







实验3:FCN对Pascal VOC2012数据集进行语义分割
一:实验目的与要求
1:掌握图像分割的含义。
2:掌握利用FCN建立训练模型。
3:掌握使用FCN对Pascal VOC2012数据集进行语义分割。
二:实验内容
1:用FCN网络完成对Pascal VOC2012数据集进行语义分割。
2:可视化比较FCN8s,FCN16s,FCN32s的分割效果和Groud Truth。
3:尝试调整网络参数提高模型的分割精度。
三:实验环境
本实验所使用的环境条件如下表所示。
| 操作系统 | Ubuntu(Linux) |
| 程序语言 | Python(3.11.4) |
| 第三方依赖 | torch, torchvision, tqdm,ninja,PIL,argparse,os,sys,__future__等 |
四:方法流程
1:编写数据加载代码,下载Pascal VOC2012数据集。
2:调用FCN系列结构的模块化代码,包括FCN8s、FCN16s、FCN32s。
3:调用FCN在数据集上的训练和验证代码,便于在训练过程中输出训练集和测试集的效果。
4:编写可视化比较原图和FCN测试后的输出结果图。
5:尝试改进FCN模型,提高分割精度。
五:实验展示(训练过程和训练部分结果进行可视化)
1:FCN8s的训练
设置训练指令,采用FCN8s作为分割模型,采用vgg16作为backbone卷积模型,采用0.0001作为初始学习率,采用30作为训练的迭代次数,采用Pascal VOC 2012作为数据集。
完整指令如下所示:
| cd awesome-semantic-segmentation-pytorch/scripts python train.py --model fcn8s --backbone vgg16 --dataset pascal_voc --lr 0.0001 --epochs 30 |
本次训练的时长统计为:Total training time: 0:36:34.115804 (0.1998s / it)
本次训练的训练日志路径为:/home/ubuntu/awesome-semantic-segmentation-pytorch/runs/logs/fcn8s_vgg16_pascal_voc_log.txt
本次训练的训练集学习率变化如下图所示:
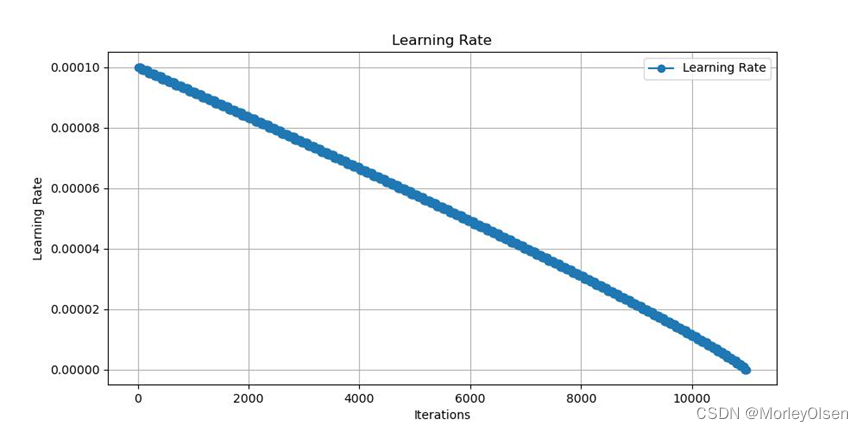
本次训练的训练集损失值变化如下图所示:
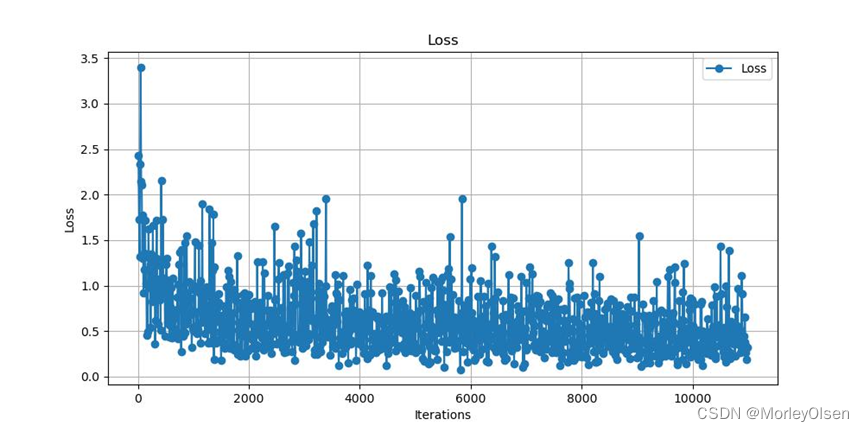
本次训练的验证集mIoU变化如下图所示:
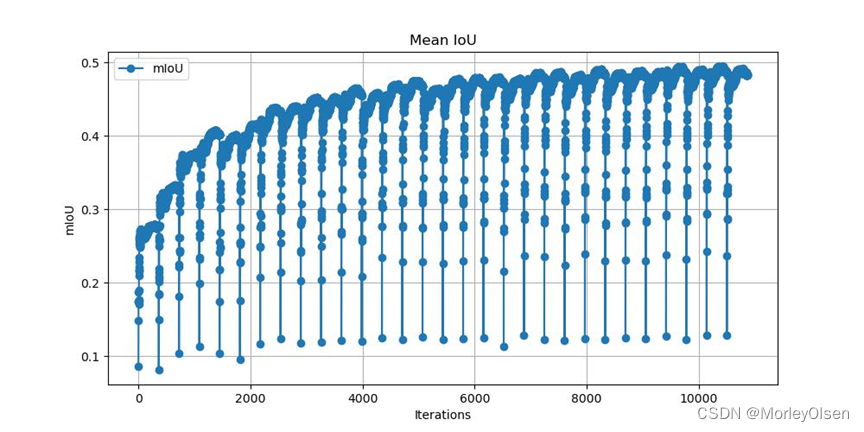
本次训练的验证集像素分类准确率变化如下图所示:
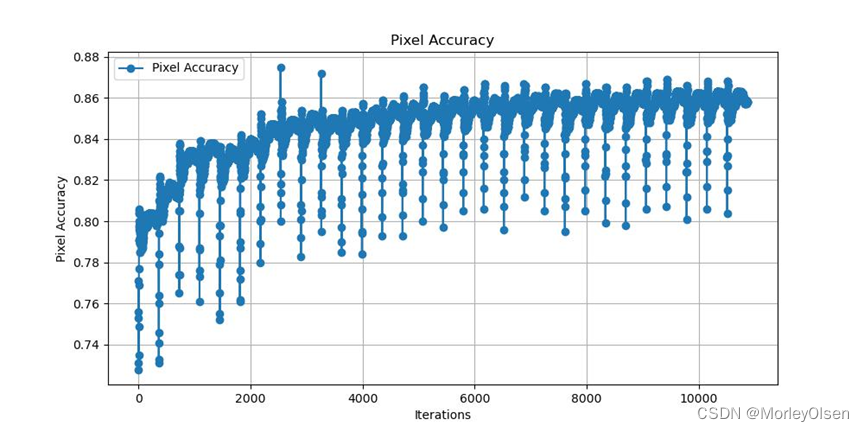
2:FCN16s的训练
设置训练指令,采用FCN16s作为分割模型,采用vgg16作为backbone卷积模型,采用0.0001作为初始学习率,采用30作为训练的迭代次数,采用Pascal VOC 2012作为数据集。
完整指令如下所示:
| python train.py --model fcn16s --backbone vgg16 --dataset pascal_voc --lr 0.0001 --epochs 30 |
本次训练的时长统计为:Total training time: 0:38:59.804016 (0.2131s / it)
本次训练的训练日志路径为:/home/ubuntu/awesome-semantic-segmentation-pytorch/runs/logs/fcn16s_vgg16_pascal_voc_log.txt
本次训练的训练集学习率变化如下图所示:
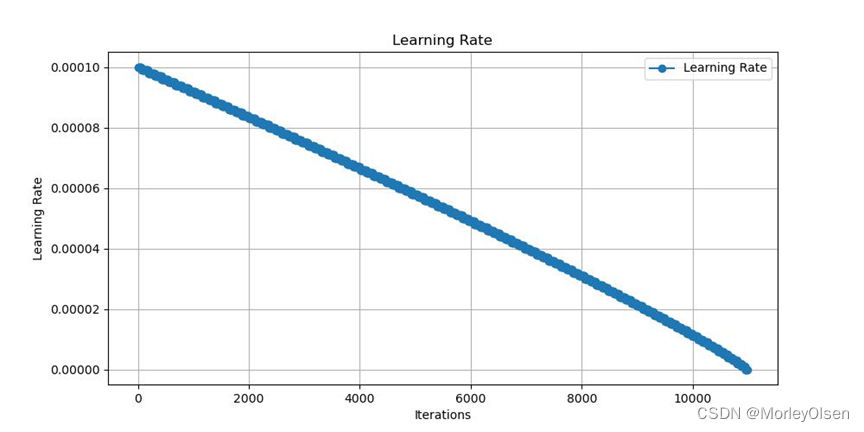
本次训练的训练集损失值变化如下图所示:
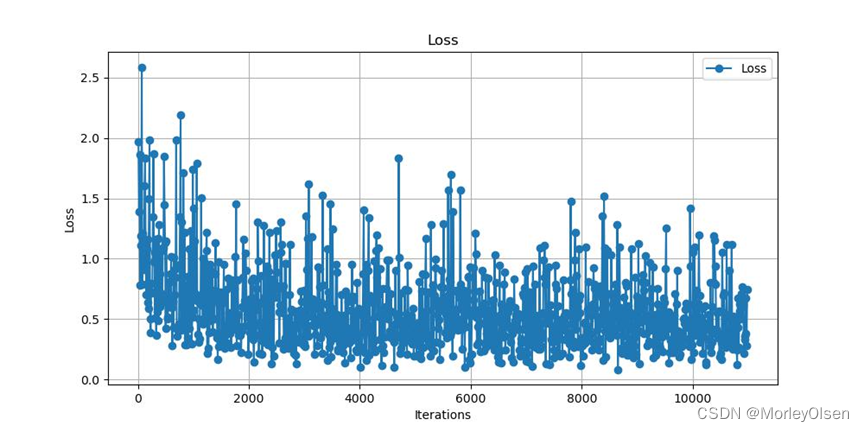
本次训练的验证集mIoU变化如下图所示:
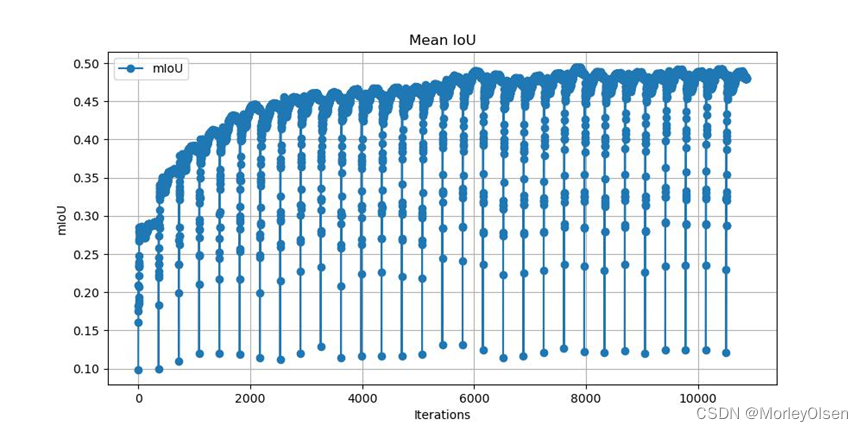
本次训练的验证集像素分类准确率变化如下图所示:
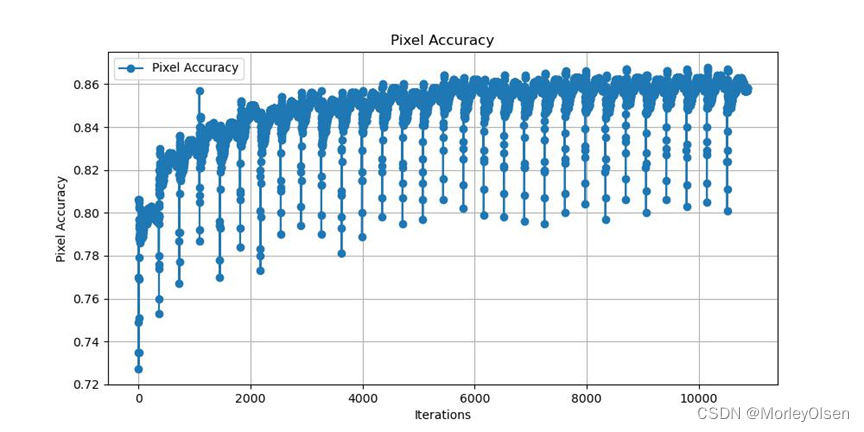
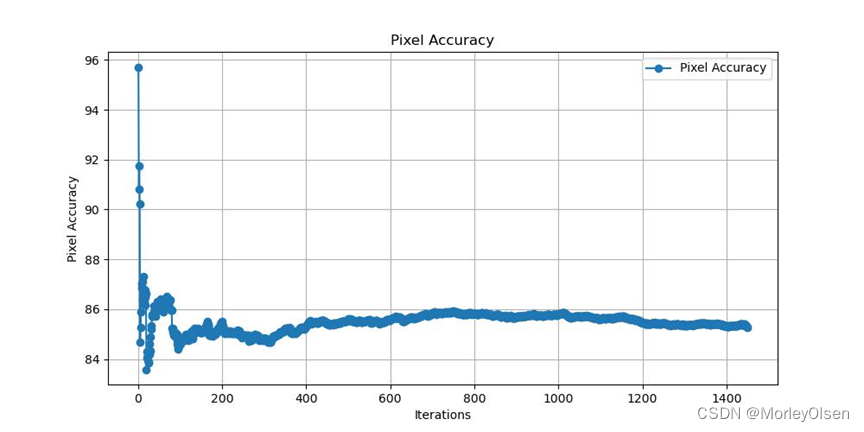
3:FCN32s的训练
设置训练指令,采用FCN32s作为分割模型,采用vgg16作为backbone卷积模型,采用0.0001作为初始学习率,采用30作为训练的迭代次数,采用Pascal VOC 2012作为数据集。
完整指令如下所示:
| python train.py --model fcn32s --backbone vgg16 --dataset pascal_voc --lr 0.0001 --epochs 30 |
本次训练的时长统计为:Total training time: 0:43:39.373219 (0.2386s / it)
本次训练的训练日志路径为:/home/ubuntu/awesome-semantic-segmentation-pytorch/runs/logs/fcn32s_vgg16_pascal_voc_log.txt
本次训练的训练集学习率变化如下图所示:

本次训练的训练集损失值变化如下图所示:
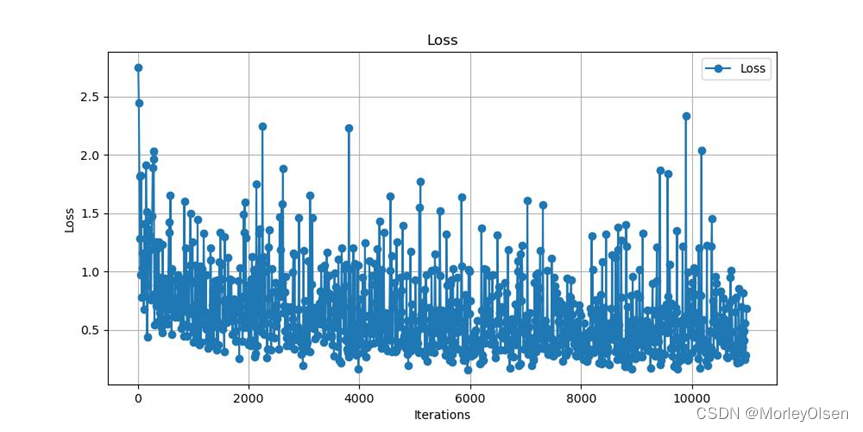
本次训练的验证集mIoU变化如下图所示:
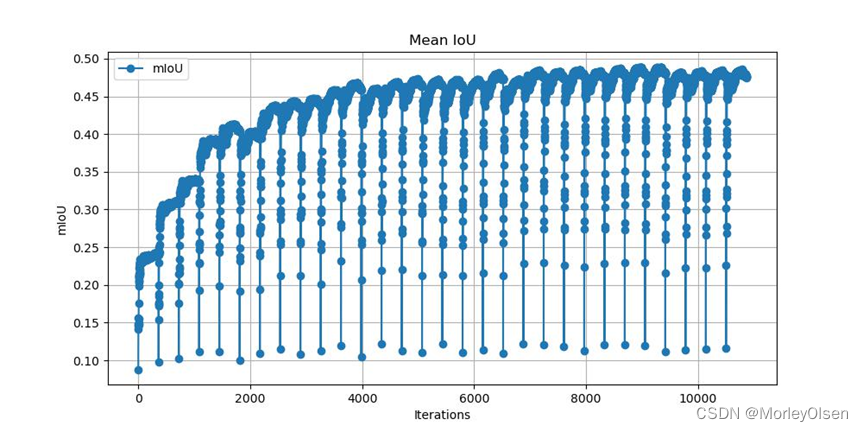
本次训练的验证集像素分类准确率变化如下图所示:
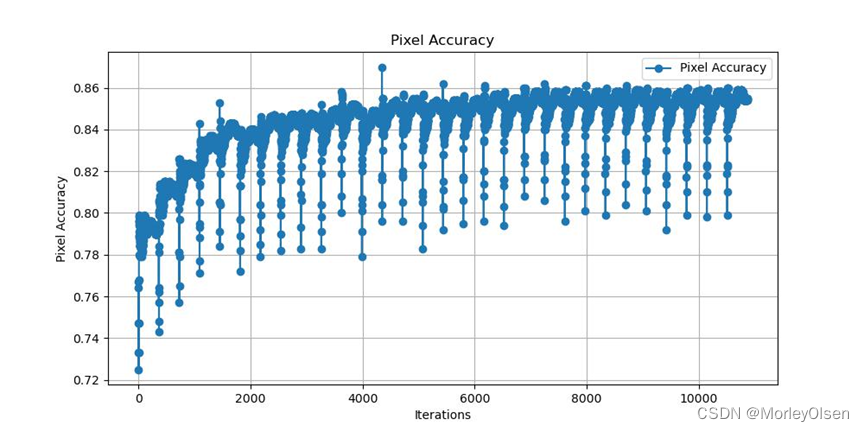
4:FCN8s的验证
完整指令如下所示:
| python eval.py --model fcn8s --backbone vgg16 --dataset pascal_voc |
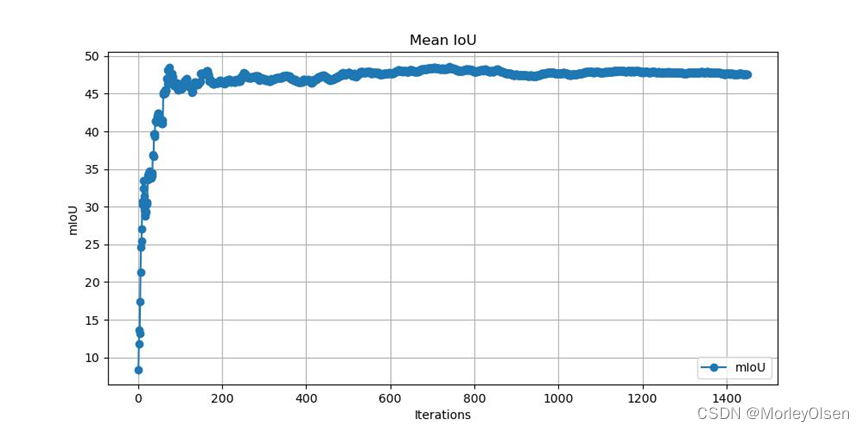
本次验证的数据集mIoU变化如下图所示:
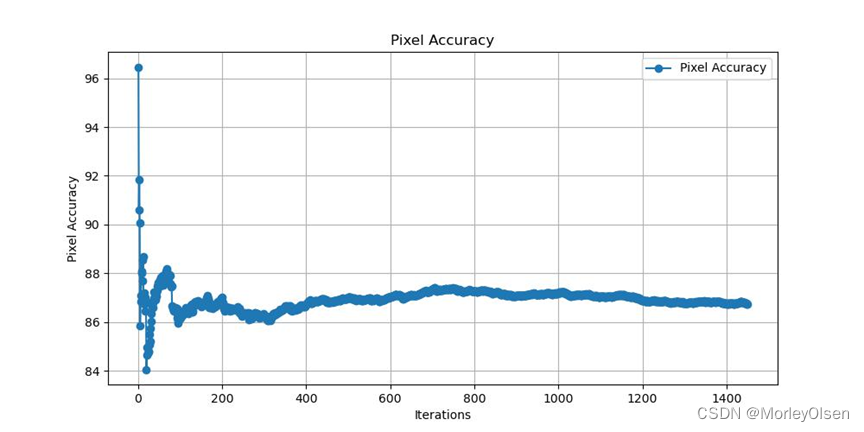
从数据集中抽样,分割图像与原图的对比结果如下图所示:

5:FCN16s的验证
完整指令如下所示:
| python eval.py --model fcn16s --backbone vgg16 --dataset pascal_voc |
本次验证的数据集mIoU变化如下图所示:
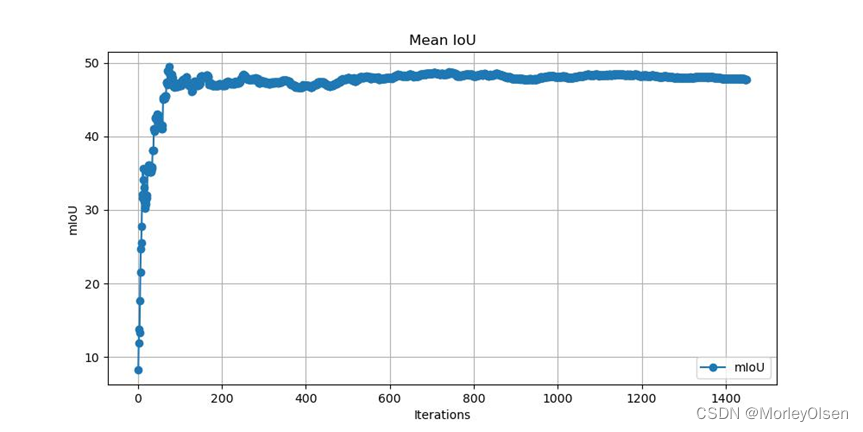
本次验证的数据集像素分类准确率变化如下图所示:

从数据集中抽样,分割图像与原图的对比结果如下图所示:

6:FCN32s的验证
完整指令如下所示:
| python eval.py --model fcn32s --backbone vgg16 --dataset pascal_voc |
本次验证的数据集mIoU变化如下图所示:
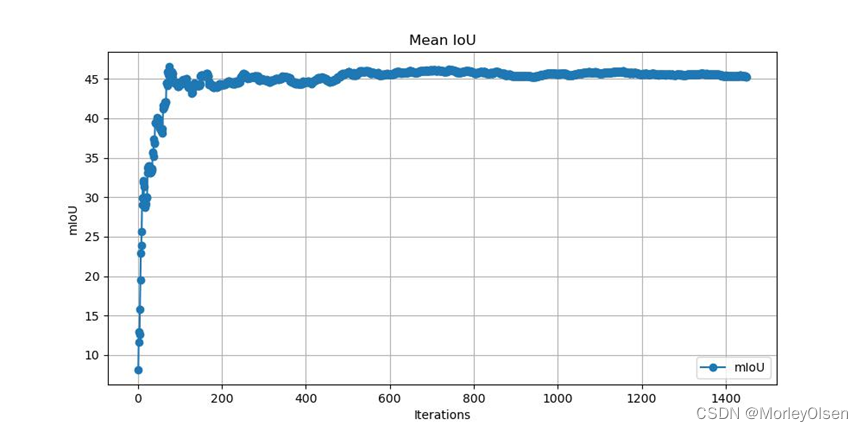
本次验证的数据集像素分类准确率变化如下图所示:
从数据集中抽样,分割图像与原图的对比结果如下图所示:

7:FCN8s的预测
完整指令如下所示:
| python demo.py --model fcn8s_vgg16_voc --input-pic /home/ubuntu/awesome-semantic-segmentation-pytorch/tests/sheep.jpg |
预测样本的分割图像与原图的对比结果如下图所示:

8:FCN16s的预测
完整指令如下所示:
| python demo.py --model fcn16s_vgg16_voc --input-pic /home/ubuntu/awesome-semantic-segmentation-pytorch/tests/sheep.jpg |
预测样本的分割图像与原图的对比结果如下图所示:

9:FCN32s的预测
完整指令如下所示:
| python demo.py --model fcn32s_vgg16_voc --input-pic /home/ubuntu/awesome-semantic-segmentation-pytorch/tests/sheep.jpg |
预测样本的分割图像与原图的对比结果如下图所示:

10:FCN的优化(backbone使用resnet系列)
根据pytorch官网中关于FCN的介绍(FCN | PyTorch),官网采用了ResNet-50和ResNet-101作为了FCN的backbone。因此,本实验中将直接把更换backbone作为FCN的优化改进方法。
以resnet50作为backbone,预测样本的分割图像与原图的对比结果如下图所示:

以resnet101作为backbone,预测样本的分割图像与原图的对比结果如下图所示:

从上图可以发现,在pytorch官网提供的FCN模型中,预测图像的精度有大幅度的提升。
六:实验结论
1:通过可视化比较不同模型的分割效果,可以直观地了解不同模型的性能差异和优劣势,进而为模型选择和优化提供参考。
2:FCN网络结构主要分为全卷积部分和反卷积部分。全卷积部分是CNN网络,用于提取特征;反卷积部分是通过上采样得到原尺寸的语义分割图像。FCN的输入可以为任意尺寸的彩色图像,输出与输入尺寸相同,通道数为目标类别数+1(背景)。FCN是从抽象的特征中恢复出每个像素所属的类别,即从图像级别的分类进一步延伸到像素级别的分类。
3:FCN通过跳级结构将最后一层的预测(富有全局信息)和更浅层(富有局部信息)的预测结合起来,在遵守全局预测的同时进行局部预测。
4:FCN的缺点,第一个是得到的结果还不够精细,对细节不够敏感;第二个是未考虑像素与像素之间的关系,缺乏空间一致性等。
七:遇到的问题和解决方法
问题1:Pascal VOC 2012数据集的数量较大,导致下载时过程较慢。
解决1:暂无,只能等待半个小时左右。
问题2:对于FCN网络的训练、验证和预测,很难通过单一代码进行实现。
解决2:在GitHub上查找了一些可用的仓库,例如awesome-semantic-segmentation-pytorch和Amazing-Semantic-Segmentation,以及官方给的fcn.berkeleyvision.org。考虑到用户友好性,最终采用了awesome-semantic-segmentation-pytorch作为本次实验的主体框架。
问题3:仓库awesome-semantic-segmentation-pytorch的工程,如果使用fcn+resnet系列,则resnet的下载链接有问题。
解决3:暂时没找到工程中的解决方法。而是选择了torch官方的集成模型进行预测。
八:程序源代码
源代码可参考以下链接:https://github.com/Tramac/awesome-semantic-segmentation-pytorch,此处只给出本次实验中重要的代码。
1:训练代码
| import argparse import time import datetime import os import shutil import sys cur_path = os.path.abspath(os.path.dirname(__file__)) root_path = os.path.split(cur_path)[0] sys.path.append(root_path) import torch import torch.nn as nn import torch.utils.data as data import torch.backends.cudnn as cudnn from torchvision import transforms from core.data.dataloader import get_segmentation_dataset from core.models.model_zoo import get_segmentation_model from core.utils.loss import get_segmentation_loss from core.utils.distributed import * from core.utils.logger import setup_logger from core.utils.lr_scheduler import WarmupPolyLR from core.utils.score import SegmentationMetric def parse_args(): parser = argparse.ArgumentParser(description='Semantic Segmentation Training With Pytorch') # model and dataset parser.add_argument('--model', type=str, default='fcn', choices=['fcn32s', 'fcn16s', 'fcn8s', 'fcn', 'psp', 'deeplabv3', 'deeplabv3_plus', 'danet', 'denseaspp', 'bisenet', 'encnet', 'dunet', 'icnet', 'enet', 'ocnet', 'psanet', 'cgnet', 'espnet', 'lednet', 'dfanet','swnet'], help='model name (default: fcn32s)') parser.add_argument('--backbone', type=str, default='resnet50', choices=['vgg16', 'resnet18', 'resnet50', 'resnet101', 'resnet152', 'densenet121', 'densenet161', 'densenet169', 'densenet201'], help='backbone name (default: vgg16)') parser.add_argument('--dataset', type=str, default='pascal_voc', choices=['pascal_voc', 'pascal_aug', 'ade20k', 'citys', 'sbu'], help='dataset name (default: pascal_voc)') parser.add_argument('--base-size', type=int, default=520, help='base image size') parser.add_argument('--crop-size', type=int, default=480, help='crop image size') parser.add_argument('--workers', '-j', type=int, default=4, metavar='N', help='dataloader threads') # training hyper params parser.add_argument('--jpu', action='store_true', default=False, help='JPU') parser.add_argument('--use-ohem', type=bool, default=False, help='OHEM Loss for cityscapes dataset') parser.add_argument('--aux', action='store_true', default=False, help='Auxiliary loss') parser.add_argument('--aux-weight', type=float, default=0.4, help='auxiliary loss weight') parser.add_argument('--batch-size', type=int, default=4, metavar='N', help='input batch size for training (default: 8)') parser.add_argument('--start_epoch', type=int, default=0, metavar='N', help='start epochs (default:0)') parser.add_argument('--epochs', type=int, default=50, metavar='N', help='number of epochs to train (default: 50)') parser.add_argument('--lr', type=float, default=1e-4, metavar='LR', help='learning rate (default: 1e-4)') parser.add_argument('--momentum', type=float, default=0.9, metavar='M', help='momentum (default: 0.9)') parser.add_argument('--weight-decay', type=float, default=1e-4, metavar='M', help='w-decay (default: 5e-4)') parser.add_argument('--warmup-iters', type=int, default=0, help='warmup iters') parser.add_argument('--warmup-factor', type=float, default=1.0 / 3, help='lr = warmup_factor * lr') parser.add_argument('--warmup-method', type=str, default='linear', help='method of warmup') # cuda setting parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training') parser.add_argument('--local_rank', type=int, default=0) # checkpoint and log parser.add_argument('--resume', type=str, default=None, help='put the path to resuming file if needed') parser.add_argument('--save-dir', default='~/.torch/models', help='Directory for saving checkpoint models') parser.add_argument('--save-epoch', type=int, default=10, help='save model every checkpoint-epoch') parser.add_argument('--log-dir', default='../runs/logs/', help='Directory for saving checkpoint models') parser.add_argument('--log-iter', type=int, default=10, help='print log every log-iter') # evaluation only parser.add_argument('--val-epoch', type=int, default=1, help='run validation every val-epoch') parser.add_argument('--skip-val', action='store_true', default=False, help='skip validation during training') args = parser.parse_args() # default settings for epochs, batch_size and lr if args.epochs is None: epoches = { 'coco': 30, 'pascal_aug': 80, 'pascal_voc': 50, 'pcontext': 80, 'ade20k': 160, 'citys': 120, 'sbu': 160, } args.epochs = epoches[args.dataset.lower()] if args.lr is None: lrs = { 'coco': 0.004, 'pascal_aug': 0.001, 'pascal_voc': 0.0001, 'pcontext': 0.001, 'ade20k': 0.01, 'citys': 0.01, 'sbu': 0.001, } args.lr = lrs[args.dataset.lower()] / 8 * args.batch_size return args class Trainer(object): def __init__(self, args): self.args = args self.device = torch.device(args.device) # image transform input_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([.485, .456, .406], [.229, .224, .225]), ]) # dataset and dataloader data_kwargs = {'transform': input_transform, 'base_size': args.base_size, 'crop_size': args.crop_size} train_dataset = get_segmentation_dataset(args.dataset, split='train', mode='train', **data_kwargs) val_dataset = get_segmentation_dataset(args.dataset, split='val', mode='val', **data_kwargs) args.iters_per_epoch = len(train_dataset) // (args.num_gpus * args.batch_size) args.max_iters = args.epochs * args.iters_per_epoch train_sampler = make_data_sampler(train_dataset, shuffle=True, distributed=args.distributed) train_batch_sampler = make_batch_data_sampler(train_sampler, args.batch_size, args.max_iters) val_sampler = make_data_sampler(val_dataset, False, args.distributed) val_batch_sampler = make_batch_data_sampler(val_sampler, args.batch_size) self.train_loader = data.DataLoader(dataset=train_dataset, batch_sampler=train_batch_sampler, num_workers=args.workers, pin_memory=True) self.val_loader = data.DataLoader(dataset=val_dataset, batch_sampler=val_batch_sampler, num_workers=args.workers, pin_memory=True) # create network BatchNorm2d = nn.SyncBatchNorm if args.distributed else nn.BatchNorm2d self.model = get_segmentation_model(model=args.model, dataset=args.dataset, backbone=args.backbone, aux=args.aux, jpu=args.jpu, norm_layer=BatchNorm2d).to(self.device) # resume checkpoint if needed if args.resume: if os.path.isfile(args.resume): name, ext = os.path.splitext(args.resume) assert ext == '.pkl' or '.pth', 'Sorry only .pth and .pkl files supported.' print('Resuming training, loading {}...'.format(args.resume)) self.model.load_state_dict(torch.load(args.resume, map_location=lambda storage, loc: storage)) # create criterion self.criterion = get_segmentation_loss(args.model, use_ohem=args.use_ohem, aux=args.aux, aux_weight=args.aux_weight, ignore_index=-1).to(self.device) # optimizer, for model just includes pretrained, head and auxlayer params_list = list() if hasattr(self.model, 'pretrained'): params_list.append({'params': self.model.pretrained.parameters(), 'lr': args.lr}) if hasattr(self.model, 'exclusive'): for module in self.model.exclusive: params_list.append({'params': getattr(self.model, module).parameters(), 'lr': args.lr * 10}) self.optimizer = torch.optim.SGD(params_list, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay) # lr scheduling self.lr_scheduler = WarmupPolyLR(self.optimizer, max_iters=args.max_iters, power=0.9, warmup_factor=args.warmup_factor, warmup_iters=args.warmup_iters, warmup_method=args.warmup_method) if args.distributed: self.model = nn.parallel.DistributedDataParallel(self.model, device_ids=[args.local_rank], output_device=args.local_rank) # evaluation metrics self.metric = SegmentationMetric(train_dataset.num_class) self.best_pred = 0.0 def train(self): save_to_disk = get_rank() == 0 epochs, max_iters = self.args.epochs, self.args.max_iters log_per_iters, val_per_iters = self.args.log_iter, self.args.val_epoch * self.args.iters_per_epoch save_per_iters = self.args.save_epoch * self.args.iters_per_epoch start_time = time.time() logger.info('Start training, Total Epochs: {:d} = Total Iterations {:d}'.format(epochs, max_iters)) self.model.train() for iteration, (images, targets, _) in enumerate(self.train_loader): iteration = iteration + 1 self.lr_scheduler.step() images = images.to(self.device) targets = targets.to(self.device) outputs = self.model(images) loss_dict = self.criterion(outputs, targets) losses = sum(loss for loss in loss_dict.values()) # reduce losses over all GPUs for logging purposes loss_dict_reduced = reduce_loss_dict(loss_dict) losses_reduced = sum(loss for loss in loss_dict_reduced.values()) self.optimizer.zero_grad() losses.backward() self.optimizer.step() eta_seconds = ((time.time() - start_time) / iteration) * (max_iters - iteration) eta_string = str(datetime.timedelta(seconds=int(eta_seconds))) if iteration % log_per_iters == 0 and save_to_disk: logger.info( "Iters: {:d}/{:d} || Lr: {:.6f} || Loss: {:.4f} || Cost Time: {} || Estimated Time: {}".format( iteration, max_iters, self.optimizer.param_groups[0]['lr'], losses_reduced.item(), str(datetime.timedelta(seconds=int(time.time() - start_time))), eta_string)) if iteration % save_per_iters == 0 and save_to_disk: save_checkpoint(self.model, self.args, is_best=False) if not self.args.skip_val and iteration % val_per_iters == 0: self.validation() self.model.train() save_checkpoint(self.model, self.args, is_best=False) total_training_time = time.time() - start_time total_training_str = str(datetime.timedelta(seconds=total_training_time)) logger.info( "Total training time: {} ({:.4f}s / it)".format( total_training_str, total_training_time / max_iters)) def validation(self): # total_inter, total_union, total_correct, total_label = 0, 0, 0, 0 is_best = False self.metric.reset() if self.args.distributed: model = self.model.module else: model = self.model torch.cuda.empty_cache() # TODO check if it helps model.eval() for i, (image, target, filename) in enumerate(self.val_loader): image = image.to(self.device) target = target.to(self.device) with torch.no_grad(): outputs = model(image) self.metric.update(outputs[0], target) pixAcc, mIoU = self.metric.get() logger.info("Sample: {:d}, Validation pixAcc: {:.3f}, mIoU: {:.3f}".format(i + 1, pixAcc, mIoU)) new_pred = (pixAcc + mIoU) / 2 if new_pred > self.best_pred: is_best = True self.best_pred = new_pred save_checkpoint(self.model, self.args, is_best) synchronize() def save_checkpoint(model, args, is_best=False): """Save Checkpoint""" directory = os.path.expanduser(args.save_dir) if not os.path.exists(directory): os.makedirs(directory) filename = '{}_{}_{}.pth'.format(args.model, args.backbone, args.dataset) filename = os.path.join(directory, filename) if args.distributed: model = model.module torch.save(model.state_dict(), filename) if is_best: best_filename = '{}_{}_{}_best_model.pth'.format(args.model, args.backbone, args.dataset) best_filename = os.path.join(directory, best_filename) shutil.copyfile(filename, best_filename) if __name__ == '__main__': args = parse_args() # reference maskrcnn-benchmark num_gpus = int(os.environ["WORLD_SIZE"]) if "WORLD_SIZE" in os.environ else 1 args.num_gpus = num_gpus args.distributed = num_gpus > 1 if not args.no_cuda and torch.cuda.is_available(): cudnn.benchmark = True args.device = "cuda" else: args.distributed = False args.device = "cpu" if args.distributed: torch.cuda.set_device(args.local_rank) torch.distributed.init_process_group(backend="nccl", init_method="env://") synchronize() args.lr = args.lr * num_gpus logger = setup_logger("semantic_segmentation", args.log_dir, get_rank(), filename='{}_{}_{}_log.txt'.format( args.model, args.backbone, args.dataset)) logger.info("Using {} GPUs".format(num_gpus)) logger.info(args) trainer = Trainer(args) trainer.train() torch.cuda.empty_cache() |
2:验证代码
| from __future__ import print_function import os import sys cur_path = os.path.abspath(os.path.dirname(__file__)) root_path = os.path.split(cur_path)[0] sys.path.append(root_path) import torch import torch.nn as nn import torch.utils.data as data import torch.backends.cudnn as cudnn from torchvision import transforms from core.data.dataloader import get_segmentation_dataset from core.models.model_zoo import get_segmentation_model from core.utils.score import SegmentationMetric from core.utils.visualize import get_color_pallete from core.utils.logger import setup_logger from core.utils.distributed import synchronize, get_rank, make_data_sampler, make_batch_data_sampler from train import parse_args class Evaluator(object): def __init__(self, args): self.args = args self.device = torch.device(args.device) # image transform input_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([.485, .456, .406], [.229, .224, .225]), ]) # dataset and dataloader val_dataset = get_segmentation_dataset(args.dataset, split='val', mode='testval', transform=input_transform) val_sampler = make_data_sampler(val_dataset, False, args.distributed) val_batch_sampler = make_batch_data_sampler(val_sampler, images_per_batch=1) self.val_loader = data.DataLoader(dataset=val_dataset, batch_sampler=val_batch_sampler, num_workers=args.workers, pin_memory=True) # create network BatchNorm2d = nn.SyncBatchNorm if args.distributed else nn.BatchNorm2d self.model = get_segmentation_model(model=args.model, dataset=args.dataset, backbone=args.backbone, aux=args.aux, pretrained=True, pretrained_base=False, local_rank=args.local_rank, norm_layer=BatchNorm2d).to(self.device) if args.distributed: self.model = nn.parallel.DistributedDataParallel(self.model, device_ids=[args.local_rank], output_device=args.local_rank) self.model.to(self.device) self.metric = SegmentationMetric(val_dataset.num_class) def eval(self): self.metric.reset() self.model.eval() if self.args.distributed: model = self.model.module else: model = self.model logger.info("Start validation, Total sample: {:d}".format(len(self.val_loader))) for i, (image, target, filename) in enumerate(self.val_loader): image = image.to(self.device) target = target.to(self.device) with torch.no_grad(): outputs = model(image) self.metric.update(outputs[0], target) pixAcc, mIoU = self.metric.get() logger.info("Sample: {:d}, validation pixAcc: {:.3f}, mIoU: {:.3f}".format( i + 1, pixAcc * 100, mIoU * 100)) if self.args.save_pred: pred = torch.argmax(outputs[0], 1) pred = pred.cpu().data.numpy() predict = pred.squeeze(0) mask = get_color_pallete(predict, self.args.dataset) mask.save(os.path.join(outdir, os.path.splitext(filename[0])[0] + '.png')) synchronize() if __name__ == '__main__': args = parse_args() num_gpus = int(os.environ["WORLD_SIZE"]) if "WORLD_SIZE" in os.environ else 1 args.distributed = num_gpus > 1 if not args.no_cuda and torch.cuda.is_available(): cudnn.benchmark = True args.device = "cuda" else: args.distributed = False args.device = "cpu" if args.distributed: torch.cuda.set_device(args.local_rank) torch.distributed.init_process_group(backend="nccl", init_method="env://") synchronize() # TODO: optim code args.save_pred = True if args.save_pred: outdir = '../runs/pred_pic/{}_{}_{}'.format(args.model, args.backbone, args.dataset) if not os.path.exists(outdir): os.makedirs(outdir) logger = setup_logger("semantic_segmentation", args.log_dir, get_rank(), filename='{}_{}_{}_log.txt'.format(args.model, args.backbone, args.dataset), mode='a+') evaluator = Evaluator(args) evaluator.eval() torch.cuda.empty_cache() |
3:测试代码
| import os import sys import argparse import torch cur_path = os.path.abspath(os.path.dirname(__file__)) root_path = os.path.split(cur_path)[0] sys.path.append(root_path) from torchvision import transforms from PIL import Image from core.utils.visualize import get_color_pallete from core.models import get_model parser = argparse.ArgumentParser( description='Predict segmentation result from a given image') parser.add_argument('--model', type=str, default='fcn32s_vgg16_voc', help='model name (default: fcn32_vgg16)') parser.add_argument('--dataset', type=str, default='pascal_aug', choices=['pascal_voc, pascal_aug, ade20k, citys'], help='dataset name (default: pascal_voc)') parser.add_argument('--save-folder', default='~/.torch/models', help='Directory for saving checkpoint models') parser.add_argument('--input-pic', type=str, default='../datasets/voc/VOC2012/JPEGImages/2007_000032.jpg', help='path to the input picture') parser.add_argument('--outdir', default='./eval', type=str, help='path to save the predict result') parser.add_argument('--local_rank', type=int, default=0) args = parser.parse_args() def demo(config): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # output folder if not os.path.exists(config.outdir): os.makedirs(config.outdir) # image transform transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ]) image = Image.open(config.input_pic).convert('RGB') images = transform(image).unsqueeze(0).to(device) model = get_model(args.model, local_rank=args.local_rank, pretrained=True, root=args.save_folder).to(device) print('Finished loading model!') model.eval() with torch.no_grad(): output = model(images) pred = torch.argmax(output[0], 1).squeeze(0).cpu().data.numpy() mask = get_color_pallete(pred, args.dataset) outname = os.path.splitext(os.path.split(args.input_pic)[-1])[0] + '.png' mask.save(os.path.join(args.outdir, outname)) if __name__ == '__main__': demo(args) |
4:分割图像和原图对比代码
| from PIL import Image def merge_images(original_image_path, segmentation_image_path, output_image_path): # Open original and segmentation images original_image = Image.open(original_image_path) segmentation_image = Image.open(segmentation_image_path) # Resize segmentation image if needed to match original image size if original_image.size != segmentation_image.size: segmentation_image = segmentation_image.resize(original_image.size, Image.NEAREST) # Create a new image with same width and double height merged_image = Image.new('RGB', (original_image.width, original_image.height * 2)) # Paste original image at the top merged_image.paste(original_image, (0, 0)) # Paste segmentation image at the bottom merged_image.paste(segmentation_image, (0, original_image.height)) # Save the merged image merged_image.save(output_image_path) original = r"/home/ubuntu/awesome-semantic-segmentation-pytorch/tests/sheep.jpg" segmentation = r"/home/ubuntu/awesome-semantic-segmentation-pytorch/scripts/eval/sheep.png" merge_images(original, segmentation, '/home/ubuntu/zzz-merged.jpg') |
5:FCN网络结构代码
| import os import torch import torch.nn as nn import torch.nn.functional as F from .base_models.vgg import vgg16 __all__ = ['get_fcn32s', 'get_fcn16s', 'get_fcn8s', 'get_fcn32s_vgg16_voc', 'get_fcn16s_vgg16_voc', 'get_fcn8s_vgg16_voc'] class FCN32s(nn.Module): """There are some difference from original fcn""" def __init__(self, nclass, backbone='vgg16', aux=False, pretrained_base=True, norm_layer=nn.BatchNorm2d, **kwargs): super(FCN32s, self).__init__() self.aux = aux if backbone == 'vgg16': self.pretrained = vgg16(pretrained=pretrained_base).features else: raise RuntimeError('unknown backbone: {}'.format(backbone)) self.head = _FCNHead(512, nclass, norm_layer) if aux: self.auxlayer = _FCNHead(512, nclass, norm_layer) self.__setattr__('exclusive', ['head', 'auxlayer'] if aux else ['head']) def forward(self, x): size = x.size()[2:] pool5 = self.pretrained(x) outputs = [] out = self.head(pool5) out = F.interpolate(out, size, mode='bilinear', align_corners=True) outputs.append(out) if self.aux: auxout = self.auxlayer(pool5) auxout = F.interpolate(auxout, size, mode='bilinear', align_corners=True) outputs.append(auxout) return tuple(outputs) class FCN16s(nn.Module): def __init__(self, nclass, backbone='vgg16', aux=False, pretrained_base=True, norm_layer=nn.BatchNorm2d, **kwargs): super(FCN16s, self).__init__() self.aux = aux if backbone == 'vgg16': self.pretrained = vgg16(pretrained=pretrained_base).features else: raise RuntimeError('unknown backbone: {}'.format(backbone)) self.pool4 = nn.Sequential(*self.pretrained[:24]) self.pool5 = nn.Sequential(*self.pretrained[24:]) self.head = _FCNHead(512, nclass, norm_layer) self.score_pool4 = nn.Conv2d(512, nclass, 1) if aux: self.auxlayer = _FCNHead(512, nclass, norm_layer) self.__setattr__('exclusive', ['head', 'score_pool4', 'auxlayer'] if aux else ['head', 'score_pool4']) def forward(self, x): pool4 = self.pool4(x) pool5 = self.pool5(pool4) outputs = [] score_fr = self.head(pool5) score_pool4 = self.score_pool4(pool4) upscore2 = F.interpolate(score_fr, score_pool4.size()[2:], mode='bilinear', align_corners=True) fuse_pool4 = upscore2 + score_pool4 out = F.interpolate(fuse_pool4, x.size()[2:], mode='bilinear', align_corners=True) outputs.append(out) if self.aux: auxout = self.auxlayer(pool5) auxout = F.interpolate(auxout, x.size()[2:], mode='bilinear', align_corners=True) outputs.append(auxout) return tuple(outputs) class FCN8s(nn.Module): def __init__(self, nclass, backbone='vgg16', aux=False, pretrained_base=True, norm_layer=nn.BatchNorm2d, **kwargs): super(FCN8s, self).__init__() self.aux = aux if backbone == 'vgg16': self.pretrained = vgg16(pretrained=pretrained_base).features else: raise RuntimeError('unknown backbone: {}'.format(backbone)) self.pool3 = nn.Sequential(*self.pretrained[:17]) self.pool4 = nn.Sequential(*self.pretrained[17:24]) self.pool5 = nn.Sequential(*self.pretrained[24:]) self.head = _FCNHead(512, nclass, norm_layer) self.score_pool3 = nn.Conv2d(256, nclass, 1) self.score_pool4 = nn.Conv2d(512, nclass, 1) if aux: self.auxlayer = _FCNHead(512, nclass, norm_layer) self.__setattr__('exclusive', ['head', 'score_pool3', 'score_pool4', 'auxlayer'] if aux else ['head', 'score_pool3', 'score_pool4']) def forward(self, x): pool3 = self.pool3(x) pool4 = self.pool4(pool3) pool5 = self.pool5(pool4) outputs = [] score_fr = self.head(pool5) score_pool4 = self.score_pool4(pool4) score_pool3 = self.score_pool3(pool3) upscore2 = F.interpolate(score_fr, score_pool4.size()[2:], mode='bilinear', align_corners=True) fuse_pool4 = upscore2 + score_pool4 upscore_pool4 = F.interpolate(fuse_pool4, score_pool3.size()[2:], mode='bilinear', align_corners=True) fuse_pool3 = upscore_pool4 + score_pool3 out = F.interpolate(fuse_pool3, x.size()[2:], mode='bilinear', align_corners=True) outputs.append(out) if self.aux: auxout = self.auxlayer(pool5) auxout = F.interpolate(auxout, x.size()[2:], mode='bilinear', align_corners=True) outputs.append(auxout) return tuple(outputs) class _FCNHead(nn.Module): def __init__(self, in_channels, channels, norm_layer=nn.BatchNorm2d, **kwargs): super(_FCNHead, self).__init__() inter_channels = in_channels // 4 self.block = nn.Sequential( nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False), norm_layer(inter_channels), nn.ReLU(inplace=True), nn.Dropout(0.1), nn.Conv2d(inter_channels, channels, 1) ) def forward(self, x): return self.block(x) def get_fcn32s(dataset='pascal_voc', backbone='vgg16', pretrained=False, root='~/.torch/models', pretrained_base=True, **kwargs): acronyms = { 'pascal_voc': 'pascal_voc', 'pascal_aug': 'pascal_aug', 'ade20k': 'ade', 'coco': 'coco', 'citys': 'citys', 'sbu': 'sbu', } from ..data.dataloader import datasets model = FCN32s(datasets[dataset].NUM_CLASS, backbone=backbone, pretrained_base=pretrained_base, **kwargs) if pretrained: from .model_store import get_model_file device = torch.device(kwargs['local_rank']) model.load_state_dict(torch.load(get_model_file('fcn32s_%s_%s' % (backbone, acronyms[dataset]), root=root), map_location=device)) return model def get_fcn16s(dataset='pascal_voc', backbone='vgg16', pretrained=False, root='~/.torch/models', pretrained_base=True, **kwargs): acronyms = { 'pascal_voc': 'pascal_voc', 'pascal_aug': 'pascal_aug', 'ade20k': 'ade', 'coco': 'coco', 'citys': 'citys', 'sbu': 'sbu', } from ..data.dataloader import datasets model = FCN16s(datasets[dataset].NUM_CLASS, backbone=backbone, pretrained_base=pretrained_base, **kwargs) if pretrained: from .model_store import get_model_file device = torch.device(kwargs['local_rank']) model.load_state_dict(torch.load(get_model_file('fcn16s_%s_%s' % (backbone, acronyms[dataset]), root=root), map_location=device)) return model def get_fcn8s(dataset='pascal_voc', backbone='vgg16', pretrained=False, root='~/.torch/models', pretrained_base=True, **kwargs): acronyms = { 'pascal_voc': 'pascal_voc', 'pascal_aug': 'pascal_aug', 'ade20k': 'ade', 'coco': 'coco', 'citys': 'citys', 'sbu': 'sbu', } from ..data.dataloader import datasets model = FCN8s(datasets[dataset].NUM_CLASS, backbone=backbone, pretrained_base=pretrained_base, **kwargs) if pretrained: from .model_store import get_model_file device = torch.device(kwargs['local_rank']) model.load_state_dict(torch.load(get_model_file('fcn8s_%s_%s' % (backbone, acronyms[dataset]), root=root), map_location=device)) return model def get_fcn32s_vgg16_voc(**kwargs): return get_fcn32s('pascal_voc', 'vgg16', **kwargs) def get_fcn16s_vgg16_voc(**kwargs): return get_fcn16s('pascal_voc', 'vgg16', **kwargs) def get_fcn8s_vgg16_voc(**kwargs): return get_fcn8s('pascal_voc', 'vgg16', **kwargs) if __name__ == '__main__': model = FCN16s(21) print(model) |
6:VGG backbone代码
| import torch import torch.nn as nn import torch.utils.model_zoo as model_zoo __all__ = [ 'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn', 'vgg19_bn', 'vgg19', ] model_urls = { 'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth', 'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth', 'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth', 'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth', 'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth', 'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth', 'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth', 'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth', } class VGG(nn.Module): def __init__(self, features, num_classes=1000, init_weights=True): super(VGG, self).__init__() self.features = features self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) self.classifier = nn.Sequential( nn.Linear(512 * 7 * 7, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, num_classes) ) if init_weights: self._initialize_weights() def forward(self, x): x = self.features(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.classifier(x) return x def _initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0) def make_layers(cfg, batch_norm=False): layers = [] in_channels = 3 for v in cfg: if v == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) if batch_norm: layers += (conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)) else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v return nn.Sequential(*layers) cfg = { 'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], 'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], 'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], 'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'], } def vgg11(pretrained=False, **kwargs): """VGG 11-layer model (configuration "A") Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['A']), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg11'])) return model def vgg11_bn(pretrained=False, **kwargs): """VGG 11-layer model (configuration "A") with batch normalization Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['A'], batch_norm=True), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg11_bn'])) return model def vgg13(pretrained=False, **kwargs): """VGG 13-layer model (configuration "B") Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['B']), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg13'])) return model def vgg13_bn(pretrained=False, **kwargs): """VGG 13-layer model (configuration "B") with batch normalization Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['B'], batch_norm=True), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg13_bn'])) return model def vgg16(pretrained=False, **kwargs): """VGG 16-layer model (configuration "D") Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['D']), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg16'])) return model def vgg16_bn(pretrained=False, **kwargs): """VGG 16-layer model (configuration "D") with batch normalization Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['D'], batch_norm=True), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg16_bn'])) return model def vgg19(pretrained=False, **kwargs): """VGG 19-layer model (configuration "E") Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['E']), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg19'])) return model def vgg19_bn(pretrained=False, **kwargs): """VGG 19-layer model (configuration 'E') with batch normalization Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ if pretrained: kwargs['init_weights'] = False model = VGG(make_layers(cfg['E'], batch_norm=True), **kwargs) if pretrained: model.load_state_dict(model_zoo.load_url(model_urls['vgg19_bn'])) return model if __name__ == '__main__': img = torch.randn((4, 3, 480, 480)) model = vgg16(pretrained=False) out = model(img) |
7:训练日志可视化输出代码
| import re import matplotlib.pyplot as plt # 读取日志文件 log_file_path = r"awesome-semantic-segmentation-pytorch/runs/logs/fcn32s_vgg16_pascal_voc_log.txt" with open(log_file_path, 'r') as f: log_data = f.readlines() # 解析日志内容 pixAcc_data = [] mIoU_data = [] iteration_data = [] lr_data = [] loss_data = [] for line in log_data: match = re.search(r'Validation pixAcc: (\d+\.\d+), mIoU: (\d+\.\d+)', line) if match: pixAcc_data.append(float(match.group(1))) mIoU_data.append(float(match.group(2))) re_match = re.search(r'Iters: (\d+)/\d+ \|\| Lr: (\d+\.\d+) \|\| Loss: (\d+\.\d+)', line) if re_match: iteration_data.append(int(re_match.group(1))) lr_data.append(float(re_match.group(2))) loss_data.append(float(re_match.group(3))) # 绘制曲线图 iterations = range(1, len(pixAcc_data) + 1) # Pixel Accuracy的图 plt.figure(figsize=(10, 5)) plt.plot(iterations, pixAcc_data, label='Pixel Accuracy', marker='o') plt.xlabel('Iterations') plt.ylabel('Pixel Accuracy') plt.title('Pixel Accuracy') plt.legend() plt.grid(True) plt.savefig(r"/home/ubuntu/zzz-pixAcc.jpg") # mIoU的图 plt.figure(figsize=(10, 5)) plt.plot(iterations, mIoU_data, label='mIoU', marker='o') plt.xlabel('Iterations') plt.ylabel('mIoU') plt.title('Mean IoU') plt.legend() plt.grid(True) plt.savefig(r"/home/ubuntu/zzz-mIoU.jpg") # Learning Rate的图 plt.figure(figsize=(10, 5)) plt.plot(iteration_data, lr_data, label='Learning Rate', marker='o') plt.xlabel('Iterations') plt.ylabel('Learning Rate') plt.title('Learning Rate') plt.legend() plt.grid(True) plt.savefig(r"/home/ubuntu/zzz-lr.jpg") # Loss的图 plt.figure(figsize=(10, 5)) plt.plot(iteration_data, loss_data, label='Loss', marker='o') plt.xlabel('Iterations') plt.ylabel('Loss') plt.title('Loss') plt.legend() plt.grid(True) plt.savefig(r"/home/ubuntu/zzz-loss.jpg") print("Finished!") |
8:torch.model预测代码
| import torch model = torch.hub.load('pytorch/vision:v0.10.0', 'fcn_resnet50', pretrained=True) model.eval() # Download an example image from the pytorch website import urllib filename = (r"/home/ubuntu/awesome-semantic-segmentation-pytorch/tests/sheep.jpg") # sample execution (requires torchvision) from PIL import Image from torchvision import transforms input_image = Image.open(filename) input_image = input_image.convert("RGB") preprocess = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model # move the input and model to GPU for speed if available if torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda') with torch.no_grad(): output = model(input_batch)['out'][0] output_predictions = output.argmax(0) # create a color pallette, selecting a color for each class palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1]) colors = torch.as_tensor([i for i in range(21)])[:, None] * palette colors = (colors % 255).numpy().astype("uint8") # plot the semantic segmentation predictions of 21 classes in each color r = Image.fromarray(output_predictions.byte().cpu().numpy()).resize(input_image.size) r.putpalette(colors) import matplotlib.pyplot as plt r.save('zzz-semantic_segmentation_result.png') |



















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











