






一、Python基础
Python3 教程 | 菜鸟教程 (runoob.com)
二、pandas
1.模块、包
通俗来讲,一个python文件就是一个模块,由python文件集成的文件夹就是一个包,包中一定含有_init_.py文件
2.Series、DataFrame
(1)Series
import pandas as pd
s1 = pd.Series(['a', 'b', 'c'], name='test', index=['A', 'B', 'C'])
print(s1)
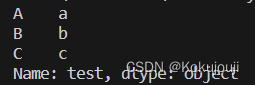
属性name:名字
属性index:索引标签
series是一维的,具有自动对齐功能
import pandas as pd
s1 = pd.Series([2, 4, 6], name='math', index=['A', 'B', 'C'])
s2 = pd.Series([8, 10, 12], name='english', index=['A', 'C', 'B'])
print(pd.concat([s1, s2], axis=1))
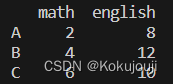
(2)DataFrame
上述例子中,将Series s1和s2拼接之后就形成了DateFrame
3.读取、导出
import pandas as pd
//更改数据类型的方法1
data = pd.read_excel(r'/*绝对路径*/name.xlsx', converters=['uid':str]/*以str存储uid数据)
data.info()//查看data的各行数据类型
//方法2
data['uid'] = data['uid'].astype(str)
//数据导出
data.to_excel('name.xlsx', index=False)
data.to_csv('name.csv', encoding='GB18030'/*编码形式*/)
data.to_csv('name.txt', sep='\t')4.访问、筛选
(1)访问列
data['id', 'content', 'uid'](2)访问行
data.iloc[1:6][['id', 'content', 'uid']]
data[['id', 'content', 'uid']].iloc[1:6](3)筛选
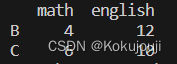
import pandas as pd
s1 = pd.Series([2, 4, 6], name='math', index=['A', 'B', 'C'])
s2 = pd.Series([8, 10, 12], name='english', index=['A', 'C', 'B'])
data = pd.concat([s1, s2], axis=1)
print(data['math'] >= 3)
print(data[data['math'] >= 3])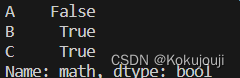
(4)数据去重
data.drop_duplicates(
subset='uid'//以uid进行去重
keep='first/last'//重复数据保留第一条信息或是最后一条
inplace=True//以更改后的数据覆盖原数据
)5.轴、合并、连接
axis=1,axis='columns',行
axis=0,axis='index',列
pd.concat([data, data2], axis=0)
pd.merge(
left,//以左表为主表
right,
how:'inner',
on=None,
left_on=None,
right_on=None
)6.排序、匿名函数
data.sort_values(['uid', 'time'], ascending=[True, False])//以uid升序排序,再以time降序排序
//匿名函数
def add(x, y):
return x + y
//用匿名函数复刻add()功能
add2 = lambda x, y: x + y7.分组、聚合、转换
level_manager = user_level.groupby('level')
level_manager.count()
level_manager['字段'].聚合函数()
level_manager[['字段']].agg(['max', 'min'])//展示最大和最小的值
level_manager.agg({'字段1':['max', 'min'], '字段2':'min'})//展示字段1的最大值和最小值,以及字段2的最小值
level_manager[['字段']].agg(lambda x: print(x))
//展示字段1的最大值和最小值的差值
//方法一
def diff(x):
return x.max() - x.min()
level_manager[['字段1']].agg(diff)
//方法二
level_manager[['字段1']].agg(lambda x: x.max() - x.min())
//转换
level_manager['字段1'].transform(func='sum')//类似于SQL的窗口函数,以字段1的分组求和
//组内排名
level_manager.groupby('字段1')['字段2'].rank(method='dense')//以字段1分组,再以字段2进行排名8.字符串方法
(1)split
DataFrame['字段1'].str.split('_', expand=True)//将分割之后的值以dataframe类型存储(2)contains
DataFrame[DataFrame['字段1'].str.contains('str1')].reset_index(drop=True)//筛选字段1中含有str1的数据(3)replace
DataFrame['字段1'].str.replace('str1', 'str2')//将字段1中的str1替换成str2(4)extract
DataFrame['字段1'].str.extract('str1')//提取只包含str1的字段1数据9.绘图
//折线图
DataFrame.groupby('字段1')['字段2'].sum().plot(kind='line', x='字段3', y='字段2')
//柱状图
DataFrame.groupby('字段1')['字段2'].sum().plot(kind='bar', x='字段3', y='字段2')
//水平柱状图
DataFrame.groupby('字段1')['字段2'].sum().plot(kind='barh', x='字段3', y='字段2')
//直方图
DataFrame['字段1'].plot(kind='hist')
//散点图
DataFrame.plot(kind='scatter', x='字段1', y='字段2')
//饼图
DataFrame.groupby('字段1')['字段2'].sum().plot(kind='pie')10.map、apply、applymap
DataSeries['字段1'].map(lambda x: int(x))//将字段1中的数值类型转换成int
DataSeries['字段1'].apply(lambda x: int(x))//将字段1中的数值类型转换成int
//map和apply生成的结果一样,map可以接收函数处理规则或字典,apply只能函数,但提供的参数更丰富
DataSeries['字段1'].map({'str1': 'str2'})//将字段1中str1替换成str2,但是其余没有制定规则的值会重置成NaN
//在处理dataframe类型时,apply传递的数据类型是一个个Series,applymap传递的是一个个值,方向向下
def demo(x):
formular = x['字段1'] + x['字段2']
return formular
DataFrame.apply(demo, axis=1)
DataFrame.apply(demo, axis=1, args=(参数,))














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









