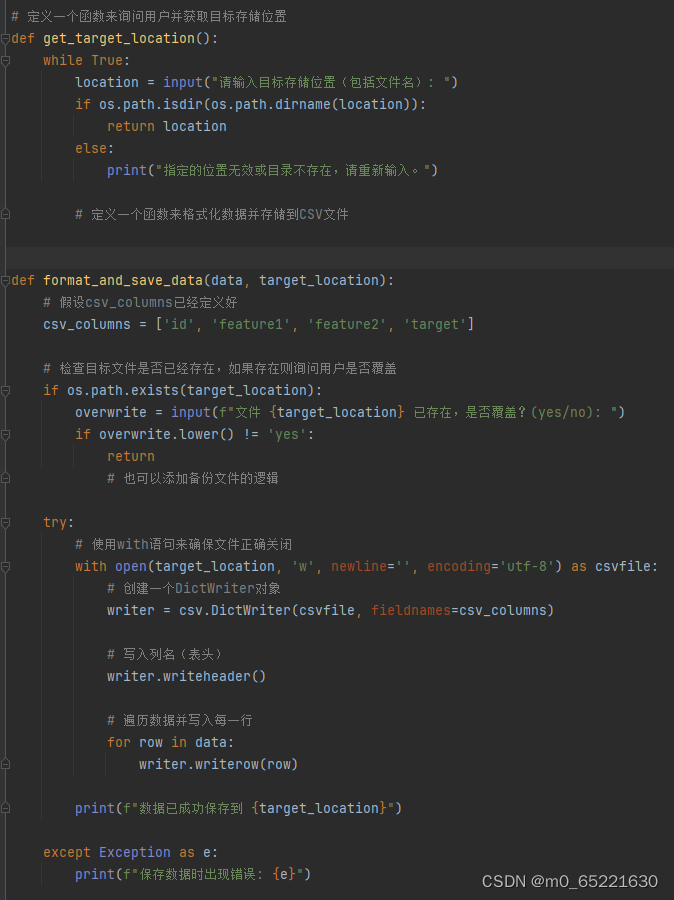
将格式化后的数据存储到目标位置可以简单地通过指定文件路径来完成。上述to_csv和to_json函数允许你指定一个文件路径,这样你就可以将数据保存到任何你想要的位置。然而,你可能还需要考虑数据的安全性和备份问题,这可能需要额外的步骤或策略。
当涉及到将格式化后的数据存储到指定位置时,实际上代码可能会相对简单,尤其是已经将数据格式化为CSV文件时。















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









