






文章目录
前情提要
本人是一名大三学生,由于期末复习需要,所以按照老师的ppt总结整理此笔记,希望对你有所帮助
第四章 汇编程序设计
1. 伪操作的含义,了解几个常用的:GBLA、GBLL 和 GBLS,LCLA、LCLL 和 LCLS,SETA、SETL、SETS,数据定义伪操作:DCB、DCW、DCD,其他常用 伪操作(AREA,END,ALIGN,EXTERN, GET,MACRO,MEND)
与单片机汇编程序设计一样,在ARM汇编语言程序里,有一些特殊指令助记符,这些助记符与指令系统的真正的指令不同,没有相对应的操作码,通常称这些特殊指令助记符为伪指令,他们所完成的操作称为伪操作。
伪操作在源程序中的作用是为完成汇编程序作各种准备工作的,这些伪操作仅在汇编过程中起作用,一旦汇编结束,伪操作的使命就完成。
在ARM的汇编程序中,有如下几种伪指令:符号定义伪指令、数据定义伪指令、汇编控制伪指令、宏指令以及其他伪指令。
符号定义伪指令
符号定义伪指令用于定义ARM汇编语言程序中的变量、对变量赋值以及定义寄存器的别名等操作。常见的符号定义伪指令有如下几种:
- 用于定义全局变量的GBLA、GBLL和GBLS。
- 用于定义局部变量的LCLA、LCLL和LCLS。
- 用于对变量赋值的SETA、SETL、SETS。
- 为通用寄存器列表定义名称的RLIST。
为一个协处理器的寄存器定义名称的伪指令:CN, 0-15为一个协处理器定义名称的伪指令:CP,0-15为一个单精度的向量浮点数运算(VFP)寄存器定义名称的伪指令:SN,寄存器名S0-S31为一个双精度的向量浮点数运算VFP寄存器定义名称的伪指令:DN,D0-D15为一个FPA浮点寄存器定义名称的伪指令:FN,F0-F7
- GBLA GBLL GBLS
GBLA伪指令用于定义一个全局的数字变量,并初始化为0;
GBLL伪指令用于定义一个全局的逻辑变量,并初始化为F(假);
GBLS伪指令用于定义一个全局的字符串变量,并初始化为空;
- 以上三条伪指令用于定义全局变量,因此在整个程序范围内变量名必须唯一。
语法格式:GBLA ( GBLL 或 GBLS ) 全局变量名
例子:
GBLA Number1;定义一个全局的数字变量,变量名为Number1
Number1 SETA 0xaa ;将Number1变量赋值为0xaa
GBLL True1;定义一个全局的逻辑变量,变量名为True1
- LCLA LCLL LCSL
LCLA伪指令用于定义一个局部的数字变量,并初始化为0;
LCLL伪指令用于定义一个局部的逻辑变量,并初始化为F(假);
LCLS伪指令用于定义一个局部的字符串变量,并初始化为空;
- 以上三条伪指令用于声明局部变量,在其作用范围内变量名必须唯一。
语法格式: LCLA ( LCLL 或 LCLS ) 局部变量名
【例】
LCLA Number2 ;声明一个局部的数字变量,变量名为Number2
Number2 SETA 0xaa ;将Number2变量赋值为0xaa
LCLL Logic2 ;声明一个局部的逻辑变量,变量名为Logic2
Logic2 SETL {TRUE} ;将Logic2变量赋值为真
LCLS String2 ;定义一个局部的字符串变量,变量名为String2
String2 SETS “Testing” ;将String2变量赋值为“Testing”
- SETA SETL SETS
SETA伪指令用于给一个数学变量赋值;
SETL伪指令用于给一个逻辑变量赋值;
SETS伪指令用于给一个字符串变量赋值;
-
其中,**变量名为已经定义过的全局变量或局部变量,**表达式为将要赋给变量的值。
语法格式: 变量名 SETA ( SETL 或 SETS ) 表达式
【例】
LCLA Number3 ;声明一个局部的数字变量,变量名为Number3
Number3 SETA 0xaa ;将Number3变量赋值为0xaa
LCLL Logic3;声明一个局部的逻辑变量,变量名为Logic3
Logic3 SETL {TRUE};将Logic3变量赋值为真
- RLIST
RLIST伪指令可用于对一个通用寄存器列表定义名称,使用该伪指令定义的名称可在ARM指令LDM/STM中使用。
在LDM/STM指令中,列表中的寄存器访问次序为根据寄存器的编号由低到高,而与列表中的寄存器排列次序无关。
语法格式: 名称 RLIST { 寄存器列表 }
【例】
RegList RLIST {R0-R5,R8,R10} ;将寄存器列表名称定义为RegList,可在ARM指令LDM/STM中通过该名称访问寄存器列表。
……
STMFD SP!,RegList ;保存寄存器列表RegList到堆栈
数据定义伪指令
数据定义伪操作一般用于为特定的数据分配存储单元,同时可完成已分配存储单元的初始化。常见的数据定义伪操作有如下几种:
- DCB 用于分配一片连续的字节存储单元并用指定的数据初始化。
- DCW(DCWU)用于分配一片连续的半字存储单元并用指定的数据初始化。
- DCD(DCDU) 用于分配一片连续的字存储单元并用指定的数据初始化。
- DCFD(DCFDU)用于为双精度的浮点数分配一片连续的字存储单元并用指定的数据初始化。
- DCFS(DCFSU) 用于为单精度的浮点数分配一片连续的字存储单元并用指定的数据初始化。
- DCQ(DCQU) 用于分配一片以8字节为单位的连续的存储单元并用指定的数据初始化。
- DCDO 用于分配一段字的内存单元,将每个单元的内容初始化为该单元相对于基址寄存器的偏移量
- DCI 用于分配一段字的内存单元,并用单精度的浮点数据初始化,指定内存单元存放的是代码,而不是数据
- SPACE 用于分配一片连续的字节存储单元,并初始化为0
- MAP 用于定义一个结构化的内存表首地址
- FIELD 用于定义一个结构化的内存表的数据域
- LTORG 用于声明一个文字池(缓冲池)
- DCB
DCB伪操作用于分配一片连续的字节存储单元并用伪指令中指定的表达式初始化。其中,表达式可以为0~255的数字或字符串。DCB也可用“=“代替。
语法格式
{label} DCB expr{,expr}…
label可选的程序标号
【例】
String DCB “This is a test!” ;分配一片连续的字节存储单元并初始化。
Parameter DCB 0x33,0x44,0x55
;分配一片连续的字节存储单元并初始化。
2.DCW
DCW(或DCWU)伪操作用于分配一片连续的半字存储单元并用指定的表达式初始化。
其中,表达式可以是程序标号或数字表达式。
用DCW分配的存储单元是半字对齐的,而用DCWU分配的存储单元并不严格半字对齐。
语法格式:{label} DCW/DCWU expr{,expr}…
label可选的程序标号
【例】
Data DCW 0,1,2,3 ;分配一片连续的半字存储
单元并初始化。
- DCD 或DCDU
DCD(或DCDU)伪操作用于分配一片连续的字存储单元并用指定的表达式初始化。
其中,表达式可以为程序标号或数字表达式。DCD也可用“&”代替。
用DCD分配的字存储单元是字对齐的,而用DCDU分配的字存储单元并不严格字对齐。
语法格式:{label} DCD/DCDU expr{,expr}…
【例】
Data DCD 3,4,5,6 ;分配一片连续的字存储单元并初始化。
- DCFD或DCFDU
DCFD(或DCFDU)伪操作用于为双精度的浮点数分配一片连续的字存储单元并用指定的表达式初始化。每个双精度的浮点数占据两个字单元。
用DCFD分配的字存储单元是字对齐的,而用DCFDU分配的字存储单元并不严格字对齐。
语法格式:标号 DCFD(或DCFDU) 表达式
【例】
FData DCFD 2E115,-5E7 ;分配一片连续的字存储单元并初始化为指定的双精度数。
- DCFS 或 DCFSU
DCFS(或DCFSU)伪操作用于为单精度的浮点数分配一片连续的字存储单元并用伪操作中指定的表达式初始化。每个单精度的浮点数占据一个字单元。
用DCFS分配的字存储单元是字对齐的,而用DCFSU分配的字存储单元并不严格字对齐。
语法格式:标号 DCFS(或DCFSU) 表达式
【例】
Sdata DCFS 1,2E5,-5E-7 ;分配一片连续的字存储单元并初始化为指定的单精度数。
- DCQ(或DCQU)
DCQ(或DCQU)伪操作用于分配一片以8个字节为单位的连续存储区域并用伪操作中指定的表达式初始化。
分配的字数等于expr个数的2倍。
用DCQ分配的存储单元是字对齐的,而用DCQU分配的存储单元并不严格字对齐。
语法格式:标号 DCQ(或DCQU) 表达式
【例】
Data DCQ 100,1000 ;分配一片连续的存储单元并初始化为指定的值。
- DCDO
DCDO用于分配一段字内存单元,并将每个字单元的内容初始化为expr基于静态基址寄存器R9内容的偏移量。
DCDO伪操作为静态基址寄存器R9的偏移量分配内存单元,该指令需要内存字对齐。
语法格式:{label} DCDO expr{,expr}….
【例】
IMPORT externsys
Data DCDO externsys;分配32位的字单元,其值为标号externsys相对于R9的偏移量
汇编控制(Assembly Control)伪操作
汇编控制伪操作用于控制汇编程序的执行流程,常用的汇编控制伪操作包括以下几条:
- IF、ELSE、ENDIF
条件汇编代码文件内的一段源代码 - WHILE、WEND
根据条件重复汇编 - MACRO、MEND
标识宏定义的开始和结束 - MEXIT
中途跳转出宏
- IF ELSE ENDIF
IF、ELSE、ENDIF伪操作能根据条件的成立与否决定是否执行某个指令序列。当IF后面的逻辑表达式为真,则执行指令序列1,否则执行指令序列2。其中,ELSE及指令序列2可以没有,此时,当IF后面的逻辑表达式为真,则执行指令序列1,否则继续执行后面的指令。
IF、ELSE、ENDIF伪操作可以嵌套使用。
语法格式:
IF 逻辑表达式
指令序列 1
{ ELSE
指令序列 2
}
ENDIF
【例】
GBLS Version ;定义一个全局的字符串变量,
;变量名为Version
……
IF Version =“V1”
指令序列1
ELSE
指令序列2
ENDIF
- WHILE WEND
WHILE、WEND伪操作能根据条件的成立与否决定是否循环执行某个指令序列。当WHILE后面的逻辑表达式为真,则执行指令序列,该指令序列执行完毕后,再判断逻辑表达式的值,若为真则继续执行,一直到逻辑表达式的值为假。WHILE、WEND伪操作可以嵌套使用。
语法格式:
WHILE 逻辑表达式
指令序列
WEND
【例】
GBLA Counter ;声明一个全局的数字变量,变量名为
Counter,作为循环计数器
……
WHILE Counter < 10
指令序列
WEND
- MACRO MEND
MACRO、MEND伪操作可以将一段代码定义为一个整体,称为宏指令,然后就可以在程序中通过宏指令多次调用该段代码。
MACRO ;标志宏定义的开始
{$label} macroname {$parameter, {$parameter}…}
指令序列
MEND
【例】
MACRO
CODE_1 ; 宏名为CODE_1,无参数
LDR R0,=rPDATG ; 读取PG0口的值
LDR R1,[R0]
ORR R1,R1,#0X01 ; CSI置位
STR R1,[R0]
MEND
宏定义中,宏指令可以使用一个或多个参数,当宏指令被展开时,这些参数被相应的值替换。
MACRO ;宏定义
CALLSubfunction $Function,$dat1,$dat2
;宏名为CALLSubfunction,带3个参数
IMPORT $Function ;声明外部子程序名
MOV R0,$dat1 ;设置子程序参数R0=$dat1
MOV R1,$dat2
BL Function ;调用子程序
MEND ;宏定义结束
- MEXIT
MEXIT用于从宏定义中跳转出去。
语法格式:
MEXIT
如果要提前从宏体中退出,例如从一个宏内的循环体中退出,可采用MEXIT伪操作提前跳出宏体。
其他常用的伪操作
其他的一些使用较频繁的伪操作:
- AREA
- ALIGN
- CODE16 CODE32
- ENTRY
- END
- EQU
- EXPORT(或GLOBAL)
- IMPORT
- EXTERN
- GET(或INCLUDE)
- INCBIN
- AREA
AREA伪操作用于定义一个代码段或数据段。ARM汇编程序设计采用分段式设计,一个ARM汇编源程序至少需要一个代码段,大的程序可以包含多个代码段和数据段。当程序太长时,也可以将程序分为多个代码段和数据段。
使用AREA伪指令将程序分为多个ELF(Executable and Linkable Format)格式的段。
【例】
AREA Init,CODE,READONLY
。。。。。。。。。。。。
指令序列
;该伪指令定义了一个代码段,段名为Init,属性为只读
- ALIGN
ALIGN伪操作可通过添加填充字节的方式,使当前位置满足一定的对齐方式。其中,表达式的值用于指定对齐方式,可能的取值为2的幂,如1、2、4、8、16等。默认4个字节对齐。
若未指定表达式,则将当前位置对齐到下一个字的位置。偏移量也为一个数字表达式,若使用该字段,则当前位置的对齐方式为:2的表达式次幂+偏移量。
【例】
AREA Init,CODE,READONLY,ALIGN=3 ;指定后面的指令为8字节对齐。
指令序列
END
- CODE16 CODE32
- CODE16伪操作通知汇编器,其后的指令序列为16位的Thumb指令。
- CODE32伪操作通知汇编器,其后的指令序列为32位的ARM指令。
- CODE16和CODE32伪操作只告诉编译器后面的指令是16位或32位的类型,指令本身不能进行程序状态的切换, 如果要进行状态的切换,可以使用BX指令进行操作。
【例】
AREA Init,CODE,READONLY ;Init代码段名
……
CODE32 ;通知编译器其后的指令为32位的ARM指令
LDR R0,=NEXT+1 ;将跳转地址放入寄存器R0
BX R0 ;程序跳转到新的位置执行,并将处理器切换到Thumb工作状态
……
CODE16 ;通知编译器其后的指令为16位的Thumb指令
NEXT
LDR R3,=0x3FF
……
END ;程序结束
- ENTRY
- ENTRY伪操作用于指定程序的入口点。
- 在一个完整的汇编语言程序中至少要有一个ENTRY
- (也可以有多个,当有多个ENTRY时,程序的真正入口点由链接器指定),
- 但在一个源文件里最多只能有一个ENTRY(可以没有)。
【例】
AREA Init,CODE,READONLY
ENTRY ;指定应用程序的入口点
……
- END
- END伪操作用于通知汇编器已经到了源程序的结尾。
- 每一个汇编源文件都需要使用一个END伪操作,指示本源程序结束。
【例】
AREA Init,CODE,READONLY
……
END ;指定应用程序的结尾
- EQU
-
EQU伪操作用于为程序中的常量、标号等定义一个等效的字符名称,类似于C语言中的#define。其中EQU可用“*”代替。
-
名称为EQU伪操作定义的字符名称,当表达式为32位的常量时,可以指定表达式的数据类型,可以有以下三种类型:CODE16、CODE32和DATA。
语法格式:
名称 EQU 表达式 { ,类型 }
【例】
ABCE EQU label+8 ;定义地址标号ABCD为label+8
Test EQU 50 ;定义标号Test的值为50
Addr EQU 0x55,CODE32 ;定义Addr的值为0x55,且该处为32位的ARM指令。
- EXPORT或GLOBAL
- EXPORT伪操作用于在程序中声明一个全局的标号,该标号可在其他的文件中引用。
- EXPORT可用GLOBAL代替。
- 标号在程序中区分大小写。
【例】
AREA Init,CODE,READONLY
EXPORT main ;声明一个可全局引用的标号main
……
END
- IMPORT
- IMPORT伪操作用于通知编译器要使用的标号在其他的源文件中定义,但要在当前源文件中引用
- 而且无论当前源文件是否引用该标号,该标号均会被加入到当前源文件的符号表中。
【例】
AREA Init,CODE,READONLY
IMPORT main ;通知编译器当前文件要引用标号main,但main在其他源文件中定义
……
END
- EXTERN
- EXTERN伪操作用于通知编译器要使用的标号在其他的源文件中定义,但要在当前源文件中引用,
- 如果当前源文件实际并未引用该标号,该标号就不会被加入到当前源文件的符号表中。
- 注意: 该伪操作与IMPORT的区别是,IMPORT伪操作无论当前源文件是否引用该标号,该标号均会被加入到当前源文件的符号表中。
【例】
AREA Init,CODE,READONLY
EXTERN main ;通知编译器当前文件要引用标号main,main在其他源文件中定义,如果本文件中没有使用main,则main就不会被加入到当前源文件的符号表中。
……
END
- GET INCLUDE
- GET伪操作用于将一个源文件包含到当前的源文件中,并将被包含的源文件在当前位置进行汇编处理。
- 可以使用INCLUDE代替GET。使用方法与C语言中的“include”相似。
- GET伪指令只能用于包含源文件, 如果需要包含经过编译后的二进制目标文件,需要使用INCBIN伪指令。
语法格式: GET 文件名
【例】
AREA Init,CODE,READONLY
GET a1.s ;通知编译器当前源文件包含源文件a1.s
GET C:\a2.s;通知编译器当前源文件包含源文件C:\ a2.s
……
END
- INCBIN
- INCBIN伪操作用于将一个二进制目标代码文件或任意格式的数据文件包含到当前的源文件中,
- 被包含的文件不作任何变动地存放在当前文件中,编译器从其后开始继续处理。
【例】
AREA Init,CODE,READONLY
INCBIN a1.dat ;通知编译器当前源文件包含文件a1.dat
INCBIN C:\a2.txt ;通知编译器当前源文件包含文件C:\a2.txt
INCBIN a3.bin ;通知编译器当前源文件包含文件a3.bin
……
END
- RN
RN 伪指令用于给一个寄存器定义一个别名。采用这种方式可以方便程序员记忆该寄存器的功能。其中,名称为给寄存器定义的别名,表达式为寄存器的编码。
语法格式: 名称 RN 表达式
使用示例:
Temp RN R0 ;将R0 定义一个别名Temp
2. 汇编程序设计:常用程序段(子程序调研、数据比较跳转、分支选择、循 环)、ppt 中的例子能看懂、能自己写。
汇编语法:
在一个项目设计中:
- 至少需要有一个汇编源文件或C程序文件,
- 可以有多个汇编文件或多个C程序文件,
- 或者C语言和汇编语言混合编程的文件。
- 汇编程序源文件的扩展名必须是“.s”。
| 源程序 | 文件名 |
| 汇编源程序 | .s |
| C文件 | .c |
| 头文件 | .h |
1 汇编语句格式
ARM(Thumb)汇编语言的语句格式为:
{标号} {指令或伪指令} {;注释}
正确的例子:
……
String1 SETS “My string1”
Count RN R0 ;给R0寄存器定义别名
START
LDR R0,=0x12345
MOV R1,#0
LOOP
MOV R2,#3
……
错误的例子:
START MOV R0,#1 ;标号START没有顶头写
ABC: MOV R1,#2 ;标号后不能带:
MOV R2,#3 ;指令不允许顶头写
Loop Mov R2,#3 ;指令中大小写混合
B loop ;无法跳转到Loop去,标号大小写敏感
在ARM 汇编中,符号可以代表地址、变量、数字常量。当符号代表地址时又称为标号,符号就是变量的变量名、数字常量的名称、标号,符号的命名规则如下:
- 符号由大、小写字母、数字以及下划线组成。
- 符号区分大小写,同名的大、小写符号会被编译器认为是两个不同的符号。
- 符号在其作用范围内必须唯一。
- 自定义的符号名不能与系统的保留字相同。
- 符号名不能与指令或伪指令同名。
汇编语言程序设计
在ARM(Thumb)汇编语言程序中,以程序段为单位组织代码。段是相对独立的指令或数据序列,具有特定的名称。段可以分为代码段和数据段,代码段的内容为执行代码,数据段存放代码运行时需要用到的数据。一个汇编程序至少应该有一个代码段,当程序较长时,可以分割为多个代码段和数据段,多个段在程序编译链接时最终形成一个可执行的映象文件。
可执行映象文件通常由以下几部分构成
- 一个或多个代码段,代码段的属性为只读。
- 零个或多个包含初始化数据的数据段,数据段的属性为可读写。
- 个或多个不包含初始化数据的数据段,数据段的属性为可读写。
链接器根据系统默认或用户设定的规则,将各个段安排在存储器中的相应位置。因此源程序中段之间的相对位置与可执行的映象文件中段的相对位置一般不会相同。
以下是一个汇编语言源程序的基本结构:
AREA Init,CODE,READONLY
ENTRY ;程序入口点
Start ;标号,指向LDR伪指令
LDR R0,=0x3FF5000
MOV R1,#0xFF
STR R1,[R0]
LDR R0,=0x3FF5008
MOV R1,#0x01
STR R1,[R0]
……
END
在汇编语言程序中,用AREA伪指令定义一个段,并说明所定义段的相关属性,本例定义一个名为Init的代码段,属性为只读。ENTRY伪指令标识程序的入口点,接下来为指令序列,程序的末尾为END伪指令,该伪指令告诉编译器源文件的结束, 每一个汇编语言程序段都必须有一条END伪指令,指示代码段的结束。
子程序调用
在ARM汇编语言程序中,子程序的调用一般是通过BL指令来实现的。在程序中,使用指令“BL 子程序名”即可完成子程序的调用。
AREA Init,CODE,READONLY
ENTRY
Start
LDR R0,=0x3FF5000
MOV R1,#0xFF
STR R1,[R0]
LDR R0,=0x3FF5004
MOV R1,#0x01
STR R1,[R0]
BL PRINT_TEXT
……
PRINT_TEXT
……
MOV PC,LR
……
END
宏定义及其作用
- 使用宏定义可以提高程序的可读性,简化程序代码和同步修改。
- ARM宏定义与标准C语言的#define相似,只在源程序中进行字符的简单替代。
- 宏定义从MACRO伪指令开始,到MEND结束,并可以使用参数。
MACRO ;宏定义
CALLSubfunction $Function,$dat1,$dat2 ;宏名为
;CALLSubfunction,带3个参数
IMPORT $Function ;声明外部子程序名
MOV R0,$dat1 ;设置子程序参数R0=$dat1
MOV R1,$dat2
BL Function ;调用子程序
MEND ;宏定义结束
……
CALLSubfunction FADD1,#3,#2 ;宏调用,参数没有$
……
汇编处理后,宏调用将被展开,程序如下:
……
IMPORT FADD1
MOV R0,#3
MOV R1,#2
BL FADD1
……
数据比较跳转
汇编程序可以使用CMP指令进行两个数的比较,然后根据比较结果实现程序的跳转,代码如下:
CMP R5,#10 ;做减法
BEQ BRANCH1 ;如果R5为10,则跳转到BRANCH1
……
CMP R1,R2
ADDHI R1,R1,#1 ;如果R1>R2,则R1=R1+1
ADDLS R1,R1,#2 ;如果R1<=R2,则R1=R1+2
……
ANDS R1,R1,#0x80 ;R1=R1&0x80,并设置相应的标志位
BNE WAIT ;如果R1的第7位0,则跳转到WAIT
循环
下面的程序代码为汇编循环程序的例子,指定了循环的次数,每循环一次进行减1操作,并判断结果是否为0,如果为0则退出循环。
MOV R0,#10
LOOP
……
SUBS R0,R0,#1 ;R0自减1
BNE LOOP ;10次执行完 R0=0 NE条件不满足
;BNE不执行,执行下一条语句,退出循环
……
堆栈操作
可以使用存储器访问指令LDM/STM实现堆栈操作,用于子程序的寄存器保护。在使用堆栈前,首先需要分配好堆栈空间,设置好寄存器R13(即堆栈指针SP),否则操作失败。
OUTDAT
STMFD SP!,{R0-R7,LR} ;寄存器入栈, 从右向左
…… ;先压LR,R7…R0
BL DELAY
……
LDMFD SP!,{R0-R7,PC} ;寄存器出栈
;出栈从从左到右
;先弹R0,最后弹出PC,PC=LR,完成子程序的返回
查表操作
查表操作是汇编程序经常使用的一种功能,代码如下:
……
LDR R3,=DISP_TAB ;字模表的首地址
LDR R2,[R3,R5,LSL #2] ;根据R5的值查表, 取出相应的值。
……
下面的表为0-F的字模
DISP_TAB DCD 0xC0,0xF9,0xA4,0x99,0x92
DCD 0x82,0xF8,0x80,0x90,0x88,0x83
DCD 0xC6,0xA1,0x86,0x8E,0xFF
长跳转
- ARM的B指令和BL指令无法进行整个内存空间范围内的跳转(仅±32MB),
- 但可以通过对PC寄存器的赋值实现32位地址的跳转和调用。
【例】
LDR PC,=JUMP_FUNC ;跳转到JUMP_FUNC处
……
JUMP_FUNC ……. ;跳转到这里
……
特殊寄存器定义及应用
对ARM芯片的外设寄存器进行访问时,可以使用下面的代码对其寄存器进行定义并应用:
WDTCNT EQU 0x01D30008 ;看门狗计数器寄存器定义
……
LDR R0,=WDTCNT ;寄存器地址传给R0
MOV R1,#12
STR R1,[R0] ;用十进制12设置看门狗计数器寄存器
片外部件控制
在ARM芯片的外围部件的控制器中,一般会设置“置位/复位”寄存器,这样方便地实现对控制位的操作,而不影响其他位,而其他I/O位的状态保持不变。另外,ARM存储/保存指令具有偏移功能,所以对外围部件的控制寄存器进行操作时可以使用此功能,避免了每次都加载寄存器地址的操作,代码如下:
LDR R0,=GPIO_BASE
MOV R1,#0x00
STR R1,[R0,#0x04] ;基地址+0x04=IOSET,将IOSET设置为0
MOV R1,#0x10
STR R1,[R0,#0x0C] ;基地址+0x0C=IOCLR,将IOCLR设置为0x10
嵌入式C语言
1.文件包含伪指令
文件包含伪指令可将头文件包含到程序中,头文件中定义的内容有符号常量,复合变量原型、用户定义的变量原型和函数的原型说明等。编译器编译预处理时,用文件包含的正文内容替换到实际程序中。
(1)文件包含伪指令的格式
include <头文件名.h> /*标准头文件*/
include "头文件名.h " /*自定义头文件*/
(2)包含文件伪指令的说明
[!TIP]
- 常在头文件名后用.h作为扩展名,可带或不带路径。
- 头文件可分为标准头文件和自定义头文件。
- 尖括号内的头文件为标准头文件,由开发环境或系统提供。
- 双引号内的头文件为用户自定义头文件。
- 搜索时,首先在当前目录中搜索,其次按环境变量include指定的目录顺序搜索。
- 搜索到头文件后,就将该伪指令直接用头文件内容替换。
2.宏定义伪指令
宏定义伪指令分为:简单宏、参数宏、条件宏、预定义宏及宏释放。
(1)简单宏
格式如下:
#define 宏标识符 宏体
- 宏体超长时,允许使用续行符“\”进行续行,续行符和其后的换行符 \n 都不会进入宏体。
- 在定义宏时,应尽量避免使用C语言的关键字和预处理器的预定义宏,以免引起灾难性的后果。
- 在源文件中,用预处理器伪指令定义过宏标识符之后,就可用宏标识编写程序。当源文件被预处理器处理时,每遇到该宏标识符,预处理器便将宏展为宏体。
(2)参数宏
格式如下:
# define 宏标识符(形式参数表) 宏体
形式参数表为逗号分割的形式参数。
- 宏体是由单词序列组成。宏体超长时,允许使用续行符“\”进行续行,续行符和其后的换行符 \n 都不会进入宏体。
- 使用参数宏时,形式参数表应换为同样个数的实参数表,这一点类似于函数的调用。参数宏与函数的区别在于参数宏的形参数表中没有类型说明符。
- 预处理器在处理参数宏时使用2遍宏展开。第1遍展开宏体,第2遍对展开后的宏体用实参数替换形式参数。
例5.4 在Linux下ARM S3C2410X芯片的A/D转换的驱动程序的头文件s3c2410-adc.h中定义了下面三个宏。
#define ADC_WRITE(ch, prescale) ((ch)<<16|(prescale))
/*ADC通道号与预标值合成一个字*/
#define ADC_WRITE_GETCH(data) (((data)>>16)&0x7)
/*获得低三位,ADC通道号*/
#define ADC_WRITE_GETPRE(data) ((data)&0xff)
/*获得低八位,ADC的预定标值*/
(3)条件宏定义
格式如下:
格式1:
# ifdef 宏标识符 //若标识符已定义
# undef 宏标识符
# define 宏标识符 宏体
# else //若标识符未定义
# define 宏标识符 宏体
# endif
格式2:
# ifndef 宏标识符 //若标识符未定义
# define 宏标识符 宏体
# else //若标识符已定义
# undef 宏标识符
# define 宏标识符 宏体
# endif
其中:
[!TIP]
- 格式1是测试存在,格式2是测试不存在。
- else可有,也可没有。
(4)宏释放
用于释放原先定义的宏标识符。经释放后的宏标识符可再次用于定义其他宏体。
格式如下:
# undef 宏标识符
例5.6
#define SIZE 512
…
buf=SIZE*blks /*宏扩展为buf=512*blks; */
…
#undef SIZE
#define SIZE 128
…
buf=SIZE*blks /*宏扩展为buf=128*blks; */
条件编译伪指令
格式如下:
# if(条件表达式1)
…
# elif (条件表达式2)
…
# elif (条件表达式3)
…
# elif (条件表达式n)
…
# else
…
# endif
例子:
# if _B0SIZE==B0SIZE_BYTE
typedef unsigned char PB0SIZE;
# elif _B0SIZE==B0SIZE_SHORT
typedef unsigned short PB0SIZE;
# elif _B0SIZE==B0SIZE_WORD
typedef unsigned long PB0SIZE;
# endif
3. ATPCS 规则:寄存器、数据栈、参数传递规则
ATPCS(ARM-Thumb Procedure Call Standard)规则
-
寄存器的使用规则
-
数据栈的使用规则
-
参数的传递规则
1.寄存器的使用规则
- 子程序间通过寄存器R0R3来传递参数,记为A1A4(别名)。
- 被调用的子程序在返回前无须恢复寄存器R0~R3的内容。
- 子程序中使用寄存器**R4R11**来保存局部变量。记为V1V8(别名)。
- 如果在子程序中使用到了寄存器V1~V8中的某些寄存器,则子程序进入时必须保存这些寄存器的值,在返回前必须恢复这些寄存器的值
- 对于子程序中没有用到的寄存器,则不必进行这些操作。在Thumb程序中,通常只能使用寄存器R4~R7来保存局部变量。
- 寄存器R13用做数据栈指针,记作SP。
- 在子程序中寄存器R13不能用做其他用途。
- 寄存器SP在进入子程序时的值和退出子程序时的值必须相等。
- 寄存器R14称为链接寄存器,记作LR。
- 它用于保存子程序的返回地址。
- 如果在子程序中保存了返回地址,则寄存器R14可作其他用途。
- R15是程序计数器,记作PC。不能作其他用途。
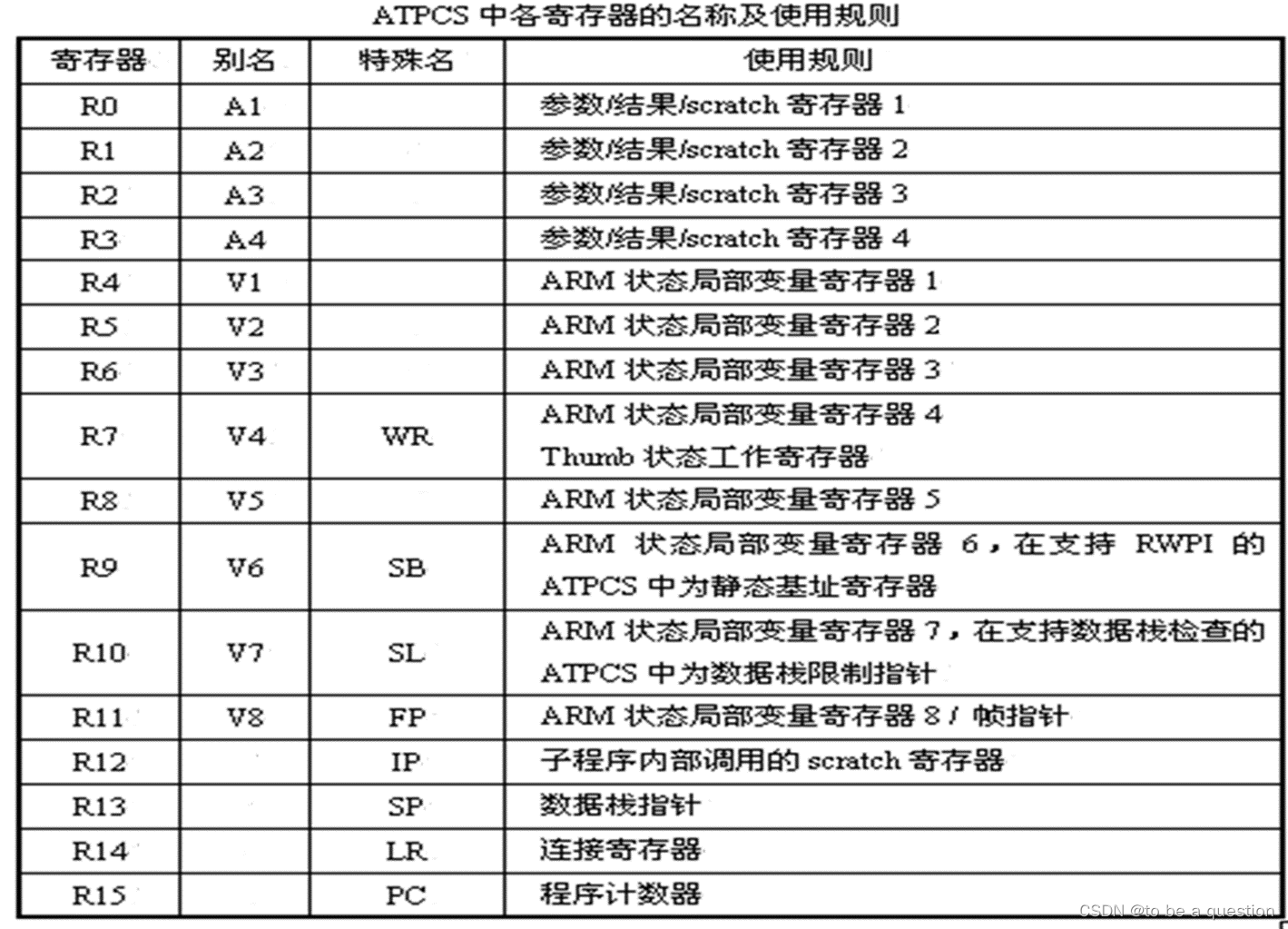
2.数据栈的使用规则
有下面4种数据栈:
- FD(Full Descending) 满递减
- ED(Empty Descending) 空递减
- FA(Full Ascending) 满递增
- EA(Empty Ascending) 空递增
ATPCS规定数据栈为FD(满递减) 类型,
并且对数据栈的操作是8字节对齐的。
异常中断处理程序可使用中断程序的数据栈。
- 数据栈指针(Stack Point):最后一个写入栈的数据的内存地址。
- 数据栈的基地址(Stack Base):数据栈的最高地址。ATPSC中的数据栈是FD型,最早入栈的数据所占的内存单元是基地址的下一个内存单元。
- 数据栈界限(Stack Limit):数据栈中可使用的最低的内存单元地址。
- 数据栈中的数据帧(Stack Frames):数据栈中为子程序分配用来保存寄存器和局部变量的区域。
3. 参数的传递规则
(1)参数个数固定的子程序参数传递规则
若系统含浮点运算硬件部件,浮点参数传递规则:
- 各个浮点参数按顺序处理。
- 为每个浮点参数分配FP寄存器。方法:满足该浮点参数需要的且编号最小的一组连续的FP寄存器。
第一个整数参数,通过寄存器R0~R3来传递。其他参数通过数据栈传递。
(2)参数个数可变的子程序参数传递规则
当参数不超过4个,用R0~R3传递参数,
当参数超过4个时,还可以使用数据栈来传递参数。
在参数传递时,所有参数看作是存放在连续的内存字单元中的字数据。然后,依次将各字数据传递到寄存器 R0~R3中。
如果参数多于4个,将剩余的字数据传送到数据栈中,入栈的顺序与参数顺序相反,即最后一个字数据先入栈。
(3)子程序结果返回规则
结果为一个32位整数,可通过寄存器R0返回;
结果为一个64位整数,可通过寄存器R0,R1返回,依次类推;
结果为一个浮点数时,可通过运算部件的寄存器F0、D0来返回;
结果为复合型的浮点数(如复数)时,可通过寄存器F0~Fn或者D0~Dn来返回。
对于位数更多的结果,需通过内存来传递,如通过数据栈来传递。
4. C 和汇编相互调用的程序能够看懂,及简单的程序编写。
C程序中嵌入汇编程序
2.内嵌汇编指令的特点
(1)操作数
- 作为操作数的寄存器和常量可以是C/C++表达式。是char、short、int类型,而且这些表达式都是作为无符号数进行操作。
- 编译器将会计算这些表达式的值,并为其分配寄存器。
- 不是真正意义的汇编
(2)物理寄存器
- 内嵌汇编指令中使用物理寄存器的限制:
- 不能直接向PC寄存器中赋值,程序的跳转只能通过B指令和BL指令实现。
- 在内嵌汇编指令中,不要使用过于复杂的C/C++表达式。
- 编译器可能会使用R12寄存器或R13寄存器存放编译的中间结果,在计算表达式值时可能会将寄存器R0到R3、R12以及R14用于子程序调用。
- 一般不要指定物理寄存器(会影响编译器分配寄存器)。
(3)常量
常量前的符号#可省略。若表达式前使用了符号#,则必须是一个常量。
(4)指令展开
如果包含常量操作数,该指令可能会被汇编器展开成几条指令。例如指令:
ADD R0,R0,#1023
可能会被展开成下面的指令序列:
ADD R0,R0,#1024
SUB R0,R0,#01
MUL指令会被展开成一系列加法和移位操作。
(5)标号
C/C++程序中的标号可被内嵌的汇编指令使用。但只有B指令可使用C/C++程序中的标号,指令BL不能使用C/C++程序中的标号。
指令B使用C/C++程序中的标号格式:
B{cond} label
(6)内存单元的分配
内嵌汇编器不支持汇编语言用于内存分配的伪操作,所用的内存单元的分配都是通过C/C++程序完成的,分配的内存单元通过变量供内嵌的汇编器使用。
(7)SWI和BL指令的使用
内嵌SWI和BL指令中3个可选寄存器列表:
- 第1个寄存器列表用于存放输入的参数。
- 第2个寄存器列表用于存放返回的参数。
- 第3个寄存器列表的内容供被调用的子程序作为工作寄存器。
3.内嵌的汇编器与armasm的区别
在功能和使用方法上主要有以下特点:
- 不能写PC (MOV PC, LR)
- 不支持伪指令LDR Rn,=expression,但可用指令: MOV Rn,expression来代替。
- 除NOP外,不支持ADR、ADRL等伪指令。
- 指令中的C变量不要与任何物理寄存器重名
- LDM/STM指令中的寄存器列表只能使用物理寄存器,不能使用C表达式
- 不支持指令BX/BLX
- 用户不用维护数据栈
- 不要轻易改变处理器模式。
- 不支持内存分配操作














 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









