







关于如何使用Python自动化登录天 猫并爬取商品数据的指南,我们需要明确这是一个涉及多个步骤的复杂过程,且需要考虑到天猫的反爬虫策略。以下是一个简化的步骤指南:
步骤一:准备工作
- 环境准备:确保你的Python环境已经安装并配置好。
- 安装必要的库:使用pip安装
requests、BeautifulSoup(或lxml、pyquery)、selenium等库。 - 下载ChromeDriver:如果你打算使用
selenium进行自动化操作,你需要下载与你的Chrome浏览器版本相匹配的ChromeDriver。
步骤二:分析天猫登录流程
- 使用开发者工具:打开Chrome的开发者工具,进入网络(Network)面板,并勾选“保留日志”选项。
- 模拟登录:在天 猫网站上进行登录操作,观察开发者工具中网络请求的变化。特别关注登录表单提交时发送的POST请求。
步骤三:编写登录代码
- 设置请求头:根据分析的结果,设置请求头(包括User-Agent、Referer等)。
- 发送登录请求:使用
requests库发送POST请求,包含登录表单的数据(如用户名、密码等)。 - 处理验证码:如果天 猫使用了验证码,你可能需要使用OCR技术识别验证码,或者考虑使用第三方服务来处理验证码。
- 获取并保存Cookies:登录成功后,从响应中获取并保存Cookies,以便后续请求使用。
步骤四:使用Cookies进行爬取
- 设置请求:在后续爬取商品数据的请求中,带上之前保存的Cookies。
- 发送请求:使用
requests库发送GET请求,获取商品页面的HTML内容。 - 解析HTML:使用
BeautifulSoup(或lxml、pyquery)库解析HTML内容,提取所需的数据(如商品标题、价格、销量等)。
步骤五:处理反爬虫策略
- 设置合理的请求间隔:避免过于频繁的请求,以免被天 猫识别为爬虫。
- 使用代理IP:如果可能的话,使用代理IP来隐藏你的真实IP地址。
- 更换User-Agent:定期更换User-Agent,模拟不同浏览器的访问。
步骤六:数据存储与清洗
- 数据存储:将爬取到的数据存储到数据库、CSV文件或Excel文件中。
- 数据清洗:去除重复数据、处理缺失值等,确保数据的准确性和完整性。
注意事项
- 遵守法律法规:确保你的爬虫行为符合相关法律法规和网站的服务条款。
- 尊重网站权益:不要过度爬取或滥用数据,尊重天猫的权益。
- 考虑使用官方API:如果天 猫提供了官方API,优先使用API来获取数据,这通常更加安全、可靠和高效。
下面我们来看一下实列代码和运行结果:
代码:
登录代码:
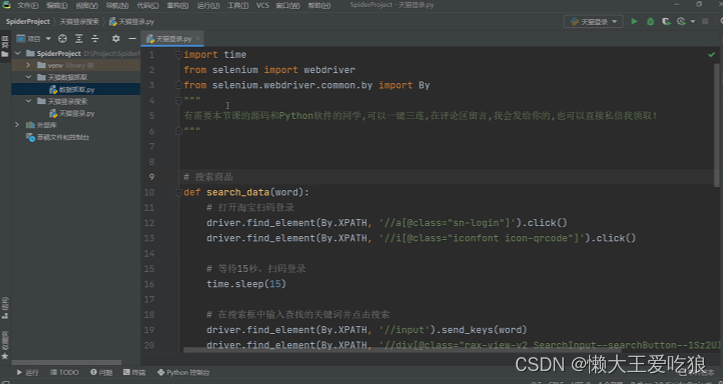
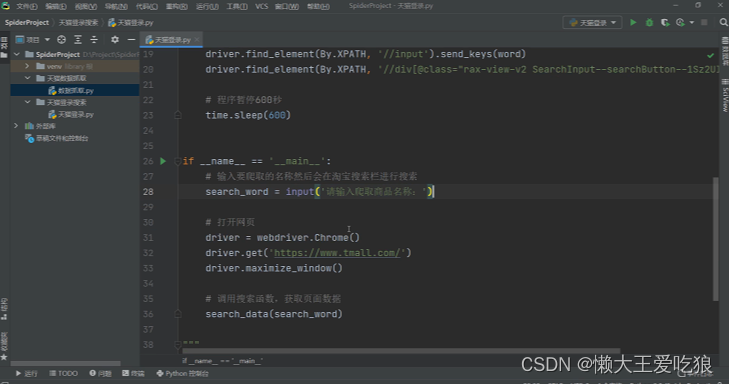
数据爬取代码:

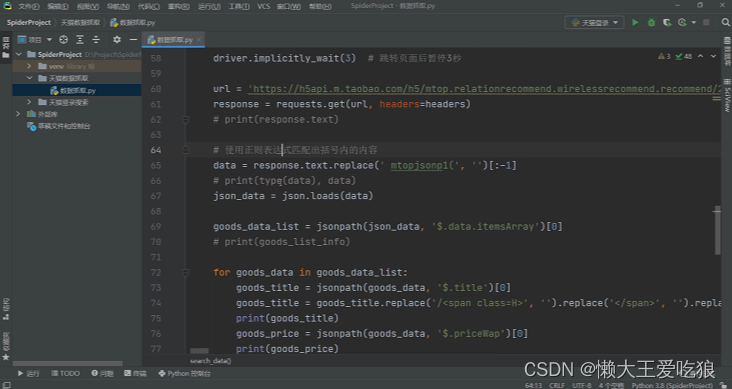
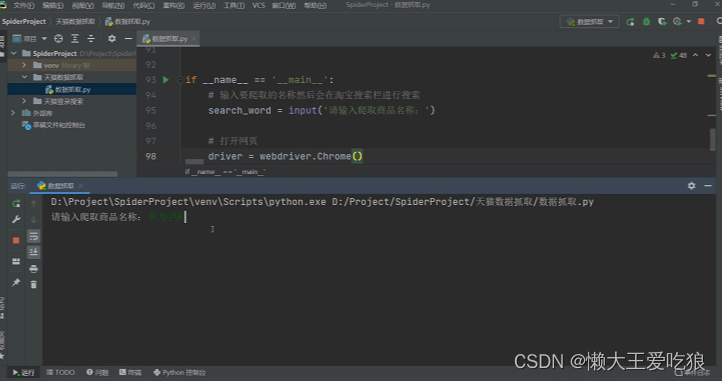
运行结果:
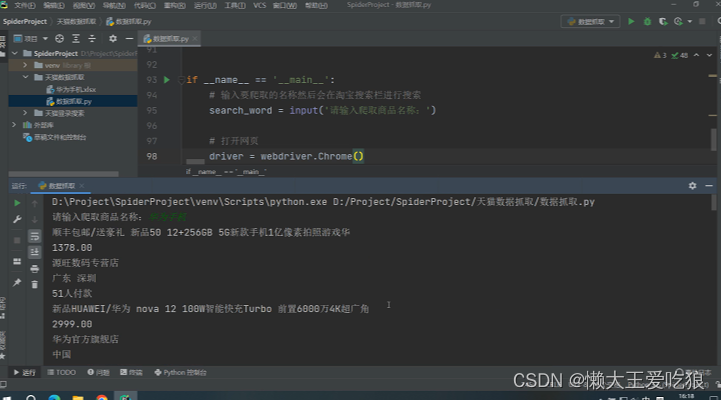
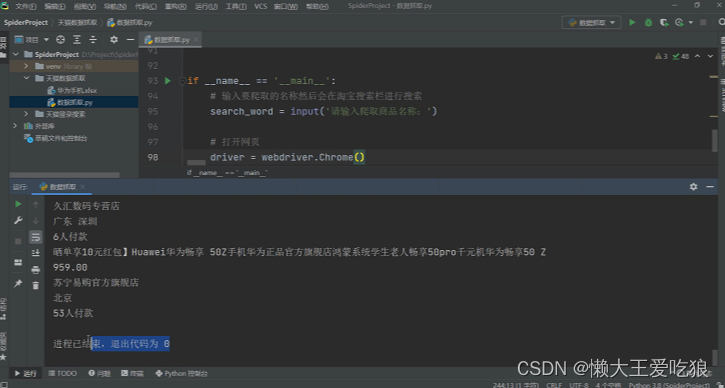
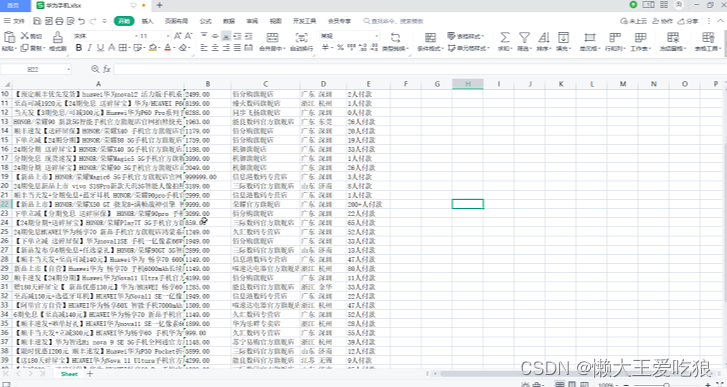
请注意,由于反爬虫策略可能随时变化,上述步骤可能需要根据实际情况进行调整。此外,由于自动化登录和爬取可能涉及敏感操作和法律问题,请务必谨慎行事。
完整代码,看这里👇↓↓↓
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









