






本博客为山东大学软件学院2024创新实训,25组可视化课程知识问答系统(VCR)的个人博客,记载个人任务进展
数据标准化是数据预处理的一个重要步骤,特别是在文本分析和自然语言处理(NLP)任务中。标准化的目的是消除数据中的不一致性和冗余,从而提高数据质量和处理效率。以下是对提到的两种数据标准化方法的详细分析和代码实现。
1. 术语统一
在文本数据中,同一个概念可能有多种表达方式,如“电脑”和“计算机”,“USB”和“通用串行总线”等。术语统一的目的就是将这些不同的表达方式转换为标准的术语。这有助于减少数据的稀疏性,提高文本分类、聚类等NLP任务的准确性。术语统一通常需要一个术语词典或者一套规则来指导转换过程。术语统一是一个重要的任务,特别是在大型文档或项目中,确保所有参与者都使用相同的术语,以避免混淆和误解。
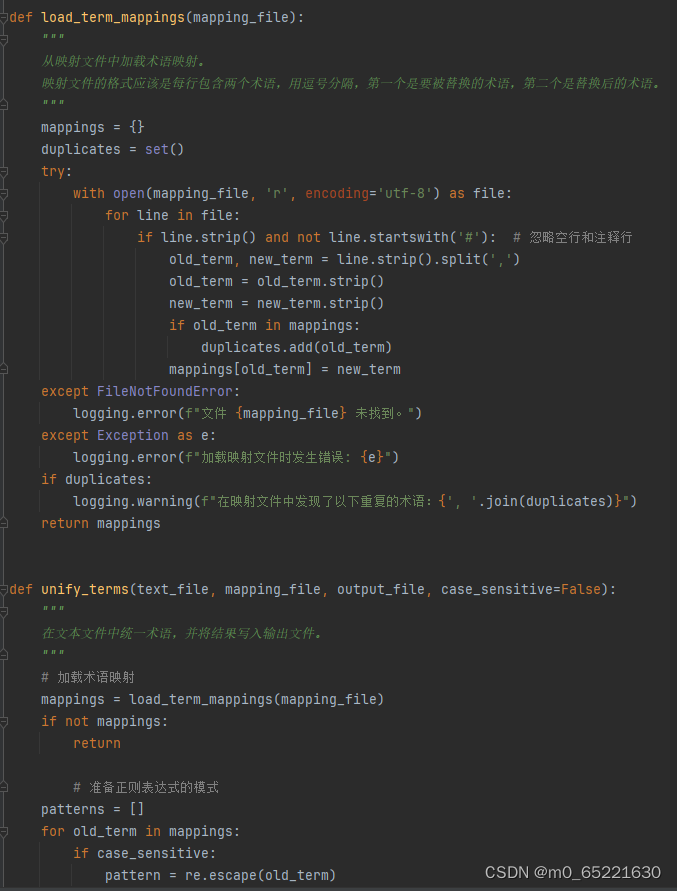
首先定义了一个load_term_mappings函数,用于从映射文件中加载术语映射。然后,定义了一个unify_terms函数,该函数读取文本文件,使用正则表达式替换文本中的术语,并将结果写入输出文件。
2.分词与去除停用词
分词是将连续的文本切分为独立的词汇单元的过程。在中文处理中,分词尤为重要,因为中文的词语之间没有明显的分隔符。停用词是在文本中频繁出现但对文本意义贡献不大的词汇,如“的”、“是”、“在”等。去除停用词可以减少数据的噪声,提高处理效率。分词和去除停用词通常作为文本预处理的初步步骤,为后续的特征提取和模型训练做准备。
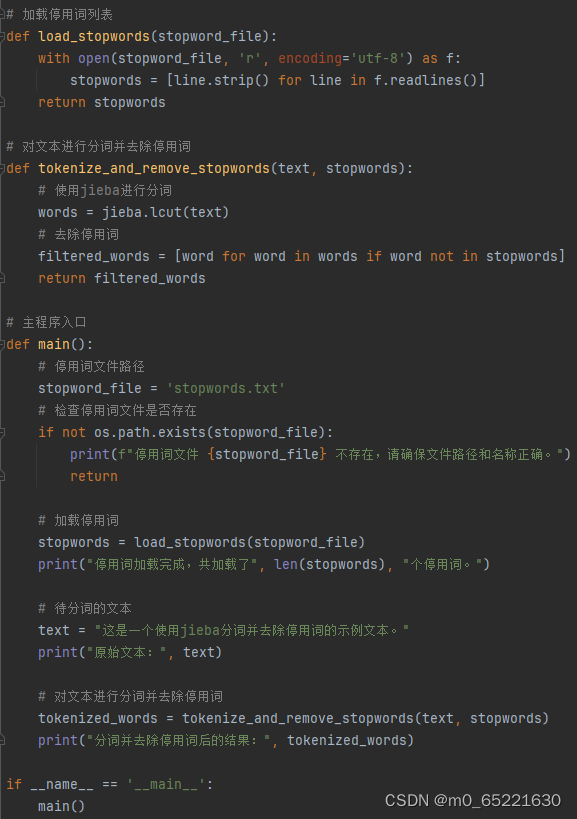
首先定义了一个load_stopwords函数来加载停用词列表,然后定义了一个tokenize_and_remove_stopwords函数来对文本进行分词并去除停用词。最后,在main函数中,加载了停用词文件,对一段示例文本进行了分词处理,并输出了去除停用词后的结果。















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









