






1 前言
最近书生(internVL)2.5发布了一系列模型,包含78B、38B、8B等多种不同size的多模态模型,恰逢工作单位在清华大学开设了一个workshop,有幸听到通讯作者代季峰教授做了一个关于多模态导向与设计训练的分享,收益匪浅。由于之前做过关于internVL-2的微调,在OCR相关能力上表现非常不错。于是便萌生了写一篇对InternVL-2.5详细剖许的文章(如果后续有时间也会补一篇代码层面的剖析)。
Technical Report:Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
论文:https://arxiv.org/abs/2412.05271
Huggingface模型权重下载页:https://huggingface.co/collections/OpenGVLab/internvl25-673e1019b66e2218f68d7c1c
Github: https://github.com/OpenGVLab/InternVL
模型训练官方指导文档:https://internvl.readthedocs.io/en
本文旨在剖析internVL-2.5的技术报告,即在12月6日挂在arxiv上的文章,也会夹杂着分享一些近日workshop作者分享的一些观点。因为个人觉得internvl系列的代码是比较工整且优美的,完整剖析一遍可以有很大的收获,日后可能会代入小白的视角去更新implementation代码层面的剖析。
总体来说,这篇论文是一篇质量极高,并且清晰透露了技术细节,为书生团队点赞。
2 Model Architecture
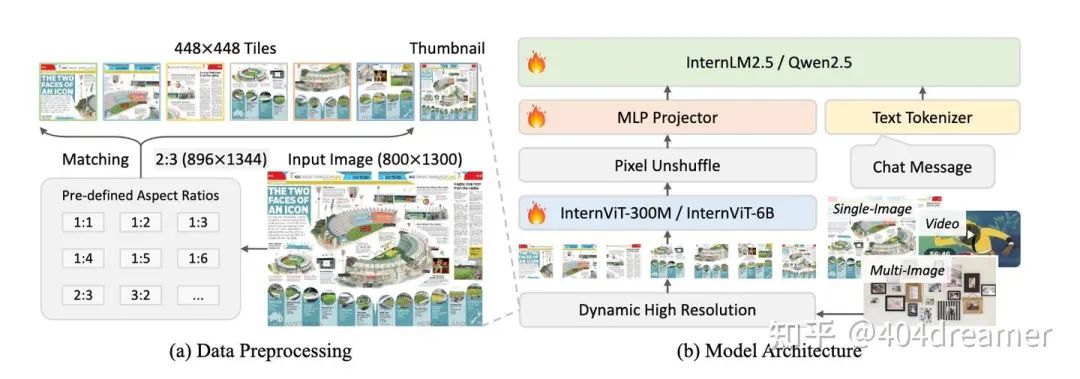
InternVL-2.5模型框架
在模型框架上,InternVL-2.5仍然遵循:ViT-MLP-LLM这种MLLM的经典桥接式框架。但是组件做了细微的更改:
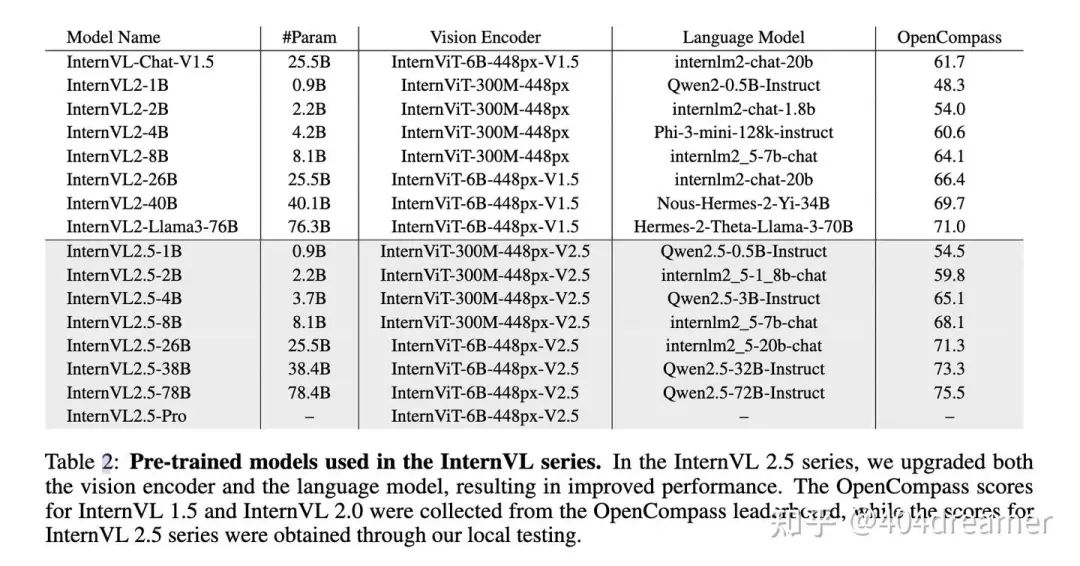
InternVL系列各模型组件概览
2.1 视觉编码器ViT
InternVL-2.5系列包含了两种参数大小的ViT:InternViT-6B 和 InternViT-300M,这两种大小的ViT适用于不同size的MLLM,小于8B的MLLM(1B、2B、4B、8B)InternViT-300M,而大于8B的MLLM(26B、38B、78B、pro)统一使用InternViT-6B。
InternViT-6B: 架构基于vanilla ViT,对QK-Norm以及RMSNorm进行了少量改动。ViT原本有48层,由于最后3层过于专注于clip的目标损失函数(contrastive loss),这最后三层优先考虑全局对齐导致部分细节信息丢失,所以最后三层被移除后用作MLLM的视觉编码器。最终,InternViT-6B-448px-V2.5包含45个layer,参数量为5.5B。
InternViT-300M: 由InternViT-6B蒸馏而来,知识蒸馏训练细节详见原文在此不过度展开。
2.2 大语言模型LLM
相较于InternVL-2,InternVL-2.5采用了更多样且先进的LLM,包含:InternLM 2.5系列和Qwen 2.5系列等。
3 训练策略
3.1 Dynamic High-Resolution for Multimodal Data
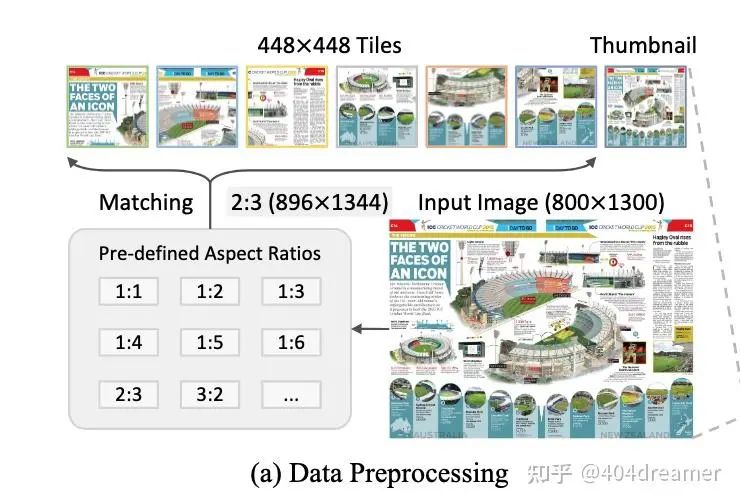
动态分辨率方案
基于上文,由于ViT支持的分辨率是448×448,即所有的图像在进入ViT之前都需要去resize成448×448的放图。若是一张输入图像不是方图或分辨率过高(例如报纸、财报),这种resize会导致图片中的严重变形失真或是信息模糊,从而影响MLLM的训练。
为了解决这类难题,U-reader提出了一种动态分辨率切片方案,通俗一点来说就是将原图切成固定分辩率的子图,i.e. 448 × 448,然后将若干子图和resize过后的原图一起送入ViT转化成视觉特征。通常,我们称被切分后的子图为tile,而被resized过后的原图为thumbnail。本质上,动态分辨率方案增加了视觉信息的token数。分享一下代季峰教授在workshop时的一个观点:
高分辨率只是一个工程化的问题,不本质。通过切子图实现高分辨率对模型训练的上限不会有太大影响。关于分辨率的争论才CV发展的历史中比比皆是,不看好分辨率相关的突破会是下一个通往AGI的breakthrough。
动态分辨率最核心的点就是切图的准则,即给定一张任意分辨率的图片并且子图tile的分辨率已经固定,该将图片resize到什么分辨率从而可以切成固定的tiles?
InternVL系列采用了比较简洁且有效的准则,即根据图片的长宽比来选择pre-defined grids。这些grid即是图像可以去size到的分辨率,grid的长和宽皆是tile(448方图)的整数倍。
首先根据tile的数量定义grids,这里需要考虑显存的问题,子图越多,对应的visual token就越多,训练时sequence的长度就越大,就会占用更多显存。通过定义切图的下限 n_{min},上限 n_{max} 来确定pre- defined grids。
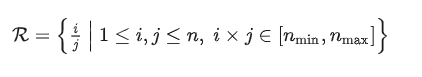
根据当前图片的长宽比选择最佳的grid,r 为长宽比:
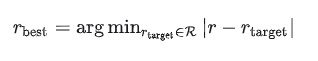
最后对原图进行resize成为thumbnail,将原图切分成多个子图(tiles):
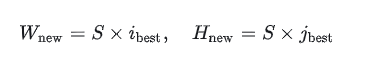
动态分辨率切图的implementation一般在dataset中:
# internvl_chat/internvl/train/internvl_chat_finetune.py -> LazySupervisedDataset
# i.e. multi_modal_multi_image_get_item: 多图处理,部分核心代码
def multi_modal_multi_image_get_item(self, data_item):
# Build transformation function
transform = self.get_transform()
images, num_tiles = [], []
num_image = len(data_item['image'])
for image_path in data_item['image']: #遍历多图list
image_path = self.get_image_path(image_path)
image = self.load_image(image_path)
if self.dynamic_image_size: #动态分辨率方案对每张图片切子图
image = dynamic_preprocess(image, min_num=self.min_dynamic_patch,
max_num=max(1, self.max_dynamic_patch // num_image),
image_size=self.image_size, use_thumbnail=self.use_thumbnail)
images += image
num_tiles.append(len(image))
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
num_patches = pixel_values.size(0)
# 计算多图中每张图片的visual token数量
num_image_tokens = [self.num_image_token * num_tile for num_tile in num_tiles]
# internvl_chat/internvl/train/dataset.py
# 自适应分辨率逻辑
def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
3.2 Single Model Training Pipeline
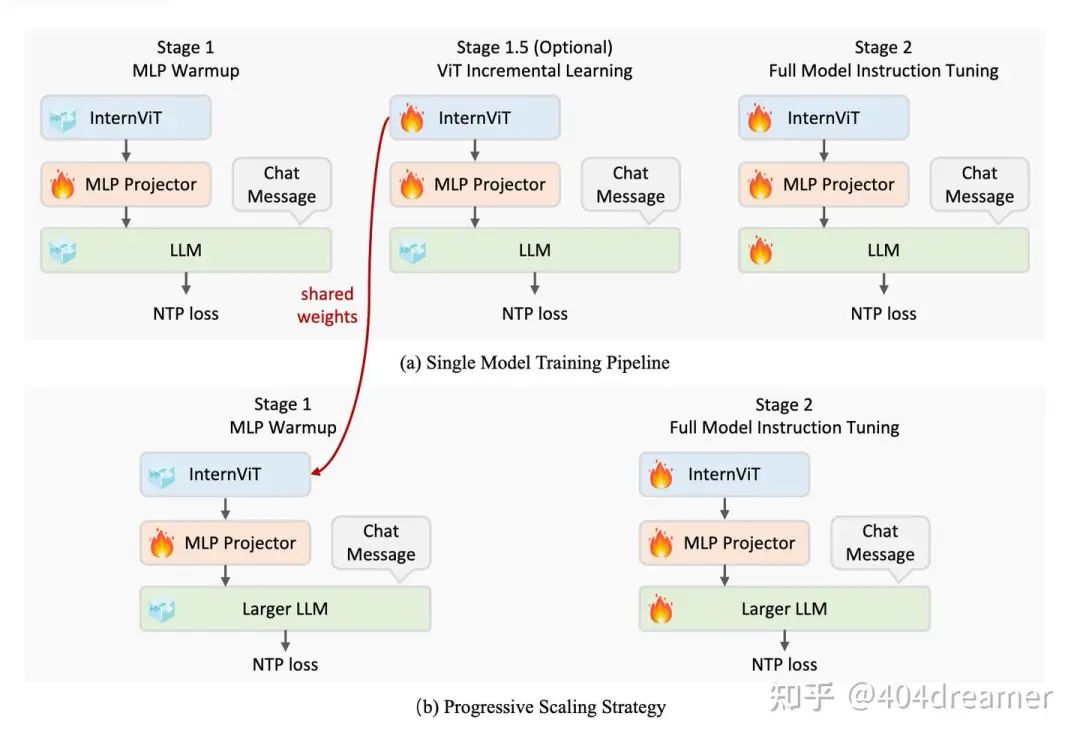

训练细节
InternVL-2.5的训练分为三个阶段,stage 1、stage 1.5(optional)和stage 2。stage 1和stage 1.5可以理解为预训练阶段,而stage 2可以理解为指令微调阶段。
-
Stage 1 - MLP Warmup(预训练):
-
MLP (Multilayer perceptron) 是modality interface(模态融合层)的一种。通常,modality interface将经过encoder的视听特征visual features (audio features)与linguistic features进行融合。一般是在token层面,即可以理解为将这些非语言学特征经过modality interface转化成与linguistic token相等价的token即可输入进LLM实现多模态理解。
-
这个阶段旨在先对MLP进行专项训练,使得模态融合到达一个可以接受的地步。该阶段仅MLP的参数被训练,其他component都被冻结。
-
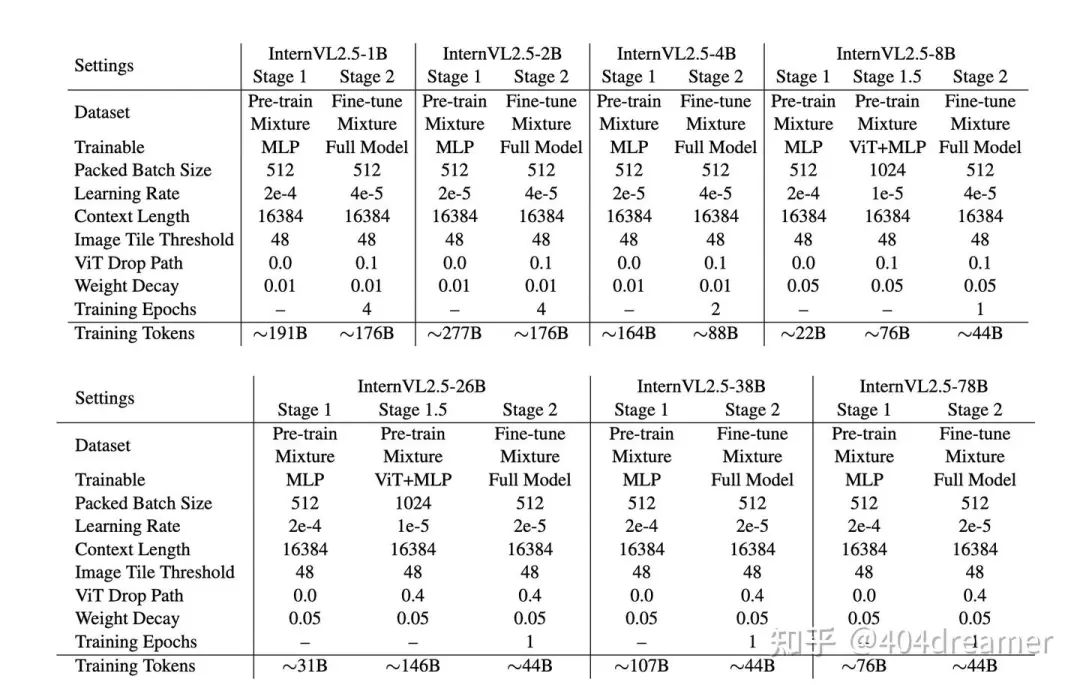
由训练细节观察可知,stage 1的学习率相对于stage 1.5与stage 2都要高,目的是为了加速收敛。除了26B和8B的模型包含stage 1.5,其余size的模型的预训练仅包含stage 1。通常在token-level,预训练的数据要多于质量微调数据。
-
Stage 1.5 - ViT Incremental Learning (预训练可选):
-
stage 1.5选择训练ViT与MLP,这个阶段主要训练了web-scale datasets中缺少的领域数据,例如:多语言OCR数据、数学图表数据。这一阶段的目的是为了提高MLP + ViT这个组合处理特定领域视觉信息的能力。据我猜测,只所以没有普及这个stage 1.5是其提升的效果并不稳定(并不是对每个size的模型都有明显提升)。并且,如果一个size的模型没有进行stage 1.5,那么并不代表其缺少一些预训练领域数据(前文提到的多语言OCR数据等),只不过没有从stage 1中拆分出来。
-
由于是接着一阶段的模型续训,于是必须要考虑到灾难性遗忘的问题(catastrophic forgetting),这也是持续学习(continue learning)领域中最关键的核心问题,在不更改模型架构的情况下,最常见的做法是data replay,即将上一阶段训练的数据采样一定的比例,与这一阶段新加入的数据进行混训,通常采用一个更小的学习率。
-
Stage 2 - Full Model Instruction Tuning(指令微调):
-
在该阶段,所有component参数都被放开 - LLM、ViT、MLP。在这个阶段特别强调数据的高质量,稍有一些低质量数据都会对该阶段的性能产生负面影响。
-
采用了简单的学习率设置方式,所有component的学习率保持一致。
-
在stage 2后可以进行高质量post-training或是强化学习preference optimization。
3.3 Progressive Scaling Strategy
现象:当一个LLM与ViT一同训练时,ViT encode的视觉特征也很容易被另外的LLM所理解。
基于这个现象,InternVL团队采用不同大小的LLM去与ViT对齐训练:
-
先用小参数量的LLM去和ViT jointly training把ViT的性能提上去。
-
再将小参数量的LLM替换成大参数量的LLM。
结果:与千问72b训了1.4 trillion tokens相比,InternVL2.5-78B只训了120 billions。大概用了不到其十分之一的计算资源,即可媲美千问72b的性能。
同时代教授也分享到,因为书生是一个偏公益研究的机构,所以没有那么多训练资源。
可能这就是激发出这样高效训练策略的核心原因吧。
3.4 Training Enhancements
文章介绍了几个可以提高benchmark得分和用户体验的小tricks。
- 数据增强 - Random JPEG Compression:随机将图片进行压缩。quality level在75%到100%之间。
def simulate_jpeg_degradation(quality):
def jpeg_degrade(img):
with io.BytesIO() as output:
img.convert('RGB').save(output, format='JPEG', quality=quality)
output.seek(0) # Move the reading cursor to the start of the stream
img_jpeg = Image.open(output).copy() # Use .copy() to make sure the image is loaded in memory
return img_jpeg
return jpeg_degrade
# Define the JPEG compression quality range, pre-create all JPEG compression functions
qualities = list(range(75, 101))
jpeg_degrade_functions = {quality: simulate_jpeg_degradation(quality) for quality in qualities}
- Loss Reweighting
背景:动态拼接是一种常用的提升训练效率的方法,在小于max token per sequence的情况下,将多条sample的tokens拼接到一条sequence中进行训练。于是,计算loss可以选择两种策略:token average和sample average
文中先阐述了一下关于loss,token average和sample average的区别。
以下为文章中给出的公式,计算整体的loss。
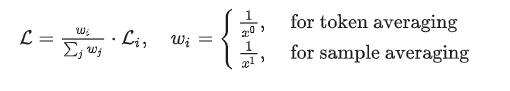
-
x 为token i 所在sample的token总数
-
wi 为当前token的loss weight.
假设将两个样本拼接成一个序列,表示为 [1, 1, 1, 2, 2](其中数字代表数据索引,用于区分样本),即第一个样本包含3个token,第二个样本包含2个token。
Token averaging:将拼接后的序列视为一个新的样本,该样本共有5个token。在计算最终的损失时,每个token对损失的权重相同。因此,未拼接前的样本对损失的影响不同,包含token越多的样本对损失的影响越大。
Sample averaging:每个token对loss的权重由其原始sample的数量决定。这样,每个样本对最终损失的贡献相同,无论其包含的token数量多少,从而确保每个样本在模型训练中的影响均等。
使用token averaging时,每个token对最终损失的贡献相等,这可能导致梯度偏向包含更多tokens的回答,从而降低基准性能。相比之下,sample averaging确保每个样本对损失的贡献相等,但可能使模型偏向较短的回答,进而影响用户体验。
为了平衡回答长度(避免出现过长或者过短的回答),InternVL对于token的权重进行了一个中和(reweighting)。
-
square averaging:将每个token 𝑖 的权重设置为
-
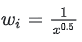
可能因为我在国外呆了5年的中文表述不太好,所以将相关代码贴出来以供理解 (详细代码可看github):
# internvl_chat/internvl/train/internvl_chat_finetune.py
def len2weight(x, loss_reduction):
if x == 0:
return x
if loss_reduction == 'token':
return 1
if loss_reduction == 'sample':
return 1 / x
if loss_reduction == 'square':
return 1 / (x ** 0.5)
raise NotImplementedError(loss_reduction)
# internvl_chat/internvl/train/internvl_chat_finetune.py -> main
if data_args.use_packed_ds:
collator = partial(
packed_collate_fn,
data_collator=concat_pad_data_collator,
max_item_length=data_args.max_packed_tokens if data_args.strict_mode else 0,
micro_num=training_args.train_batch_size,
len2weight=partial(len2weight, loss_reduction=data_args.loss_reduction),
loss_reduction_all_gather=data_args.loss_reduction_all_gather,
)
# internvl_chat/internvl/train/dataset_packed.py -> packed_collate_fn
for feat_idx, feat in enumerate(features):
data_index = feat.pop('data_index')
curr_cu_seqlens, curr_indexes, curr_loss_weight = PackedDataset.get_cu_seqlens_and_indexes(
data_index=data_index,
input_ids=feat['input_ids'],
labels=feat['labels'],
len2weight=len2weight,
)
# internvl_chat/internvl/train/dataset_packed.py -> get_cu_seqlens_and_indexes
def get_cu_seqlens_and_indexes(
data_index: torch.LongTensor, # (seq_len,)
input_ids: torch.LongTensor, # (seq_len,)
labels: torch.LongTensor, # (seq_len,)
len2weight: callable,
):
indexes = []
cu_seqlens = [0]
loss_weight = []
start = data_index.min()
end = data_index.max() + 1
# refer to the group IDs
for i in range(start, end):
num_tokens = (data_index == i).sum().item()
indexes.extend(list(range(num_tokens)))
# 更新累积序列长度
cu_seqlens.append(cu_seqlens[-1] + num_tokens)
assert num_tokens > 0
# 确保当前数据块的所有 data_index 都等于 i,保证数据分组的正确性
curr_data_index = data_index[cu_seqlens[-2]:cu_seqlens[-2]+num_tokens]
assert (curr_data_index == i).all(), data_index
curr_labels = labels[cu_seqlens[-2]:cu_seqlens[-2]+num_tokens]
num_effective_tokens = (curr_labels != IGNORE_TOKEN_ID).sum().item()
loss_weight.extend([len2weight(num_effective_tokens)] * num_tokens)
assert len(indexes) == data_index.size(0), f'{len(indexes)=}, {data_index.size(0)=}'
loss_weight = torch.tensor(loss_weight, dtype=torch.float32)
return cu_seqlens, indexes, loss_weight
# internvl_chat/internvl/model/internvl_chat/modeling_internvl_chat.py -> forward
if labels is not None and loss_weight is not None:
loss_weight = torch.tensor(loss_weight, dtype=torch.float32, device=labels.device)
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
shift_weights = loss_weight[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss(reduction='none')
shift_logits = shift_logits.view(-1, self.language_model.config.vocab_size)
shift_labels = shift_labels.view(-1)
shift_weights = shift_weights.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
shift_weights = shift_weights.to(shift_logits.device)
# per token loss
loss = loss_fct(shift_logits, shift_labels)
shift_weights_sum = shift_weights.sum()
if loss_reduction_all_gather:
dist.all_reduce(shift_weights_sum, op=dist.ReduceOp.AVG)
loss = loss * shift_weights
loss = loss.sum() / shift_weights_sum
if ignore_flag:
loss = loss * 0.0
4 数据安排
4.1 Dataset Configuration

不同数据集的configuration
-
Data Augmentation:前文提到的JPEG compression。
-
Max Tile Number:动态分辨率方案切分子图(tiles)的最大数量。
-
Repeat Factor:单一dataset的迭代轮数。对于一个特定的dataset,internVL的训练过程之中最多将其迭代4轮。
4.2 Multimodal Data Packing
数据拼接方案,通过将多个样本拼接成长序列来减少填充,从而最大化模型输入序列容量的利用率。一般而言,我们通常考虑max token per sequence即可,因为视觉信息通过ViT+MLP已经转化成了visual token。但是,internVL的训练代码对其进行了更细的限定:同时限定语言学信息:max linguistic token per sequence以及视觉信息:max tiles per sequence。在implementation层面,是先判断是否满足max tiles per sequence再判断是否满足max linguistic token per sequence。
# internvl_chat/internvl/train/dataset_packed.py ->PackedDataset.find_buffer
def find_buffer(self, buffer_list, new_sample):
# NOTE: use `bisect` to search might be faster
find = False
find_idx = -1
num_images_current = new_sample['pixel_values'].size(0)
for buffer_idx, buffer in enumerate(buffer_list):
num_images_buffer = buffer['pixel_values'].size(0)
if num_images_buffer + num_images_current <= self.num_images_expected: #判断tiles
num_merged_tokens = new_sample['input_ids'].size(0) + buffer['input_ids'].size(0)
if num_merged_tokens <= self.max_packed_tokens: #判断linguistic tokens
find = True
find_idx = buffer_idx
break
if self.allow_overflow and len(buffer_list) >= self.max_buffer_size // 2:
find = True
find_idx = buffer_idx
if find:
return buffer_list.pop(find_idx)
return None
5 结语
现在业界充斥着一些观点:模型架构已经几乎固定,模型效果的好坏全靠数据质量。但是internVL这篇技术报告还是给了不少比较令人耳目一新的训练策略。作为大模型训练从业者,不能仅仅把自己定位成一个数据搬运工,即训练代码细节全然不知仅仅在数据配比上做消融,这不是未来的核心竞争力。
由于我本科在英国学的就是CS的AI track,刚入门时我酷爱读paper却很少看代码,就导致经常眼高手低,觉得自己理论很充足但是一看代码就傻眼就看不懂,觉得那些不重要。后面到了硕士,导师(教授)在每周的meeting上都会和我一起讨论代码层面上的事情(虽然那个意大利人总是会阴阳怪气我代码能力差),他称之为:make your hand dirty with code。
后续如果有时间我甚至想找一个成熟的模型,把训练框架中每一块小小的积木都深度剖析一下,走到底层才能创新。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











